Copiar várias tabelas em massa usando o Azure Data Factory no portal do Azure
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este tutorial demonstra a cópia de várias tabelas do Banco de Dados SQL do Azure para o Azure Synapse Analytics. Também pode aplicar o mesmo padrão noutros cenários de cópia. Por exemplo, copiando tabelas do SQL Server/Oracle para o Banco de Dados SQL do Azure/Azure Synapse Analytics /Azure Blob, copiando caminhos diferentes de Blob para tabelas do Banco de Dados SQL do Azure.
Nota
Se não estiver familiarizado com o Azure Data Factory, veja Introdução ao Azure Data Factory.
A um nível elevado, este tutorial envolve os seguintes passos:
- Criar uma fábrica de dados.
- Crie o Banco de Dados SQL do Azure, o Azure Synapse Analytics e os serviços vinculados do Armazenamento do Azure.
- Crie conjuntos de dados do Banco de Dados SQL do Azure e do Azure Synapse Analytics.
- Criar um pipeline para procurar as tabelas a copiar e outro pipeline para executar a operação de cópia real.
- Iniciar uma execução de pipeline.
- Monitorizar o pipeline e execuções de atividades.
Este tutorial utiliza o portal do Azure. Para saber mais sobre como utilizar outras ferramentas/SDKs para criar uma fábrica de dados, veja Inícios rápidos.
Fluxo de trabalho ponto a ponto
Nesse cenário, você tem várias tabelas no Banco de Dados SQL do Azure que deseja copiar para o Azure Synapse Analytics. Segue-se a sequência lógica de passos no fluxo de trabalho que ocorre nos pipelines:

- O primeiro pipeline procura a lista de tabelas que têm de ser copiadas para os arquivos de dados de sink. Em alternativa, pode manter uma tabela de metadados que apresenta uma lista de todas as tabelas a copiar para o arquivo de dados de sink. Em seguida, o pipeline aciona outro pipeline, que itera cada tabela na base de dados e executa a operação de cópia de dados.
- O segundo pipeline executa a cópia real. Aceita a lista de tabelas como um parâmetro. Para cada tabela na lista, copie a tabela específica no Banco de Dados SQL do Azure para a tabela correspondente no Azure Synapse Analytics usando cópia em estágios via armazenamento de Blob e PolyBase para obter o melhor desempenho. Neste exemplo, o primeiro pipeline passa a lista de tabelas como um valor para o parâmetro.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Conta do Armazenamento do Azure. A conta de Armazenamento do Azure é utilizada como armazenamento de blobs de teste na operação de cópia em massa.
- Base de Dados SQL do Azure. Esta base de dados contém os dados de origem. Crie um banco de dados no Banco de Dados SQL com dados de exemplo do Adventure Works LT seguindo o artigo Criar um banco de dados no Banco de Dados SQL do Azure. Este tutorial copia todas as tabelas deste banco de dados de exemplo para um Azure Synapse Analytics.
- Azure Synapse Analytics. Este armazém de dados contém os dados copiados da Base de Dados SQL. Se você não tiver um espaço de trabalho do Azure Synapse Analytics, consulte o artigo Introdução ao Azure Synapse Analytics para conhecer as etapas para criar um.
Serviços do Azure para aceder ao SQL Server
Para o Banco de Dados SQL e o Azure Synapse Analytics, permita que os serviços do Azure acessem o SQL Server. Certifique-se de que Permitir que os serviços e recursos do Azure acedam a esta definição de servidor está ativada para o seu servidor. Essa configuração permite que o serviço Data Factory leia dados do Banco de Dados SQL do Azure e grave dados no Azure Synapse Analytics.
Para verificar e ativar essa configuração, vá para seus firewalls de segurança > do servidor > e redes > virtuais defina Permitir que os serviços e recursos do Azure acessem este servidor como ATIVADO.
Criar uma fábrica de dados
Abra o browser Microsoft Edge ou Google Chrome. Atualmente, a IU do Data Factory é suportada apenas nos browsers Microsoft Edge e Google Chrome.
Aceda ao portal do Azure.
À esquerda do menu do portal do Azure, selecione Criar um recurso>Integration>Data Factory.
