Disputa interativa de dados com o Apache Spark no Azure Machine Learning
A disputa de dados torna-se uma das etapas mais importantes em projetos de aprendizado de máquina. A integração do Azure Machine Learning, com o Azure Synapse Analytics, fornece acesso a um pool do Apache Spark - apoiado pelo Azure Synapse - para disputa de dados interativa usando os Blocos de Anotações do Azure Machine Learning.
Neste artigo, você aprenderá como executar disputas de dados usando
- Computação do Spark sem servidor
- Piscina Synapse Spark anexada
Pré-requisitos
- Uma assinatura do Azure; se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Uma área de trabalho do Azure Machine Learning. Consulte Criar recursos do espaço de trabalho.
- Uma conta de armazenamento do Azure Data Lake Storage (ADLS) Gen 2. Consulte Criar uma conta de armazenamento do Azure Data Lake Storage (ADLS) Gen 2.
- (Opcional): Um Cofre de Chaves do Azure. Consulte Criar um Cofre de Chaves do Azure.
- (Opcional): Uma entidade de serviço. Consulte Criar uma entidade de serviço.
- (Opcional): um pool Synapse Spark anexado no espaço de trabalho do Azure Machine Learning.
Antes de iniciar suas tarefas de disputa de dados, saiba mais sobre o processo de armazenamento de segredos
- Chave de acesso da conta de armazenamento de Blob do Azure
- Token de Assinatura de Acesso Compartilhado (SAS)
- Informações principais do serviço Azure Data Lake Storage (ADLS) Gen 2
no Cofre da Chave do Azure. Você também precisa saber como lidar com atribuições de função nas contas de armazenamento do Azure. As seções a seguir analisam esses conceitos. Em seguida, exploraremos os detalhes da disputa interativa de dados usando os pools do Spark nos Blocos de Anotações do Azure Machine Learning.
Gorjeta
Para saber mais sobre a configuração de atribuição de função de conta de armazenamento do Azure ou se você acessar dados em suas contas de armazenamento usando passagem de identidade de usuário, consulte Adicionar atribuições de função em contas de armazenamento do Azure.
Disputa interativa de dados com o Apache Spark
O Azure Machine Learning oferece computação Spark sem servidor e pool Synapse Spark anexado para disputa de dados interativa com o Apache Spark em Blocos de Anotações do Azure Machine Learning. A computação do Spark sem servidor não requer a criação de recursos no espaço de trabalho do Azure Synapse. Em vez disso, uma computação Spark sem servidor totalmente gerenciada fica disponível diretamente nos Blocos de Anotações do Azure Machine Learning. Usar uma computação do Spark sem servidor é a abordagem mais fácil para acessar um cluster do Spark no Azure Machine Learning.
Computação do Serverless Spark nos Blocos de Anotações do Azure Machine Learning
Uma computação do Spark sem servidor está disponível nos Blocos de Anotações do Azure Machine Learning por padrão. Para acessá-lo em um bloco de anotações, selecione Serverless Spark Compute em Azure Machine Learning Serverless Spark no menu de seleção Compute .
A interface do usuário do Notebooks também fornece opções para a configuração da sessão do Spark, para a computação do Spark sem servidor. Para configurar uma sessão do Spark:
- Selecione Configurar sessão na parte superior da tela.
- Selecione Versão do Apache Spark no menu suspenso.
Importante
Azure Synapse Runtime for Apache Spark: Anúncios
- Azure Synapse Runtime para Apache Spark 3.2:
- Data de anúncio EOLA: 8 de julho de 2023
- Data de fim do suporte: 8 de julho de 2024. Após essa data, o tempo de execução será desativado.
- Para suporte contínuo e desempenho ideal, recomendamos que você migre para o Apache Spark 3.3.
- Azure Synapse Runtime para Apache Spark 3.2:
- Selecione Tipo de instância no menu suspenso. Os seguintes tipos de instância são suportados atualmente:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Insira um valor de tempo limite da Sessão Spark, em minutos.
- Selecione se deseja alocar executores dinamicamente
- Selecione o número de Executores para a sessão do Spark.
- Selecione Tamanho do executor no menu suspenso.
- Selecione Tamanho do driver no menu suspenso.
