Anexar e gerenciar um Pool do Spark do Synapse no Azure Machine Learning
APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Neste artigo, você aprenderá a anexar um Pool do Spark do Synapse no Azure Machine Learning. Você pode anexar um Pool do Spark do Synapse no Azure Machine Learning de uma destas maneiras:
- Usar a interface do usuário do Estúdio do Azure Machine Learning
- Usar a CLI do Azure Machine Learning
- Usar o SDK do Python do Azure Machine Learning
Pré-requisitos
- Uma assinatura do Azure. Caso não tenha uma, crie uma conta gratuita antes de começar.
- Um Workspace do Azure Machine Learning. Confira Criar recursos de workspace.
- Crie um espaço de trabalho do Azure Synapse Analytics no portal do Azure.
- Crie um Pool do Apache Spark usando o portal do Azure.
Anexar um Pool do Spark do Synapse no Azure Machine Learning
O Azure Machine Learning oferece diferentes maneiras de anexar e gerenciar um Pool do Synapse Spark.
Para anexar um Pool do Synapse Spark com a guia Computação do Studio:

- Na seção Gerenciar no painel esquerdo, selecione Computação.
- Selecione Computações anexadas.
- Na tela Computações anexadas, selecione Novo para ver as opções para anexar diferentes tipos de computação.
- Selecione Pool do Spark do Synapse.
O painel Anexar Pool do Synapse Spark é aberto no lado direito da tela. Nesse painel:
Insira um Nome que se referirá ao Pool do Synapse Spark anexado dentro do recurso Azure Machine Learning.
Selecione uma Assinatura do Azure no menu suspenso.
Selecione um Workspace do Synapse no menu suspensa.
Selecione um Pool do Spark no menu suspenso.
Alterne a opção Atribuir uma identidade gerenciada para habilitá-la.
Selecione um tipo de Identidade gerenciada para usar com esse Pool do Spark do Synapse anexado.
Selecione Atualizar para concluir o processo de anexação do Pool do Spark do Synapse.
Adicionar atribuições de função no Azure Synapse Analytics
Para garantir que o Pool do Spark do Synapse anexado funcione corretamente, atribua a função Administrador a ele, da interface do usuário do Estúdio do Azure Synapse Analytics. Estas etapas mostram como fazer isso:
Selecione o seu Workspace do Synapse no portal do Azure.
No painel esquerdo, selecione Visão geral.
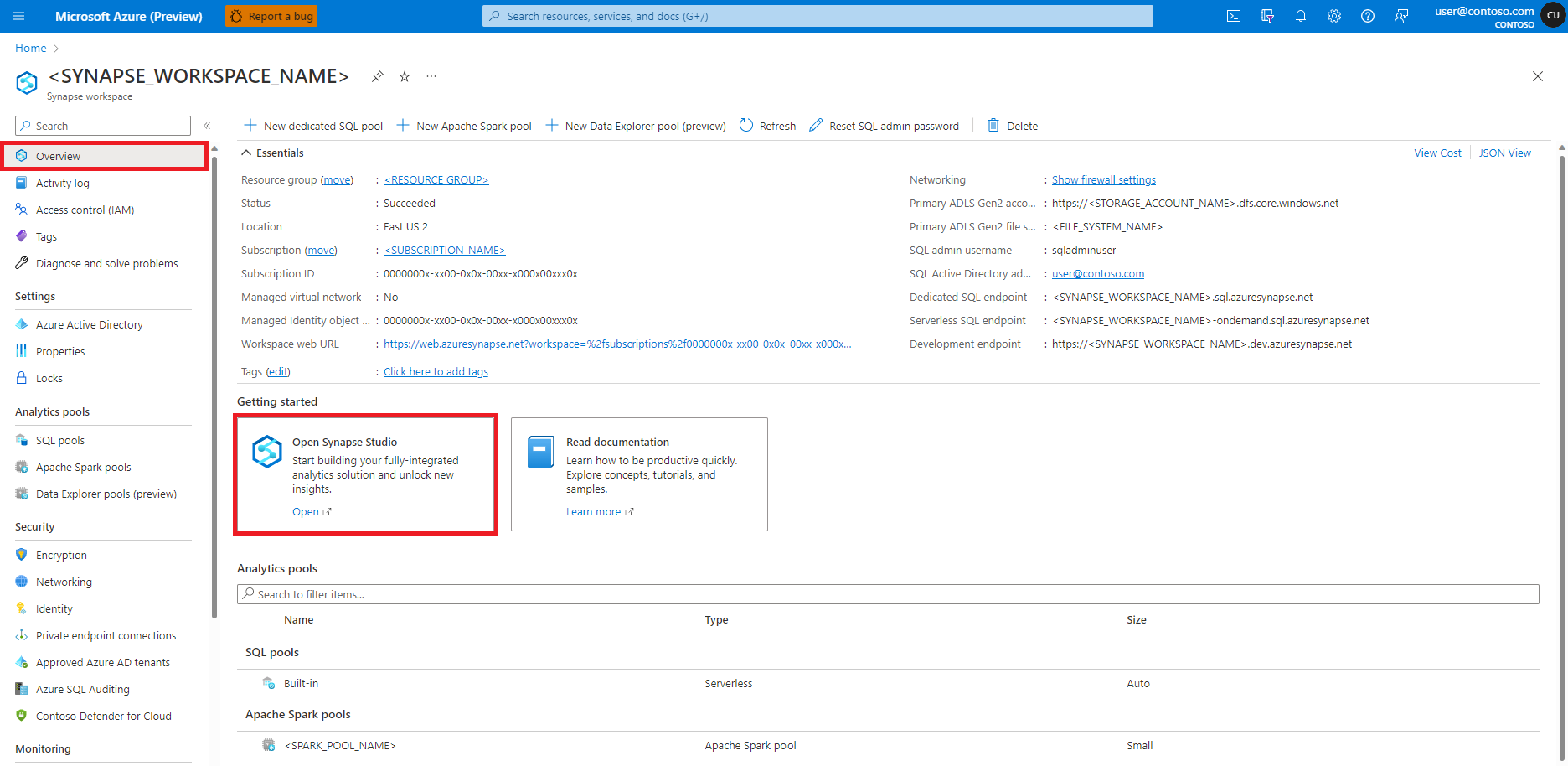
Consulte Abrir o Synapse Studio.
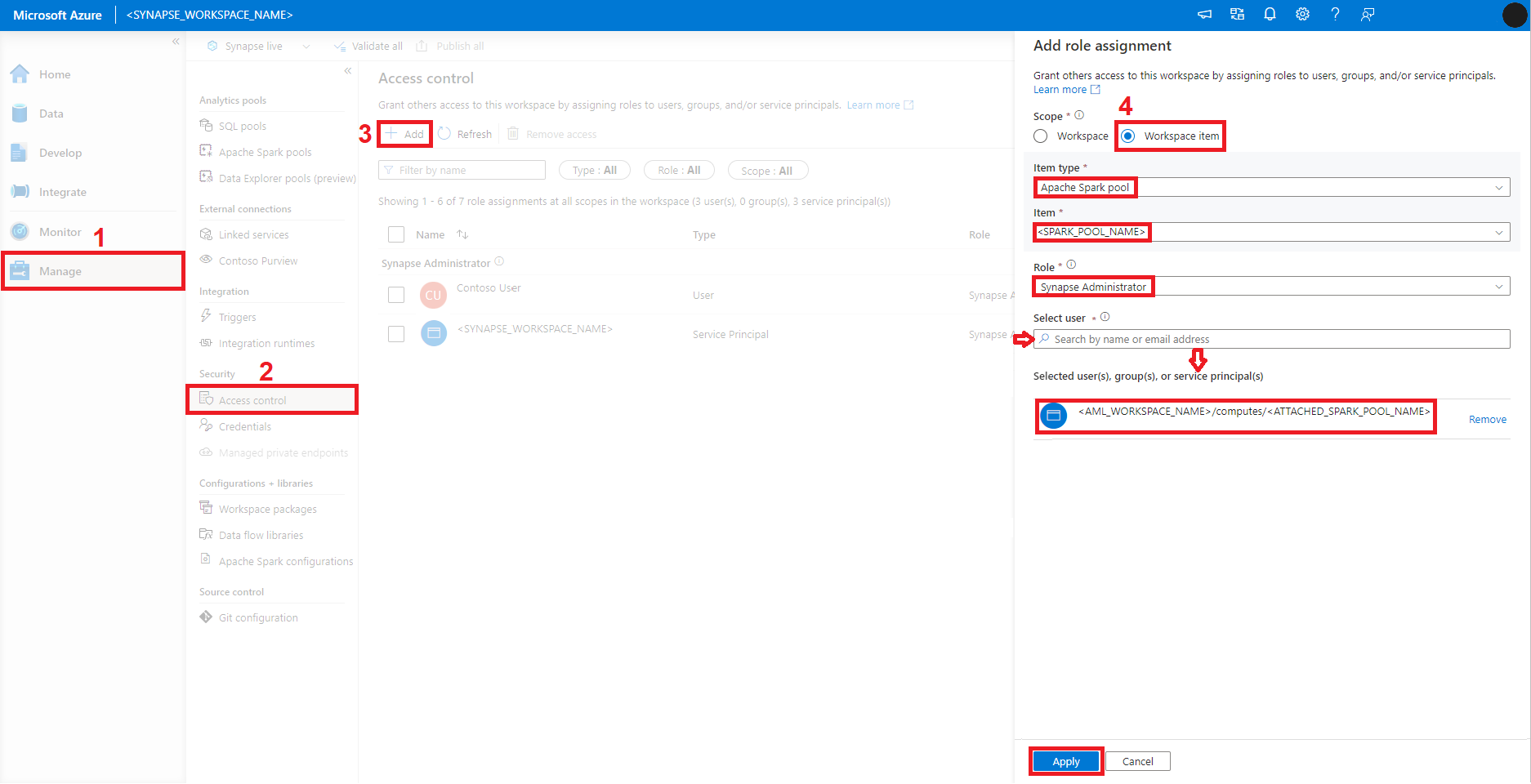
No Estúdio do Azure Synapse Analytics, selecione Gerenciar no painel esquerdo.
Selecione Controle de acesso na seção Segurança do painel esquerdo, segundo à esquerda.
Selecione Adicionar.
O painel Adicionar atribuição de função será aberto no lado direito da tela. Nesse painel:
Selecione Item de workspace para Escopo.
No menu suspenso Tipo de item, selecione Pool do Apache Spark.
No menu suspenso Item, selecione seu Pool do Apache Spark.
No menu suspenso Função, selecione Administrador do Synapse.
Na caixa de pesquisa Selecionar usuário, comece a digitar o nome do Workspace do Azure Machine Learning. Ele mostrará uma lista de Pools do Spark do Synapse anexados. Selecione o Pool do Spark do Synapse desejado na lista.
Selecione Aplicar.


Atualizar o Pool do Spark do Synapse
Você pode gerenciar o Pool do Spark do Synapse anexado na interface do usuário do Estúdio do Azure Machine Learning. A funcionalidade de gerenciamento do Pool do Spark inclui atualizações de identidade gerenciadas associadas para um Pool do Spark do Synapse anexado. Você pode atribuir uma identidade atribuída pelo sistema ou atribuída pelo usuário ao atualizar um Pool do Spark do Synapse. Você deve criar uma identidade gerenciada atribuída pelo usuário no portal do Azure, antes de atribuí-la a um Pool do Synapse Spark.
Para atualizar a identidade gerenciada para o Pool do Spark do Synapse anexado:

Abra a página Detalhes do Pool do Spark do Synapse no Estúdio do Azure Machine Learning.
Localize o ícone de edição, localizado no lado direito da seção Identidade gerenciada.
Para atribuir uma identidade gerenciada pela primeira vez, alterne Atribuir uma identidade gerenciada para habilitá-la.
Para atribuir uma identidade gerenciada atribuída pelo sistema:
- Selecione Atribuído pelo sistema como o Tipo de identidade.
- Selecione Atualizar.
Para atribuir uma identidade gerenciada atribuída pelo usuário:
- Selecione Atribuído pelo usuário como o Tipo de identidade.
- Selecione uma Assinatura do Azure no menu suspenso.
- Digite as primeiras letras do nome da identidade gerenciada atribuída pelo usuário na caixa que mostra o texto Pesquisar por nome. Uma lista com nomes de identidade gerenciada atribuídos pelo usuário correspondentes será exibida. Selecione na lista a identidade gerenciada atribuída pelo usuário que deseja. Você pode selecionar várias identidades gerenciadas atribuídas pelo usuário e atribuí-las ao Pool do Spark do Synapse anexado.
- Selecione Atualizar.
Desanexar o Pool do Spark do Synapse
Talvez queiramos desanexar um Pool do Spark do Synapse anexado para limpar um workspace.
A interface do usuário do Estúdio do Azure Machine Learning também fornece uma maneira de desanexar um Pool do Spark do Synapse anexado. Para fazer isso, siga estas etapas:
Abra a página Detalhes do Pool do Spark do Synapse no Estúdio do Azure Machine Learning.
Selecione Desanexar para desanexar o Pool do Spark do Synapse anexado.
Computação do Spark sem servidor nos Notebooks de Machine Learning do Azure
Alguns cenários de usuário podem exigir acesso a um recurso de computação do Spark sem servidor durante um envio de trabalho do Azure Machine Learning, sem a necessidade de anexar um Pool do Spark. A integração do Azure Synapse Analytics com o Azure Machine Learning também fornece uma experiência de computação spark sem servidor. Isso permite o acesso a uma computação do Spark em um trabalho, sem a necessidade de anexar a computação a um espaço de trabalho primeiro. Saiba mais sobre a experiência com a computação do Spark sem servidor.