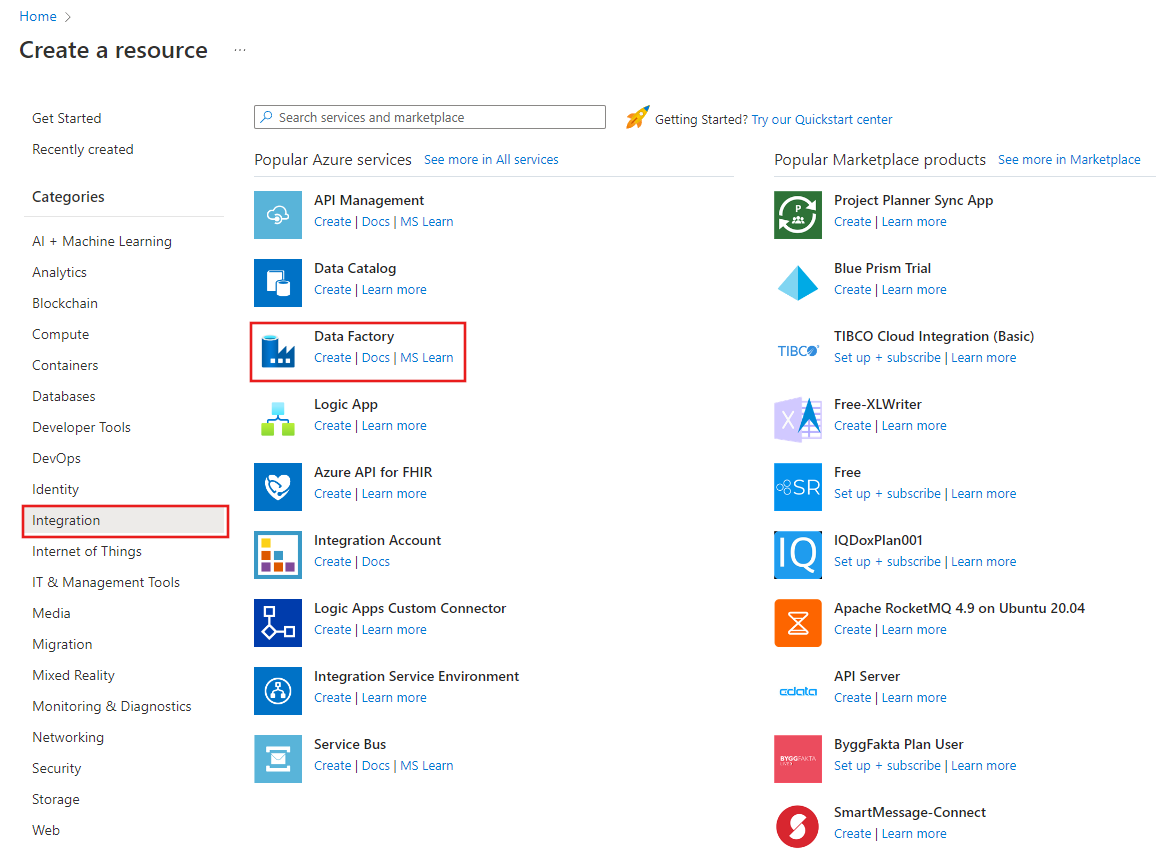
Na página Novo data factory, digite ADFTutorialBulkCopyDF para nome.
O nome do Azure Data Factory deve ser globalmente exclusivo. Se vir o erro seguinte no campo de nome, altere o nome da fábrica de dados (por exemplo, oseunomeADFTutorialBulkCopyDF). Veja o artigo Data Factory – Naming Rules (Data Factory – Regras de Nomenclatura) para obter as regras de nomenclatura dos artefactos do Data Factory.
Data factory name "ADFTutorialBulkCopyDF" is not availableSelecione a sua subscrição do Azure na qual pretende criar a fábrica de dados.
No Grupo de Recursos, siga um destes passos:
Selecione Utilizar existente e selecione um grupo de recursos já existente na lista pendente.
Selecione Criar novo e introduza o nome de um grupo de recursos.
Para saber mais sobre os grupos de recursos, veja Utilizar grupos de recursos para gerir os recursos do Azure.
Selecione V2 para a versão.
Selecione a localização da fábrica de dados. Para obter uma lista de regiões do Azure em que o Data Factory está atualmente disponível, selecione as regiões que lhe interessam na página seguinte e, em seguida, expanda Analytics para localizar Data Factory: Produtos disponíveis por região. Os arquivos de dados (Armazenamento do Azure, Base de Dados SQL do Azure, etc.) e as computações (HDInsight, etc.) utilizados pela fábrica de dados podem estar noutras regiões.
Clique em Criar.
Após a conclusão da criação, selecione Ir para o recurso para navegar até a página Data Factory .
Selecione Abrir no bloco Abrir o Azure Data Factory Studio para iniciar o aplicativo da interface do usuário do Data Factory em uma guia separada.
Criar serviços ligados
Os serviços ligados são criados para ligar os seus arquivos de dados e computações a uma fábrica de dados. O serviço ligado tem as informações de ligação que o serviço Data Factory utiliza para se ligar ao arquivo de dados no runtime.
