Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Este artigo descreve a alta disponibilidade no Banco de Dados do Azure para PostgreSQL, que inclui zonas de disponibilidade , recuperação entre regiões e continuidade de negócios. Para obter uma visão geral mais detalhada da confiabilidade no Azure, consulte Confiabilidade do Azure.
O Banco de Dados do Azure para PostgreSQL dá suporte à alta disponibilidade provisionando réplicas primárias e em espera fisicamente separadas, dentro da mesma zona de disponibilidade (zonal) ou entre zonas de disponibilidade (com redundância de zona). Esse modelo de alta disponibilidade foi projetado para garantir que os dados comprometidos nunca sejam perdidos durante falhas. Em uma configuração de alta disponibilidade (HA), os dados são confirmados de forma síncrona no servidor primário e no de backup. O modelo é projetado para que o banco de dados não se torne um único ponto de falha em sua arquitetura de software. Para obter mais informações sobre alta disponibilidade e suporte à zona de disponibilidade, consulte Suporte à zona de disponibilidade.
Suporte à zona de disponibilidade
As zonas de disponibilidade são grupos fisicamente separados de centros de dados dentro de uma região Azure. Quando uma zona falha, os serviços podem ser transferidos para uma das zonas restantes.
O Banco de Dados do Azure para PostgreSQL dá suporte a modelos zonais e com redundância de zona para configurações de alta disponibilidade. Ambas as configurações de alta disponibilidade permitem a capacidade de failover automático com perda de dados zero durante eventos planejados e não planejados.
Zona redundante. A alta disponibilidade redundante de zona implanta uma réplica em espera em uma zona diferente com capacidade de failover automático. A redundância de zona fornece o mais alto nível de disponibilidade, mas você precisa configurar a redundância de aplicativos entre zonas. Por esse motivo, escolha redundância de zona quando quiser proteção contra falhas no nível da zona de disponibilidade e quando a latência nas zonas de disponibilidade for aceitável. Embora possa haver algum impacto de latência nas gravações e confirmações devido à replicação síncrona, isso não afeta as consultas de leitura. Esse impacto é específico para suas cargas de trabalho, o tipo de SKU selecionado e a região.
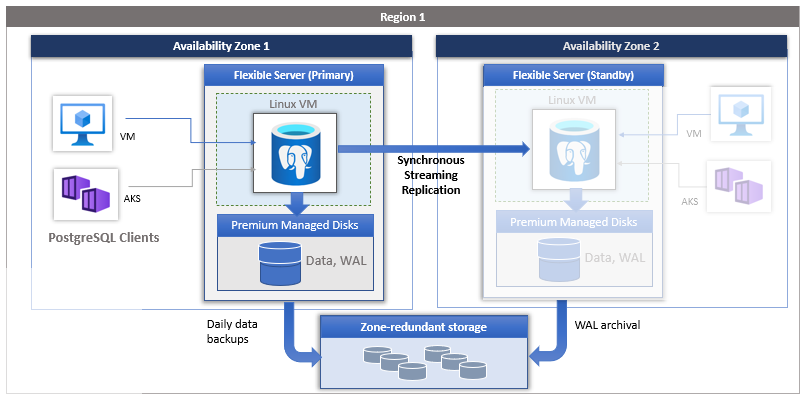
Você pode escolher a região e as zonas de disponibilidade para servidores primários e em espera. O servidor de réplica em espera é provisionado na zona de disponibilidade escolhida na mesma região com uma configuração de computação, armazenamento e rede semelhante à do servidor primário. Os arquivos de dados e os arquivos de log de transações (logs write-ahead, também conhecidos como WAL) são armazenados em LRS (armazenamento com redundância local) dentro de cada zona de disponibilidade, armazenando automaticamente três cópias de dados. Uma configuração redundante por zona proporciona isolamento físico de toda a pilha entre servidores primários e secundários.

A opção com redundância de zona só está disponível em regiões que têm suporte para zonas de disponibilidade.
