Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
As dicas de desempenho neste artigo são apenas para o SDK Python do Azure Cosmos DB. Consulte as Notas de versão, Pacote (PyPI), Pacote (Conda) e guia de solução de problemas do SDK Python do Azure Cosmos DB para obter mais informações.
O Azure Cosmos DB é uma base de dados distribuída rápida e flexível que escala de forma fluida, com latência e rendimento garantidos. Não é necessário fazer grandes alterações na arquitetura ou escrever código complexo para dimensionar seu banco de dados com o Azure Cosmos DB. Escalar para cima e para baixo é tão fácil quanto fazer uma única chamada de API ou chamada de método SDK. No entanto, como o Azure Cosmos DB é acessado por meio de chamadas de rede, há otimizações do lado do cliente que você pode fazer para atingir o desempenho máximo ao usar o SDK Python do Azure Cosmos DB.
Portanto, se você estiver perguntando "Como posso melhorar o desempenho do meu banco de dados?", considere as seguintes opções:
Rede
- Coloque clientes na mesma região do Azure para desempenho
Quando possível, coloque todos os aplicativos que chamam o Azure Cosmos DB na mesma região do banco de dados do Azure Cosmos DB. Para uma comparação aproximada, as chamadas para o Azure Cosmos DB dentro da mesma região são concluídas dentro de 1 a 2 ms, mas a latência entre a costa oeste e leste dos EUA é >de 50 ms. Essa latência provavelmente pode variar de solicitação para solicitação, dependendo da rota tomada pela solicitação à medida que ela passa do cliente para o limite do datacenter do Azure. A menor latência possível é alcançada garantindo que a aplicação que realiza a chamada esteja localizada na mesma região do Azure que o endpoint provisionado do Azure Cosmos DB. Para obter uma lista de regiões disponíveis, consulte Regiões do Azure.
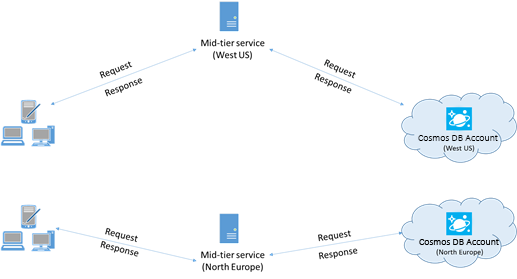
Um aplicativo que interage com uma conta do Azure Cosmos DB de várias regiões precisa configurar locais preferenciais para garantir que as solicitações sejam enviadas para uma região colocada.
Habilite a rede acelerada para reduzir a latência e os desvios da CPU
É recomendável que você siga as instruções para habilitar a Rede Acelerada em sua VM do Azure Windows (selecione para obter instruções) ou Linux (selecione para obter instruções), a fim de maximizar o desempenho (reduzir a latência e os desvios da CPU).
Sem rede acelerada, a E/S que transita entre sua VM do Azure e outros recursos do Azure pode ser roteada desnecessariamente por meio de um host e comutador virtual situado entre a VM e sua placa de rede. Ter o host e o comutador virtual embutidos no caminho de dados não só aumenta a latência e os desvios no canal de comunicação, como também rouba ciclos de CPU da VM. Com rede acelerada, a VM interage diretamente com a NIC sem intermediários; quaisquer detalhes da política de rede que estavam sendo manipulados pelo host e comutador virtual agora são tratados em hardware na NIC; O host e o comutador virtual são ignorados. Geralmente, você pode esperar menor latência e maior taxa de transferência, bem como latência mais consistente e menor utilização da CPU quando você habilita a rede acelerada.
Limitações: a rede acelerada deve ser suportada no sistema operacional da VM e só pode ser habilitada quando a VM é interrompida e deslocalizada. A VM não pode ser implantada com o Azure Resource Manager. App Service não tem rede acelerada ativada.
Consulte as instruções para Windows e Linux para obter mais detalhes.
Alta disponibilidade
Para obter orientações gerais sobre como configurar a alta disponibilidade no Azure Cosmos DB, consulte Alta disponibilidade no Azure Cosmos DB.