Neste tutorial, você vincula seus armazenamentos de dados do Banco de Dados SQL do Azure, do Azure Synapse Analytics e do Armazenamento de Blobs do Azure ao seu data factory. A Base de Dados SQL do Azure é o arquivo de dados de origem. O Azure Synapse Analytics é o repositório de dados de coletor/destino. O Armazenamento de Blobs do Azure deve preparar os dados antes que os dados sejam carregados no Azure Synapse Analytics usando o PolyBase.
Criar o serviço ligado da Base de Dados SQL do Azure de origem
Nesta etapa, você cria um serviço vinculado para vincular seu banco de dados no Banco de Dados SQL do Azure ao data factory.
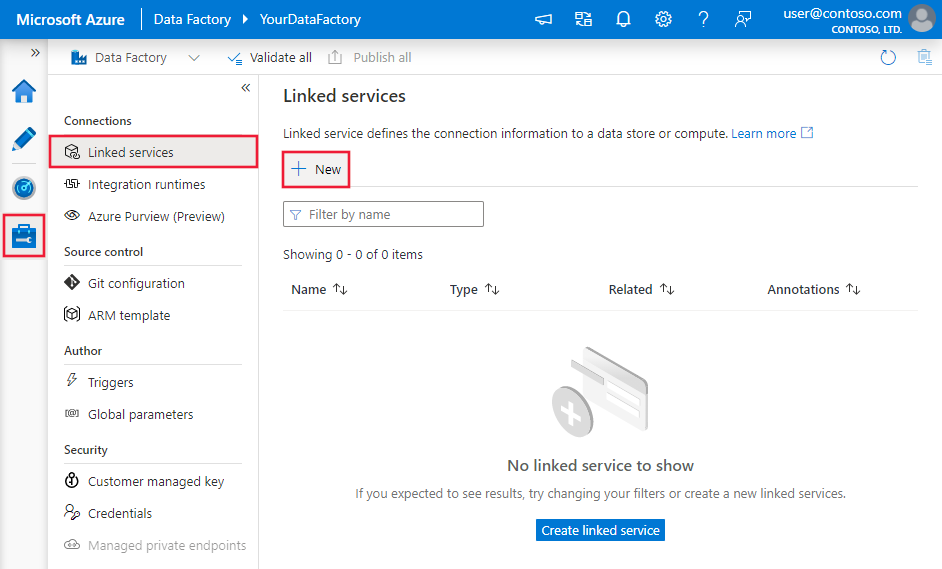
Abra a guia Gerenciar no painel esquerdo.
Na página Serviços vinculados, selecione +Novo para criar um novo serviço vinculado.
Na janela Novo Serviço Ligado, selecione Base de Dados SQL do Azure e clique em Continuar.
Na janela Novo Serviço Vinculado (Banco de Dados SQL do Azure), execute as seguintes etapas:
a. Introduza AzureSqlDatabaseLinkedService em Nome.
b. Selecione o servidor para Nome do servidor
c. Selecione seu banco de dados para Nome do banco de dados.
d. Digite o nome do usuário para se conectar ao seu banco de dados.
e. Introduza a palavra-passe do utilizador.
f. Para testar a conexão com seu banco de dados usando as informações especificadas, clique em Testar conexão.
g. Clique em Criar para salvar o serviço vinculado.
Criar o coletor do serviço vinculado do Azure Synapse Analytics
No separador Ligações, clique em + Novo, novamente na barra de ferramentas.
Na janela Novo Serviço Vinculado, selecione Azure Synapse Analytics e clique em Continuar.
Na janela Novo Serviço Vinculado (Azure Synapse Analytics), execute as seguintes etapas:
a. Introduza AzureSqlDWLinkedService em Nome.
b. Selecione o servidor para Nome do servidor
c. Selecione seu banco de dados para Nome do banco de dados.
d. Digite Nome de usuário para se conectar ao seu banco de dados.
e. Digite a senha do usuário.
f. Para testar a conexão com seu banco de dados usando as informações especificadas, clique em Testar conexão.
g. Clique em Criar.
Criar o serviço ligado de Armazenamento do Azure de teste
Neste tutorial, vai utilizar o armazenamento de Blobs do Azure como área de teste provisória para ativar o PolyBase para um melhor desempenho de cópia.
No separador Ligações, clique em + Novo, novamente na barra de ferramentas.
Na janela Novo Serviço Ligado, selecione Armazenamento de Blobs do Azure e clique em Continuar.
Na janela Novo Serviço Vinculado (Armazenamento de Blob do Azure), execute as seguintes etapas:
a. Introduza AzureStorageLinkedService em Nome.
b. Selecione a sua conta de armazenamento do Azure em Nome da conta de armazenamento.c. Clique em Criar.