- Para usar um arquivo Conda para configurar uma sessão do Spark, marque a caixa de seleção Carregar arquivo conda. Em seguida, selecione Procurar e escolha o arquivo Conda com a configuração de sessão do Spark desejada.
- Adicione propriedades de definições de configuração, valores de entrada nas caixas de texto Propriedade e Valor e selecione Adicionar.
- Selecione Aplicar.
- Selecione Parar sessão no pop-up Configurar nova sessão?
As alterações de configuração da sessão persistem e ficam disponíveis para outra sessão de bloco de anotações que é iniciada usando a computação do Spark sem servidor.
Gorjeta
Se você usar pacotes Conda no nível da sessão, poderá melhorar o tempo de início a frio da sessão do Spark se definir a variável spark.hadoop.aml.enable_cache de configuração como true. Um início frio de sessão com pacotes Conda de nível de sessão normalmente leva de 10 a 15 minutos quando a sessão começa pela primeira vez. No entanto, o início frio da sessão subsequente com a variável de configuração definida como true normalmente leva de três a cinco minutos.
Importar e processar dados do Azure Data Lake Storage (ADLS) Gen 2
Você pode acessar e processar dados armazenados em contas de armazenamento do Azure Data Lake Storage (ADLS) Gen 2 com abfss:// URIs de dados seguindo um dos dois mecanismos de acesso a dados:
- Passagem de identidade do usuário
- Acesso a dados baseado em entidade de serviço
Gorjeta
A disputa de dados com uma computação Spark sem servidor e a passagem de identidade do usuário para acessar dados em uma conta de armazenamento do Azure Data Lake Storage (ADLS) Gen 2 exigem o menor número de etapas de configuração.
Para iniciar a disputa interativa de dados com a passagem de identidade do usuário:
Verifique se a identidade do usuário tem atribuições de função de Colaborador e Colaborador de Dados de Blob de Armazenamento na conta de armazenamento do Azure Data Lake Storage (ADLS) Gen 2.
Para usar a computação do Spark sem servidor, selecione Serverless Spark Compute em Azure Machine Learning Serverless Spark no menu de seleção Compute .
Para usar um pool Synapse Spark anexado, selecione um pool Synapse Spark anexado em Synapse Spark pools no menu Seleção de computação.
Este exemplo de código de disputa de dados do Titanic mostra o uso de um URI de dados no formato
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>compyspark.pandasepyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Nota
Este exemplo de código Python usa
pyspark.pandas. Somente o tempo de execução do Spark versão 3.2 ou posterior suporta isso.
Para processar dados por meio de acesso por meio de uma entidade de serviço:
Verifique se a entidade de serviço tem atribuições de função de Colaborador e Colaborador de Dados de Blob de Armazenamento na conta de armazenamento do Azure Data Lake Storage (ADLS) Gen 2.
Crie segredos do Cofre da Chave do Azure para a ID do locatário da entidade de serviço, a ID do cliente e os valores do segredo do cliente.
Selecione Serverless Spark compute em Azure Machine Learning Serverless Spark no menu de seleção Compute ou selecione um pool Synapse Spark anexado em Synapse Spark pools no menu de seleção Compute .
Para definir a ID do locatário da entidade de serviço, a ID do cliente e o segredo do cliente na configuração e execute o exemplo de código a seguir.
A
get_secret()chamada no código depende do nome do Cofre da Chave do Azure e dos nomes dos segredos do Cofre da Chave do Azure criados para a ID do locatário da entidade de serviço, a ID do cliente e o segredo do cliente. Defina estes nomes/valores de propriedade correspondentes na configuração:- Propriedade ID do cliente:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Propriedade secreta do cliente:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Propriedade ID do inquilino:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Valor da ID do locatário:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Propriedade ID do cliente:
Importe e escreva dados usando URI de dados no formato
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>mostrado no exemplo de código, usando os dados do Titanic.
Importar e processar dados do armazenamento de Blob do Azure
Você pode acessar os dados de armazenamento de Blob do Azure com a chave de acesso da conta de armazenamento ou um token de assinatura de acesso compartilhado (SAS). Você deve armazenar essas credenciais no Cofre da Chave do Azure como um segredo e defini-las como propriedades na configuração da sessão.
Para iniciar a disputa interativa de dados:
No painel esquerdo do estúdio de Aprendizado de Máquina do Azure, selecione Blocos de Anotações.
Selecione Serverless Spark compute em Azure Machine Learning Serverless Spark no menu de seleção Compute ou selecione um pool Synapse Spark anexado em Synapse Spark pools no menu de seleção Compute .
Para configurar a chave de acesso da conta de armazenamento ou um token de assinatura de acesso compartilhado (SAS) para acesso a dados nos Blocos de Anotações do Azure Machine Learning:
Para a chave de acesso, defina a propriedade
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netcomo mostrado neste trecho de código:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Para o token SAS, defina a propriedade
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netcomo mostrado neste trecho de código:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Nota
As
get_secret()chamadas nos trechos de código acima exigem o nome do Cofre de Chaves do Azure e os nomes dos segredos criados para a chave de acesso da conta de armazenamento de Blob do Azure ou token SAS
Execute o código de disputa de dados no mesmo bloco de anotações. Formate o URI de dados como
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>, semelhante ao que este trecho de código mostra:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Nota
Este exemplo de código Python usa
pyspark.pandas. Somente o tempo de execução do Spark versão 3.2 ou posterior suporta isso.
Importar e processar dados do Azure Machine Learning Datastore
Para acessar dados do Repositório de Dados do Azure Machine Learning, defina um caminho para os dados no armazenamento de dados com o formato azureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>URI. Para extrair dados de um armazenamento de dados do Azure Machine Learning em uma sessão do Notebooks de forma interativa:
Selecione Serverless Spark compute em Azure Machine Learning Serverless Spark no menu de seleção Compute ou selecione um pool Synapse Spark anexado em Synapse Spark pools no menu de seleção Compute .
Este exemplo de código mostra como ler e distorcer dados do Titanic de um armazenamento de dados do Azure Machine Learning, usando
azureml://o URIpyspark.pandasdo armazenamento de dados epyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Nota
Este exemplo de código Python usa
pyspark.pandas. Somente o tempo de execução do Spark versão 3.2 ou posterior suporta isso.
Os armazenamentos de dados do Azure Machine Learning podem acessar dados usando credenciais de conta de armazenamento do Azure
- chave de acesso
- Token de SAS
- principal de serviço
ou fornecer acesso a dados sem credenciais. Dependendo do tipo de armazenamento de dados e do tipo de conta de armazenamento subjacente do Azure, selecione um mecanismo de autenticação apropriado para garantir o acesso aos dados. Esta tabela resume os mecanismos de autenticação para acessar dados nos armazenamentos de dados do Azure Machine Learning:
| Storage account type | Acesso a dados sem credenciais | Mecanismo de acesso aos dados | Atribuições de funções |
|---|---|---|---|
| Blob do Azure | Não | Chave de acesso ou token SAS | Não são necessárias atribuições de função |
| Blob do Azure | Sim | Passagem de identidade do usuário* | A identidade do usuário deve ter atribuições de função apropriadas na conta de armazenamento de Blob do Azure |
| Armazenamento Azure Data Lake (ADLS) Gen 2 | Não | Service principal (Principal de serviço) | A entidade de serviço deve ter atribuições de função apropriadas na conta de armazenamento do Azure Data Lake Storage (ADLS) Gen 2 |
| Armazenamento Azure Data Lake (ADLS) Gen 2 | Sim | Passagem de identidade do usuário | A identidade do usuário deve ter atribuições de função apropriadas na conta de armazenamento do Azure Data Lake Storage (ADLS) Gen 2 |
* A passagem de identidade do usuário funciona para armazenamentos de dados sem credenciais que apontam para contas de armazenamento de Blob do Azure, somente se a exclusão suave não estiver habilitada.
Acessando dados no compartilhamento de arquivos padrão
O compartilhamento de arquivos padrão é montado na computação do Spark sem servidor e nos pools Synapse Spark anexados.
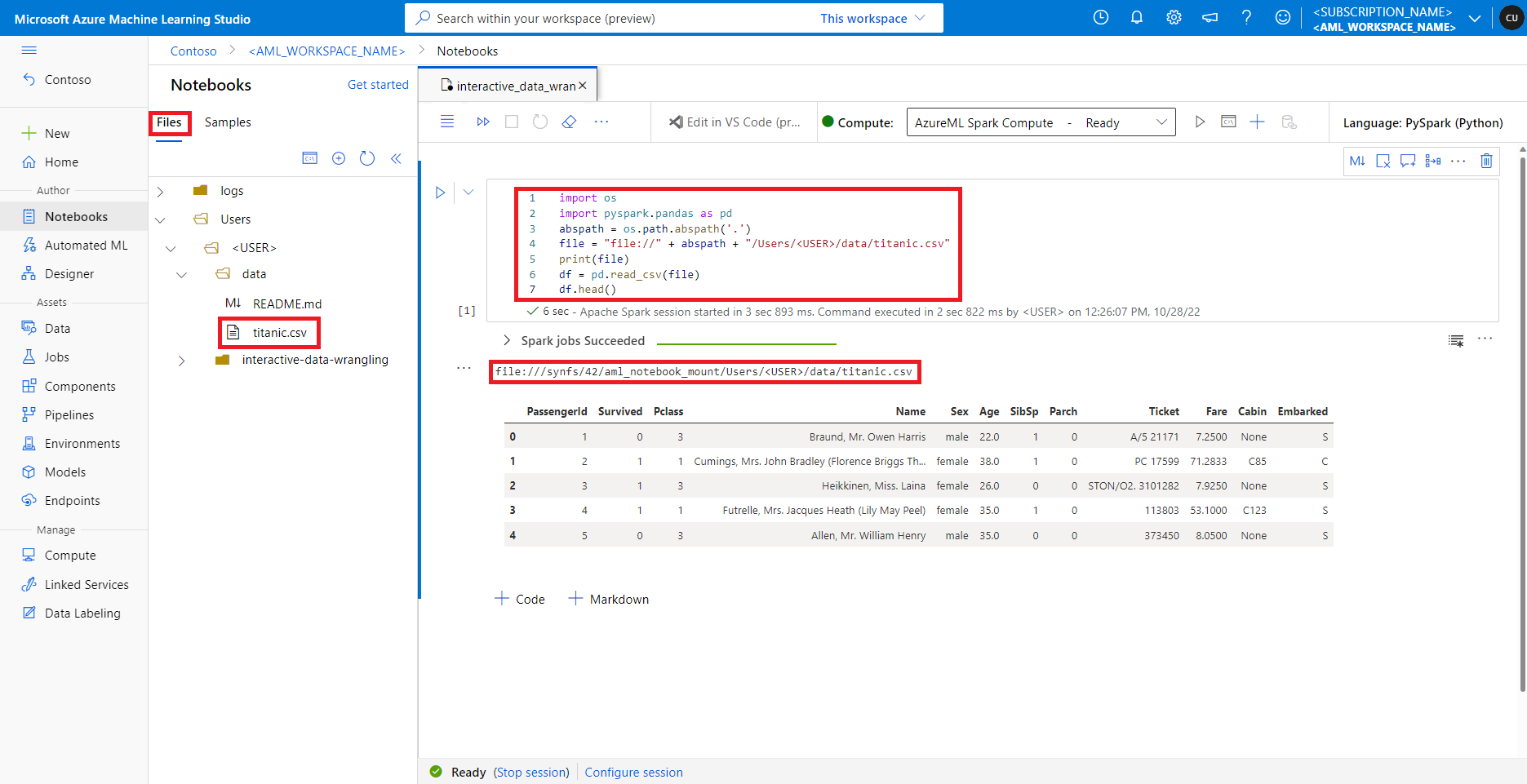
No estúdio do Azure Machine Learning, os arquivos no compartilhamento de arquivos padrão são mostrados na árvore de diretórios na guia Arquivos . O código do bloco de anotações pode acessar diretamente os arquivos armazenados neste compartilhamento de arquivos com file:// protocolo, juntamente com o caminho absoluto do arquivo, sem mais configurações. Este trecho de código mostra como acessar um arquivo armazenado no compartilhamento de arquivos padrão:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Nota
Este exemplo de código Python usa pyspark.pandas. Somente o tempo de execução do Spark versão 3.2 ou posterior suporta isso.
Próximos passos
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários