Criar e executar pipelines de aprendizagem automática com o SDK do Azure Machine Learning
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Neste artigo, você aprenderá a criar e executar pipelines de aprendizado de máquina usando o SDK do Azure Machine Learning. Use pipelines de ML para criar um fluxo de trabalho que una várias fases de ML. Em seguida, publique esse pipeline para acesso posterior ou compartilhamento com outras pessoas. Acompanhe os pipelines de ML para ver o desempenho do seu modelo no mundo real e detetar desvio de dados. Os pipelines de ML são ideais para cenários de pontuação em lote, usando vários cálculos, reutilizando etapas em vez de executá-las novamente e compartilhando fluxos de trabalho de ML com outras pessoas.
Este artigo não é um tutorial. Para obter orientação sobre como criar seu primeiro pipeline, consulte Tutorial: Criar um pipeline do Azure Machine Learning para pontuação em lote ou Usar ML automatizado em um pipeline do Azure Machine Learning em Python.
Embora você possa usar um tipo diferente de pipeline chamado Pipeline do Azure para automação de CI/CD de tarefas de ML, esse tipo de pipeline não é armazenado em seu espaço de trabalho. Compare esses diferentes pipelines.
Os pipelines de ML criados são visíveis para os membros do seu espaço de trabalho do Azure Machine Learning.
Os pipelines de ML são executados em destinos de computação (consulte O que são destinos de computação no Azure Machine Learning). Os pipelines podem ler e gravar dados de e para locais de Armazenamento do Azure suportados.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
Pré-requisitos
Uma área de trabalho do Azure Machine Learning. Crie recursos de espaço de trabalho.
Configure seu ambiente de desenvolvimento para instalar o SDK do Azure Machine Learning ou use uma instância de computação do Azure Machine Learning com o SDK já instalado.
Comece por anexar a sua área de trabalho:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Configurar recursos de aprendizagem automática
Crie os recursos necessários para executar um pipeline de ML:
Configure um armazenamento de dados usado para acessar os dados necessários nas etapas de pipeline.
Configure um
Datasetobjeto para apontar para dados persistentes que vivem ou estão acessíveis em um armazenamento de dados. Configure umOutputFileDatasetConfigobjeto para dados temporários passados entre as etapas do pipeline.Configure os destinos de computação nos quais as etapas do pipeline serão executadas.
Configurar um armazenamento de dados
Um armazenamento de dados armazena os dados para o pipeline acessar. Cada espaço de trabalho tem um armazenamento de dados padrão. Você pode registrar mais datastores.
Quando você cria seu espaço de trabalho, os Arquivos do Azure e o armazenamento de Blob do Azure são anexados ao espaço de trabalho. Um armazenamento de dados padrão é registrado para se conectar ao armazenamento de Blob do Azure. Para saber mais, consulte Decidir quando usar Arquivos do Azure, Blobs do Azure ou Discos do Azure.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
As etapas geralmente consomem dados e produzem dados de saída. Uma etapa pode criar dados como um modelo, um diretório com arquivos de modelo e dependentes ou dados temporários. Esses dados ficam disponíveis para outras etapas mais adiante no pipeline. Para saber mais sobre como conectar seu pipeline aos seus dados, consulte os artigos Como acessar dados e Como registrar conjuntos de dados.
Configurar dados com Dataset e OutputFileDatasetConfig objetos
A maneira preferida de fornecer dados a um pipeline é um objeto Dataset . O Dataset objeto aponta para dados que vivem ou são acessíveis a partir de um armazenamento de dados ou em uma URL da Web. A Dataset classe é abstrata, portanto, você criará uma instância de um FileDataset (referindo-se a um ou mais arquivos) ou um TabularDataset que é criado por um ou mais arquivos com colunas de dados delimitadas.
Você cria um Dataset usando métodos como from_files ou from_delimited_files.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
Os dados intermediários (ou a saída de uma etapa) são representados por um objeto OutputFileDatasetConfig . output_data1 é produzido como a saída de uma etapa. Opcionalmente, esses dados podem ser registrados como um conjunto de dados chamando register_on_complete. Se você criar um OutputFileDatasetConfig em uma etapa e usá-lo como uma entrada para outra etapa, essa dependência de dados entre as etapas criará uma ordem de execução implícita no pipeline.