Criar conjuntos de dados
Neste tutorial, vai criar conjuntos de dados de origem e sink, que especificam a localização onde os dados são armazenados.
O conjunto de dados de entrada AzureSqlDatabaseDataset refere-se a AzureSqlDatabaseLinkedService. O serviço ligado especifica a cadeia de ligação para ligar à base de dados. O conjunto de dados especifica o nome da base de dados e a tabela que contém os dados de origem.
O conjunto de dados de saída AzureSqlDWDataset refere-se a AzureSqlDWLinkedService. O serviço vinculado especifica a cadeia de conexão para se conectar ao Azure Synapse Analytics. O conjunto de dados especifica a base de dados e a tabela para a qual os dados são copiados.
Neste tutorial, as tabelas SQL de origem e destino não estão hard-coded nas definições do conjunto de dados. Em vez disso, a atividade ForEach transmite o nome da tabela no runtime à atividade Cópia.
Criar um conjunto de dados para a Base de Dados SQL de origem
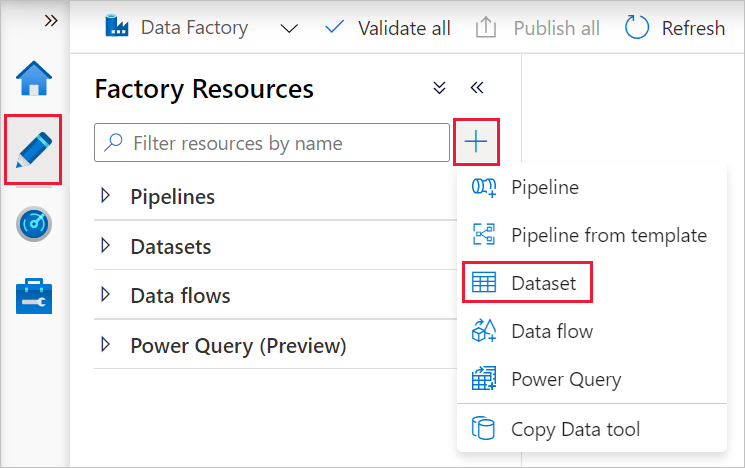
Selecione a guia Autor no painel esquerdo.
Selecione o + (mais) no painel esquerdo e, em seguida, selecione Conjunto de dados.
Na janela Novo Conjunto de Dados, selecione Banco de Dados SQL do Azure e clique em Continuar.
Na janela Definir propriedades, em Nome, insira AzureSqlDatabaseDataset. Em Serviço vinculado, selecione AzureSqlDatabaseLinkedService. Em seguida, clique em OK.
Alterne para a guia Conexão , selecione qualquer tabela para Tabela. Esta é uma tabela fictícia. Vai especificar uma consulta no conjunto de dados de origem quando criar um pipeline. A consulta é usada para extrair dados do seu banco de dados. Como alternativa, você pode clicar na caixa de seleção Editar e digitar dbo.dummyName como o nome da tabela.
Criar um conjunto de dados para o coletor Azure Synapse Analytics
Clique em + (mais), no painel do lado esquerdo, e clique em Conjunto de Dados.
Na janela Novo Conjunto de Dados, selecione Azure Synapse Analytics e clique em Continuar.
Na janela Definir propriedades, em Nome, insira AzureSqlDWDataset. Em Serviço vinculado, selecione AzureSqlDWLinkedService. Em seguida, clique em OK.
Mude para o separador Parâmetros, clique em + Novo e introduza DWTableName no nome do parâmetro. Clique em + Novo novamente e digite DWSchema para o nome do parâmetro. Se você copiar/colar esse nome da página, verifique se não há nenhum caractere de espaço à direita no final de DWTableName e DWSchema.
Mude para o separador Ligação,
Em Tabela, marque a opção Editar. Selecione a primeira caixa de entrada e clique no link Adicionar conteúdo dinâmico abaixo. Na página Adicionar Conteúdo Dinâmico, clique no DWSchema em Parâmetros, que preencherá automaticamente a caixa
@dataset().DWSchemade texto da expressão superior e, em seguida, clique em Concluir.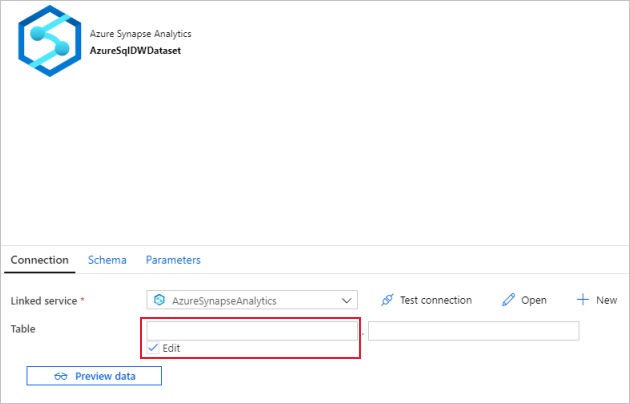
Selecione a segunda caixa de entrada e clique no link Adicionar conteúdo dinâmico abaixo. Na página Adicionar Conteúdo Dinâmico, clique em DWTAbleName em Parâmetros, que preencherá automaticamente a caixa
@dataset().DWTableNamede texto da expressão superior e, em seguida, clique em Concluir.A propriedade tableName do conjunto de dados é definida como os valores que são passados como argumentos para os parâmetros DWSchema e DWTableName . A atividade ForEach itera através de uma lista de tabelas e transmite-as uma a uma à atividade Cópia.
