Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugestão
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a atividade "Copy Activity" no Azure Data Factory e nos pipelines do Synapse Analytics para copiar dados de e para uma base de dados do Azure para PostgreSQL. E, como usar o Fluxo de Dados para transformar dados no Banco de Dados do Azure para PostgreSQL. Para saber mais, leia os artigos introdutórios do Azure Data Factory e do Synapse Analytics.
Importante
O Banco de Dados do Azure para PostgreSQL versão 2.0 fornece suporte aprimorado ao Banco de Dados do Azure nativo para PostgreSQL. Se você estiver usando o Banco de Dados do Azure para PostgreSQL versão 1.0 em sua solução, é recomendável atualizar seu Banco de Dados do Azure para o conector PostgreSQL o mais rápido possível.
Esse conector é especializado para o serviço Banco de Dados do Azure para PostgreSQL. Para copiar dados de um banco de dados PostgreSQL genérico localizado no local ou na nuvem, use o conector PostgreSQL.
Capacidades suportadas
Este conector do Banco de Dados do Azure para PostgreSQL tem suporte para os seguintes recursos:
| Capacidades suportadas | IR | Endpoint privado gerido | Versões suportadas pelo conector |
|---|---|---|---|
| Atividade de cópia (origem/destino) | (1) (2) | ✓ | 1,0 & 2,0 |
| Mapeamento do fluxo de dados (origem/destino) | (1) | ✓ | 1,0 & 2,0 |
| Atividade de Pesquisa | (1) (2) | ✓ | 1,0 & 2,0 |
| Atividade de script | (1) (2) | ✓ | 2.0 |
(1) Infraestrutura de integração do Azure (2) Infraestrutura de integração auto-hospedada
As três atividades funcionam no Banco de Dados do Azure para PostgreSQL Single Server, Servidor Flexível e Azure Cosmos DB para PostgreSQL.