Não há suporte para redundância de zona para:
Camada de computação elástica
Regiões com disponibilidade de zona única
Zonal. Escolha uma implantação zonal quando quiser atingir o mais alto nível de disponibilidade em uma única zona de disponibilidade, mas com a menor latência de rede. Você pode escolher a região e a zona de disponibilidade para implantar o servidor de banco de dados primário. Um servidor de réplica em espera é automaticamente provisionado e gerenciado na mesma zona de disponibilidade - com computação, armazenamento e configuração de rede semelhantes - que o servidor primário. Uma configuração zonal protege seus bancos de dados contra falhas no nível do nó e também ajuda a reduzir o tempo de inatividade do aplicativo durante eventos de tempo de inatividade planejados e não planejados. Os dados do servidor primário são replicados para a réplica em espera no modo síncrono. Se houver alguma interrupção no servidor primário, o servidor fará failover automaticamente para a réplica em espera.


A opção de implantação zonal está disponível em todas as regiões do Azure onde você pode implantar o Servidor Flexível.
Observação
Os modelos de implantação zoneados e com redundância de zona comportam-se da mesma forma do ponto de vista arquitetónico. Várias discussões nas seções a seguir se aplicam a ambos, salvo indicação em contrário.
Configurar Crítico para o Negócio (Alta Disponibilidade) no portal
Você pode configurar a alta disponibilidade (HA) de duas maneiras: HA com redundância de zona, que coloca o servidor em espera em uma zona de disponibilidade diferente para máxima resiliência, ou HA de mesma zona, que implanta o servidor em espera na mesma zona do servidor primário para minimizar a latência.
A secção 'Business Critical (Alta Disponibilidade)' oferece a opção de criar um servidor HA de reserva com configuração de resiliência zonal . Para simplificar a configuração e garantir a resiliência zonal, o portal fornece uma opção de resiliência zonal com dois botões de opção: Ativado e Desativado. Selecionar Ativado tenta criar o servidor em espera em uma zona de disponibilidade diferente (modo HA com redundância de zona). Se a região não oferecer suporte a HA com redundância de zona, você poderá marcar a caixa de seleção de fallback (realçada na imagem a seguir) para habilitar a HA da mesma zona.

Selecionar a caixa de seleção de fallback faz com que o sistema crie o servidor de standby na mesma zona. Se a capacidade zonal mais tarde ficar disponível, o Azure notificá-lo-á para que possa escolher migrar para uma configuração de alta disponibilidade (HA) redundante de zona usando PITR ou réplicas de leitura. Se você não marcar a caixa de seleção e a capacidade zonal não estiver disponível, a ativação do HA falhará. Este design impõe a alta disponibilidade (HA) redundante por zona como padrão, enquanto oferece um recuo controlado para alta disponibilidade na mesma zona, garantindo que as cargas de trabalho atinjam eventualmente a total resiliência por zona.
Recursos de alta disponibilidade
Uma réplica em espera é implantada na mesma configuração de VM - incluindo vCores, armazenamento e configurações de rede - que o servidor primário.
Você pode adicionar suporte à zona de disponibilidade para um servidor de banco de dados existente.
Você pode remover a réplica em espera desativando a alta disponibilidade.
Você pode escolher zonas de disponibilidade para seus servidores de banco de dados primários e em espera para disponibilidade com redundância de zona.
Operações como parar, iniciar e reiniciar são realizadas nos servidores de bases de dados principal e de reserva em simultâneo.
Em modelos zonais e com redundância de zona, o servidor de banco de dados primário executa backups automáticos periodicamente. Ao mesmo tempo, a réplica em espera arquiva continuamente os logs de transações no armazenamento de backup. Se a região oferecer suporte a zonas de disponibilidade, os dados de backup serão armazenados no ZRS (armazenamento com redundância de zona). Em regiões que não oferecem suporte a zonas de disponibilidade, os dados de backup são armazenados no LRS (armazenamento redundante local).
Os clientes sempre se conectam ao nome do host final do servidor de banco de dados primário.
Quaisquer alterações nos parâmetros do servidor também são aplicadas à réplica em espera.
Você pode reiniciar o servidor para pegar quaisquer alterações de parâmetros estáticos do servidor.
Atividades de manutenção periódicas, como atualizações de versões secundárias, acontecem primeiro no modo de espera. Para reduzir o tempo de inatividade, o modo de espera é promovido a principal para que as cargas de trabalho possam continuar enquanto as tarefas de manutenção são aplicadas no nó restante.
Observação
Para garantir que as funções de alta disponibilidade funcionem corretamente, configure os valores dos parâmetros do servidor max_replication_slots e max_wal_senders. A alta disponibilidade requer quatro de cada para lidar com failovers e upgrades contínuos. Para uma configuração de alta disponibilidade com cinco réplicas de leitura e 12 slots lógicos de replicação, defina ambos os parâmetros max_replication_slots e max_wal_senders para 21. Essa configuração é necessária porque cada réplica de leitura e slot de replicação lógica requer um de cada um, além dos quatro necessários para que a alta disponibilidade funcione corretamente. Para obter mais informações sobre max_replication_slots e max_wal_senders parâmetros, consulte a documentação.
Monitorar a integridade da alta disponibilidade
O monitoramento do status de integridade de alta disponibilidade (HA) no Banco de Dados do Azure para PostgreSQL fornece uma visão geral contínua da integridade e da prontidão das instâncias habilitadas para HA. Esse recurso de monitoramento aplica a estrutura RHC (Verificação de Integridade de Recursos) do Azure para detetar e alertar sobre quaisquer problemas que possam afetar a prontidão para failover ou a disponibilidade geral do banco de dados. Ao avaliar as principais métricas, como status da conexão, estado de failover e integridade da replicação de dados, o monitoramento do status de integridade do HA permite a solução de problemas proativa e ajuda a manter o tempo de atividade e o desempenho do banco de dados.
Utilize o monitoramento do status de integridade do HA para:
- Obtenha informações em tempo real sobre a integridade das réplicas primárias e em espera, com indicadores de status que revelam possíveis problemas, como desempenho degradado ou bloqueio de rede.
- Configure alertas para notificações oportunas sobre quaisquer alterações no status da HA, para que você possa tomar medidas imediatas para resolver possíveis interrupções.
- Otimize a prontidão para failover identificando e resolvendo problemas antes que eles afetem as operações do banco de dados.
Para obter um guia detalhado sobre como configurar e interpretar status de integridade de HA, consulte Monitoramento de status de integridade de alta disponibilidade (HA) para o Banco de Dados do Azure para PostgreSQL.
Limitações de alta disponibilidade
Devido à replicação síncrona para o servidor em espera, especialmente com uma configuração com redundância de zona, as aplicações podem experimentar latência aumentada de escrita e confirmação.
Não é possível usar a réplica em espera para consultas de leitura de dados.
Dependendo da carga de trabalho e da atividade no servidor primário, o processo de failover pode levar mais de 120 segundos porque a réplica em espera precisa ser recuperada antes de ser promovida.
O servidor em espera normalmente recupera arquivos WAL em 40 MB / s. Para versões maiores, essa taxa pode aumentar para até 200 MB/s. Se a sua carga de trabalho exceder este limite, poderá enfrentar um tempo prolongado para que a recuperação seja concluída, quer durante o failover, quer após estabelecer um novo standby.
A reinicialização do servidor de banco de dados primário também reinicia a réplica em espera.
Não é possível configurar um modo de espera extra.
Não é possível agendar tarefas de gerenciamento iniciadas pelo cliente durante a janela de manutenção gerenciada.
Os eventos planejados, como computação em escala e armazenamento em escala, acontecem primeiro no modo de espera e, em seguida, no servidor primário. Atualmente, o servidor não faz failover para essas operações planejadas.
Se configurar descodificação lógica ou replicação lógica num servidor flexível com capacidade HA:
- No PostgreSQL 16 e versões anteriores, os slots de replicação lógica não são preservados no servidor em espera após um failover por padrão.
- Para garantir que a replicação lógica continue a funcionar após o failover, você precisa habilitar a
pg_failover_slotsextensão e definir configurações de suporte, comohot_standby_feedback = on. - A partir do PostgreSQL 17, a sincronização de slots é suportada nativamente. Se você habilitar as configurações corretas do PostgreSQL (
sync_replication_slots,hot_standby_feedback), os slots de replicação lógica serão preservados automaticamente após o failover e nenhuma extensão será necessária. - Para obter informações sobre as etapas de configuração e pré-requisitos, consulte a documentação da extensão PG_Failover_Slots.
Não há suporte para a configuração de zonas de disponibilidade entre acesso privado (rede virtual) e público com pontos de extremidade privados. Você deve configurar zonas de disponibilidade dentro de uma rede virtual (abrangendo zonas de disponibilidade dentro de uma região) ou acesso público com pontos de extremidade privados.
Você só pode configurar zonas de disponibilidade dentro de uma única região. Não é possível configurar zonas de disponibilidade entre regiões.
SLA
O modelo Zonal oferece uma disponibilidade para um SLA de cerca de 99,95%.
O modelo de redundância por zonas oferece uma disponibilidade para um SLA de cerca de 99,99%.
Criar um Banco de Dados do Azure para PostgreSQL com a zona de disponibilidade habilitada
Para saber como criar um Banco de Dados do Azure para PostgreSQL para alta disponibilidade com zonas de disponibilidade, consulte Guia de início rápido: criar um Banco de Dados do Azure para PostgreSQL no portal do Azure.
Redistribuição e migração da zona de disponibilidade
Para saber como habilitar ou desabilitar a configuração de alta disponibilidade em seu servidor flexível em modelos de implantação com redundância de zona e zonal, consulte Gerenciar alta disponibilidade no servidor flexível.
Componentes de alta disponibilidade e fluxo de trabalho
Conclusão da transação
Uma transação de aplicação desencadeia uma escrita e confirmação que primeiro regista no WAL no servidor principal. O servidor primário transmite esses logs para o servidor em espera usando o protocolo de streaming Postgres. Quando o armazenamento do servidor em espera persiste os logs, o servidor primário reconhece a conclusão do processo de escrita. O aplicativo confirma sua transação somente após esse reconhecimento. Essa viagem extra de ida e volta adiciona latência ao seu aplicativo. A percentagem de impacto depende da aplicação. Esse processo de confirmação não espera que os logs sejam aplicados ao servidor em espera. O servidor em espera permanece no modo de recuperação até ser promovido.
Verificação de saúde
O monitoramento flexível da integridade do servidor verifica periodicamente a integridade dos servidores primário e em espera. Após vários pings, se o monitoramento de integridade detetar que um servidor primário não está acessível, o serviço iniciará um failover automático para o servidor em espera. O algoritmo de monitoramento de saúde usa múltiplos pontos de dados para evitar situações de falso positivo.
Modos de failover
O servidor flexível suporta dois modos de mudança de função, mudança de função planeada e mudança de função não planeada. Em ambos os modos, quando a replicação quebra, o servidor secundário executa a recuperação antes de ser promovido a servidor primário e abre para leituras e gravações. Com entradas DNS automáticas atualizadas com o novo ponto de extremidade do servidor primário, os aplicativos podem se conectar ao servidor usando o mesmo ponto de extremidade. Um novo servidor em espera é estabelecido em segundo plano, para que seu aplicativo possa manter a conectividade.
Estado de alta disponibilidade
O sistema monitora continuamente a integridade dos servidores primários e em espera. Adota medidas adequadas para corrigir problemas, incluindo a execução de um failover para o servidor de reserva. A tabela a seguir lista os possíveis status de alta disponibilidade:
| Situação | Descrição |
|---|---|
| Inicializando | No processo de criação de um novo servidor de reserva. |
| Replicando dados | Após a criação do modo de espera, está a par com o principal. |
| Saudável | A replicação está em estado estacionário e saudável. |
| Falha | O servidor de banco de dados está em processo de failover para o modo de espera. |
| Removendo o modo de espera | No processo de eliminação do servidor em espera. |
| Não ativado | A alta disponibilidade não está ativada. |
Observação
Você pode habilitar a alta disponibilidade durante a criação do servidor ou posteriormente. Caso habilite ou desabilite a alta disponibilidade durante o estágio pós-criação, faça-o quando a atividade do servidor principal estiver baixa.
Operações no estado estacionário
Os aplicativos cliente PostgreSQL se conectam ao servidor primário usando o nome do servidor de banco de dados. O servidor primário serve diretamente as leituras de aplicativos. Ao mesmo tempo, o aplicativo recebe a confirmação dos commits e grava apenas depois que os dados de log persistem tanto no servidor primário quanto na réplica de standby. Devido a essa viagem extra de ida e volta, os aplicativos podem esperar latência elevada para gravações e confirmações. Você pode monitorizar a integridade da alta disponibilidade no portal.

- Os clientes se conectam ao servidor flexível e executam operações de gravação.
- As alterações são replicadas para o site em espera.
- A primária recebe um reconhecimento.
- Escritos e compromissos são reconhecidos.
Restauração em um ponto específico no tempo de servidores de alta disponibilidade
Para servidores flexíveis configurados com alta disponibilidade, o sistema replica dados de log em tempo real para o servidor em espera. Quaisquer erros do usuário no servidor primário - como a eliminação acidental de uma tabela ou atualizações de dados incorretas - são replicados para a réplica secundária. Então, você não pode usar o modo de espera para se recuperar de tais erros lógicos. Para se recuperar de tais erros, você deve executar uma restauração point-in-time a partir do backup. Usando o recurso de restauração point-in-time de um servidor flexível, você pode restaurar para o tempo anterior à ocorrência do erro. Um novo servidor de banco de dados é restaurado como um servidor flexível de zona única com um novo nome de servidor fornecido pelo usuário para bancos de dados configurados com alta disponibilidade. Você pode usar o servidor restaurado para vários casos de uso:
Use o servidor restaurado para produção e, opcionalmente, habilite a alta disponibilidade com réplica em espera na mesma zona ou em outra zona na mesma região.
Se quiser restaurar um objeto, exporte-o do servidor de banco de dados restaurado e importe-o para o servidor de banco de dados de produção.
Se desejar clonar o servidor de banco de dados para fins de teste e desenvolvimento ou restaurar para quaisquer outros fins, você poderá executar a restauração point-in-time.
Para saber como fazer uma restauração point-in-time de um servidor flexível, consulte Restauração point-in-time de um servidor flexível.
Suporte para failover
Alternância planeada
Os eventos de tempo de inatividade planejados incluem atualizações periódicas de software agendadas do Azure e atualizações de versões secundárias. Você também pode usar um failover planejado para retornar o servidor primário a uma zona de disponibilidade preferencial. Quando você configura a alta disponibilidade, essas operações primeiro se aplicam à réplica em espera enquanto os aplicativos continuam a acessar o servidor primário. Depois que o processo atualiza a réplica em espera, ele encerra as conexões do servidor primário e inicia um failover que transforma a réplica em espera em servidor primário, mantendo o mesmo nome de servidor de banco de dados. Os aplicativos cliente se reconectam com o mesmo nome de servidor de banco de dados ao novo servidor primário e podem retomar suas operações. O processo estabelece um novo servidor em espera na mesma zona que o antigo primário.
Para outras operações iniciadas pelo usuário, como computação em escala ou armazenamento em escala, o processo aplica as alterações primeiro no modo de espera e, em seguida, no primário. Atualmente, o serviço não faz failover para o modo de espera. Assim, enquanto a operação de escala é executada no servidor primário, as aplicações encontram um breve período de inatividade.
Você também pode usar esse recurso para fazer failover para o servidor em espera com tempo de inatividade reduzido. Por exemplo, seu servidor primário pode estar em uma zona de disponibilidade diferente do aplicativo após um failover não planejado. Você deseja trazer o servidor primário de volta para a zona anterior para ser colocado junto com a sua aplicação.
Quando você executa esse recurso, o processo primeiro prepara o servidor em espera para garantir que ele se atualize com as transações recentes, permitindo que o aplicativo continue executando leituras e gravações. O processo promove o estado de espera e interrompe as conexões com o primário. A sua aplicação pode continuar a gravar no servidor primário enquanto o processo estabelece um novo servidor de standby em background. A tabela a seguir descreve as etapas envolvidas no failover planejado:
| Step | Descrição | Tempo de inatividade do aplicativo esperado? |
|---|---|---|
| 1 | Espere até que o servidor de espera alcance o servidor primário. | Não |
| 2 | O sistema de monitorização interna inicia o fluxo de trabalho de failover. | Não |
| 3 | As escritas de aplicativos são bloqueadas quando o servidor em espera está próximo ao número de sequência de log principal (LSN). | Yes |
| 4 | O servidor em espera é promovido a servidor independente. | Yes |
| 5 | O registro DNS é atualizado com o endereço IP do novo servidor em espera. | Yes |
| 6 | A aplicação reconecta-se e retoma a sua leitura/escrita com o novo servidor primário. | Não |
| 7 | Um novo servidor de espera noutra zona foi estabelecido. | Não |
| 8 | O servidor de espera começa a recuperar logs (do Blob do Azure) que perdeu durante a sua configuração. | Não |
| 9 | Um estado estável entre o servidor primário e o servidor em espera é estabelecido. | Não |
| 10 | O processo de failover planejado está concluído. | Não |
O tempo de inatividade do aplicativo começa na etapa 3 e pode retomar a operação após a etapa 5. O restante das etapas acontece em segundo plano sem afetar as gravações e confirmações do aplicativo.
Sugestão
Com o servidor flexível, você pode, opcionalmente, agendar atividades de manutenção iniciadas pelo Azure escolhendo uma janela de 60 minutos em um dia de sua preferência, quando se espera que as atividades nos bancos de dados sejam baixas. As tarefas de manutenção do Azure, como patches ou atualizações de versões secundárias, acontecem durante essa janela. Se você não escolher uma janela personalizada, o sistema alocará uma janela de uma hora entre 23h e 7h no horário local para o servidor. Essas atividades de manutenção iniciadas pelo Azure também são executadas na réplica em espera para servidores flexíveis configurados com zonas de disponibilidade.
Para obter uma lista de possíveis eventos de tempo de inatividade planejados, consulte Eventos de tempo de inatividade planejados.
Falha não planeada
Tempos de inatividade não planejados podem ocorrer como resultado de interrupções imprevistas, como falhas de hardware subjacentes, problemas de rede e bugs de software. Se o servidor de banco de dados configurado com alta disponibilidade cair inesperadamente, o processo ativará a réplica em espera e os clientes poderão retomar suas operações. Se você não configurar a alta disponibilidade (HA) e a tentativa de reinicialização falhar, o processo provisionará automaticamente um novo servidor de banco de dados. Embora um tempo de inatividade não planejado não possa ser evitado, o servidor flexível ajuda a reduzir o tempo de inatividade executando automaticamente as operações de recuperação sem a necessidade de intervenção humana.
Para obter informações sobre falhas não planeadas e interrupções, incluindo cenários possíveis, consulte Mitigação de interrupções não planeadas.
Teste de failover (failover forçado)
Com um failover forçado, você pode simular um cenário de interrupção não planejada enquanto executa sua carga de trabalho de produção e observar o tempo de inatividade do aplicativo. Você também pode usar um failover forçado quando o servidor primário deixar de responder.
Um failover forçado desativa o servidor primário e inicia o fluxo de trabalho de failover, no qual a operação de promoção do servidor de reserva é realizada. Quando o servidor em espera conclui o processo de recuperação até os últimos dados confirmados, ele é promovido a servidor primário. Os registros DNS são atualizados e seu aplicativo pode se conectar ao servidor primário promovido. O seu aplicativo pode continuar a escrever no servidor primário enquanto um novo servidor de contingência é configurado em segundo plano, sem impactar o tempo de atividade.
A tabela a seguir descreve as etapas durante o failover forçado:
| Step | Descrição | Tempo de inatividade do aplicativo esperado? |
|---|---|---|
| 1 | O servidor primário para logo após receber a solicitação de failover. | Yes |
| 2 | A aplicação enfrenta uma interrupção porque o servidor principal está fora de serviço. | Yes |
| 3 | O sistema de monitoramento interno deteta a falha e inicia um failover para o servidor em espera. | Yes |
| 4 | O servidor em espera entra no modo de recuperação antes de ser totalmente promovido como um servidor independente. | Yes |
| 5 | O processo de failover aguarda a conclusão da recuperação em espera. | Yes |
| 6 | Quando o servidor estiver ativo, o processo atualiza o registro DNS com o mesmo nome de host, mas usa o endereço IP do standby. | Yes |
| 7 | O aplicativo pode se reconectar ao novo servidor primário e retomar a operação. | Não |
| 8 | Um servidor em espera na zona preferencial é estabelecido. | Não |
| 9 | O servidor de espera começa a recuperar logs (do Blob do Azure) que perdeu durante a sua configuração. | Não |
| 10 | Um estado estável entre o servidor primário e o servidor em espera é estabelecido. | Não |
| 11 | O processo de failover forçado está concluído. | Não |
O tempo de inatividade do aplicativo começa após a etapa 1 e continua até a etapa 6 terminar. As outras etapas são executadas em segundo plano sem afetar as gravações e confirmações do aplicativo.
Importante
O processo de comutação de ponta a ponta inclui (a) a comutação para o servidor em espera após a falha primária e (b) o estabelecimento de um novo servidor em espera em estado estável. À medida que seu aplicativo incorre em tempo de inatividade até que o failover para o modo de espera seja concluído, meça o tempo de inatividade da perspetiva do aplicativo/cliente em vez do processo geral de failover de ponta a ponta.
Considerações ao executar failovers forçados
O tempo geral de operação de ponta a ponta pode ser maior do que o tempo de inatividade real experimentado pelo aplicativo.
Importante
Observe sempre o tempo de inatividade do ponto de vista da aplicação!
Não execute failovers imediatos e consecutivos. Aguarde pelo menos 15 a 20 minutos entre failovers, para que o novo servidor em espera possa ser totalmente estabelecido.
Execute um failover forçado durante um período de baixa atividade para reduzir o tempo de inatividade.
Práticas recomendadas para estatísticas do PostgreSQL após failover
Após um failover do PostgreSQL, manter o desempenho ótimo da base de dados envolve compreender os papéis distintos das views pg_statistic e pg_stat_*. A pg_statistic tabela armazena estatísticas do otimizador, que são cruciais para o planejador de consultas. Essas estatísticas incluem distribuições de dados dentro de tabelas e permanecem intactas após um failover, garantindo que o planejador de consultas possa continuar a otimizar a execução de consultas de forma eficaz com base em informações precisas e históricas de distribuição de dados.
Em contraste, as pg_stat_* vistas fornecem estatísticas de atividade em tempo de execução, como o número de varreduras, tuplas lidas e atualizações, que são armazenadas na memória e reiniciadas após o failover. Um exemplo é pg_stat_user_tables, que acompanha a atividade de tabelas definidas pelo utilizador. Essa redefinição reflete com precisão o estado operacional da nova primária, mas também significa a perda de métricas históricas de atividade que poderiam informar o processo de autovácuo e outras eficiências operacionais.
Dada esta distinção, pode considerar executar ANALYZE após um failover do PostgreSQL. Esta ação atualiza os pg_stat_* dados (por exemplo, pg_stat_user_tables) com estatísticas recentes de atividade de vácuo, ajudando o processo de autovácuo, o que, por sua vez, garante que o desempenho da base de dados permaneça ótimo na sua nova função. Essa etapa proativa preenche a lacuna entre a preservação das estatísticas essenciais do otimizador e a atualização das métricas de atividade para alinhá-las com o estado atual do banco de dados.
Experiência de redução de zona
Zonal: Para se recuperar de uma falha ao nível da zona, pode realizar uma restauração de ponto no tempo usando o backup. Você pode escolher um ponto de restauração personalizado com a hora mais recente para restaurar os dados mais recentes. Um novo servidor flexível é implantado em outra zona não afetada. O tempo necessário para restaurar depende do backup anterior e do volume de logs de transações a serem recuperados.
Para obter mais informações sobre restauração point-in-time, consulte Backup e restauração no Servidor Flexível do Azure para PostgreSQL.
Zona redundante: O servidor flexível realiza automaticamente failover para o servidor em espera dentro de 60-120 segundos com perda de dados zero.
Configurações sem zonas de disponibilidade
Embora não seja recomendado, é possível configurar o seu servidor flexível sem a alta disponibilidade ativada. Para servidores flexíveis configurados sem alta disponibilidade, o serviço fornece armazenamento localmente redundante com três cópias de dados, backup com redundância de zona (em regiões onde é suportado) e resiliência de servidor integrada para reiniciar automaticamente um servidor com falha e realocar o servidor para outro nó físico. Esta configuração oferece uma SLA de disponibilidade de 99,9%. Durante eventos de failover planejados ou não planejados, se o servidor ficar inativo, o serviço manterá a disponibilidade dos servidores usando o seguinte procedimento automatizado:
- Uma nova VM Linux de computação é provisionada.
- O armazenamento com arquivos de dados é mapeado para a nova máquina virtual.
- O mecanismo de banco de dados PostgreSQL é colocado online na nova máquina virtual.
A imagem a seguir mostra a transição entre VM e falha de armazenamento.

Recuperação de desastres entre regiões e continuidade de negócios
Se ocorrer um desastre regional, o Azure pode fornecer proteção contra desastres regionais ou de grande geografia através da recuperação de desastres, utilizando outra região. Para obter mais informações sobre a arquitetura de recuperação de desastres do Azure, consulte Arquitetura de recuperação de desastres do Azure para Azure.
O servidor flexível fornece recursos que protegem os dados e reduzem o tempo de inatividade de seus bancos de dados de missão crítica durante eventos de tempo de inatividade planejados e não planejados. Criado com base na infraestrutura do Azure que oferece resiliência e disponibilidade robustas, o servidor flexível oferece recursos de continuidade de negócios que fornecem proteção contra falhas, atendem aos requisitos de tempo de recuperação e reduzem a exposição à perda de dados. Ao arquitetar seus aplicativos, considere a tolerância ao tempo de inatividade - o RTO (Recovery Time Objetive, objetivo de tempo de recuperação) e a exposição à perda de dados - o RPO (Recovery Point Objetive, objetivo de ponto de recuperação). Por exemplo, seu banco de dados crítico para os negócios requer um tempo de atividade mais rigoroso do que um banco de dados de teste.
Recuperação de desastres em geografia de várias regiões
Backup e restauração com redundância geográfica
O backup e a restauração com redundância geográfica oferecem a capacidade de restaurar o servidor em uma região diferente se ocorrer um desastre. Ele também fornece pelo menos 99,99999999999999 por cento (16 noves) de durabilidade de objetos de backup ao longo de um ano.
Você só pode configurar o backup com redundância geográfica ao criar o servidor. Quando você configura o servidor com backup com redundância geográfica, os dados de backup e os logs de transações são copiados para a região emparelhada de forma assíncrona por meio da replicação de armazenamento.
Para obter mais informações sobre backup e restauração com redundância geográfica, consulte Backup e restauração com redundância geográfica.
Réplicas de leitura
Você pode implantar réplicas de leitura entre regiões para proteger seus bancos de dados contra falhas no nível da região. As réplicas de leitura são atualizadas de forma assíncrona usando a tecnologia de replicação física do PostgreSQL e podem atrasar a principal. As camadas de computação para fins gerais e otimizadas para memória suportam réplicas de leitura.
Para obter mais informações sobre as funcionalidades e considerações das réplicas de leitura, consulte Réplicas de leitura.
Deteção, notificação e gerenciamento de interrupções
Se você configurar seu servidor com backup com redundância geográfica, poderá executar a restauração geográfica na região emparelhada. Um novo servidor é provisionado e recuperado com base nos últimos dados disponíveis que foram copiados para esta região.
Pode também usar réplicas de leitura em regiões diferentes. Se ocorrer uma falha de região, poderá executar a operação de recuperação após desastres promovendo a sua réplica de leitura para ser um servidor autónomo com capacidade de leitura e escrita. Espera-se que o RPO seja de até 5 minutos (perda de dados possível), exceto em caso de falha regional grave, quando o RPO pode estar próximo do atraso de replicação no momento da falha.
Para obter mais informações sobre a redução e recuperação de tempo de inatividade não planejado após um desastre regional, consulte Mitigação de tempo de inatividade não planejado.