Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Tip
Microsoft Fabric Data Warehouse é um armazém relacional de escala empresarial baseado numa base de data lake, com uma arquitetura pronta para o futuro, IA incorporada e novas funcionalidades. Se és novo no data warehousing, começa pelo Fabric Data Warehouse. As cargas de trabalho existentes de pool SQL dedicado podem atualizar para o Fabric para acessar novas capacidades em ciência de dados, análise em tempo real e relatórios.
Este guia rápido fornece dicas úteis e melhores práticas para criar soluções dedicadas de pool SQL (anteriormente conhecido como SQL DW).
O gráfico a seguir mostra o processo de criação de um data warehouse com pool SQL dedicado (anteriormente SQL DW):
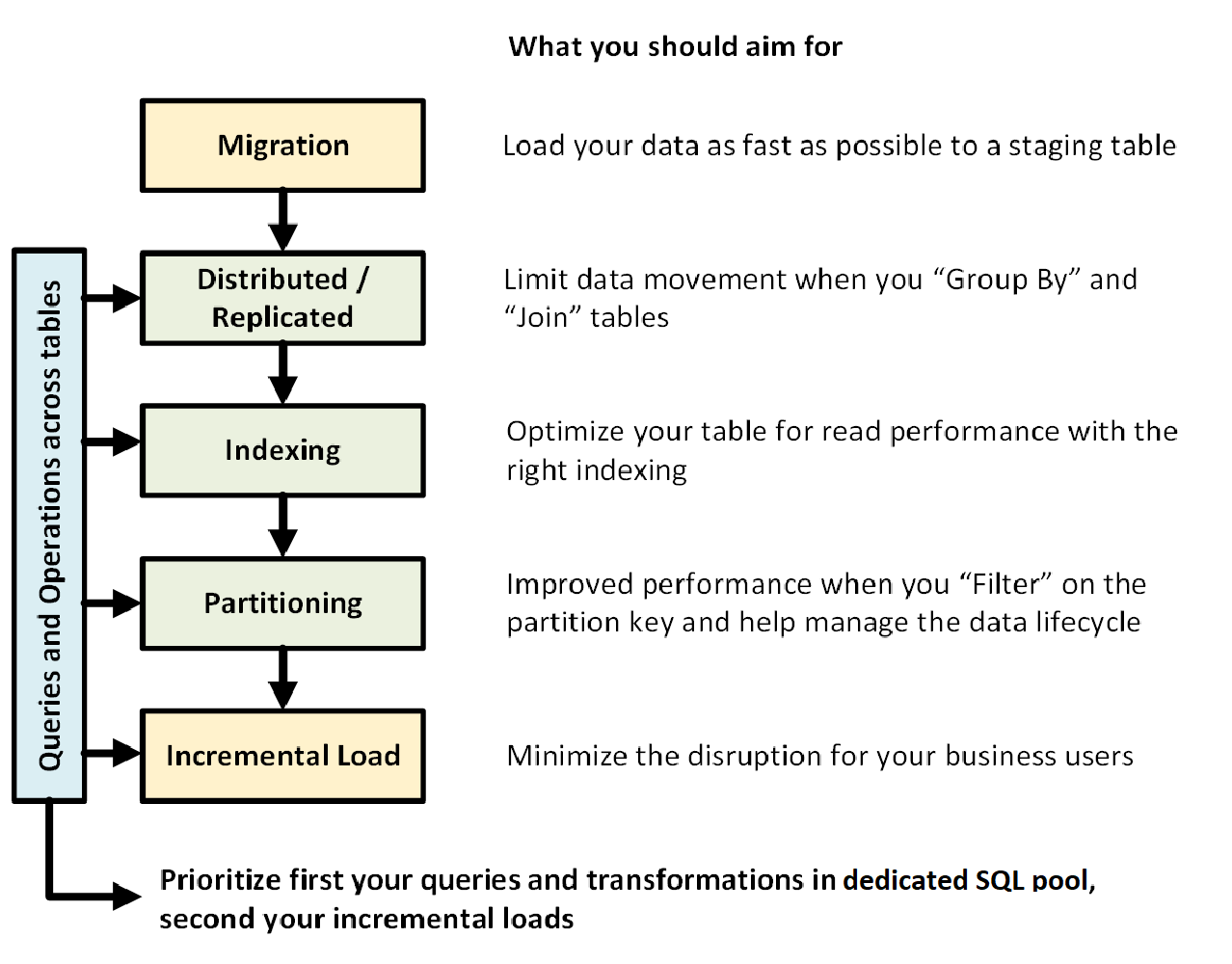
Consultas e operações entre tabelas
Quando você souber com antecedência as principais operações e consultas a serem executadas em seu data warehouse, poderá priorizar sua arquitetura de data warehouse para essas operações. Essas consultas e operações podem incluir:
- Unir uma ou duas tabelas de fatos com tabelas de dimensão, filtrar a tabela combinada e, em seguida, anexar os resultados em um data mart.
- Fazer grandes ou pequenas atualizações nos seus dados de vendas.
- Anexar apenas dados às suas tabelas.
Conhecer os tipos de operações com antecedência ajuda a otimizar o design das suas tabelas.
Migração de dados
Primeiro, carregue seus dados no Armazenamento Azure Data Lake ou no Armazenamento de Blobs do Azure. Em seguida, use a instrução COPY para carregar os dados em tabelas de estágio. Utilize a seguinte configuração:
| Desenho | Recomendação |
|---|---|
| Distribuição | Round Robin |
| Indexação | Heap |
| Particionamento | Nenhum |
| Classe de recursos | largerc ou xlargerc |
Saiba mais sobre migração de dados, carregamento de dados e o processo ELT (Extrair, Carregar e Transformar).
Tabelas distribuídas ou replicadas
Use as seguintes estratégias, dependendo das propriedades da tabela:
| Tipo | Ideal para... | Tenha cuidado se... |
|---|---|---|
| Replicado | * Tabelas de pequena dimensão num esquema de estrela com menos de 2 GB de armazenamento após a compressão (~5x compressão) | * Muitas transações de gravação estão na tabela (como inserir, upsert, excluir, atualizar) * Você altera o provisionamento de unidades de data warehouse (DWU) com freqüência * Você usa apenas 2-3 colunas, mas sua tabela tem muitas colunas * Você indexa uma tabela replicada |
| Round Robin (padrão) | * Tabela temporária/de preparação * Nenhuma chave de junção óbvia ou coluna potencialmente adequada |
* O desempenho é lento devido à movimentação de dados |
| Hash | * Tabelas de factos * Tabelas de grandes dimensões |
* A chave de distribuição não pode ser atualizada |
Sugestões:
- Comece com Round Robin, mas tenha como objetivo uma estratégia de distribuição de hash para aproveitar ao máximo uma arquitetura de grande paralelismo.
- Certifique-se de que as chaves hash comuns têm o mesmo formato de dados.
- Não distribua no formato varchar.
- As tabelas de dimensão, que compartilham uma chave de hash comum com uma tabela de fatos, podem ser distribuídas por hash quando há operações de junção frequentes.
- Utilize sys.dm_pdw_nodes_db_partition_stats para analisar qualquer desequilíbrio nos dados.
- Use o sys.dm_pdw_request_steps para analisar os movimentos de dados por trás das consultas, monitorizar o tempo de difusão e embaralhar as operações. Isso é útil para rever sua estratégia de distribuição.
Saiba mais sobre tabelas replicadas e tabelas distribuídas.
Indexar a sua tabela
A indexação é útil para ler tabelas rapidamente. Há um conjunto exclusivo de tecnologias que você pode usar com base em suas necessidades:
| Tipo | Ideal para... | Tenha cuidado se... |
|---|---|---|
| Heap | * Tabela de preparação/intermédia/temporária * Pequenas tabelas com pequenas buscas |
* Qualquer pesquisa verifica a tabela completa |
| Índice agrupado | * Tabelas com até 100 milhões de linhas * Grandes tabelas (mais de 100 milhões de linhas) com apenas 1-2 colunas muito utilizadas |
* Usado numa tabela replicada * Você tem consultas complexas envolvendo várias operações de junção e agrupamento por * Você faz atualizações nas colunas indexadas: é preciso memória |
| Índice de armazém de colunas clusterizado (CCI) (padrão) | * Grandes tabelas (mais de 100 milhões de linhas) | * Usado numa tabela replicada * Você faz operações de atualização extensas na sua tabela * Você divide excessivamente a sua tabela: os grupos de linhas não se estendem por diferentes nós de distribuição e partições |
Sugestões:
- Além de um índice clusterizado, talvez você queira adicionar um índice não clusterizado a uma coluna muito usada para filtragem.
- Tenha cuidado ao gerenciar a memória em uma tabela com CCI. Ao carregar dados, você deseja que o usuário (ou a consulta) se beneficie de uma classe de recurso grande. Certifique-se de evitar cortar e criar muitos pequenos grupos de linhas compactadas.
- No Gen2, as tabelas CCI são armazenadas em cache localmente nos nós de computação para maximizar o desempenho.
- Para a CCI, o desempenho pode ser lento devido à baixa compactação dos grupos de linhas. Se isso ocorrer, reconstrua ou reorganize sua CCI. Você deseja pelo menos 100.000 linhas por grupos de linhas compactadas. O ideal é 1 milhão de linhas em um grupo de linhas.
- Com base na frequência e no tamanho da carga incremental, você deseja automatizar ao reorganizar ou reconstruir seus índices. A limpeza de primavera é sempre útil.
- Seja estratégico quando quiser reduzir um grupo de linhas. Qual é o tamanho dos grupos de linhas abertas? Quantos dados espera carregar nos próximos dias?
Saiba mais sobre índices.
Particionamento
Você pode particionar sua tabela quando tiver uma tabela de fatos grande (maior que 1 bilhão de linhas). Em 99% dos casos, a chave de partição deve ser baseada na data.
Com tabelas de estágio que exigem ELT, pode beneficiar-se do particionamento. Ele facilita o gerenciamento do ciclo de vida dos dados. Tenha cuidado para não particionar demais a sua tabela de factos ou de estágio, especialmente num índice de columnstore clusterizado.
Saiba mais sobre partições.
Carregamento incremental
Se você vai carregar incrementalmente seus dados, primeiro certifique-se de alocar classes de recursos maiores para carregar seus dados. Isso é particularmente importante ao carregar em tabelas com índices de colunas clusterizados. Consulte classes de recursos para obter mais detalhes.
Recomendamos o uso do PolyBase e do ADF V2 para automatizar seus pipelines ELT em seu data warehouse.
Para um grande lote de atualizações em seus dados históricos, considere usar um CTAS para gravar os dados que você deseja manter em uma tabela em vez de usar INSERT, UPDATE e DELETE.
Manter as estatísticas
É importante atualizar as estatísticas à medida que mudanças significativas acontecem nos seus dados. Consulte atualizar estatísticas para determinar se ocorreram alterações significativas . As estatísticas atualizadas otimizam seus planos de consulta. Se você achar que leva muito tempo para manter todas as suas estatísticas, seja mais seletivo sobre quais colunas têm estatísticas.
Você também pode definir a frequência das atualizações. Por exemplo, talvez você queira atualizar colunas de data, onde novos valores podem ser adicionados, diariamente. Você obtém o maior benefício ao ter estatísticas sobre colunas envolvidas em junções, colunas usadas na cláusula WHERE e colunas encontradas em GROUP BY.
Saiba mais sobre estatísticas.
Classe de recurso
Os grupos de recursos são usados como uma maneira de alocar memória para consultas. Se precisar de mais memória para melhorar a velocidade de consulta ou carregamento, você deve alocar classes de recursos mais altas. Por outro lado, o uso de classes de recursos maiores afeta a simultaneidade. Você deseja levar isso em consideração antes de mover todos os seus usuários para uma classe de recursos grande.
Se notar que as consultas demoram muito, verifique se os usuários não estejam a executar em classes de recursos grandes. Grandes classes de recursos consomem muitos slots de concorrência. Eles podem fazer com que outras consultas fiquem na fila.
Finalmente, usando Gen2 do pool SQL dedicado (anteriormente SQL DW), cada classe de recurso obtém 2,5 vezes mais memória do que Gen1.
Saiba mais como trabalhar com classes de recursos e simultaneidade.
Diminua o seu custo
Um recurso importante do Azure Synapse é a capacidade de gerenciar recursos de computação. Você pode pausar seu pool SQL dedicado (anteriormente SQL DW) quando não estiver usando-o, o que interrompe o faturamento de recursos de computação. Você pode dimensionar recursos para atender às suas demandas de desempenho. Para pausar, use o portal do Azure ou o PowerShell. Para dimensionar, use o portal do Azure, PowerShell, T-SQL ou uma API REST.
Dimensione automaticamente agora no momento desejado com o Funções do Azure:

Otimize sua arquitetura para desempenho
Recomendamos considerar a Base de Dados SQL e o Azure Analysis Services numa arquitetura hub-and-spoke. Essa solução pode fornecer isolamento de carga de trabalho entre diferentes grupos de usuários e, ao mesmo tempo, usar recursos avançados de segurança do Banco de Dados SQL e do Azure Analysis Services. Esta também é uma maneira de fornecer simultaneidade ilimitada para seus usuários.
Saiba mais sobre arquiteturas típicas que aproveitam o pool SQL dedicado (anteriormente SQL DW) no Azure Synapse Analytics.
Desenvolva os spokes em bases de dados SQL a partir do pool dedicado SQL (anteriormente SQL DW):