Criar pipelines
Neste tutorial, vai criar dois pipelines, IterateAndCopySQLTables e GetTableListAndTriggerCopyData.
O pipeline GetTableListAndTriggerCopyData executa duas ações:
- Procura a tabela do sistema da Base de Dados SQL do Azure para obter a lista de tabelas a copiar.
- Aciona o pipeline IterateAndCopySQLTables para executar a cópia de dados real.
O pipeline IterateAndCopySQLTables usa uma lista de tabelas como parâmetro. Para cada tabela na lista, ele copia dados da tabela no Banco de Dados SQL do Azure para o Azure Synapse Analytics usando cópia em estágios e PolyBase.
Criar o pipeline IterateAndCopySQLTables
No painel do lado esquerdo, clique em + (mais) e clique em Pipeline.
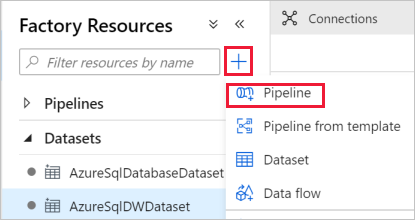
No painel Geral, em Propriedades, especifique IterateAndCopySQLTables para Name. Em seguida, feche o painel clicando no ícone Propriedades no canto superior direito.
Mude para o separador Parâmetros e execute as ações seguintes:
a. Clique em + Novo.
b. Insira tableList para o parâmetro Name.
c. Selecione Matriz para Tipo.
Na caixa de ferramentas Atividades, expanda Iteração e Condições e arraste e largue a atividade ForEach na superfície de desenho do pipeline. Também pode pesquisar por atividades na caixa de ferramentas Atividades.
a. No separador Geral, na parte inferior, introduza IterateSQLTables em Nome.
b. Alterne para a guia Configurações , clique na caixa de entrada para Itens e clique no link Adicionar conteúdo dinâmico abaixo.
c. Na página Adicionar Conteúdo Dinâmico, feche as seções Variáveis e Funções do Sistema, clique na tableList em Parâmetros, que preencherá automaticamente a caixa de texto da expressão superior como
@pipeline().parameter.tableList. Em seguida, clique em Concluir.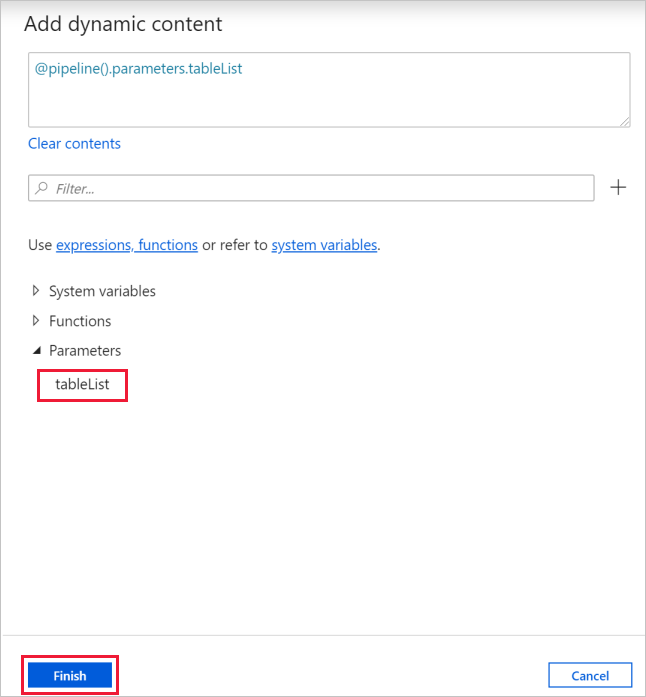
d. Alterne para a guia Atividades, clique no ícone de lápis para adicionar uma atividade filho à atividade ForEach.
