Conjuntos de dados no Azure Data Factory e no Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve o que são conjuntos de dados, como eles são definidos no formato JSON e como eles são usados no Azure Data Factory e nos pipelines Synapse.
Se você é novo no Data Factory, consulte Introdução ao Azure Data Factory para obter uma visão geral. Para obter mais informações sobre o Azure Synapse, consulte O que é o Azure Synapse
Descrição geral
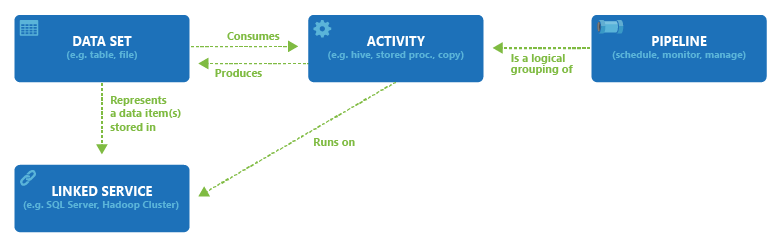
Um espaço de trabalho do Azure Data Factory ou Synapse pode ter um ou mais pipelines. Um pipeline é um agrupamento lógico de atividades que, juntas, executam uma tarefa. As atividades num pipeline definem as ações a executar nos seus dados. Agora, um conjunto de dados é uma exibição nomeada de dados que simplesmente aponta ou faz referência aos dados que você deseja usar em suas atividades como entradas e saídas. Os conjuntos de dados identificam dados dentro de diferentes arquivos de dados, como tabelas, ficheiros, pastas e documentos. Por exemplo, um conjunto de dados de Blob do Azure especifica o contêiner e a pasta de blob no Armazenamento de Blob a partir do qual a atividade deve ler os dados.
Antes de criar um conjunto de dados, você deve criar um serviço vinculado para vincular seu armazenamento de dados ao serviço. Os serviços vinculados são muito parecidos com cadeias de conexão, que definem as informações de conexão necessárias para que o serviço se conecte a recursos externos. Pense nisso desta forma; O conjunto de dados representa a estrutura dos dados dentro dos armazenamentos de dados vinculados e o serviço vinculado define a conexão com a fonte de dados. Por exemplo, um serviço vinculado do Armazenamento do Azure vincula uma conta de armazenamento. Um conjunto de dados de Blob do Azure representa o contêiner de blob e a pasta dentro dessa conta de Armazenamento do Azure que contém os blobs de entrada a serem processados.
Aqui está um cenário de exemplo. Para copiar dados do armazenamento de Blob para um Banco de Dados SQL, crie dois serviços vinculados: Armazenamento de Blob do Azure e Banco de Dados SQL do Azure. Em seguida, crie dois conjuntos de dados: Conjunto de dados de Texto Delimitado (que se refere ao serviço vinculado do Armazenamento de Blobs do Azure, supondo que você tenha arquivos de texto como origem) e Conjunto de dados da Tabela SQL do Azure (que se refere ao serviço vinculado do Banco de Dados SQL do Azure). Os serviços vinculados do Armazenamento de Blobs do Azure e do Banco de Dados SQL do Azure contêm cadeias de conexão que o serviço usa em tempo de execução para se conectar ao Armazenamento do Azure e ao Banco de Dados SQL do Azure, respectivamente. O conjunto de dados Texto Delimitado especifica o contêiner de blob e a pasta de blob que contém os blobs de entrada em seu Armazenamento de Blobs, juntamente com as configurações relacionadas ao formato. O conjunto de dados Tabela SQL do Azure especifica a tabela SQL em seu Banco de Dados SQL para a qual os dados devem ser copiados.
O diagrama a seguir mostra as relações entre pipeline, atividade, conjunto de dados e serviços vinculados:
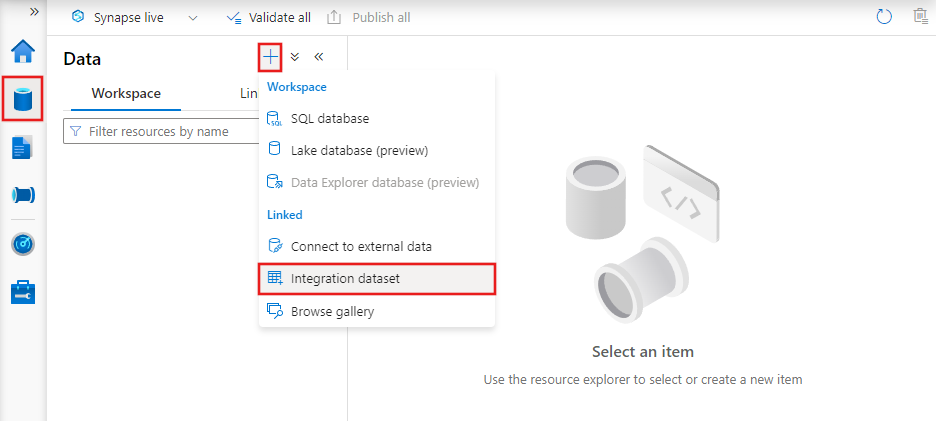
Criar um conjunto de dados com a interface do usuário
Para criar um conjunto de dados com o Azure Data Factory Studio, selecione a guia Autor (com o ícone de lápis) e, em seguida, o ícone de sinal de adição, para escolher Conjunto de Dados.
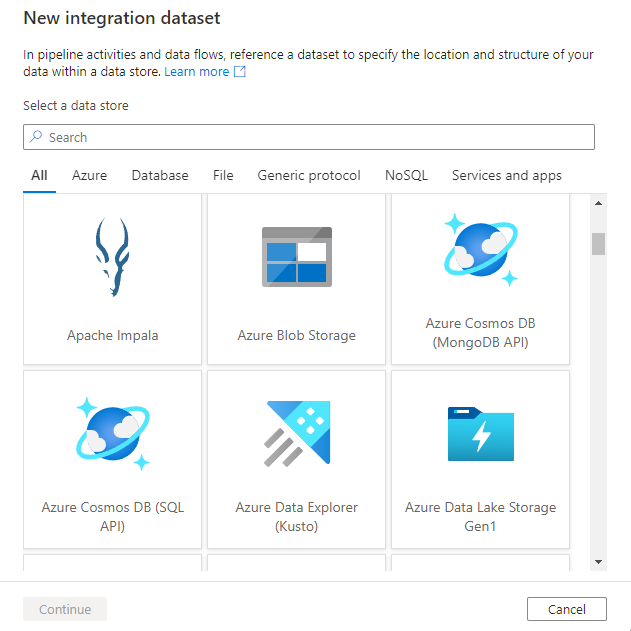
Você verá a nova janela do conjunto de dados para escolher qualquer um dos conectores disponíveis no Azure Data Factory, para configurar um serviço vinculado novo ou existente.
Em seguida, você será solicitado a escolher o formato do conjunto de dados.

Finalmente, você pode escolher um serviço vinculado existente do tipo selecionado para o conjunto de dados ou criar um novo, se ainda não estiver definido.
Depois de criar o conjunto de dados, você pode usá-lo em qualquer pipeline no Azure Data Factory.
JSON do conjunto de dados
Um conjunto de dados é definido no seguinte formato JSON:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
A tabela a seguir descreve as propriedades no JSON acima:
| Property | Descrição | Obrigatório |
|---|---|---|
| nome | Nome do conjunto de dados. Consulte Regras de nomenclatura. | Sim |
| tipo | Tipo do conjunto de dados. Especifique um dos tipos suportados pelo Data Factory (por exemplo: DelimitedText, AzureSqlTable). Para obter detalhes, consulte Tipos de conjunto de dados. |
Sim |
| esquema | Esquema do conjunto de dados, representa o tipo de dados físicos e a forma. | Não |
| typeProperties | As propriedades de tipo são diferentes para cada tipo. Para obter detalhes sobre os tipos suportados e suas propriedades, consulte Tipo de conjunto de dados. | Sim |
Ao importar o esquema do conjunto de dados, selecione o botão Importar esquema e escolha importar da origem ou de um arquivo local. Na maioria dos casos, você importará o esquema diretamente da origem. Mas se você já tiver um arquivo de esquema local (um arquivo Parquet ou CSV com cabeçalhos), poderá direcionar o serviço para basear o esquema nesse arquivo.
Na atividade de cópia, os conjuntos de dados são usados na origem e no coletor. O esquema definido no conjunto de dados é opcional como referência. Se quiser aplicar o mapeamento de coluna/campo entre a origem e o coletor, consulte Mapeamento de esquema e tipo.
No Fluxo de Dados, os conjuntos de dados são usados em transformações de origem e coletor. Os conjuntos de dados definem os esquemas de dados básicos. Se os dados não tiverem esquema, você poderá usar o desvio de esquema para a origem e o coletor. Os metadados dos conjuntos de dados aparecem na transformação de origem como a projeção de origem. A projeção na transformação de origem representa os dados de fluxo de dados com nomes e tipos definidos.
Tipo de conjunto de dados
O serviço suporta muitos tipos diferentes de conjuntos de dados, dependendo dos armazenamentos de dados que você usa. Você pode encontrar a lista de armazenamentos de dados suportados no artigo Visão geral do conector. Selecione um armazenamento de dados para saber como criar um serviço vinculado e um conjunto de dados para ele.
Por exemplo, para um conjunto de dados Texto Delimitado, o tipo de conjunto de dados é definido como DelimitedText conforme mostrado no seguinte exemplo JSON:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Nota
O valor do esquema é definido usando a sintaxe JSON. Para obter informações mais detalhadas sobre mapeamento de esquema e mapeamento de tipo de dados, consulte a documentação Esquema de Atividade de Cópia e Mapeamento de Tipo do Azure Data Factory.
Criar conjuntos de dados
Você pode criar conjuntos de dados usando uma destas ferramentas ou SDKs: API .NET, PowerShell, API REST, Modelo do Azure Resource Manager e portal do Azure
Conjuntos de dados da versão atual vs. versão 1
Aqui estão algumas diferenças entre os conjuntos de dados na versão atual do Data Factory (e no Azure Synapse) e a versão 1 do Data Factory herdado:
- A propriedade externa não é suportada na versão atual. É substituído por um gatilho.
- As propriedades de política e disponibilidade não são suportadas na versão atual. A hora de início de um pipeline depende de gatilhos.
- Conjuntos de dados com escopo (conjuntos de dados definidos em um pipeline) não são suportados na versão atual.
Conteúdos relacionados
Guias de Início Rápido
Consulte o tutorial a seguir para obter instruções passo a passo para criar pipelines e conjuntos de dados usando uma dessas ferramentas ou SDKs.
- Quickstart: create a data factory using .NET (Início rápido: criar uma fábrica de dados com .NET)
- Guia de início rápido: criar uma fábrica de dados usando o PowerShell
- Guia de início rápido: criar uma fábrica de dados usando a API REST
- Guia de início rápido: criar uma fábrica de dados usando o portal do Azure