Importante
O Banco de Dados do Azure para PostgreSQL Single Server será desativado em 28 de março de 2025. Migre para o Servidor Flexível até essa data. Você pode consultar este artigo e as Perguntas frequentes para obter as diretrizes de migração.
Como Começar
Para executar a atividade de cópia com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- Ferramenta Copiar dados
- portal do Azure
- SDK do .NET
- Python SDK
- Azure PowerShell
- API REST
- Modelo Azure Resource Manager
Criar um serviço vinculado ao Banco de Dados do Azure para PostgreSQL usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao banco de dados do Azure para PostgreSQL na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e, em seguida, selecione Novo:
Pesquise PostgreSQL e selecione o banco de dados do Azure para conector PostgreSQL.
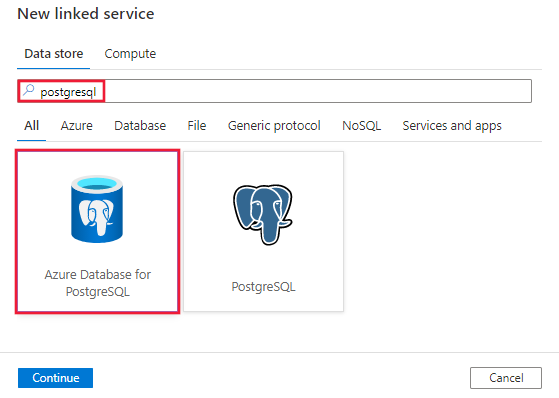
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
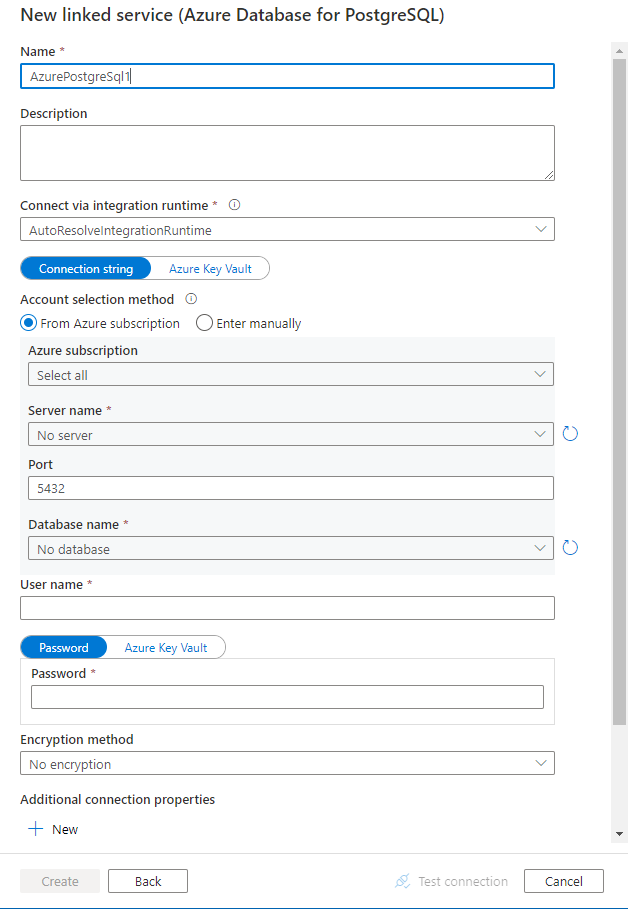
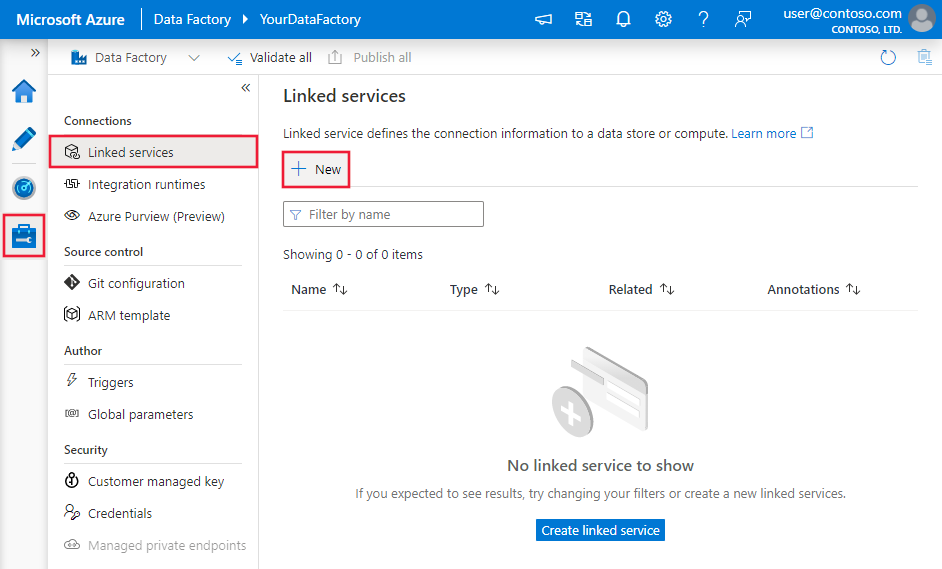
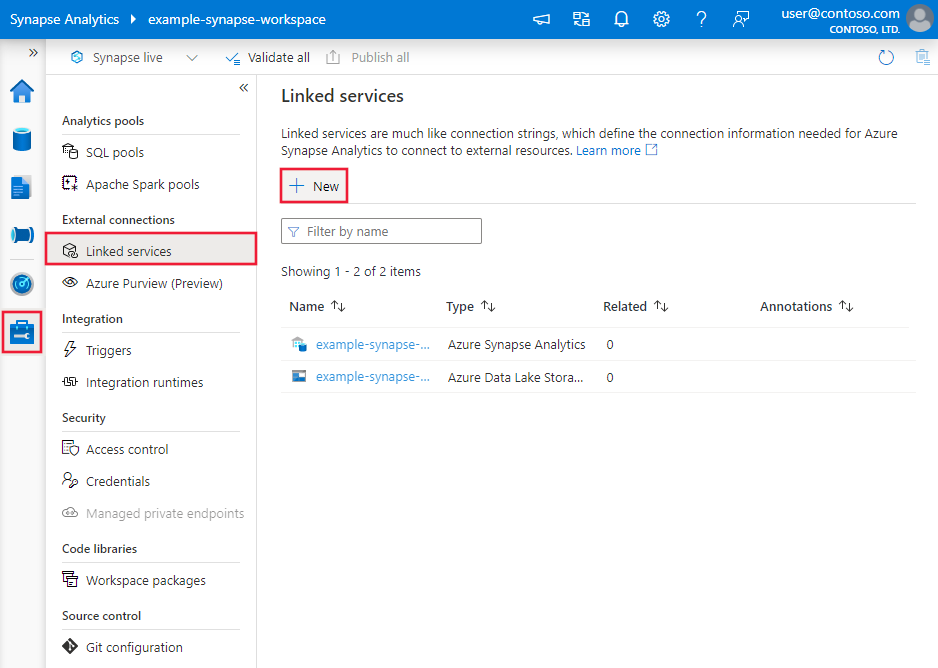
Detalhes de configuração do conector
As seções a seguir oferecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas para o conector do Banco de Dados do Azure para PostgreSQL.
Propriedades do serviço vinculado
O conector do Banco de Dados do Azure para PostgreSQL versão 2.0 dá suporte ao Transport Layer Security (TLS) 1.3 e a vários modos SSL (Secured Socket Layer). Consulte esta seção para atualizar sua versão do conector do Banco de Dados SQL do Azure da versão 1.0. Para obter os detalhes da propriedade, consulte as seções correspondentes.
