Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O Databricks suporta o uso de diferentes linguagens de programação para desenvolvimento e engenharia de dados. Este artigo descreve as opções disponíveis, onde esses idiomas podem ser usados e suas limitações.
Recomendações
Databricks recomenda Python e SQL para novos projetos:
- Python é uma linguagem de programação de uso geral muito popular. Os DataFrames PySpark facilitam a criação de transformações modulares testáveis. O ecossistema Python também suporta uma ampla gama de bibliotecas, suporta uma ampla gama de bibliotecas para estender sua solução.
-
SQL é uma linguagem muito popular para gerenciar e manipular conjuntos de dados relacionais executando operações como consultar, atualizar, inserir e excluir dados. SQL é uma boa escolha se o seu background é principalmente em bancos de dados ou data warehousing. SQL também pode ser incorporado em Python usando
spark.sql.
Os seguintes idiomas têm suporte limitado, portanto, o Databricks não os recomenda para novos projetos de engenharia de dados:
- Scala é a linguagem usada para o desenvolvimento do Apache Spark™.
- R só é totalmente suportado em notebooks Databricks.
O suporte a idiomas também varia dependendo dos recursos usados para criar pipelines de dados e outras soluções. Por exemplo, o Lakeflow Spark Declarative Pipelines suporta Python e SQL, enquanto fluxos de trabalho permitem criar pipelines de dados usando Python, SQL, Scala e Java.
Observação
Outras linguagens podem ser usadas para interagir com o Databricks para consultar dados ou executar transformações de dados. No entanto, essas interações são principalmente no contexto de integrações com sistemas externos. Nesses casos, um desenvolvedor pode usar praticamente qualquer linguagem de programação para interagir com o Databricks por meio da API REST do Databricks, dos drivers ODBC/JDBC , linguagens específicas com suporte do conector SQL do Databricks (Go, Python, Javascript/Node.js), ou linguagens que tenham implementações do Spark Connect , como Go e Rust.
Desenvolvimento do espaço de trabalho vs desenvolvimento local
Você pode desenvolver projetos de dados e pipelines usando o espaço de trabalho Databricks ou um IDE (ambiente de desenvolvimento integrado) em sua máquina local, mas é recomendável iniciar novos projetos no espaço de trabalho Databricks. O espaço de trabalho é acessível através de um navegador web, proporciona fácil acesso a dados no Unity Catalog e suporta poderosas capacidades e funcionalidades de depuração, como o Código Genie.
Desenvolva código no espaço de trabalho Databricks usando blocos de anotações Databricks ou o editor SQL. Os notebooks Databricks suportam várias linguagens de programação, mesmo dentro do mesmo notebook, para que você possa desenvolver usando Python, SQL e Scala.
Há várias vantagens de desenvolver código diretamente no espaço de trabalho Databricks:
- O ciclo de feedback é mais rápido. Você pode testar imediatamente o código escrito em dados reais.
- O Código Genie incorporado e consciente do contexto pode acelerar o desenvolvimento e ajudar a resolver problemas.
- Você pode facilmente agendar blocos de anotações e consultas diretamente do espaço de trabalho Databricks.
- Para desenvolvimento em Python, você pode estruturar corretamente seu código Python usando arquivos como pacotes Python em um espaço de trabalho.
No entanto, o desenvolvimento local dentro de um IDE oferece as seguintes vantagens:
- Os IDEs têm melhores ferramentas para trabalhar com projetos de software, como navegação, refatoração de código e análise estática de código.
- Você pode escolher como controlar sua fonte e, se usar o Git, uma funcionalidade mais avançada estará disponível localmente do que no espaço de trabalho com pastas Git.
- Há uma gama mais ampla de idiomas suportados. Por exemplo, você pode desenvolver código usando Java e implementá-lo como uma tarefa JAR.
- Há um melhor suporte para depuração de código.
- Há um melhor suporte para a realização de testes de unidade.
Exemplo de seleção de idioma
A seleção de linguagem para engenharia de dados é visualizada usando a seguinte árvore de decisão:
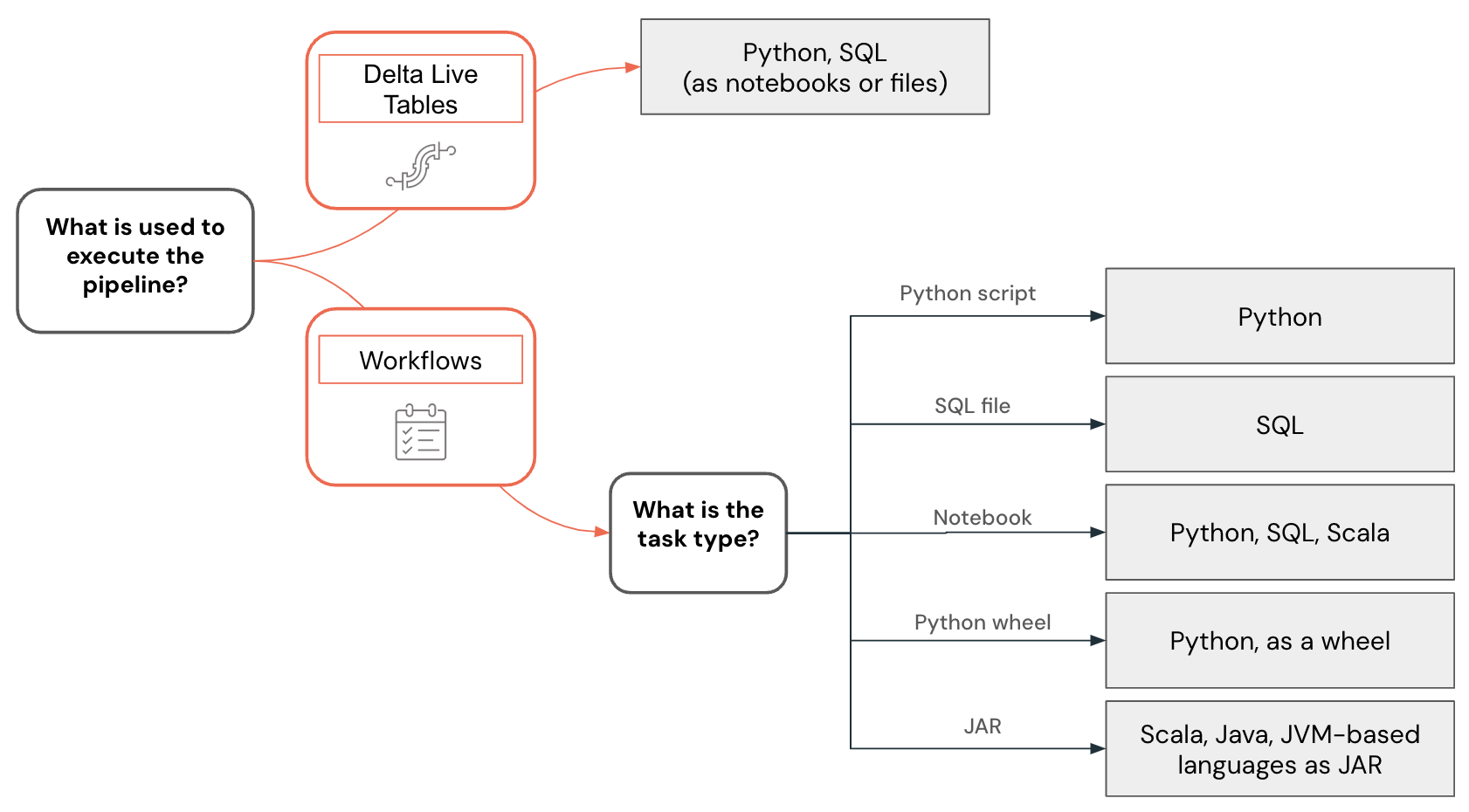
Desenvolvendo código Python
A linguagem Python tem suporte de primeira classe em Databricks. Você pode usá-lo em notebooks Databricks, Lakeflow Spark Declarative Pipelines e fluxos de trabalho, para desenvolver UDFs e também implantá-lo como um script Python e como rodas.
Ao desenvolver projetos Python no espaço de trabalho Databricks, seja em cadernos ou em ficheiros, o Databricks disponibiliza ferramentas como completamento de código, navegação, validação de sintaxe, geração de código usando Genie Code, depuração interativa e muito mais. O código desenvolvido pode ser executado interativamente, implantado como um fluxo de trabalho Databricks ou Lakeflow Spark Declarative Pipelines, ou até mesmo como uma função no Unity Catalog. Você pode estruturar seu código dividindo-o em pacotes Python separados que podem ser usados em vários pipelines ou trabalhos.
O Databricks fornece uma extensão para o Visual Studio Code e o JetBrains oferece um plug-in para o PyCharm que permite desenvolver código Python em um IDE, sincronizar código com um espaço de trabalho Databricks, executá-lo dentro do espaço de trabalho e executar depuração passo a passo usando Databricks Connect. O código desenvolvido pode então ser implementado usando Declarative Automation Bundles como uma tarefa ou pipeline no Databricks.
Desenvolvendo código SQL
A linguagem SQL pode ser usada nos cadernos do Databricks ou como consultas no Databricks usando o editor SQL. Em ambos os casos, o programador tem acesso a ferramentas como a completação de código e o Código Genie consciente do contexto, que pode ser usado para geração de código e resolução de problemas. O código desenvolvido pode ser implantado como um trabalho ou um processo.
Os fluxos de trabalho Databricks também permitem executar código SQL armazenado em um arquivo. Você pode usar um IDE para criar esses arquivos e carregá-los no espaço de trabalho. Outro uso popular do SQL é em pipelines de engenharia de dados desenvolvidos usando dbt (ferramenta de construção de dados). Os fluxos de trabalho do Databricks suportam a orquestração de projetos dbt.
Desenvolvendo código Scala
Scala é a língua original do Apache Spark™. É uma linguagem poderosa, mas tem uma curva de aprendizagem íngreme. Embora o Scala seja uma linguagem suportada em notebooks Databricks, existem algumas limitações relacionadas à forma como as classes e objetos Scala são criados e mantidos que podem dificultar o desenvolvimento de pipelines complexos. Normalmente, os IDEs fornecem um melhor suporte para o desenvolvimento de código Scala, que pode ser implantado usando tarefas JAR em fluxos de trabalho Databricks.
Próximos passos
- Develop on Databricks é um ponto de entrada para documentação sobre diferentes opções de desenvolvimento para Databricks.
- A página de ferramentas para desenvolvedores descreve diferentes ferramentas de desenvolvimento que podem ser usadas para desenvolver localmente para Databricks, incluindo Pacotes de Automação Declarativa e plugins para IDEs.
- Desenvolver código em blocos de anotações Databricks descreve como desenvolver no espaço de trabalho Databricks usando blocos de anotações Databricks.
- Escreva consultas e explore dados no editor SQL. Este artigo descreve como usar o editor Databricks SQL para trabalhar com código SQL.
- Develop Lakeflow Spark Declarative Pipelines descreve o processo de desenvolvimento de Lakeflow Spark Declarative Pipelines.
- Databricks Connect permite que você se conecte a clusters Databricks e execute código de seu ambiente local.
- Aprenda a usar o Genie Code para um desenvolvimento mais rápido e para resolver problemas de código.