Preparar Modelo PyTorch
Este artigo descreve como utilizar o componente Train PyTorch Model no estruturador do Azure Machine Learning para preparar modelos PyTorch como o DenseNet. A preparação ocorre depois de definir um modelo e definir os respetivos parâmetros e requer dados etiquetados.
Atualmente, o componente Train PyTorch Model suporta tanto o nó único como a preparação distribuída.
Como utilizar o Modelo Train PyTorch
Adicione o componente DenseNet ou a ResNet ao seu rascunho de pipeline no estruturador.
Adicione o componente Train PyTorch Model ao pipeline. Pode encontrar este componente na categoria Preparação de Modelos . Expanda Preparar e, em seguida, arraste o componente Train PyTorch Model para o pipeline.
Nota
Preparar o componente do Modelo PyTorch é melhor executado na computação do tipo GPU para um conjunto de dados grande, caso contrário, o pipeline falhará. Pode selecionar computação para um componente específico no painel direito do componente ao definir Utilizar outro destino de computação.
Na entrada esquerda, anexe um modelo não preparado. Anexe o conjunto de dados de preparação e o conjunto de dados de validação à entrada média e direita do Modelo Train PyTorch.
Para um modelo não preparado, tem de ser um modelo PyTorch como o DenseNet; caso contrário, será emitido um "InvalidModelDirectoryError".
Para o conjunto de dados, o conjunto de dados de preparação tem de ser um diretório de imagem etiquetado. Veja Converter para o Diretório de Imagens para saber como obter um diretório de imagem etiquetado. Se não estiver etiquetado, será emitido um "NotLabeledDatasetError".
O conjunto de dados de preparação e o conjunto de dados de validação têm as mesmas categorias de etiqueta, caso contrário, será emitido um InvalidDatasetError.
Para Épocas, especifique quantas épocas gostaria de preparar. Todo o conjunto de dados será iterado em cada época, por predefinição 5.
Para o tamanho do Batch, especifique quantas instâncias preparar num lote, por predefinição, 16.
Para o número do passo de aquecimento, especifique quantas épocas gostaria de aquecer a preparação, caso a taxa de aprendizagem inicial seja ligeiramente grande demais para começar a convergir, por predefinição 0.
Para Taxa de aprendizagem, especifique um valor para a taxa de aprendizagem e o valor predefinido é 0,001. A taxa de aprendizagem controla o tamanho do passo utilizado no otimizador como o sgd sempre que o modelo é testado e corrigido.
Ao definir a taxa mais pequena, testa o modelo com mais frequência, com o risco de ficar preso num planalto local. Ao definir a taxa maior, pode convergir mais rapidamente, com o risco de ultrapassar o verdadeiro minima.
Nota
Se a perda do comboio se tornar nan durante a preparação, o que pode ser causado por uma taxa de aprendizagem demasiado grande, a diminuição da taxa de aprendizagem pode ajudar. Na preparação distribuída, para manter a descida de gradação estável, a taxa de aprendizagem real é calculada porque
lr * torch.distributed.get_world_size()o tamanho do lote do grupo de processos é o tamanho do mundo vezes superior ao do processo único. A degradação da taxa de aprendizagem polinomial é aplicada e pode ajudar a resultar num modelo de melhor desempenho.Para Sementes aleatórias, escreva opcionalmente um valor inteiro para utilizar como semente. A utilização de uma semente é recomendada se quiser garantir a reprodutibilidade da experimentação em todas as tarefas.
Para Paciência, especifique a quantidade de épocas para parar a preparação antecipada se a perda de validação não diminuir consecutivamente. por predefinição 3.
Para Frequência de impressão, especifique a frequência de impressão do registo de preparação sobre iterações em cada época, por predefinição 10.
Submeta o pipeline. Se o conjunto de dados tiver um tamanho maior, demorará algum tempo e a computação de GPU será recomendada.
Preparação distribuída
Na preparação distribuída, a carga de trabalho para preparar um modelo é dividida e partilhada entre vários mini processadores, denominados nós de trabalho. Estes nós de trabalho funcionam em paralelo para acelerar a preparação de modelos. Atualmente, o estruturador suporta a preparação distribuída para o componente Train PyTorch Model .
Tempo de preparação
A preparação distribuída permite preparar um conjunto de dados grande como ImageNet (1000 classes, 1,2 milhões de imagens) em apenas várias horas por Train PyTorch Model. A tabela seguinte mostra o tempo de preparação e o desempenho durante a preparação de 50 épocas do Resnet50 na ImageNet de raiz com base em diferentes dispositivos.
| Dispositivos | Tempo de Preparação | Débito de Preparação | Precisão de Validação top-1 | Precisão de Validação top-5 |
|---|---|---|---|---|
| 16 GPUs V100 | 6h22min | ~3200 Imagens/Seg | 68.83% | 88.84% |
| 8 GPUs V100 | 12h21min | ~1670 Imagens/Seg | 68.84% | 88.74% |
Clique neste separador "Métricas" deste componente e veja gráficos de métricas de preparação, como "Preparar imagens por segundo" e "Precisão 1 superior".

Como ativar a preparação distribuída
Para ativar a preparação distribuída para preparar o componente do Modelo PyTorch , pode definir as definições da tarefa no painel direito do componente. Apenas o cluster de Computação AML é suportado para preparação distribuída.
Nota
São necessárias várias GPUs para ativar a preparação distribuída porque o componente Modelo PyTorch de Preparação de Back-end NCCL utiliza cuda de necessidades.
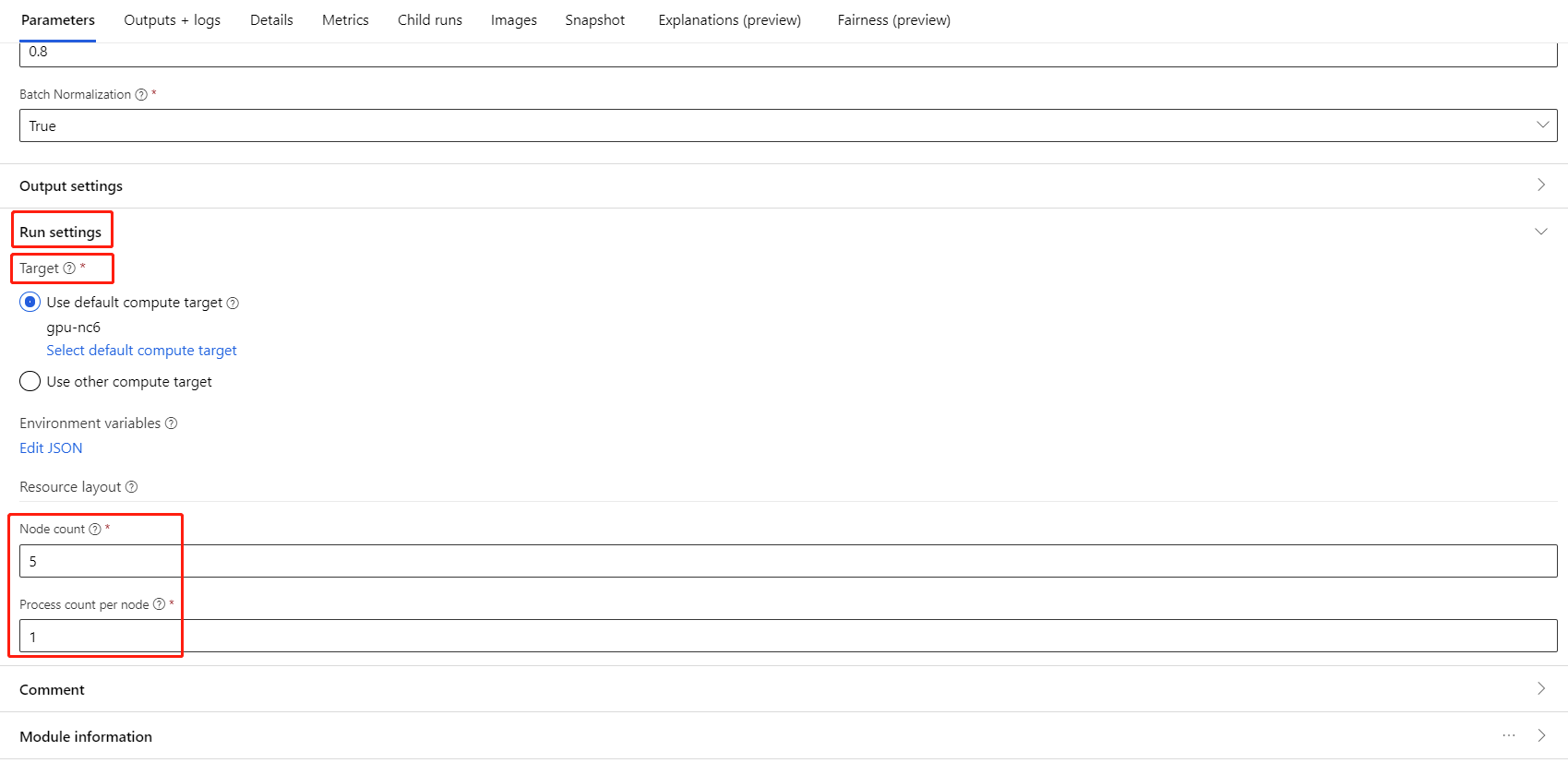
Selecione o componente e abra o painel direito. Expanda a secção Definições da tarefa.
Certifique-se de que selecionou computação AML para o destino de computação.
Na secção Esquema de recursos, tem de definir os seguintes valores:
Contagem de nós : número de nós no destino de computação utilizado para preparação. Deve ser menor ou igual aoNúmero máximo de nós do cluster de computação. Por predefinição, é 1, o que significa uma tarefa de nó único.
Contagem de processos por nó: número de processos acionados por nó. Deve ser menor ou igual àUnidade de Processamento da sua computação. Por predefinição, é 1, o que significa uma tarefa de processo único.
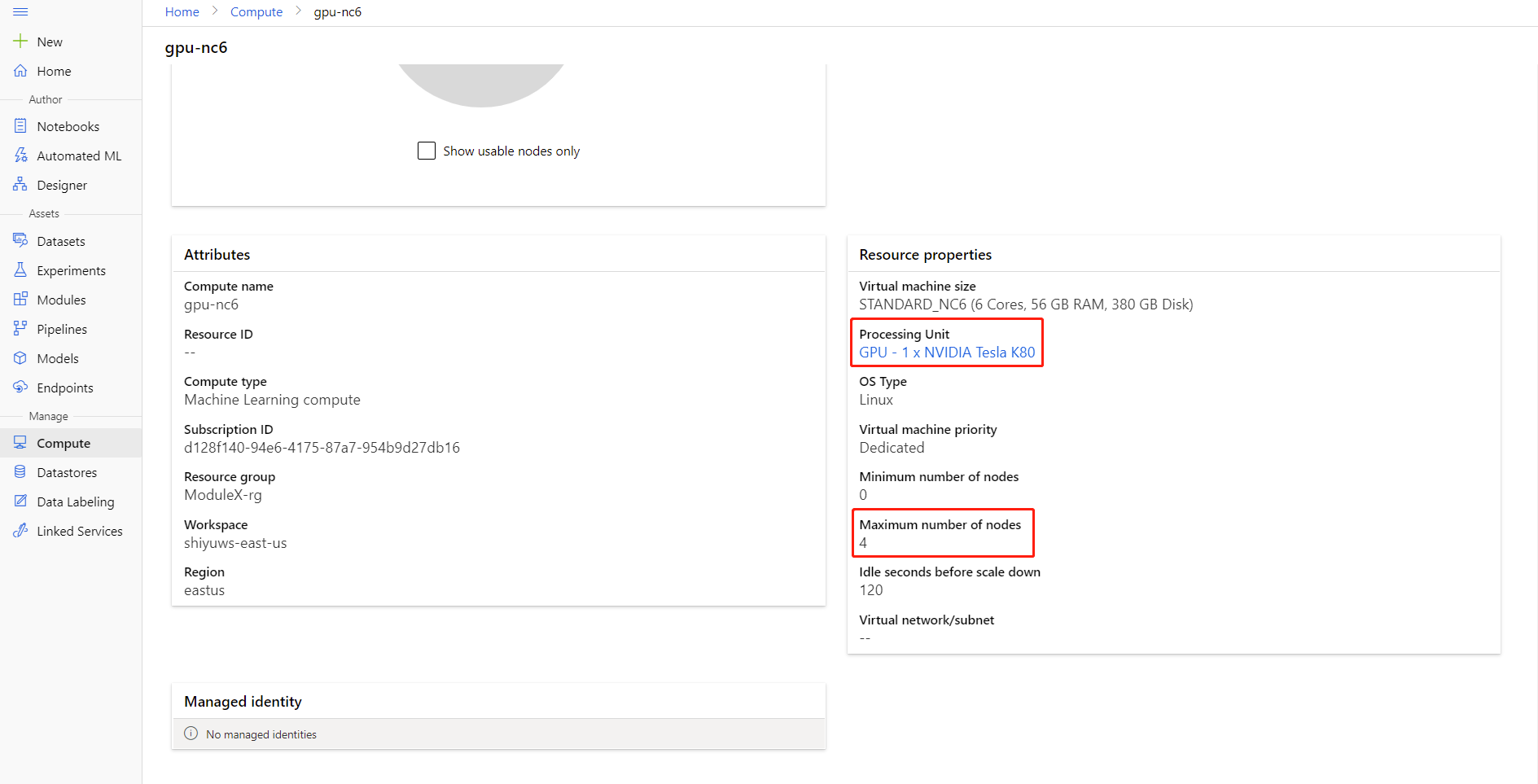
Pode verificar o número máximo de nós e Unidade de Processamento da sua computação ao clicar no nome da computação na página de detalhes de computação.


Pode saber mais sobre a formação distribuída no Azure Machine Learning aqui.
Resolução de problemas de preparação distribuída
Se ativar a preparação distribuída para este componente, haverá registos de controladores para cada processo. 70_driver_log_0 é para o processo principal. Pode verificar os registos de controladores para obter detalhes de erro de cada processo no separador Saídas+registos no painel direito.

Se a preparação distribuída ativada pelo componente falhar sem quaisquer 70_driver registos, pode verificar se existem 70_mpi_log detalhes do erro.
O exemplo seguinte mostra um erro comum, que é a Contagem de processos por nó maior do que a Unidade de Processamento da computação.

Pode consultar este artigo para obter mais detalhes sobre a resolução de problemas de componentes.
Resultados
Após a conclusão da tarefa de pipeline, para utilizar o modelo para classificação, ligue o Modelo De Preparação do PyTorch ao Modelo de Imagem de Classificação, para prever valores para novos exemplos de entrada.
Notas técnicas
Entradas esperadas
| Nome | Tipo | Descrição |
|---|---|---|
| Modelo não preparado | UntrainedModelDirectory | Modelo não preparado, exigir PyTorch |
| Conjunto de dados de preparação | ImageDirectory | Conjunto de dados de preparação |
| Conjunto de dados de validação | ImageDirectory | Conjunto de dados de validação para avaliação a cada época |
Parâmetros do componente
| Nome | Intervalo | Tipo | Predefinição | Description |
|---|---|---|---|---|
| Épocas | >0 | Número inteiro | 5 | Selecione a coluna que contém a etiqueta ou a coluna de resultados |
| Tamanho do lote | >0 | Número inteiro | 16 | Quantas instâncias preparar num lote |
| Número do passo de aquecimento | >=0 | Número inteiro | 0 | Quantas épocas para aquecer o treino |
| Taxa de aprendizagem | >=duplo. Epsilon | Float | 0.1 | A taxa de aprendizagem inicial do otimizador de Gradação de Gradação Estocástico. |
| Semente aleatória | Qualquer | Número inteiro | 1 | A semente do gerador de números aleatórios utilizado pelo modelo. |
| Paciência | >0 | Número inteiro | 3 | Quantas épocas para parar o treino precoce |
| Frequência de impressão | >0 | Número inteiro | 10 | Frequência de impressão do registo de preparação sobre iterações em cada época |
Saídas
| Nome | Tipo | Description |
|---|---|---|
| Modelo preparado | ModelDirectory | Modelo preparado |
Passos seguintes
Veja o conjunto de componentes disponíveis para o Azure Machine Learning.