Além de uma boa configuração fundamental na plataforma de banco de dados, o disjuntor de nível de partição pode ser implementado no SDK do Python, o que pode ajudar em cenários de interrupção. Esta funcionalidade oferece mecanismos avançados para enfrentar desafios de disponibilidade, superando as funcionalidades de repetição inter-regionais que são incorporadas ao SDK por padrão. Isso pode aumentar significativamente a resiliência e o desempenho de seu aplicativo, especialmente em condições de alta carga ou degradadas.
Disjuntor de nível de partição
O disjuntor de nível de partição (PPCB) no SDK do Python melhora a disponibilidade e a resiliência rastreando a integridade de partições físicas individuais e roteando solicitações longe de partições problemáticas. Esse recurso é particularmente útil para lidar com problemas transitórios e de terminal, como problemas de rede, atualizações de partição ou migrações.
O PPCB é aplicável nos seguintes cenários:
- Qualquer nível de consistência
- Operações com chave de partição (operações pontuais de leitura/escrita)
- Contas com uma única região de gravação e múltiplas regiões de leitura
- Contas com múltiplas regiões de gravação
Como funciona
As partições transitam por quatro estados - Saudável, Não Saudável Tentativo, Não Saudável e Saudável Tentativo - com base no sucesso ou insucesso das solicitações:
- Rastreamento de falhas: O SDK monitora as taxas de erro (por exemplo, 5xx, 408) por partição durante uma janela de um minuto. Falhas consecutivas por partição são rastreadas indefinidamente pelo SDK.
- Marcação como Indisponível: Se uma partição exceder os limites configurados, ela será marcada como Provisória Não Íntegra e excluída do roteamento por 1 minuto.
- Promoção para não saudável ou recuperação: Se as tentativas de recuperação falharem, a partição transita para Não saudável. Após um intervalo de recuo, uma sonda Tentativa Saudável é feita com uma solicitação de tempo limitado para determinar a recuperação.
- Reintegração: Se o teste provisório for bem-sucedido, a partição retornará como Saudável. Caso contrário, permanece insalubre até a próxima sonda.
Esse failover é gerenciado internamente pelo SDK e garante que as solicitações evitem partições com problemas conhecidos até que se confirme que estão íntegras novamente.
Configuração via variáveis de ambiente
Você pode controlar o comportamento do PPCB usando estas variáveis de ambiente:
| Variable | Description | Predefinição |
|---|---|---|
AZURE_COSMOS_ENABLE_CIRCUIT_BREAKER |
Habilita/desabilita o PPCB | false |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_READ |
Número máximo de falhas de leitura consecutivas antes de tornar uma partição indisponível | 10 |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_WRITE |
Número máximo de falhas de gravação consecutivas antes de tornar uma partição indisponível | 5 |
AZURE_COSMOS_FAILURE_PERCENTAGE_TOLERATED |
Percentagem de falha limite antes de marcar uma partição inacessível | 90 |
Tip
Opções de configuração adicionais podem ser disponibilizadas em versões futuras para ajustar as durações de tempo de espera e o atraso na recuperação.
Regiões excluídas
O recurso de regiões excluídas permite um controle refinado sobre o roteamento de solicitações, permitindo que você exclua regiões específicas de seus locais preferidos por solicitação. Esse recurso está disponível no SDK Python do Azure Cosmos DB versão 4.14.0 e superior.
Principais benefícios:
- Limite de taxa de manipulação: ao encontrar 429 respostas (muitas solicitações), encaminhe automaticamente as solicitações para regiões alternativas com taxa de transferência disponível
- Roteamento direcionado: garanta que as solicitações sejam atendidas de regiões específicas, excluindo todas as outras
- Ignorar ordem preferencial: substitua a lista de regiões preferenciais padrão para solicitações individuais sem criar clientes separados
Configuration:
As regiões excluídas podem ser configuradas no nível do cliente e da solicitação:
from azure.cosmos import CosmosClient
from azure.cosmos.partition_key import PartitionKey
# Configure preferred locations and excluded locations at client level
preferred_locations = ['West US 3', 'West US', 'East US 2']
excluded_locations_on_client = ['West US 3', 'West US']
client = CosmosClient(
url=HOST,
credential=MASTER_KEY,
preferred_locations=preferred_locations,
excluded_locations=excluded_locations_on_client
)
database = client.create_database('TestDB')
container = database.create_container(
id='TestContainer',
partition_key=PartitionKey(path="/pk")
)
# Create an item (writes ignore excluded_locations in single-region write accounts)
test_item = {
'id': 'Item_1',
'pk': 'PartitionKey_1',
'test_object': True,
'lastName': 'Smith'
}
created_item = container.create_item(test_item)
# Read operations will use preferred_locations minus excluded_locations
# In this example: ['West US 3', 'West US', 'East US 2'] - ['West US 3', 'West US'] = ['East US 2']
item = container.read_item(
item=created_item['id'],
partition_key=created_item['pk']
)
Regiões excluídas no nível de solicitação:
As regiões excluídas no nível de solicitação têm prioridade máxima e substituem as configurações no nível do cliente:
# Excluded locations can be specified per request, overriding client settings
excluded_locations_on_request = ['West US 3']
# Create item with request-level excluded regions
created_item = container.create_item(
test_item,
excluded_locations=excluded_locations_on_request
)
# Read with request-level excluded regions
# This will use: ['West US 3', 'West US', 'East US 2'] - ['West US 3'] = ['West US', 'East US 2']
item = container.read_item(
item=created_item['id'],
partition_key=created_item['pk'],
excluded_locations=excluded_locations_on_request
)
Ajuste preciso de consistência vs disponibilidade
O recurso de regiões excluídas fornece um mecanismo adicional para equilibrar compensações de consistência e disponibilidade em seu aplicativo. Esta capacidade é particularmente valiosa em cenários dinâmicos em que os requisitos podem mudar com base nas condições operacionais:
Tratamento dinâmico de interrupções: quando uma região primária sofre uma interrupção e os limites do disjuntor no nível da partição se mostram insuficientes, as regiões excluídas permitem failover imediato sem alterações de código ou reinicializações de aplicativos. Isso fornece uma resposta mais rápida a problemas regionais em comparação com a espera pela ativação automática do disjuntor.
Preferências de consistência condicional: os aplicativos podem implementar diferentes estratégias de consistência com base no estado operacional:
- Estado estacionário: priorize leituras consistentes excluindo todas as regiões, exceto a principal, garantindo a consistência dos dados ao custo potencial de disponibilidade
- Cenários de paralisação: favoreça a disponibilidade em detrimento da consistência estrita, permitindo o roteamento entre regiões, aceitando possíveis atrasos de dados em troca de disponibilidade contínua do serviço
Essa abordagem permite que mecanismos externos (como gerenciadores de tráfego ou balanceadores de carga) orquestram decisões de failover enquanto o aplicativo mantém o controle sobre os requisitos de consistência por meio de padrões de exclusão de região.
Quando todas as regiões forem excluídas, as solicitações serão encaminhadas para a região principal/central. Esse recurso funciona com todos os tipos de solicitação, incluindo consultas, e é particularmente útil para manter instâncias de cliente singleton enquanto alcança um comportamento de roteamento flexível.
Utilização do SDK
- Instalar o SDK mais recente
Os SDKs do Azure Cosmos DB estão sendo constantemente aprimorados para fornecer o melhor desempenho. Consulte as notas de versão do SDK do Azure Cosmos DB para determinar o SDK mais recente e revisar as melhorias.
- Use um cliente singleton do Azure Cosmos DB durante o tempo de vida da sua aplicação
Cada instância de cliente do Azure Cosmos DB é thread-safe e realiza um gerenciamento eficiente de conexões e de cacheamento de endereços. Para permitir um gerenciamento de conexão eficiente e um melhor desempenho pelo cliente do Azure Cosmos DB, é recomendável usar uma única instância do cliente do Azure Cosmos DB durante o tempo de vida do aplicativo.
- Ajuste o tempo limite e as configurações de repetição
As configurações de tempo limite e as políticas de repetição podem ser personalizadas com base nas necessidades do aplicativo. Consulte o documento de configuração de tempo limite e novas tentativas para obter uma lista completa de configurações que podem ser personalizadas.
- Use o nível de consistência mais baixo necessário para seu aplicativo
Quando você cria um CosmosClient, a consistência no nível da conta é usada se nenhuma for especificada na criação do cliente. Para obter mais informações sobre níveis de consistência, consulte o documento de níveis de consistência.
- Dimensione a carga de trabalho do cliente
Se estiver a testar a altos níveis de taxa de transferência, o aplicativo cliente pode tornar-se o gargalo devido à máquina atingir o limite de utilização da CPU ou da rede. Se você chegar a esse ponto, poderá continuar a expandir a conta do Azure Cosmos DB ao distribuir seus aplicativos cliente por vários servidores.
Uma boa regra geral é não exceder >50% de utilização da CPU em qualquer servidor, para manter a latência baixa.
- Limite de recursos de arquivos abertos do sistema operativo
Alguns sistemas Linux (como o Red Hat) têm um limite superior no número de arquivos abertos e, portanto, no número total de conexões. Execute o seguinte para exibir os limites atuais:
ulimit -a
O número de arquivos abertos (nofile) precisa ser grande o suficiente para ter espaço suficiente para o tamanho do pool de conexões configurado e outros arquivos abertos pelo sistema operacional. Ele pode ser modificado para permitir um tamanho maior do pool de conexões.
Abra o arquivo limits.conf:
vim /etc/security/limits.conf
Adicione/modifique as seguintes linhas:
* - nofile 100000
Operações de consulta
Para operações de consulta, consulte as dicas de desempenho para consultas.
Política de indexação
- Excluir os caminhos não utilizados da indexação para assegurar escritas mais rápidas
A política de indexação do Azure Cosmos DB permite especificar quais caminhos de documento devem ser incluídos ou excluídos da indexação aproveitando os Caminhos de Indexação (setIncludedPaths e setExcludedPaths). O uso de caminhos de indexação pode oferecer melhor desempenho de gravação e menor armazenamento de índice para cenários nos quais os padrões de consulta são conhecidos de antemão, já que os custos de indexação estão diretamente correlacionados ao número de caminhos exclusivos indexados. Por exemplo, o código a seguir mostra como incluir e excluir seções inteiras dos documentos (também conhecida como subárvore) da indexação usando o curinga "*".
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Para obter mais informações, consulte Políticas de indexação do Azure Cosmos DB.
Capacidade de processamento
- Meça e ajuste para reduzir o uso de unidades de requisição por segundo
O Azure Cosmos DB oferece um conjunto avançado de operações de banco de dados, incluindo consultas relacionais e hierárquicas com UDFs, procedimentos armazenados e gatilhos, todos operando nos documentos de uma coleção de banco de dados. O custo associado a cada uma destas operações varia com base na CPU, E/S e memória necessárias para concluir a operação. Em vez de pensar e gerenciar recursos de hardware, você pode pensar em uma unidade de solicitação (RU) como uma única medida para os recursos necessários para executar várias operações de banco de dados e atender a uma solicitação de aplicativo.
A taxa de transferência é provisionada com base no número de unidades de solicitação definidas para cada contentor. O consumo unitário de solicitação é avaliado como uma taxa por segundo. Os aplicativos que excedem a taxa unitária de solicitação provisionada para seu contêiner são limitados até que a taxa caia abaixo do nível provisionado para o contêiner. Se seu aplicativo exigir um nível mais alto de taxa de transferência, você poderá aumentar sua taxa de transferência provisionando unidades de solicitação adicionais.
A complexidade de uma consulta afeta quantas unidades de solicitação são consumidas para uma operação. O número de predicados, a natureza dos predicados, o número de UDFs e o tamanho do conjunto de dados de origem influenciam o custo das operações de consulta.
Para medir a sobrecarga de qualquer operação (criar, atualizar ou excluir), inspecione o cabeçalho x-ms-request-charge para medir o número de unidades de solicitação consumidas por essas operações.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
O custo de solicitação retornado neste cabeçalho é uma fração da taxa de transferência provisionada. Por exemplo, se você tiver 2000 RU/s provisionados e se a consulta anterior retornar 1000 documentos de 1KB, o custo da operação será 1000. Como tal, dentro de um segundo, o servidor honra apenas duas dessas solicitações antes de limitar as solicitações subsequentes. Para obter mais informações, consulte Unidades de Solicitação e a Calculadora de Unidades de Solicitação.
- Lidar com limitação de taxa / taxa de solicitação muito grande
Quando um cliente tenta exceder a taxa de transferência reservada para uma conta, não há degradação de desempenho no servidor e nenhum uso da capacidade de taxa de transferência além do nível reservado. O servidor terminará preventivamente a solicitação com RequestRateTooLarge (código de status HTTP 429) e retornará o cabeçalho x-ms-retry-after-ms indicando a quantidade de tempo, em milissegundos, que o usuário deve aguardar antes de tentar novamente a solicitação.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Todos os SDKs capturam implicitamente essa resposta, respeitam o cabeçalho retry-after especificado pelo servidor e tentam novamente a solicitação. A menos que sua conta esteja sendo acessada simultaneamente por vários clientes, a próxima tentativa será bem-sucedida.
Se você tiver mais de um cliente operando cumulativamente acima da taxa de solicitação, a contagem de tentativas padrão atualmente definida como 9 internamente pelo cliente pode não ser suficiente; nesse caso, o cliente lança um CosmosHttpResponseError com o código de status 429 para o aplicativo. A contagem de tentativas padrão pode ser alterada passando retry_total a configuração para o cliente. Por padrão, o CosmosHttpResponseError com o código de status 429 é retornado após um tempo de espera cumulativo de 30 segundos se a solicitação continuar a operar acima da taxa de solicitação. Isso ocorre mesmo quando a contagem de tentativas atual é menor do que a contagem máxima de tentativas, seja o padrão de 9 ou um valor definido pelo usuário.
Embora o comportamento de repetição automatizada ajude a melhorar a resiliência e a usabilidade para a maioria dos aplicativos, ele pode entrar em desacordo ao fazer benchmarks de desempenho, especialmente ao medir a latência. A latência observada pelo cliente aumentará se o experimento atingir o limite do servidor e fizer com que o SDK do cliente tente novamente de forma silenciosa. Para evitar picos de latência durante experimentos de desempenho, meça a carga retornada por cada operação e verifique se as solicitações estão operando abaixo da taxa de solicitação reservada. Para obter mais informações, consulte Unidades de solicitação.
- Design de documentos menores para maior eficiência
A taxa de solicitação (o custo de processamento da solicitação) de uma determinada operação está diretamente correlacionada com o tamanho do documento. As operações em documentos grandes custam mais do que as operações em documentos pequenos. Idealmente, arquitete seu aplicativo e fluxos de trabalho para que o tamanho do item seja de ~1KB, ou ordem ou magnitude semelhante. Para aplicativos sensíveis à latência, itens grandes devem ser evitados - documentos de vários MB tornarão seu aplicativo mais lento.
Passos seguintes
Para saber mais sobre como desenhar a sua aplicação para escala e alto desempenho, consulte Particionamento e escalonamento em Azure Cosmos DB.
Tentando fazer o planejamento de capacidade para uma migração para o Azure Cosmos DB? Você pode usar informações sobre seu cluster de banco de dados existente para planejamento de capacidade.
- Se tudo o que você sabe é o número de vCores e servidores em seu cluster de banco de dados existente, leia sobre como estimar unidades de solicitação usando vCores ou vCPUs
- Se você souber as taxas de solicitação típicas para sua carga de trabalho de banco de dados atual, leia sobre como estimar unidades de solicitação usando o planejador de capacidade do Azure Cosmos DB