OutputFileDatasetConfig objetos retornam um diretório e, por padrão, gravam a saída no armazenamento de dados padrão do espaço de trabalho.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Importante
Os dados intermediários armazenados usando OutputFileDatasetConfig não são excluídos automaticamente pelo Azure.
Você deve excluir programaticamente dados intermediários no final de uma execução de pipeline, usar um armazenamento de dados com uma política de retenção de dados curta ou fazer limpeza manual regularmente.
Gorjeta
Carregue apenas ficheiros relevantes para o trabalho em questão. Quaisquer alterações nos ficheiros no diretório de dados serão encaradas como motivo para voltar a executar o passo na próxima vez que o pipeline for executado, mesmo que a reutilização seja especificada.
Configurar um destino de computação
No Azure Machine Learning, o termo computação (ou destino de computação) refere-se às máquinas ou clusters que executam as etapas computacionais em seu pipeline de aprendizado de máquina. Consulte Destinos de computação para treinamento de modelo para obter uma lista completa de destinos de computação e Criar destinos de computação para saber como criá-los e anexá-los ao seu espaço de trabalho. O processo para criar e/ou anexar um destino de computação é o mesmo, quer você esteja treinando um modelo ou executando uma etapa de pipeline. Depois de criar e anexar o destino de computação, use o ComputeTarget objeto na etapa de pipeline.
Importante
Não há suporte para a execução de operações de gerenciamento em destinos de computação dentro de trabalhos remotos. Como os pipelines de aprendizagem automática são enviados como um trabalho remoto, não utilize operações de gestão em destinos de computação a partir do pipeline.
Computação do Azure Machine Learning
Você pode criar uma computação do Azure Machine Learning para executar suas etapas. O código para outros destinos de computação é semelhante, com parâmetros ligeiramente diferentes, dependendo do tipo.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Configurar o ambiente da execução de treinamento
O próximo passo é certificar-se de que a execução de treinamento remoto tenha todas as dependências necessárias para as etapas de treinamento. As dependências e o contexto de tempo de execução são definidos criando e configurando um RunConfiguration objeto.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
O código acima mostra duas opções para lidar com dependências. Conforme apresentado, com USE_CURATED_ENV = Trueo , a configuração é baseada em um ambiente com curadoria. Os ambientes com curadoria são "pré-preparados" com bibliotecas interdependentes comuns e podem ser mais rápidos de colocar online. Os ambientes com curadoria têm imagens pré-criadas do Docker no Microsoft Container Registry. Para obter mais informações, consulte Ambientes com curadoria do Azure Machine Learning.
O caminho percorrido se você mudar USE_CURATED_ENV para False mostra o padrão para definir explicitamente suas dependências. Nesse cenário, uma nova imagem personalizada do Docker será criada e registrada em um Registro de Contêiner do Azure dentro do seu grupo de recursos (consulte Introdução aos registros de contêiner privados do Docker no Azure). Construir e registrar essa imagem pode levar alguns minutos.
Criar os passos do pipeline
Depois de criar o recurso de computação e o ambiente, você estará pronto para definir as etapas do pipeline. Há muitas etapas internas disponíveis por meio do SDK do Azure Machine Learning, como você pode ver na documentação de referência do azureml.pipeline.steps pacote. A classe mais flexível é PythonScriptStep, que executa um script Python.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
O código acima mostra uma etapa inicial típica do pipeline. Seu código de preparação de dados está em um subdiretório (neste exemplo, "prepare.py" no diretório "./dataprep.src"). Como parte do processo de criação do pipeline, esse diretório é compactado e carregado para o compute_target e a etapa executa o script especificado como o valor de script_name.
Os arguments valores especificam as entradas e saídas da etapa. No exemplo acima, os dados da linha de base são o my_dataset conjunto de dados. Os dados correspondentes serão baixados para o recurso de computação, uma vez que o código os especifica como as_download(). O script prepare.py faz todas as tarefas de transformação de dados apropriadas para a tarefa em questão e envia os dados para output_data1, do tipo OutputFileDatasetConfig. Para obter mais informações, consulte Movendo dados para e entre etapas de pipeline de ML (Python).
A etapa será executada na máquina definida por compute_target, usando a configuração aml_run_config.
A reutilização de resultados anteriores (allow_reuse) é fundamental ao usar pipelines em um ambiente colaborativo, uma vez que eliminar reexecuções desnecessárias oferece agilidade. A reutilização é o comportamento padrão quando a script_name, as entradas e os parâmetros de uma etapa permanecem os mesmos. Quando a reutilização é permitida, os resultados da execução anterior são imediatamente enviados para a próxima etapa. Se allow_reuse estiver definido como False, uma nova execução sempre será gerada para esta etapa durante a execução do pipeline.
É possível criar um pipeline com uma única etapa, mas quase sempre você optará por dividir seu processo geral em várias etapas. Por exemplo, você pode ter etapas para preparação de dados, treinamento, comparação de modelos e implantação. Por exemplo, pode-se imaginar que, após o especificado acima, o próximo passo pode ser o data_prep_step treinamento:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
O código acima é semelhante ao código na etapa de preparação de dados. O código de treinamento está em um diretório separado do código de preparação de dados. A OutputFileDatasetConfig saída da etapa output_data1 de preparação de dados é usada como entrada para a etapa de treinamento. Um novo OutputFileDatasetConfig objeto training_results é criado para armazenar os resultados para uma comparação posterior ou etapa de implantação.
Para obter outros exemplos de código, consulte como criar um pipeline de ML de duas etapas e como gravar dados de volta em armazenamentos de dados após a conclusão da execução.
Depois de definir suas etapas, você cria o pipeline usando algumas ou todas essas etapas.
Nota
Nenhum arquivo ou dado é carregado no Aprendizado de Máquina do Azure quando você define as etapas ou cria o pipeline. Os arquivos são carregados quando você chama Experiment.submit().
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Usar um conjunto de dados
Os conjuntos de dados criados a partir do armazenamento de Blob do Azure, Arquivos do Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Banco de Dados SQL do Azure e Banco de Dados do Azure para PostgreSQL podem ser usados como entrada para qualquer etapa de pipeline. Você pode gravar a saída em um DataTransferStep, DatabricksStep ou, se quiser gravar dados em um armazenamento de dados específico, use OutputFileDatasetConfig.
Importante
A escrita de dados de saída novamente num arquivo de dados com OutputFileDatasetConfig é suportada apenas para arquivos de dados de Blobs do Azure, Partilha de Ficheiros do Azure, ADLS Gen1 e Gen2.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
Em seguida, você recupera o conjunto de dados em seu pipeline usando o dicionário Run.input_datasets .
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
A linha Run.get_context() merece destaque. Esta função recupera um Run que representa a execução experimental atual. No exemplo acima, nós o usamos para recuperar um conjunto de dados registrado. Outro uso comum do Run objeto é recuperar o próprio experimento e o espaço de trabalho no qual o experimento reside:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Para obter mais detalhes, incluindo maneiras alternativas de passar e acessar dados, consulte Movendo dados para e entre etapas de pipeline de ML (Python).
Armazenamento em cache e reutilização
Para otimizar e personalizar o comportamento de seus pipelines, você pode fazer algumas coisas em torno do cache e da reutilização. Por exemplo, pode optar por:
- Desative a reutilização padrão da saída de execução de etapa definindo
allow_reuse=Falsedurante a definição de etapa. A reutilização é fundamental ao usar pipelines em um ambiente colaborativo, uma vez que eliminar execuções desnecessárias oferece agilidade. No entanto, pode optar por não reutilizar. - Força a regeneração de saída para todas as etapas de uma execução com
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)
Por padrão, allow_reuse para etapas é habilitado e o source_directory especificado na definição de etapa é hash. Assim, se o script para uma determinada etapa permanecer o mesmo (script_name, entradas e parâmetros), e nada mais no source_directory tiver mudado, a saída de uma execução de etapa anterior será reutilizada, o trabalho não será enviado para a computação e os resultados da execução anterior estarão imediatamente disponíveis para a próxima etapa.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Nota
Se os nomes das entradas de dados mudarem, a etapa será executada novamente, mesmo que os dados subjacentes não sejam alterados. Você deve definir explicitamente o name campo de dados de entrada (data.as_input(name=...)). Se você não definir explicitamente esse valor, o name campo será definido como um guid aleatório e os resultados da etapa não serão reutilizados.
Enviar o pipeline
Quando você envia o pipeline, o Aprendizado de Máquina do Azure verifica as dependências de cada etapa e carrega um instantâneo do diretório de origem especificado. Se nenhum diretório de origem for especificado, o diretório local atual será carregado. O instantâneo também é armazenado como parte do experimento em seu espaço de trabalho.
Importante
Para evitar que arquivos desnecessários sejam incluídos no instantâneo, crie um arquivo de ignorar (.gitignore ou .amlignore) no diretório. Adicione os ficheiros e os diretórios a excluir neste ficheiro. Para obter mais informações sobre a sintaxe a ser usada dentro desse arquivo, consulte sintaxe e padrões para .gitignore. O .amlignore arquivo usa a mesma sintaxe. Se ambos os arquivos existirem, o .amlignore arquivo será usado e o .gitignore arquivo não será usado.
Para obter mais informações, consulte Instantâneos.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
Quando você executa um pipeline pela primeira vez, o Aprendizado de Máquina do Azure:
Baixa o instantâneo do projeto para o destino de computação do armazenamento de Blob associado ao espaço de trabalho.
Cria uma imagem do Docker correspondente a cada etapa do pipeline.
Baixa a imagem do Docker para cada etapa para o destino de computação do registro do contêiner.
Configura o acesso a
DataseteOutputFileDatasetConfigobjetos. Paraas_mount()o modo de acesso, o FUSE é usado para fornecer acesso virtual. Se a montagem não for suportada ou se o usuário especificou o acesso comoas_upload(), os dados serão copiados para o destino de computação.Executa a etapa no destino de computação especificado na definição da etapa.
Cria artefatos, como logs, stdout e stderr, métricas e saída especificadas pela etapa. Esses artefatos são então carregados e mantidos no armazenamento de dados padrão do usuário.
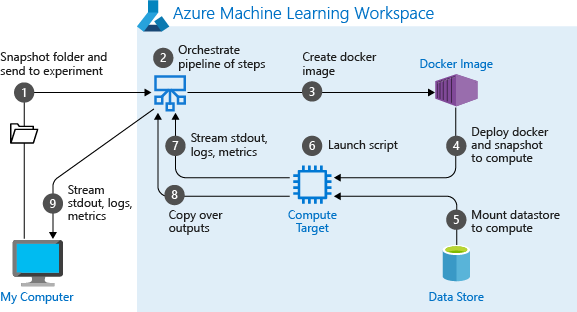
Para obter mais informações, consulte a referência da classe Experiment.
Usar parâmetros de pipeline para argumentos que mudam no momento da inferência
Às vezes, os argumentos para etapas individuais dentro de um pipeline estão relacionados ao período de desenvolvimento e treinamento: coisas como taxas de treinamento e momentum, ou caminhos para dados ou arquivos de configuração. Quando um modelo é implantado, no entanto, você vai querer passar dinamicamente os argumentos sobre os quais você está inferindo (ou seja, a consulta que você criou o modelo para responder!). Você deve fazer esses tipos de parâmetros de pipeline de argumentos. Para fazer isso em Python, use a azureml.pipeline.core.PipelineParameter classe, conforme mostrado no seguinte trecho de código:
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Como os ambientes Python funcionam com parâmetros de pipeline
Conforme discutido anteriormente em Configurar o ambiente da execução de treinamento, o estado do ambiente e as dependências da biblioteca Python são especificados usando um Environment objeto. Geralmente, você pode especificar um existente Environment referindo-se ao seu nome e, opcionalmente, a uma versão:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
No entanto, se você optar por usar PipelineParameter objetos para definir dinamicamente variáveis em tempo de execução para suas etapas de pipeline, não poderá usar essa técnica de referência a um arquivo Environment. Em vez disso, se você quiser usar PipelineParameter objetos, você deve definir o environment campo do RunConfiguration para um Environment objeto. É sua responsabilidade garantir que tal um Environment tenha suas dependências em pacotes Python externos definidos corretamente.
Exibir resultados de um pipeline
Veja a lista de todos os seus pipelines e seus detalhes de execução no estúdio:
Entre no estúdio do Azure Machine Learning.
À esquerda, selecione Pipelines para ver todas as execuções do pipeline.
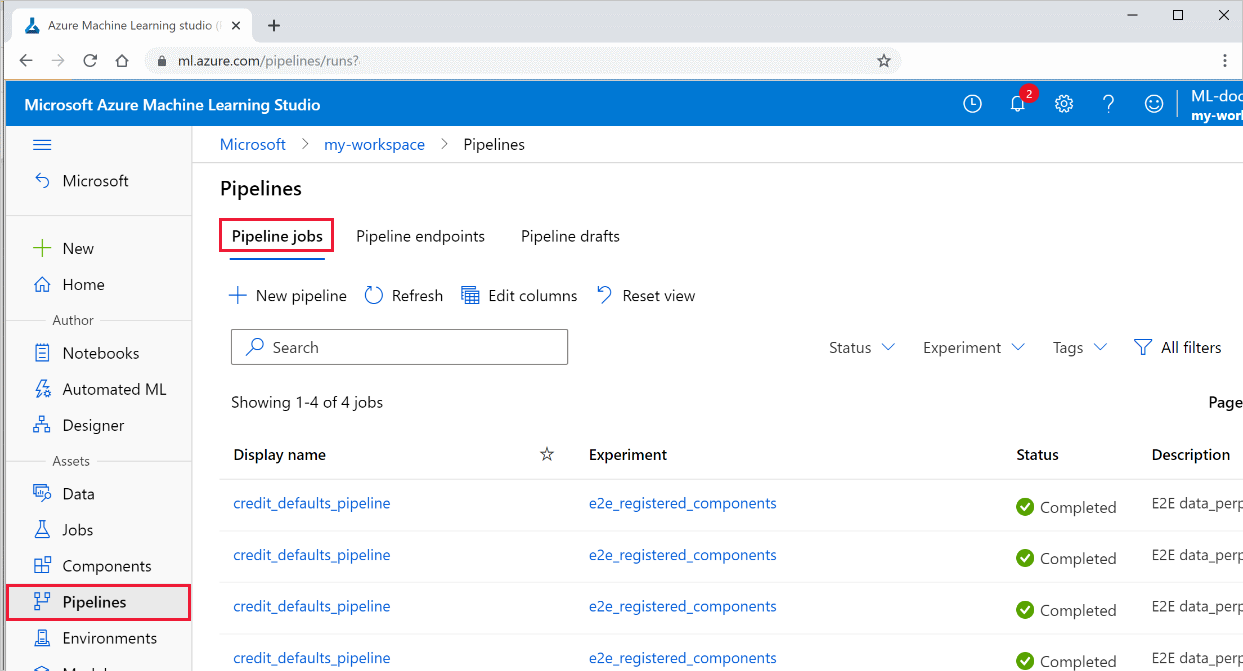
Selecione um pipeline específico para ver os resultados da execução.
Rastreamento e integração com Git
Quando você inicia uma execução de treinamento em que o diretório de origem é um repositório Git local, as informações sobre o repositório são armazenadas no histórico de execução. Para obter mais informações, consulte Integração do Git para o Azure Machine Learning.
Próximos passos
- Para compartilhar seu pipeline com colegas ou clientes, consulte Publicar pipelines de aprendizado de máquina
- Use esses notebooks Jupyter no GitHub para explorar ainda mais os pipelines de aprendizado de máquina
- Consulte a ajuda de referência do SDK para o pacote azureml-pipelines-core e o pacote azureml-pipelines-steps
- Consulte o tutorial para obter dicas sobre depuração e solução de problemas de pipelines=
- Saiba como executar blocos de notas ao seguir o artigo Utilizar blocos de notas Jupyter para explorar este serviço.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários