Enviar trabalhos do Spark no Azure Machine Learning
APLICA-SE A: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
O Azure Machine Learning dá suporte ao envio de trabalhos de aprendizado de máquina autônomos e à criação de pipelines de aprendizado de máquina que envolvem várias etapas de fluxo de trabalho de aprendizado de máquina. O Azure Machine Learning lida com a criação de trabalhos do Spark autônomos e a criação de componentes reutilizáveis do Spark que os pipelines do Azure Machine Learning podem usar. Neste artigo, você aprenderá como enviar trabalhos do Spark usando:
- Interface do usuário do estúdio do Azure Machine Learning
- CLI do Azure Machine Learning
- Azure Machine Learning SDK
Para obter mais informações sobre o Apache Spark nos conceitos do Azure Machine Learning , consulte este recurso.
Pré-requisitos
APLICA-SE A: Azure CLI ml extension v2 (atual)
- Uma assinatura do Azure; se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Uma área de trabalho do Azure Machine Learning. Consulte Criar recursos do espaço de trabalho.
- Crie uma instância de computação do Azure Machine Learning.
- Instale a CLI do Azure Machine Learning.
- (Opcional): um pool Synapse Spark anexado no espaço de trabalho do Azure Machine Learning.
Nota
- Para saber mais sobre o acesso a recursos ao usar a computação do Spark sem servidor do Aprendizado de Máquina do Azure e o pool Synapse Spark anexado, consulte Garantindo o acesso a recursos para trabalhos do Spark.
- O Azure Machine Learning fornece um pool de cotas compartilhadas a partir do qual todos os usuários podem acessar a cota de computação para executar testes por um tempo limitado. Quando você usa a computação do Spark sem servidor, o Aprendizado de Máquina do Azure permite que você acesse essa cota compartilhada por um curto período de tempo.
Anexar identidade gerenciada atribuída ao usuário usando a CLI v2
- Crie um arquivo YAML que defina a identidade gerenciada atribuída pelo usuário que deve ser anexada ao espaço de trabalho:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - Com o
--fileparâmetro, use oaz ml workspace updatearquivo YAML no comando para anexar a identidade gerenciada atribuída ao usuário:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Anexar identidade gerenciada atribuída ao usuário usando ARMClient
- Instale
ARMCliento , uma ferramenta de linha de comando simples que invoca a API do Azure Resource Manager. - Crie um arquivo JSON que defina a identidade gerenciada atribuída pelo usuário que deve ser anexada ao espaço de trabalho:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Para anexar a identidade gerenciada atribuída pelo usuário ao espaço de trabalho, execute o seguinte comando no prompt do PowerShell ou no prompt de comando.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Nota
- Para garantir a execução bem-sucedida do trabalho do Spark, atribua as funções de Colaborador e Colaborador de Dados do Blob de Armazenamento , na conta de armazenamento do Azure usada para entrada e saída de dados, à identidade que o trabalho do Spark usa
- O Acesso à Rede Pública deve ser habilitado no espaço de trabalho do Azure Synapse para garantir a execução bem-sucedida do trabalho do Spark usando um pool Synapse Spark anexado.
- Se um pool do Synapse Spark anexado apontar para um pool do Synapse Spark, em um espaço de trabalho do Azure Synapse que tenha uma rede virtual gerenciada associada a ele, um ponto de extremidade privado gerenciado para a conta de armazenamento deverá ser configurado para garantir o acesso aos dados.
- A computação do Serverless Spark dá suporte à rede virtual gerenciada do Azure Machine Learning. Se uma rede gerenciada for provisionada para a computação do Spark sem servidor, os pontos de extremidade privados correspondentes para a conta de armazenamento também deverão ser provisionados para garantir o acesso aos dados.
Enviar um trabalho independente do Spark
Depois de fazer as alterações necessárias para a parametrização do script Python, um script Python desenvolvido pela disputa interativa de dados pode ser usado para enviar um trabalho em lote para processar um volume maior de dados. Um trabalho em lote de disputa de dados simples pode ser enviado como um trabalho autônomo do Spark.
Um trabalho Spark requer um script Python que usa argumentos, que pode ser desenvolvido com a modificação do código Python desenvolvido a partir de disputa de dados interativa. Um exemplo de script Python é mostrado aqui.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Nota
Este exemplo de código Python usa pyspark.pandas. Somente o tempo de execução do Spark versão 3.2 ou posterior suporta isso.
O script acima usa dois argumentos --titanic_data e --wrangled_data, que passam o caminho dos dados de entrada e da pasta de saída, respectivamente.
APLICA-SE A: Azure CLI ml extension v2 (atual)
Para criar um trabalho, um trabalho Spark autônomo pode ser definido como um arquivo de especificação YAML, que pode ser usado no az ml job create comando, com o --file parâmetro. Defina estas propriedades no arquivo YAML:
Propriedades YAML na especificação do trabalho do Spark
type- definido comospark.code- define o local da pasta que contém o código-fonte e scripts para este trabalho.entry- define o ponto de entrada para o trabalho. Deve abranger uma destas propriedades:file- define o nome do script Python que serve como ponto de entrada para o trabalho.
py_files- define uma lista de.zip,.eggou.pyarquivos, a serem colocados noPYTHONPATH, para a execução bem-sucedida do trabalho. Esta propriedade é opcional.jars- define uma lista de.jararquivos para incluir no driver Spark, e o executorCLASSPATH, para a execução bem-sucedida do trabalho. Esta propriedade é opcional.files- define uma lista de arquivos que devem ser copiados para o diretório de trabalho de cada executor, para a execução bem-sucedida do trabalho. Esta propriedade é opcional.archives- define uma lista de arquivos que devem ser extraídos para o diretório de trabalho de cada executor, para a execução bem-sucedida do trabalho. Esta propriedade é opcional.conf- define estas propriedades do driver e do executor do Spark:spark.driver.cores: o número de núcleos para o driver Spark.spark.driver.memory: memória alocada para o driver Spark, em gigabytes (GB).spark.executor.cores: o número de núcleos para o executor do Spark.spark.executor.memory: a alocação de memória para o executor Spark, em gigabytes (GB).spark.dynamicAllocation.enabled- se os executores devem ou não ser atribuídos dinamicamente, como umTrueFalseou valor.- Se a alocação dinâmica de executores estiver habilitada, defina estas propriedades:
spark.dynamicAllocation.minExecutors- o número mínimo de instâncias de executores Spark, para alocação dinâmica.spark.dynamicAllocation.maxExecutors- o número máximo de instâncias de executores do Spark, para alocação dinâmica.
- Se a alocação dinâmica de executores estiver desativada, defina esta propriedade:
spark.executor.instances- o número de instâncias do executor do Spark.
environment- um ambiente do Azure Machine Learning para executar o trabalho.args- os argumentos de linha de comando que devem ser passados para o script Python do ponto de entrada do trabalho. Consulte o arquivo de especificação YAML fornecido aqui para obter um exemplo.resources- esta propriedade define os recursos a serem usados por uma computação do Spark sem servidor do Azure Machine Learning. Ele usa as seguintes propriedades:instance_type- o tipo de instância de computação a ser usado para o pool do Spark. Os seguintes tipos de instância são suportados atualmente:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- define a versão de tempo de execução do Spark. As seguintes versões de tempo de execução do Spark são suportadas no momento:3.33.4Importante
Azure Synapse Runtime for Apache Spark: Anúncios
- Azure Synapse Runtime para Apache Spark 3.3:
- Data de anúncio EOLA: 12 de julho de 2024
- Data de fim do suporte: 31 de março de 2025. Após essa data, o tempo de execução será desativado.
- Para suporte contínuo e desempenho ideal, recomendamos a migração para o Apache Spark 3.4.
- Azure Synapse Runtime para Apache Spark 3.3:
Este é um exemplo:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute- esta propriedade define o nome de um pool Synapse Spark anexado, como mostrado neste exemplo:compute: mysparkpoolinputs- esta propriedade define entradas para o trabalho do Spark. As entradas para um trabalho do Spark podem ser um valor literal ou dados armazenados em um arquivo ou pasta.- Um valor literal pode ser um número, um valor booleano ou uma cadeia de caracteres. Alguns exemplos são mostrados aqui:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Os dados armazenados em um arquivo ou pasta devem ser definidos usando estas propriedades:
type- defina esta propriedade comouri_file, ouuri_folder, para dados de entrada contidos em um arquivo ou uma pasta, respectivamente.path- o URI dos dados de cálculo, comoazureml://,abfss://ouwasbs://.mode- defina esta propriedade comodirect. Este exemplo mostra a definição de uma entrada de trabalho, que pode ser referida como$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Um valor literal pode ser um número, um valor booleano ou uma cadeia de caracteres. Alguns exemplos são mostrados aqui:
outputs- esta propriedade define as saídas de trabalho do Spark. As saídas para um trabalho do Spark podem ser gravadas em um arquivo ou em um local de pasta, que é definido usando as três propriedades a seguir:type- Esta propriedade pode ser definida comouri_fileouuri_folderpara gravar dados de saída em um arquivo ou uma pasta, respectivamente.path- esta propriedade define o URI do local de saída, comoazureml://,abfss://ouwasbs://.mode- defina esta propriedade comodirect. Este exemplo mostra a definição de uma saída de trabalho, que pode ser referida como${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- Esta propriedade opcional define a identidade usada para enviar este trabalho. Pode teruser_identityemanagedvalorizar. Se a especificação YAML não definir uma identidade, o trabalho do Spark usará a identidade padrão.
Trabalho Standalone Spark
Este exemplo de especificação YAML mostra um trabalho Spark autônomo. Ele usa uma computação do Spark sem servidor do Azure Machine Learning:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Nota
Para usar um pool Synapse Spark anexado, defina a compute propriedade no arquivo de especificação YAML de exemplo mostrado anteriormente, em vez da resources propriedade.
Os arquivos YAML mostrados az ml job create anteriormente podem ser usados no comando, com o --file parâmetro, para criar um trabalho Spark autônomo, conforme mostrado:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Você pode executar o comando acima de:
- terminal de uma instância de computação do Azure Machine Learning.
- terminal do Visual Studio Code conectado a uma instância de computação do Azure Machine Learning.
- seu computador local que tenha a CLI do Azure Machine Learning instalada.
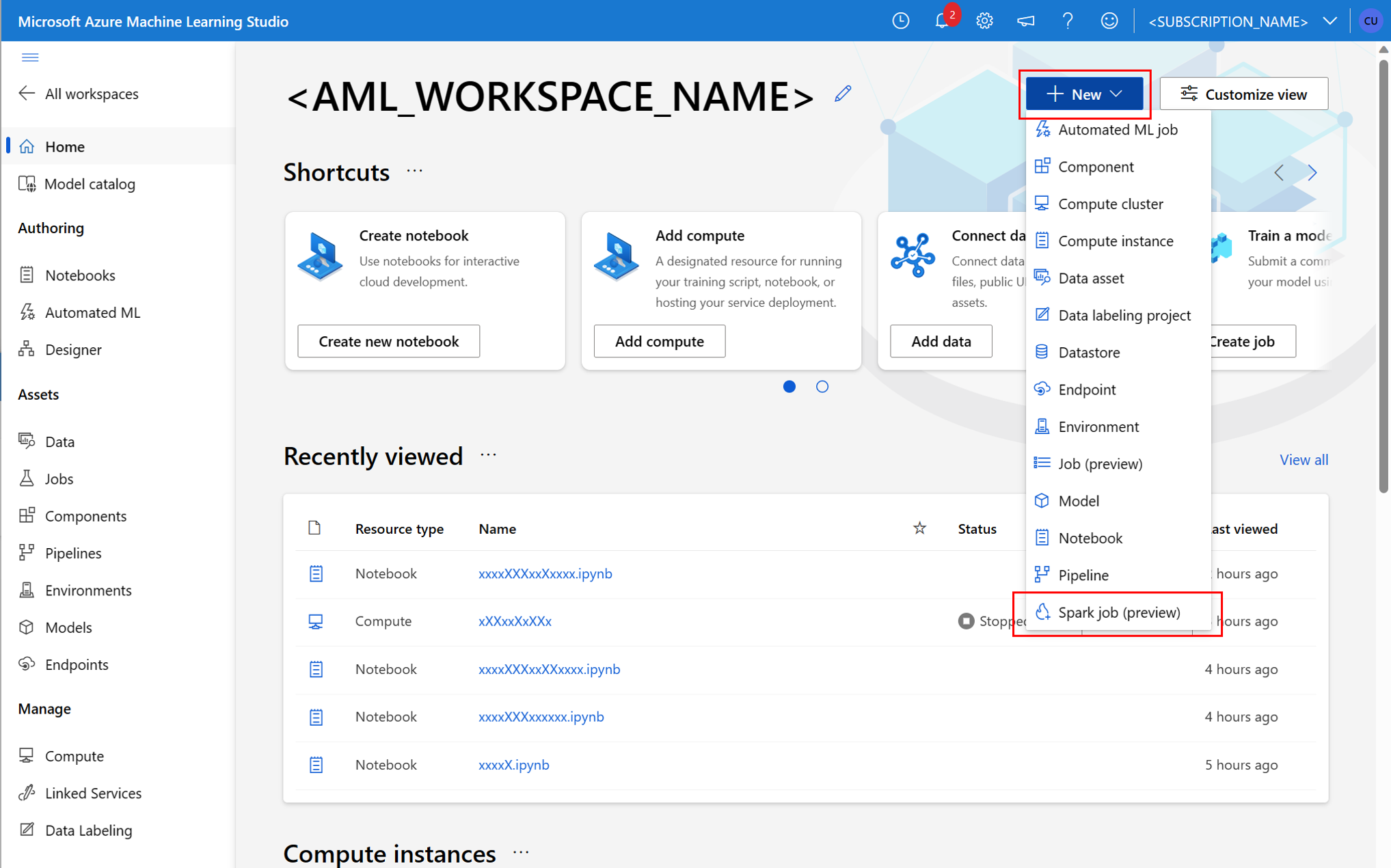
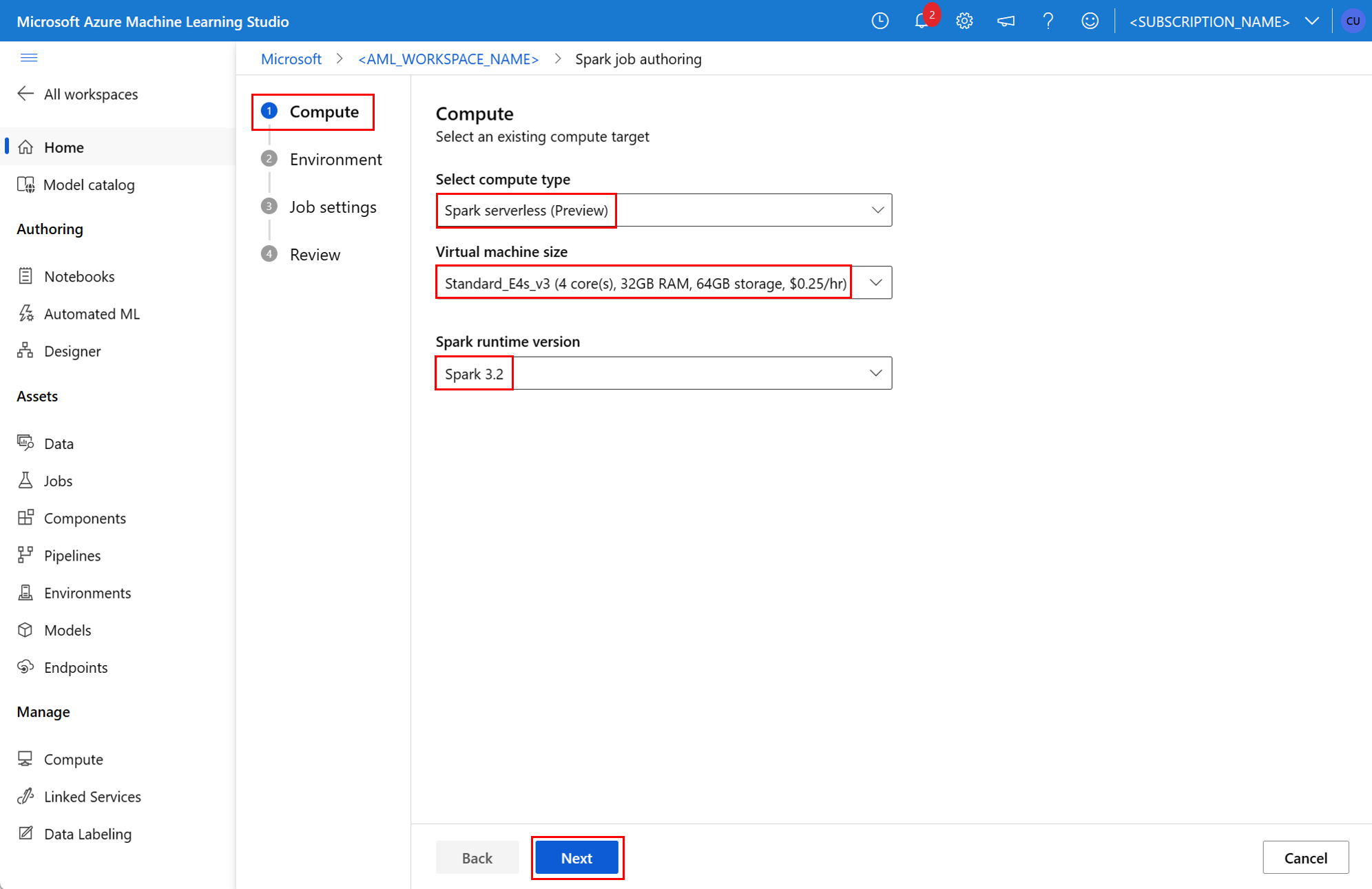
Componente Spark em um trabalho de pipeline
Um componente do Spark oferece a flexibilidade de usar o mesmo componente em vários pipelines do Azure Machine Learning, como uma etapa de pipeline.
APLICA-SE A: Azure CLI ml extension v2 (atual)
A sintaxe YAML para um componente Spark se assemelha à sintaxe YAML para especificação de trabalho do Spark na maioria das maneiras. Essas propriedades são definidas de forma diferente na especificação YAML do componente Spark:
name- o nome do componente Spark.version- a versão do componente Spark.display_name- o nome do componente Spark a ser exibido na interface do usuário e em outros lugares.description- a descrição do componente Spark.inputs- esta propriedade é semelhante àinputspropriedade descrita na sintaxe YAML para especificação de trabalho do Spark, exceto que ela não define apathpropriedade. Este trecho de código mostra um exemplo da propriedade do componenteinputsSpark:inputs: titanic_data: type: uri_file mode: directoutputs- esta propriedade é semelhante àoutputspropriedade descrita na sintaxe YAML para especificação de trabalho do Spark, exceto que ela não define apathpropriedade. Este trecho de código mostra um exemplo da propriedade do componenteoutputsSpark:outputs: wrangled_data: type: uri_folder mode: direct
Nota
Um componente Spark não define identity, compute ou resources propriedades. O arquivo de especificação YAML do pipeline define essas propriedades.
Este arquivo de especificação YAML fornece um exemplo de um componente Spark:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
O componente Spark definido no arquivo de especificação YAML acima pode ser usado em um trabalho de pipeline do Azure Machine Learning. Consulte Esquema YAML do trabalho de pipeline para saber mais sobre a sintaxe YAML que define um trabalho de pipeline. Este exemplo mostra um arquivo de especificação YAML para um trabalho de pipeline, com um componente Spark e uma computação Spark sem servidor do Azure Machine Learning:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Nota
Para usar um pool Synapse Spark anexado, defina a compute propriedade no arquivo de especificação YAML de exemplo mostrado acima, em vez da resources propriedade.
O arquivo de especificação YAML acima pode ser usado no az ml job create comando, usando o --file parâmetro, para criar um trabalho de pipeline como mostrado:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Você pode executar o comando acima de:
- terminal de uma instância de computação do Azure Machine Learning.
- terminal do Visual Studio Code conectado a uma instância de computação do Azure Machine Learning.
- seu computador local que tenha a CLI do Azure Machine Learning instalada.
Solução de problemas de trabalhos do Spark
Para solucionar problemas de um trabalho do Spark, você pode acessar os logs gerados para esse trabalho no estúdio do Azure Machine Learning. Para exibir os logs de um trabalho do Spark:
- Navegue até Trabalhos no painel esquerdo na interface do usuário do estúdio de Aprendizado de Máquina do Azure
- Selecione a guia Todos os trabalhos
- Selecione o valor Nome para exibição do trabalho
- Na página de detalhes do trabalho, selecione a guia Saída + logs
- No explorador de ficheiros, expanda a pasta logs e, em seguida, expanda a pasta azureml
- Acesse os logs de trabalho do Spark dentro das pastas do driver e do gerenciador de bibliotecas
Nota
Para solucionar problemas de trabalhos do Spark criados durante a disputa interativa de dados em uma sessão de bloco de anotações, selecione Detalhes do trabalho no canto superior direito da interface do usuário do bloco de anotações. Um trabalho do Spark de uma sessão de bloco de anotações interativo é criado sob o nome de experimento notebook-runs.