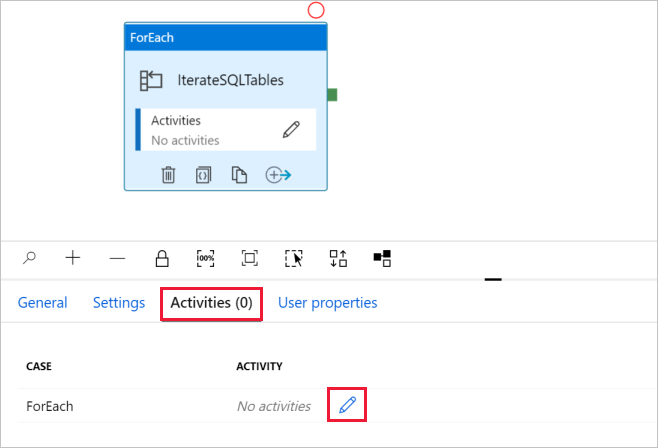
Na caixa de ferramentas Atividades, expanda Mover & Transferir e arraste e solte a atividade Copiar dados na superfície do designer de pipeline. Repare no menu de trilho na parte superior. O IterateAndCopySQLTable é o nome do pipeline e IterateSQLTables é o nome da atividade ForEach. O estruturador está no âmbito da atividade. Para voltar para o editor de pipeline a partir do editor ForEach, você pode clicar no link no menu de navegação.
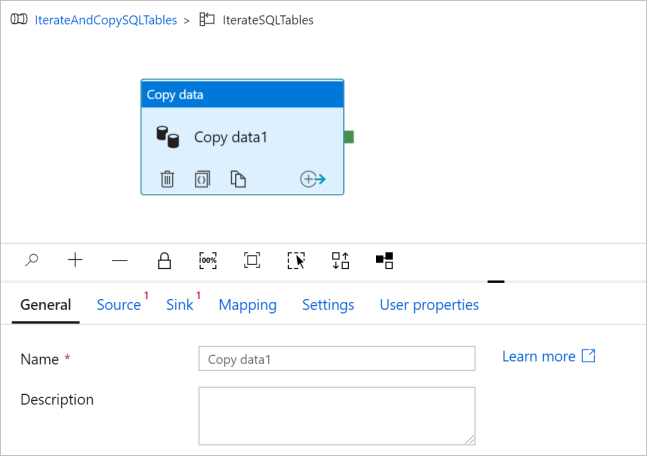
Mude para o separador Origem e siga os passos abaixo:
Selecione AzureSqlDatabaseDataset em Conjunto de Dados de Origem.
Selecione a opção Consulta para Usar consulta.
Clique na caixa de entrada Consulta -> selecione Adicionar conteúdo dinâmico abaixo -> insira a seguinte expressão para Consulta -> selecione Concluir.
SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]
Mude para o separador Sink e siga os passos abaixo:
Selecione AzureSqlDWDataset em Conjunto de Dados de Sink.
Clique na caixa de entrada para o parâmetro VALUE of DWTableName -> selecione Adicionar conteúdo dinâmico abaixo, insira
@item().TABLE_NAMEexpressão como script, -> selecione Concluir.Clique na caixa de entrada para o parâmetro VALUE of DWSchema -> selecione Add dynamic content abaixo, insira
@item().TABLE_SCHEMAexpression as script, -> selecione Finish.Para Método Copy, selecione PolyBase.
Desmarque a opção Usar tipo padrão .
Para a opção Tabela, a configuração padrão é "Nenhum". Se você não tiver tabelas pré-criadas no coletor Azure Synapse Analytics, habilite a opção Criar tabela automaticamente, a atividade de cópia criará automaticamente tabelas para você com base nos dados de origem. Para obter detalhes, consulte Criar tabelas de coletor automaticamente.
Clique na caixa de entrada Pré-cópia do script -> selecione Adicionar conteúdo dinâmico abaixo -> insira a seguinte expressão como script -> selecione Concluir.
IF EXISTS (SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]) TRUNCATE TABLE [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]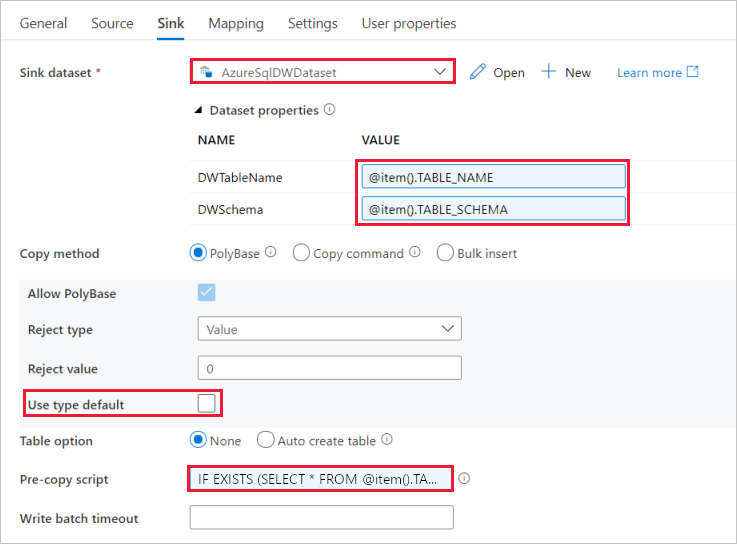
Mude para o separador Definições e siga os passos abaixo:
- Marque a caixa de seleção Ativar preparo.
