Previsão em escala: muitos modelos e formação distribuída
Este artigo é sobre o treinamento de modelos de previsão em grandes quantidades de dados históricos. Instruções e exemplos para treinar modelos de previsão no AutoML podem ser encontrados em nosso artigo de configuração do AutoML para previsão de séries temporais .
Os dados de séries temporais podem ser grandes devido ao número de séries nos dados, ao número de observações históricas ou a ambos. Muitos modelos e séries temporais hierárquicas, ou HTS, são soluções de dimensionamento para o primeiro cenário, onde os dados consistem em um grande número de séries temporais. Nesses casos, pode ser benéfico para a precisão e escalabilidade do modelo particionar os dados em grupos e treinar um grande número de modelos independentes em paralelo nos grupos. Por outro lado, há cenários em que um ou um pequeno número de modelos de alta capacidade é melhor. O treinamento distribuído da DNN tem como alvo este caso. Revisamos os conceitos em torno desses cenários no restante do artigo.
Muitos modelos
Os muitos componentes de modelos no AutoML permitem treinar e gerenciar milhões de modelos em paralelo. Por exemplo, suponha que você tenha dados históricos de vendas para um grande número de lojas. Você pode usar muitos modelos para iniciar trabalhos de treinamento AutoML paralelos para cada loja, como no diagrama a seguir:

O componente de treinamento de muitos modelos aplica a varredura e seleção de modelos do AutoML de forma independente a cada loja neste exemplo. Essa independência do modelo ajuda na escalabilidade e pode beneficiar a precisão do modelo, especialmente quando as lojas têm dinâmicas de vendas divergentes. No entanto, uma abordagem de modelo único pode produzir previsões mais precisas quando há dinâmicas de vendas comuns. Consulte a seção de treinamento DNN distribuído para obter mais detalhes sobre esse caso.
Você pode configurar o particionamento de dados, as configurações de AutoML para os modelos e o grau de paralelismo para muitos trabalhos de treinamento de modelos. Para exemplos, consulte a nossa secção de guia sobre muitos componentes de modelos.
Previsão hierárquica de séries cronológicas
É comum que séries cronológicas em aplicativos de negócios tenham atributos aninhados que formam uma hierarquia. Os atributos geográficos e do catálogo de produtos geralmente são aninhados, por exemplo. Considere um exemplo em que a hierarquia tem dois atributos geográficos, estado e ID de armazenamento, e dois atributos de produto, categoria e SKU:

Esta hierarquia é ilustrada no diagrama seguinte:

É importante ressaltar que as quantidades de vendas no nível de folha (SKU) somam as quantidades de vendas agregadas nos níveis de vendas estaduais e totais. Os métodos de previsão hierárquica preservam essas propriedades de agregação ao prever a quantidade vendida em qualquer nível da hierarquia. As previsões com esta propriedade são coerentes em relação à hierarquia.
O AutoML suporta os seguintes recursos para séries temporais hierárquicas (HTS):
- Formação a qualquer nível da hierarquia. Em alguns casos, os dados ao nível das folhas podem ser ruidosos, mas os agregados podem ser mais passíveis de previsão.
- Recuperação de previsões de pontos em qualquer nível da hierarquia. Se o nível de previsão estiver "abaixo" do nível de formação, as previsões do nível de formação são desagregadas através de proporções históricas médias ou proporções de médias históricas. As previsões de nível de formação são somadas de acordo com a estrutura de agregação quando o nível de previsão está "acima" do nível de formação.
- Recuperação de previsões quantis/probabilísticas para níveis iguais ou "abaixo" do nível de formação. Os recursos de modelagem atuais suportam a desagregação de previsões probabilísticas.
Os componentes HTS no AutoML são construídos em cima de muitos modelos, de modo que o HTS compartilha as propriedades escaláveis de muitos modelos. Para exemplos, consulte nossa seção de guia sobre componentes HTS.
Formação DNN distribuída (pré-visualização)
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Cenários de dados com grandes quantidades de observações históricas e/ou um grande número de séries temporais relacionadas podem se beneficiar de uma abordagem de modelo único escalável. Assim, o AutoML suporta treinamento distribuído e pesquisa de modelos em modelos de rede convolucional temporal (TCN), que são um tipo de rede neural profunda (DNN) para dados de séries temporais. Para obter mais informações sobre a classe de modelo TCN do AutoML, consulte nosso artigo DNN.
O treinamento DNN distribuído alcança escalabilidade usando um algoritmo de particionamento de dados que respeita os limites das séries temporais. O diagrama a seguir ilustra um exemplo simples com duas partições:
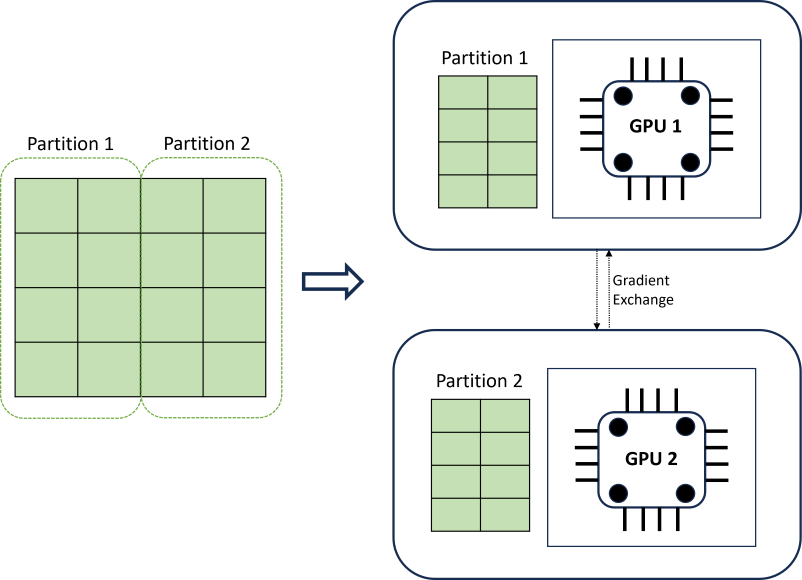
Durante o treinamento, os carregadores de dados DNN em cada computação carregam exatamente o que precisam para concluir uma iteração de retropropagação; todo o conjunto de dados nunca é lido na memória. As partições são distribuídas em vários núcleos de computação (geralmente GPUs) em possivelmente vários nós para acelerar o treinamento. A coordenação entre cálculos é fornecida pela estrutura Horovod .
Próximos passos
- Saiba mais sobre como configurar o AutoML para treinar um modelo de previsão de séries temporais.
- Saiba mais sobre como o AutoML usa o aprendizado de máquina para criar modelos de previsão.
- Saiba mais sobre modelos de aprendizagem profunda para previsão no AutoML