Versão 2.0
As seguintes propriedades são suportadas para o serviço associado Azure Database for PostgreSQL ao aplicar a versão 2.0:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como: AzurePostgreSql. | Sim |
| versão | A versão que especificares. O valor é 2.0. |
Sim |
| tipo de autenticação | Selecione entre tipos de autenticação básica, principal de serviço, identidade gerenciada atribuída pelo sistema ou identidade gerenciada atribuída pelo usuário. | Sim |
| servidor | Especifica o nome do host e, opcionalmente, a porta na qual o Banco de Dados do Azure para PostgreSQL está sendo executado. | Sim |
| porta | A porta TCP do Banco de Dados do Azure para servidor PostgreSQL. O valor predefinido é 5432. |
Não |
| base de dados | O nome do Banco de Dados do Azure para banco de dados PostgreSQL ao qual se conectar. | Sim |
| modo SSL | Controla se o SSL é usado, dependendo do suporte ao servidor. - Desativar: SSL está desativado. Se o servidor requer SSL, a conexão falha. - Permitir: Prefira conexões não SSL se o servidor permitir, mas permita conexões SSL. - Preferir: Prefira conexões SSL se o servidor permitir, mas permita conexões sem SSL. - Exigir: A conexão falhará se o servidor não suportar SSL. - Verify-ca: A conexão falhará se o servidor não suportar SSL. Também verifica o certificado do servidor. - Verificação completa: A conexão falhará se o servidor não suportar SSL. Também verifica o certificado do servidor com o nome do host. Opções: Desativar (0) / Permitir (1) / Preferir (2) (Padrão) / Exigir (3) / Verificar-ca (4) / Verificar-completo (5) |
Não |
| ConecteVia | Essa propriedade representa o tempo de execução de integração a ser usado para se conectar ao repositório de dados. Você pode usar o Azure Integration Runtime ou o Self-hosted Integration Runtime (se seu armazenamento de dados estiver localizado em rede privada). Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
| Propriedades de conexão adicionais: | ||
| esquema | Define o caminho de pesquisa do esquema. | Não |
| Agrupamento | Se o pool de conexões deve ser usado. | Não |
| tempo de espera da conexão | O tempo de espera (em segundos) ao tentar estabelecer uma conexão antes de encerrar a tentativa e gerar um erro. | Não |
| commandTimeout | O tempo de espera (em segundos) ao tentar executar um comando antes de encerrar a tentativa e gerar um erro. Defina para zero para obter o infinito. | Não |
| trustServerCertificate | Se o certificado do servidor deve ser confiado sem validá-lo. | Não |
| tamanho do buffer de leitura | Determina o tamanho do buffer interno que o Npgsql usa durante a leitura. Aumentar o tamanho pode melhorar o desempenho ao transferir grandes valores do banco de dados. | Não |
| Fuso horário | Obtém ou define o fuso horário da sessão. | Não |
| codificação | Obtém ou define a codificação .NET para codificação/decodificação de dados de cadeia de caracteres PostgreSQL. | Não |
autenticação Básica
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| nome de utilizador | O nome de usuário com o qual se conectar. Não é necessário se estiver usando IntegratedSecurity. | Sim |
| palavra-passe | A senha com a qual se conectar. Não é necessário se estiver usando IntegratedSecurity. Marque este campo como SecureString para armazená-lo com segurança. Ou, você pode fazer referência a um segredo armazenado no Cofre da Chave do Azure. | Sim |
Exemplo:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Exemplo:
Armazenar palavra-passe no Cofre da Chave do Azure
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Autenticação de identidade gerenciada atribuída pelo sistema
Uma fábrica de dados ou um espaço de trabalho Synapse pode ser associado a uma identidade gerenciada atribuída pelo Sistema que representa o serviço ao autenticar outros recursos no Azure. Você pode usar essa identidade gerenciada para o banco de dados do Azure para autenticação PostgreSQL. A fábrica designada ou o espaço de trabalho Synapse pode acessar e copiar dados de ou para seu banco de dados usando essa identidade.
Para usar a identidade gerenciada atribuída ao sistema, siga as etapas:
Uma fábrica de dados ou um espaço de trabalho Synapse pode ser associado a uma identidade gerenciada atribuída ao sistema. Saiba mais, Gerar identidade gerenciada atribuída ao sistema
Os dados do Azure para PostgreSQL com identidade gerida atribuída pelo sistema On.

No seu recurso Banco de Dados do Azure para PostgreSQL em Segurança
Selecione Autenticação
Selecione o método de autenticação somente do Microsoft Entra ou de autenticação do PostgreSQL e do Microsoft Entra.
Selecione + Adicionar administradores do Microsoft Entra
Adicione a identidade gerida atribuída pelo sistema ao recurso Azure Data Factory, tornando-a um dos Administradores do Microsoft Entra.

Configure um banco de dados do Azure para o serviço vinculado PostgreSQL.


Exemplo:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "SystemAssignedManagedIdentity"
}
}
}
Observação
Esse tipo de autenticação não é suportado no tempo de execução de integração auto-hospedado.
Autenticação de identidade gerenciada atribuída pelo usuário
Um Data Factory ou espaço de trabalho Synapse pode ser associado a uma identidade gerida atribuída pelo utilizador que representa o serviço ao autenticar-se junto a outros recursos no Azure. Você pode usar essa identidade gerenciada para o banco de dados do Azure para autenticação PostgreSQL. A fábrica designada ou o espaço de trabalho Synapse pode acessar e copiar dados de ou para seu banco de dados usando essa identidade.
Para usar a autenticação de identidade gerenciada atribuída pelo usuário, além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| credencial | Especifique a identidade gerenciada atribuída pelo usuário como o objeto de credencial. | Sim |
Você também precisa seguir as etapas:
Certifique-se de criar um recurso de Identidade Gerenciada Atribuída pelo Usuário no portal do Azure. Para saber mais, vá para Gerenciar identidades gerenciadas atribuídas pelo usuário
Atribuir a Identidade Gerenciada atribuída pelo Usuário ao seu banco de dados do Azure para o recurso PostgreSQL
Em seu banco de dados do Azure para recurso de servidor PostgreSQL, em Segurança
Selecione Autenticação
Verifique se o método de autenticação é apenas autenticação do Microsoft Entra ou autenticação do PostgreSQL e do Microsoft Entra
Selecione + Adicionar link de administradores do Microsoft Entra e selecione sua identidade gerenciada atribuída pelo usuário

Atribuir a Identidade Gerenciada atribuída pelo Usuário ao seu recurso do Azure Data Factory
Selecione Configurações e, em seguida, Identidades gerenciadas
Na guia Usuário atribuído . Selecione o link + Adicionar e selecione sua identidade gerenciada pelo usuário

Configure um banco de dados do Azure para o serviço vinculado PostgreSQL.


Exemplo:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "<your credential>",
"type": "CredentialReference"
}
}
}
}
Autenticação do Service Principal
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| nome de utilizador | O nome para exibição da entidade de serviço | Sim |
| inquilino | O locatário no qual o Banco de Dados do Azure para servidor PostgreSQL está localizado | Sim |
| ID do Serviço Principal | ID do aplicativo da entidade de serviço | Sim |
| Tipo de Credencial do Principal de Serviço | Selecione se o certificado da entidade de serviço ou a chave da entidade de serviço é o método de autenticação desejado - ServicePrincipalCert: Defina como certificado de entidade de serviço para certificado de entidade de serviço. - ServicePrincipalKey: Defina como chave do principal do serviço para autenticação pela chave do principal do serviço. |
Sim |
| chavePrincipalDoServiço | Valor secreto do cliente. Usado quando a chave principal de serviço é selecionada | Sim |
| azureCloudType | Selecione o tipo de nuvem do Azure do seu Banco de Dados do Azure para servidor PostgreSQL | Sim |
| serviçoPrincipalEmbeddedCert | Arquivo de certificado da entidade de serviço | Sim |
| servicePrincipalEmbeddedCertPassword | Palavra-passe do certificado da entidade de serviço, quando necessário | Não |
Exemplo:
Chave da entidade de serviço
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalKey": "<service principal key>"
}
}
}
Exemplo:
Certificado de principal de serviço
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalEmbeddedCert": "<service principal certificate>",
"servicePrincipalEmbeddedCertPassword": "<service principal embedded certificate password>"
}
}
}
Observação
A autenticação do Microsoft Entra ID utilizando uma identidade gerida atribuída a utilizador e entidade de serviço é suportada no runtime de integração auto-hospedado versão 5.50 ou superior.
Versão 1.0
As seguintes propriedades têm suporte para o serviço vinculado Banco de Dados do Azure para PostgreSQL quando você aplica a versão 1.0:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como: AzurePostgreSql. | Sim |
| versão | A versão que especificares. O valor é 1.0. |
Sim |
| string de conexão | Uma cadeia de conexão Npgsql para se conectar ao Banco de Dados do Azure para PostgreSQL. Você também pode colocar uma senha no Cofre de Chaves do Azure e extrair a password configuração da cadeia de conexão. Consulte os seguintes exemplos e Armazenar credenciais no Azure Key Vault para obter mais detalhes. |
Sim |
| ConecteVia | Essa propriedade representa o tempo de execução de integração a ser usado para se conectar ao repositório de dados. Você pode usar o Azure Integration Runtime ou o Self-hosted Integration Runtime (se seu armazenamento de dados estiver localizado em rede privada). Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
Uma cadeia de conexão típica é host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>. Aqui estão mais propriedades que você pode definir de acordo com o seu caso:
| Propriedade | Descrição | Opções | Obrigatório |
|---|---|---|---|
| Método de criptografia (EM) | O método que o driver usa para criptografar dados enviados entre o driver e o servidor de banco de dados. Por exemplo, EncryptionMethod=<0/1/6>; |
0 (Sem criptografia) (padrão) / 1 (SSL) / 6 (RequestSSL) | Não |
| ValidateServerCertificate (VSC) | Determina se o driver valida o certificado enviado pelo servidor de banco de dados quando a criptografia SSL está habilitada (Método de Criptografia=1). Por exemplo, ValidateServerCertificate=<0/1>; |
0 (Desativado) (Padrão) / 1 (Habilitado) | Não |
Exemplo:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>"
}
}
}
Exemplo:
Armazenar palavra-passe no Cofre da Chave do Azure
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte Conjuntos de dados. Esta seção fornece uma lista de propriedades que o Banco de Dados do Azure para PostgreSQL oferece suporte em conjuntos de dados.
Para copiar dados do Banco de Dados do Azure para PostgreSQL, defina a propriedade type do conjunto de dados como AzurePostgreSqlTable. As seguintes propriedades são suportadas:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como AzurePostgreSqlTable. | Sim |
| esquema | Nome do esquema. | Não (caso "consulta" esteja especificada na fonte da atividade) |
| tabela | Nome da tabela/vista. | Não (caso "consulta" esteja especificada na fonte da atividade) |
| nome da tabela | Nome da tabela. Esta propriedade é suportada para compatibilidade com versões anteriores. Para nova carga de trabalho, use schema e table. |
Não (caso "consulta" esteja especificada na fonte da atividade) |
Exemplo:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte Pipelines e atividades. Esta seção fornece uma lista de propriedades suportadas por um Banco de Dados do Azure para fonte PostgreSQL.
Banco de Dados do Azure para PostgreSql como origem
Para copiar dados do Banco de Dados do Azure para PostgreSQL, defina o tipo de origem na atividade de cópia como AzurePostgreSqlSource. As seguintes propriedades são suportadas na seção de origem da atividade de cópia:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como AzurePostgreSqlSource | Sim |
| consulta | Utilize a consulta SQL personalizada para ler os dados. Por exemplo: SELECT * FROM mytable ou SELECT * FROM "MyTable". Observação: no PostgreSQL, o nome da entidade é tratado como sem distinção entre maiúsculas e minúsculas se não for citado. |
Não (se a propriedade tableName no conjunto de dados for especificada) |
| tempo de espera da consulta | O tempo de espera antes de encerrar a tentativa de executar um comando e gerar um erro, o padrão é de 120 minutos. Se o parâmetro for definido para essa propriedade, os valores permitidos serão de intervalo de tempo, como "02:00:00" (120 minutos). Para obter mais informações, consulte CommandTimeout. | Não |
| opçõesDePartição | Especifica as opções de particionamento de dados usadas para carregar dados do Banco de Dados SQL do Azure. Os valores permitidos são: None (padrão), PhysicalPartitionsOfTable e DynamicRange. Quando uma opção de partição é ativada (ou seja, não None), o grau de paralelismo para carregar simultaneamente dados de uma base de dados SQL do Azure é controlado pela configuração parallelCopies na atividade de cópia. |
Não |
| definições de partição | Especifique o grupo de configurações para particionamento de dados. Aplique quando a opção de partição não for None. |
Não |
Em partitionSettings: |
||
| nomes de partições | A lista de partições físicas que precisam ser copiadas. Aplique quando a opção de partição for PhysicalPartitionsOfTable. Se utilizar uma consulta para recuperar os dados de origem, insira ?AdfTabularPartitionName na cláusula WHERE. Para obter um exemplo, consulte a seção Cópia paralela do Banco de Dados do Azure para PostgreSQL . |
Não |
| nomeDaColunaDePartição | Especifique o nome da coluna de origem do tipo inteiro ou data/datetime (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone, ou time without time zone) que será usado pelo particionamento de intervalo para cópia paralela. Se não for especificado, a chave primária da tabela será detetada automaticamente e usada como coluna de partição.Aplique quando a opção de partição for DynamicRange. Se utilizar uma consulta para recuperar os dados de origem, insira ?AdfRangePartitionColumnName na cláusula WHERE. Para obter um exemplo, consulte a seção Cópia paralela do Banco de Dados do Azure para PostgreSQL . |
Não |
| limiteSuperiorDePartição | O valor máximo da coluna de partição para exportar dados. Aplique quando a opção de partição for DynamicRange. Se utilizar uma consulta para recuperar os dados de origem, insira ?AdfRangePartitionUpbound na cláusula WHERE. Para obter um exemplo, consulte a seção Cópia paralela do Banco de Dados do Azure para PostgreSQL . |
Não |
| limiteInferiorDaPartição | O valor mínimo da coluna de partição para copiar dados. Aplique quando a opção de partição for DynamicRange. Se utilizar uma consulta para recuperar os dados de origem, insira ?AdfRangePartitionLowbound na cláusula WHERE. Para obter um exemplo, consulte a seção Cópia paralela do Banco de Dados do Azure para PostgreSQL . |
Não |
Exemplo:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Banco de Dados do Azure para PostgreSQL como coletor
Para copiar dados para o Banco de Dados do Azure para PostgreSQL, defina o tipo de coletor na atividade de cópia como SqlSink. As seguintes propriedades são suportadas na seção coletor de atividade de cópia:
| Propriedade | Descrição | Obrigatório | Versão de suporte para conectores |
|---|---|---|---|
| tipo | A propriedade type do coletor de atividade de cópia deve ser definida como AzurePostgreSQLSink. | Sim | Versão 1.0 & Versão 2.0 |
| PreCopyScript | Especifique uma consulta SQL para a atividade de cópia a ser executada antes de gravar dados no Banco de Dados do Azure para PostgreSQL em cada execução. Você pode usar essa propriedade para limpar os dados pré-carregados. | Não | Versão 1.0 & Versão 2.0 |
| writeMethod | O método usado para gravar dados no Banco de Dados do Azure para PostgreSQL. Os valores permitidos são: CopyCommand (padrão, que é mais eficiente), BulkInsert e Upsert (somente versão 2.0). |
Não | Versão 1.0 & Versão 2.0 |
| upsertSettings | Especifique o grupo de configurações para o comportamento de gravação. Aplique quando a opção WriteBehavior for Upsert. |
Não | Versão 2.0 |
Em upsertSettings: |
|||
| Teclas | Especifique os nomes das colunas para identificação de linha exclusiva. Uma única chave ou uma série de chaves podem ser usadas. As chaves devem ser uma chave primária ou uma coluna exclusiva. Se não for especificado, a chave primária será usada. | Não | Versão 2.0 |
| writeBatchSize | O número de linhas carregadas no Banco de Dados do Azure para PostgreSQL por lote. O valor permitido é um número inteiro que representa o número de linhas. |
Não (o padrão é 1.000.000) | Versão 1.0 & Versão 2.0 |
| writeBatchTimeout | Aguarde o tempo para que a operação de inserção em lote seja concluída antes de atingir o tempo limite. Os valores permitidos são cadeias de caracteres Timespan. Um exemplo é 00:30:00 (30 minutos). |
Não (o padrão é 00:30:00) | Versão 1.0 & Versão 2.0 |
Exemplo 1: Comando Copiar
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSqlSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Exemplo 2: Inserir ou atualizar dados (Upsert)
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"writeMethod": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
]
},
}
}
}
]
Atualizar ou inserir dados
A atividade de cópia suporta nativamente operações de upsert. Para executar um upsert, o usuário deve fornecer coluna(s) de chave que são chaves primárias ou colunas exclusivas. Se o usuário não fornecer coluna(s) de chave, então a(s) coluna(s) de chave primária na tabela de coletor serão usadas. A Atividade de Cópia atualizará a(s) coluna(s) não-chave(s) na tabela do coletor onde o(s) valor(es) da(s) coluna(s) chave(s) corresponde(m) aos da tabela de origem; caso contrário, inserirá novos dados.
Cópia paralela do Banco de Dados do Azure para PostgreSQL
O conector do Banco de Dados do Azure para PostgreSQL na atividade de cópia fornece particionamento de dados integrado para copiar dados em paralelo. Você pode encontrar opções de particionamento de dados na guia Origem da atividade de cópia.
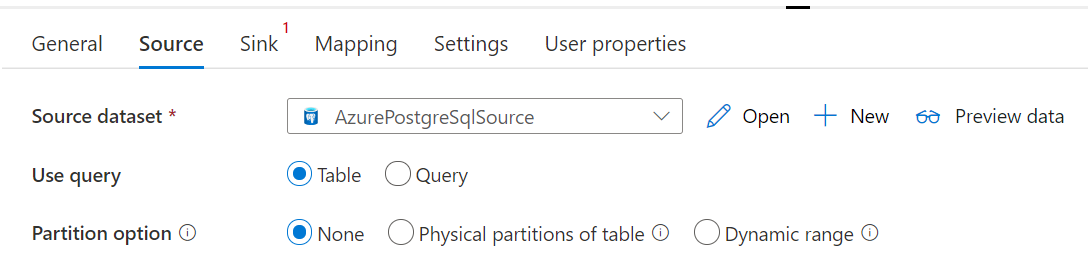
Quando você habilita a cópia particionada, a atividade de cópia executa consultas paralelas no Banco de Dados do Azure para a fonte PostgreSQL para carregar dados por partições. O grau de paralelismo é controlado pela configuração parallelCopies na atividade de cópia. Por exemplo, se você definir parallelCopies como quatro, o serviço gerará e executará simultaneamente quatro consultas com base na opção e nas configurações de partição especificadas, e cada consulta recuperará uma parte dos dados do Banco de Dados do Azure para PostgreSQL.
Sugere-se que você habilite a cópia paralela com particionamento de dados, especialmente quando carrega uma grande quantidade de dados do Banco de Dados do Azure para PostgreSQL. A seguir estão sugeridas configurações para diferentes cenários. Ao copiar dados para o armazenamento de dados baseado em arquivo, a recomendação é gravar em uma pasta como vários arquivos (especifique apenas o nome da pasta), caso em que o desempenho é melhor do que gravar em um único arquivo.
| Cenário | Configurações sugeridas |
|---|---|
| Carga completa a partir de uma tabela grande, com partições físicas. |
Opção de partição: Partições físicas da tabela. Durante a execução, o serviço deteta automaticamente as partições físicas e copia os dados por partições. |
| Carga completa de uma tabela grande, sem partições físicas, mas com uma coluna inteira para particionamento de dados. |
Opções de partição: Partição de intervalo dinâmico. Coluna de partição: especifique a coluna usada para particionar dados. Se não for especificado, a coluna de chave primária será usada. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, com partições físicas. |
Opção de partição: Partições físicas da tabela. Consulta: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Nome da partição: especifique um ou mais nomes de partição dos quais copiar dados. Se não for especificado, o serviço detetará automaticamente as partições físicas na tabela especificada no conjunto de dados PostgreSQL. Durante a execução, o serviço substitui ?AdfTabularPartitionName pelo nome real da partição e envia para o Banco de Dados do Azure para PostgreSQL. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, sem partições físicas, mas com uma coluna de inteiro para particionamento de dados. |
Opções de partição: Partição de intervalo dinâmico. Consulta: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Coluna de partição: especifique a coluna usada para particionar dados. Você pode particionar a coluna com tipo de dados inteiro ou data/hora. Limite superior da partição e limite inferior da partição: especifique se deseja filtrar a coluna da partição para recuperar dados apenas entre o intervalo inferior e superior. Durante a execução, o serviço substitui ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbounde ?AdfRangePartitionLowbound com o nome da coluna real e intervalos de valores para cada partição, e envia para o Banco de Dados do Azure para PostgreSQL. Por exemplo, se a coluna de partição "ID" estiver definida com o limite inferior como 1 e o limite superior como 80, com cópia paralela definida como 4, o serviço recuperará dados por quatro partições. Os seus IDs situam-se entre [1,20], [21, 40], [41, 60] e [61, 80], respetivamente. |
Práticas recomendadas para carregar dados com a opção de partição:
- Escolha uma coluna distinta como coluna de partição (como chave primária ou chave exclusiva) para evitar distorção de dados.
- Se a tabela tiver partição incorporada, use a opção de partição "Partições físicas da tabela" para obter um melhor desempenho.
- Se você usar o Tempo de Execução de Integração do Azure para copiar dados, poderá definir "Unidades de Integração de Dados (DIU)" (>4) maiores para utilizar mais recursos de computação. Verifique os cenários aplicáveis lá.
- "Grau de paralelismo de cópia controla os números de partição; definir um número muito grande às vezes prejudica o desempenho." Recomendo definir este número como (DIU ou número de nós IR auto-hospedados) * (2 a 4).
Exemplo: carga completa de tabela grande com partições físicas
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exemplo: consulta com partição de intervalo dinâmico
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Mapeando propriedades de fluxo de dados
Ao transformar dados num fluxo de dados de mapeamento, é possível ler e gravar em tabelas do Azure Database para PostgreSQL. Para obter mais informações, consulte a transformação de origem e transformação de destino no mapeamento de fluxos de dados. Você pode optar por usar um banco de dados do Azure para conjunto de dados PostgreSQL ou um conjunto de dados embutido como tipo de fonte e coletor.
Observação
Atualmente, apenas a autenticação básica é suportada para as versões V1 e V2 do conector do Banco de Dados do Azure para PostgreSQL em Mapeando Fluxos de Dados.
Transformação da fonte
A tabela abaixo lista as propriedades suportadas pelo Banco de Dados do Azure para a origem do PostgreSQL. Você pode editar essas propriedades na guia Opções de origem .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Tabela | Se você selecionar Tabela como entrada, o fluxo de dados buscará todos os dados da tabela especificada no conjunto de dados. | Não | - |
(apenas para conjunto de dados integrado) nome da tabela |
| Pergunta | Se você selecionar Consulta como entrada, especifique uma consulta SQL para buscar dados da origem, que substituirá qualquer tabela especificada no conjunto de dados. Usar consultas é uma ótima maneira de reduzir linhas para testes ou pesquisas. A cláusula Order By não é suportada, mas você pode definir uma instrução SELECT FROM completa. Você também pode usar funções de tabela definidas pelo usuário. select * from udfGetData() é um UDF em SQL que retorna uma tabela que você pode usar no fluxo de dados. Exemplo de consulta: select * from mytable where customerId > 1000 and customerId < 2000 ou select * from "MyTable". Observação: no PostgreSQL, o nome da entidade é tratado como sem distinção entre maiúsculas e minúsculas se não for citado. |
Não | Cordão | consulta |
| Nome do esquema | Se você selecionar Procedimento armazenado como entrada, especifique um nome de esquema do procedimento armazenado ou selecione Atualizar para solicitar que o serviço descubra os nomes do esquema. | Não | Cordão | nomeDoEsquema |
| Procedimento armazenado | Se você selecionar Procedimento armazenado como entrada, especifique um nome do procedimento armazenado para ler dados da tabela de origem ou selecione Atualizar para solicitar que o serviço descubra os nomes dos procedimentos. | Sim (se você selecionar Procedimento armazenado como entrada) | Cordão | nome procedimento |
| Parâmetros do procedimento | Se você selecionar Procedimento armazenado como entrada, especifique quaisquer parâmetros de entrada para o procedimento armazenado na ordem definida no procedimento ou selecione Importar para importar todos os parâmetros do procedimento usando o formulário @paraName. |
Não | Matriz | Insumos |
| Tamanho do lote | Especifique um tamanho de lote para fragmentar dados grandes em lotes. | Não | Número inteiro | tamanho de batch |
| Nível de isolamento | Escolha um dos seguintes níveis de isolamento: - Ler Comprometido - Ler Não confirmado (padrão) - Leitura repetível - Serializável - Nenhum (ignorar o nível de isolamento) |
Não | LEITURA_CONFIRMADA READ_UNCOMMITTED (Leitura Não Confirmada) Leitura Repetível SERIALIZÁVEL NENHUM |
Nível de isolamento |
Exemplo de script de origem do Banco de Dados do Azure para PostgreSQL
Quando você usa o Banco de Dados do Azure para PostgreSQL como tipo de origem, o script de fluxo de dados associado é:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Transformação do lavatório
A tabela abaixo lista as propriedades suportadas pelo coletor do Banco de Dados do Azure para PostgreSQL. Você pode editar essas propriedades no separador Opções do Sink.
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Método de atualização | Especifique quais operações são permitidas no destino do banco de dados. O padrão é permitir apenas inserções. Para atualizar, inserir ou excluir linhas, uma transformação Alter row é necessária para marcar linhas para essas ações. |
Sim |
true ou false |
eliminável inserível atualizável Inserção-Atualização |
| Colunas-chave | Para atualizações, upserts e exclusões, as colunas de chave devem ser definidas para determinar qual linha alterar. O nome da coluna que escolher como chave é usado como parte da atualização subsequente, inserção/atualização e exclusão. Portanto, você deve escolher uma coluna que existe no mapeamento de coletor. |
Não | Matriz | Teclas |
| Ignorar colunas chave | Se não desejar escrever o valor na coluna-chave, selecione "Ignorar a escrita das colunas-chave". | Não |
true ou false |
ignorarEscritasChave |
| Ação de tabela | Determina se todas as linhas da tabela de destino devem ser recriadas ou removidas antes de escrever. - Nenhuma: Nenhuma ação é feita na tabela. - Recriar: A tabela é descartada e recriada. Necessário caso crie uma nova tabela de forma dinâmica. - Truncate: Todas as linhas da tabela de destino são removidas. |
Não |
true ou false |
recriar truncar |
| Tamanho do lote | Especifique quantas linhas estão sendo escritas em cada lote. Lotes maiores melhoram a compactação e a otimização da memória, mas correm o risco de exceções de falta de memória ao armazenar dados em cache. | Não | Número inteiro | tamanho de batch |
| Selecionar esquema de banco de dados do usuário | Por padrão, uma tabela temporária é criada sob o esquema de coletor como preparação. Como alternativa, você pode desmarcar a opção Usar esquema de coletor e, em vez disso, especificar um nome de esquema sob o qual o Data Factory cria uma tabela de preparo para carregar dados upstream e limpá-los automaticamente após a conclusão. Verifique se você tem permissão para criar tabela no banco de dados e alterar permissão no esquema. | Não | Cordão | nomeDoEsquemaDeTransição |
| Scripts pré e pós SQL | Especifique scripts SQL de várias linhas que serão executados antes (pré-processamento) e depois que os dados (pós-processamento) forem gravados no banco de dados do coletor. | Não | Cordão | pré-SQLs postSQLs |
Sugestão
- Divida scripts de um único lote que contêm vários comandos em múltiplos lotes.
- Somente instruções DDL (Data Definition Language) e DML (Data Manipulation Language) que retornam uma contagem de atualização simples podem ser executadas como parte de um lote. Saiba mais em Executando operações em lote
Habilitar extração incremental: use esta opção para configurar o ADF para processar apenas as linhas que mudaram desde a última execução do pipeline.
Coluna incremental: Ao usar o recurso de extração incremental, deve-se escolher a coluna de data/hora ou a coluna numérica que se deseja usar como marca d'água na tabela de origem.
Comece a ler desde o início: definir essa opção com extração incremental instrui o ADF a ler todas as linhas na primeira execução de um pipeline com a extração incremental ativada.
Exemplo de script de coletor do Banco de Dados do Azure para PostgreSQL
Ao utilizar o Azure Database for PostgreSQL como tipo de destino, o script de fluxo de dados associado é:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSqlSink
Atividade de script
Importante
A atividade de script só é suportada no conector da versão 2.0.
Importante
Não há suporte para instruções de múltiplas consultas usando parâmetros de saída. É recomendável dividir todas as consultas de saída em blocos de script separados dentro da mesma atividade de script ou diferente.
Não há suporte para declarações de múltiplas consultas usando parâmetros posicionais. É recomendável dividir todas as consultas posicionais em blocos de script separados dentro da mesma atividade de script ou diferente.
Para obter mais informações sobre a atividade de script, consulte Atividade de script.
Propriedades da atividade de consulta
Para obter mais informações sobre as propriedades, consulte Atividade de pesquisa.
Atualizar o Banco de Dados do Azure para o conector PostgreSQL
Na página Editar serviço vinculado , selecione 2.0 em Versão e configure o serviço vinculado consultando Propriedades do serviço vinculado versão 2.0.
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores pela atividade de cópia, consulte Armazenamentos de dados suportados.