- Selecione AzureStorageLinkedService em Nome do Serviço Ligado da Conta de Armazenamento.
Para validar as definições do pipeline, clique em Validar, na barra de ferramentas do mesmo. Certifique-se de que não há nenhum erro de validação. Para fechar o Relatório de Validação de Pipeline, clique nos colchetes angulares duplos >>.
Criar o pipeline GetTableListAndTriggerCopyData
Este pipeline realiza duas ações:
- Procura a tabela do sistema da Base de Dados SQL do Azure para obter a lista de tabelas a copiar.
- Aciona o pipeline "IterateAndCopySQLTables" para executar a cópia de dados real.
Aqui estão as etapas para criar o pipeline:
No painel do lado esquerdo, clique em + (mais) e clique em Pipeline.
No painel Geral, em Propriedades, altere o nome do pipeline para GetTableListAndTriggerCopyData.
Na caixa de ferramentas Atividades, expanda Geral e arraste e solte a atividade Pesquisa na superfície do designer de pipeline e execute as seguintes etapas:
- Introduza LookupTableList em Nome.
- Digite Recuperar a lista de tabelas do meu banco de dados para Descrição.
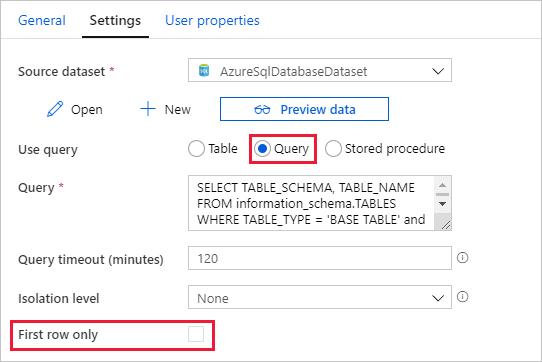
Mude para o separador Definições e siga os passos abaixo:
Selecione AzureSqlDatabaseDataset em Conjunto de Dados de Origem.
Selecione Consulta para uso consulta.
Introduza a seguinte consulta SQL em consulta.
SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.TABLES WHERE TABLE_TYPE = 'BASE TABLE' and TABLE_SCHEMA = 'SalesLT' and TABLE_NAME <> 'ProductModel'Desmarque a caixa de verificação do campo Primeira linha apenas.
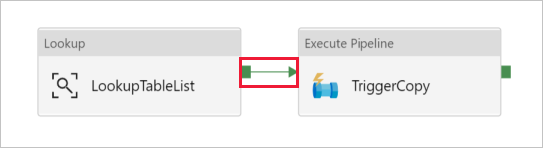
Arraste e solte a atividade Executar pipeline da caixa de ferramentas Atividades para a superfície do designer de pipeline e defina o nome como TriggerCopy.
Para Conectar a atividade Pesquisa à atividade Executar Pipeline, arraste a caixa verde anexada à atividade Pesquisa à esquerda da atividade Executar Pipeline.
Alterne para a guia Configurações da atividade Executar pipeline e execute as seguintes etapas:
Selecione IterateAndCopySQLTables em Pipeline invocado.
Desmarque a caixa de seleção Aguarde na conclusão.
Na seção Parâmetros, clique na caixa de entrada em VALOR -> selecione Adicionar conteúdo dinâmico abaixo -> insira
@activity('LookupTableList').output.valuecomo valor do nome da tabela -> selecione Concluir. Você está definindo a lista de resultados da atividade Pesquisa como uma entrada para o segundo pipeline. A lista de resultados contém a lista de tabelas cujos dados têm de ser copiados para o destino.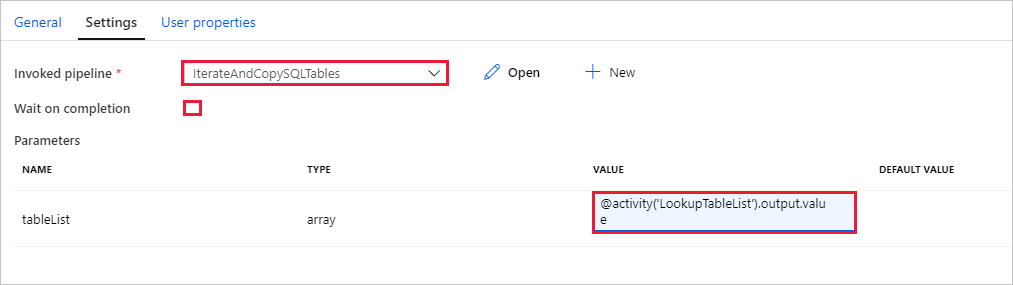
Para validar o pipeline, clique em Validar, na barra de ferramentas. Confirme que não há erros de validação. Para fechar o Relatório de Validação do Pipeline, clique em >>.
Para publicar entidades (conjuntos de dados, pipelines, etc.) no serviço Data Factory, clique em Publicar tudo na parte superior da janela. Aguarde até que a publicação seja bem-sucedida.
Acionar uma execução de pipeline
Vá para pipeline GetTableListAndTriggerCopyData, clique em Adicionar Gatilho na barra de ferramentas de pipeline superior e, em seguida, clique em Gatilho agora.
Confirme a execução na página Execução do pipeline e selecione Concluir.
Monitorizar a execução do pipeline.
Alterne para a guia Monitor . Clique em Atualizar até ver execuções para ambos os pipelines em sua solução. Continue a atualizar a lista até ver o estado Com Êxito.
Para exibir as execuções de atividade associadas ao pipeline GetTableListAndTriggerCopyData , clique no link de nome do pipeline para o pipeline. Deverá ver duas execuções de atividade para esta execução de pipeline.
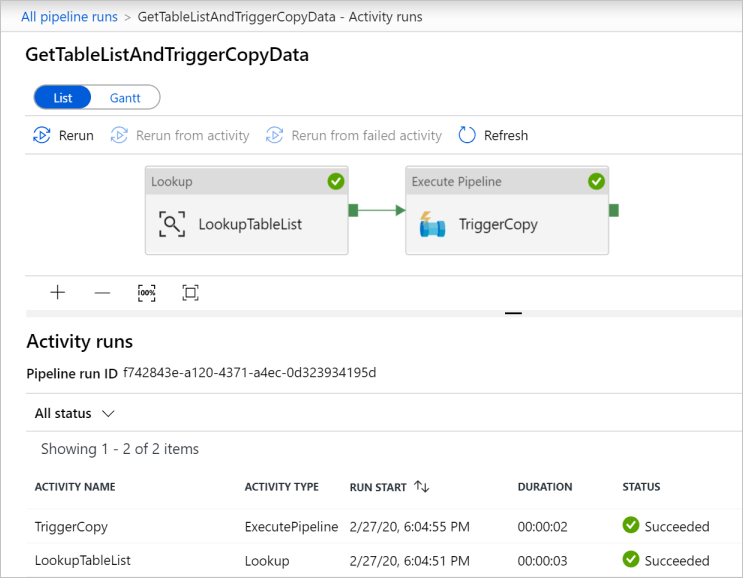
Para exibir a saída da atividade de pesquisa, clique no link Saída ao lado da atividade na coluna NOME DA ATIVIDADE. Pode maximizar e restaurar a janela Saída. Depois de rever, clique em X para fechar a janela Saída.
{ "count": 9, "value": [ { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Customer" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Product" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductModelProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductCategory" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Address" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "CustomerAddress" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderDetail" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderHeader" } ], "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)", "effectiveIntegrationRuntimes": [ { "name": "DefaultIntegrationRuntime", "type": "Managed", "location": "East US", "billedDuration": 0, "nodes": null } ] }Para voltar para o modo de exibição Pipeline Runs , clique no link All Pipeline runs na parte superior do menu breadcrumb. Clique no link IterateAndCopySQLTables (na coluna PIPELINE NAME ) para exibir as execuções de atividade do pipeline. Observe que há uma atividade de cópia executada para cada tabela na saída da atividade de pesquisa .
Confirme se os dados foram copiados para o Azure Synapse Analytics de destino usado neste tutorial.
Conteúdos relacionados
Neste tutorial, executou os passos seguintes:
- Criar uma fábrica de dados.
- Crie o Banco de Dados SQL do Azure, o Azure Synapse Analytics e os serviços vinculados do Armazenamento do Azure.
- Crie conjuntos de dados do Banco de Dados SQL do Azure e do Azure Synapse Analytics.
- Criar um pipeline para procurar as tabelas a copiar e outro pipeline para executar a operação de cópia real.
- Iniciar uma execução de pipeline.
- Monitorizar o pipeline e execuções de atividades.
Avance para o tutorial seguinte para saber como copiar dados de forma incremental de uma origem para um destino: