Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este tutorial mostra-te como construir um recomendador de filmes com ML.NET numa aplicação de consola .NET. Os passos usam C# e Visual Studio 2019.
Neste tutorial, aprenderás como:
- Selecione um algoritmo de aprendizagem automática
- Prepare e carregue os seus dados
- Construir e treinar um modelo
- Avaliar um modelo
- Implementar e consumir um modelo
Podes encontrar o código-fonte deste tutorial no repositório dotnet/samples .
Fluxo de trabalho de aprendizagem automática
Utilizará os seguintes passos para realizar a sua tarefa, bem como qualquer outra tarefa ML.NET:
Pré-requisitos
Selecione a tarefa de aprendizagem automática apropriada
Existem várias formas de abordar problemas de recomendação, como recomendar uma lista de filmes ou recomendar uma lista de produtos relacionados, mas neste caso irá prever que classificação (1-5) um utilizador dará a um determinado filme e recomendá-lo se este for superior a um limiar definido (quanto maior a classificação, maior a probabilidade de um utilizador gostar de um determinado filme).
Criar uma aplicação de consola
Criar um projeto
Crie uma aplicação de consola C# chamada "MovieRecommender". Clique no botão Seguinte.
Escolhe o .NET 8 como framework a usar. Clique no botão Criar .
Crie um diretório chamado Dados no seu projeto para armazenar o conjunto de dados:
No Explorador de Soluções, clique com o botão direito no projeto e selecione Adicionar>Nova Pasta. Escreve "Data" e seleciona Enter.
Instale os pacotes NuGet Microsoft.ML e Microsoft.ML.Recommender :
Observação
Este exemplo utiliza a versão estável mais recente dos pacotes NuGet mencionados, salvo indicação em contrário.
No Gerenciador de Soluções, clique com o botão direito do mouse no projeto e selecione Gerenciar Pacotes NuGet. Escolha "nuget.org" como origem do pacote, selecione a aba Explorar, procure por Microsoft.ML, selecione o pacote na lista e selecione Instalar. Selecione o botão OK na janela de Pré-visualização de Alterações e depois selecione o botão Aceitar na janela de Aceitação de Licença se concordar com os termos da licença dos pacotes listados. Repita estes passos para o Microsoft.ML.Recommender.
Adicione as seguintes
usingdiretivas no topo do seu ficheiro Program.cs :using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Descarregue os seus dados
Descarregue os dois conjuntos de dados e guarde-os na pasta Data que criou anteriormente:
Clique com o botão direito do rato em recommendation-ratings-train.csv e selecione "Guardar Link (ou Alvo) como..."
Clique com o botão direito recommendation-ratings-test.csv e selecione "Guardar Link (ou Alvo) como..."
Certifica-te de que guardas os ficheiros *.csv na pasta Data , ou, depois de os guardares noutro local, moves os ficheiros *.csv para a pasta Data .
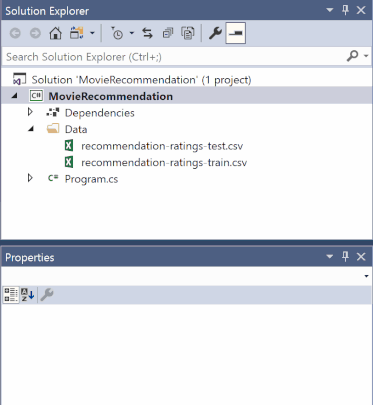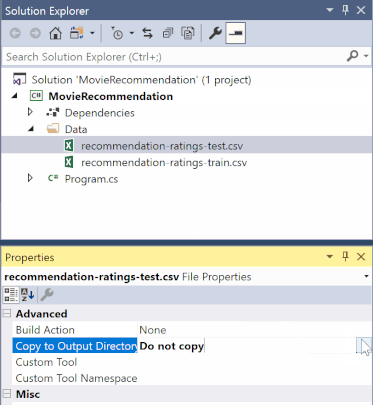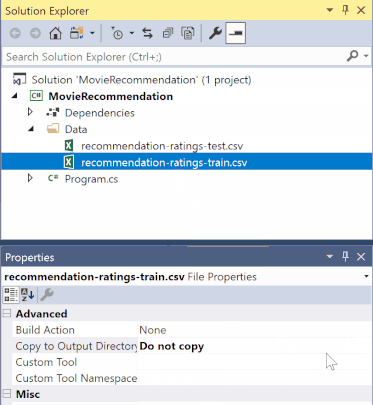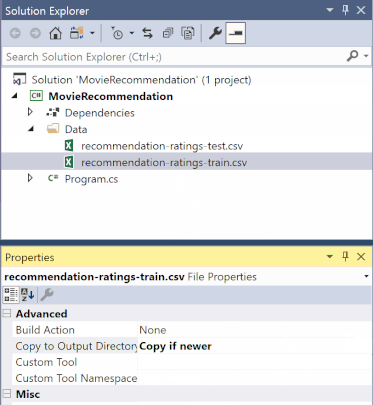
No Explorador de Soluções, clique com o botão direito em cada um dos ficheiros *.csv e selecione Propriedades. Em Avançado, altere o valor de Copiar para Diretório de Saída para Cópia, se for mais recente.
Carregue os seus dados
O primeiro passo no processo de ML.NET é preparar e carregar os dados de treino e teste do modelo.
Os dados das classificações de recomendação estão divididos em conjuntos de dados Train e Test. Os Train dados são usados para ajustar o seu modelo. Os Test dados são usados para fazer previsões com o seu modelo treinado e avaliar o desempenho do modelo. É comum haver uma divisão de 80/20 entre Train os dados.Test
Abaixo está uma pré-visualização dos dados dos seus ficheiros *.csv:
Nos ficheiros *.csv, existem quatro colunas:
userIdmovieIdratingtimestamp
Em aprendizagem automática, as colunas usadas para fazer uma previsão chamam-se Features, e a coluna com a previsão devolvida chama-se Label.
Quer prever as classificações dos filmes, por isso a coluna de classificação é a Label. As outras três colunas, userId, movieId, e timestamp são todas Features usadas para prever o Label.
| Caraterísticas | Etiqueta |
|---|---|
userId |
rating |
movieId |
|
timestamp |
Cabe-lhe a si decidir quais Features são usados para prever o Label. Também pode usar métodos como a importância da característica de permutação para ajudar a selecionar a melhor Features.
Neste caso, deverá eliminar a coluna timestamp como um Feature visto que o carimbo temporal não afeta realmente a forma como um utilizador avalia um determinado filme e, por isso, não contribuiria para fazer uma previsão mais precisa.
| Caraterísticas | Etiqueta |
|---|---|
userId |
rating |
movieId |
De seguida, deve definir a sua estrutura de dados para a classe de entrada.
Adicione uma nova turma ao seu projeto:
No Explorador de Soluções, clique com o botão direito no projeto e depois selecione Adicionar > Novo Item.
Na caixa de diálogo Adicionar Novo Item, selecione Classe e altere o campo Nome para MovieRatingData.cs. Em seguida, selecione Adicionar.
O ficheiro MovieRatingData.cs abre no editor de código. Adicione a seguinte using diretiva no topo da MovieRatingData.cs:
using Microsoft.ML.Data;
Crie uma classe chamada MovieRating removendo a definição de classe existente e adicionando o seguinte código em MovieRatingData.cs:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating especifica uma classe de dados de entrada. O atributo LoadColumn especifica quais as colunas (por índice de colunas) no conjunto de dados que devem ser carregadas. As colunas userId e movieId são os seus Features (os dados de entrada que fornecerá ao modelo para prever o Label), e a coluna de classificação é o Label, que será o que o modelo irá prever (o resultado do modelo).
Crie outra classe, MovieRatingPrediction, para representar os resultados previstos, adicionando o seguinte código após a MovieRating classe em MovieRatingData.cs:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
Em Program.cs, substitua o Console.WriteLine("Hello World!") pelo seguinte código:
MLContext mlContext = new MLContext();
A classe MLContext é um ponto de partida para todas as operações ML.NET, e a inicialização mlContext cria um novo ambiente ML.NET que pode ser partilhado entre os objetos de fluxo de trabalho de criação de modelos. É semelhante, do ponto de vista conceptual, ao DBContext no Entity Framework.
No final do ficheiro, crie um método chamado LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Observação
Este método dar-lhe-á um erro até adicionar uma declaração de retorno nos passos seguintes.
Inicialize as variáveis do caminho dos dados, carregue os dados dos ficheiros *.csv e devolva os Train e Test como objetos IDataView, adicionando o seguinte como a próxima linha de código em LoadData():
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
Os dados em ML.NET são representados como uma interface IDataView.
IDataView é uma forma flexível e eficiente de descrever dados tabulares (numéricos e textuais). Os dados podem ser carregados a partir de um ficheiro de texto ou em tempo real (por exemplo, base de dados SQL ou ficheiros de log) para um IDataView objeto.
O LoadFromTextFile() define o esquema de dados e lê no ficheiro. Recebe as variáveis do caminho de dados e devolve um IDataView. Neste caso, indica o caminho para os seus ficheiros Test e Train e especifica tanto o cabeçalho do ficheiro de texto (para que possa usar corretamente os nomes das colunas) como o separador de dados por vírgula (o separador padrão é o tab).
Adicione o seguinte código para chamar o seu LoadData() método e devolve os Train dados and Test :
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Constrói e treina o teu modelo
Crie o BuildAndTrainModel() método, logo a seguir ao LoadData() método, usando o seguinte código:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Observação
Este método dar-lhe-á um erro até adicionar uma declaração de retorno nos passos seguintes.
Defina as transformações de dados adicionando o seguinte código a BuildAndTrainModel():
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Como userId e movieId representam utilizadores e títulos de filmes, não valores reais, utiliza-se o método MapValueToKey() para transformar cada userIdmovieId uma numa coluna numérica de tipo Feature de chave (um formato aceite por algoritmos de recomendação) e adicioná-las como novas colunas de conjunto de dados:
| userId | movieId | Etiqueta | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | filmeKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
Escolha o algoritmo de aprendizagem automática e anexe-o às definições de transformação de dados, adicionando a seguinte linha de código em BuildAndTrainModel():
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
O MatrixFactorizationTrainer é o seu algoritmo de treino por recomendação. A Fatoração de Matrizes é uma abordagem comum de recomendação quando se tem dados sobre como os utilizadores avaliaram produtos no passado, o que é o caso dos conjuntos de dados deste tutorial. Existem outros algoritmos de recomendação para quando dispõe de dados diferentes (consulte a secção Outros algoritmos de recomendação abaixo para saber mais).
Neste caso, o Matrix Factorization algoritmo utiliza um método chamado "filtragem colaborativa", que assume que, se o Utilizador 1 tiver a mesma opinião que o Utilizador 2 sobre uma determinada questão, então o Utilizador 1 tem mais probabilidade de sentir o mesmo que o Utilizador 2 sobre outra questão.
Por exemplo, se o Utilizador 1 e o Utilizador 2 avaliarem os filmes de forma semelhante, então o Utilizador 2 tem mais probabilidade de gostar de um filme que o Utilizador 1 tenha visto e classificado bem:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Utilizador 1 | Vi e gostei do filme | Vi e gostei do filme | Vi e gostei do filme |
| Utilizador 2 | Vi e gostei do filme | Vi e gostei do filme | Ainda não viu -- RECOMENDO filme |
O Matrix Factorization treinador tem várias Opções, sobre as quais pode ler mais na secção de hiperparâmetros do Algoritmo abaixo.
Ajuste o modelo aos Train dados e devolve o modelo treinado adicionando a seguinte linha de código no BuildAndTrainModel() método:
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
O método Fit() treina o seu modelo com o conjunto de dados de treino fornecido. Tecnicamente, executa as Estimator definições transformando os dados e aplicando o treino, e devolve o modelo treinado, que é um Transformer.
Para mais informações sobre o fluxo de trabalho de treino de modelos em ML.NET, veja O que é ML.NET e como funciona?.
Adicione a seguinte linha de código abaixo da chamada ao LoadData() método para chamar o seu BuildAndTrainModel() método e devolve o modelo treinado:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Avalie o seu modelo
Depois de treinar o seu modelo, utilize os dados de teste para avaliar o desempenho do modelo.
Crie o EvaluateModel() método, logo a seguir ao BuildAndTrainModel() método, usando o seguinte código:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Transforme os Test dados adicionando o seguinte código a EvaluateModel():
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
O método Transform() faz previsões para múltiplas linhas de entrada fornecidas de um conjunto de dados de teste.
Avalie o modelo adicionando a seguinte linha de código no EvaluateModel() método:
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Depois de ter a previsão definida, o método Evaluate() avalia o modelo, que compara os valores previstos com os reais Labels no conjunto de dados de teste e devolve métricas sobre o desempenho do modelo.
Imprima as suas métricas de avaliação na consola adicionando a seguinte linha de código no EvaluateModel() método:
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Adicione a seguinte linha de código abaixo da chamada ao BuildAndTrainModel() método para chamar o seu EvaluateModel() método:
EvaluateModel(mlContext, testDataView, model);
O resultado até agora deverá ser semelhante ao seguinte texto:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
Neste resultado, existem 20 iterações. Em cada iteração, a medida do erro diminui e converge cada vez mais perto de 0.
O root of mean squared error (RMS ou RMSE) é usado para medir as diferenças entre os valores previstos do modelo e os valores observados no conjunto de dados de teste. Tecnicamente, é a raiz quadrada da média dos quadrados dos erros. Quanto mais baixo, melhor é o modelo.
R Squared indica quão bem os dados se encaixam num modelo. Varia de 0 a 1. Um valor 0 significa que os dados são aleatórios ou não podem ser ajustados ao modelo. Um valor de 1 significa que o modelo corresponde exatamente aos dados. Queres que a tua R Squared pontuação seja o mais próxima possível de 1.
Construir modelos bem-sucedidos é um processo iterativo. Este modelo tem qualidade inicial inferior, pois o tutorial utiliza pequenos conjuntos de dados para fornecer treino rápido de modelos. Se não estiver satisfeito com a qualidade do modelo, pode tentar melhorá-lo fornecendo conjuntos de dados de treino maiores ou escolhendo diferentes algoritmos de treino com hiperparâmetros distintos para cada algoritmo. Para mais informações, consulte a secção Melhorar o seu modelo abaixo.
Utilize o seu modelo
Agora pode usar o seu modelo treinado para fazer previsões sobre novos dados.
Crie o UseModelForSinglePrediction() método, logo a seguir ao EvaluateModel() método, usando o seguinte código:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
Use o PredictionEngine para prever a classificação adicionando o seguinte código a UseModelForSinglePrediction():
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
O PredictionEngine é uma API de conveniência, que permite realizar uma previsão sobre uma única instância de dados.
PredictionEngine não é seguro para rosca. É aceitável usar em ambientes monofio ou ambientes de protótipo. Para melhorar o desempenho e a segurança das threads em ambientes de produção, use o PredictionEnginePool serviço, que cria um ObjectPool conjunto de PredictionEngine objetos para usar em toda a sua aplicação. Consulte este guia sobre como usar PredictionEnginePool numa API Web Core ASP.NET.
Observação
PredictionEnginePool A extensão do serviço está atualmente em pré-visualização.
Crie uma instância de MovieRating chamada testInput e passe-a para o Motor de Previsão adicionando as seguintes linhas de código no UseModelForSinglePrediction() método:
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
A função Predict() faz uma previsão sobre uma única coluna de dados.
Pode então usar o Score, ou a classificação prevista, para determinar se quer recomendar o filme com movieId 10 ao utilizador 6. Quanto maior o Score, maior a probabilidade de um utilizador gostar de um determinado filme. Neste caso, digamos que recomendas filmes com uma classificação prevista de > 3,5.
Para imprimir os resultados, adicione as seguintes linhas de código no UseModelForSinglePrediction() método:
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Adicione a seguinte linha de código após a chamada ao EvaluateModel() método para chamar o seu UseModelForSinglePrediction() método:
UseModelForSinglePrediction(mlContext, model);
O resultado deste método deve ser semelhante ao seguinte texto:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Guarde o seu modelo
Para usar o seu modelo para fazer previsões em aplicações de utilizador final, deve primeiro guardar o modelo.
Crie o SaveModel() método, logo a seguir ao UseModelForSinglePrediction() método, usando o seguinte código:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Guarde o seu modelo treinado adicionando o seguinte código no SaveModel() método:
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Este método guarda o seu modelo treinado num ficheiro .zip (na pasta "Data"), que pode depois ser usado noutras aplicações .NET para fazer previsões.
Adicione a seguinte linha de código após a chamada ao UseModelForSinglePrediction() método para chamar o seu SaveModel() método:
SaveModel(mlContext, trainingDataView.Schema, model);
Usa o teu modelo guardado
Depois de guardar o seu modelo treinado, pode consumi-lo em diferentes ambientes. Veja Guardar e carregar modelos treinados para aprender a operacionalizar um modelo de aprendizagem automática treinado em aplicações.
Results
Depois de seguir os passos acima, execute a sua aplicação de consola (Ctrl + F5). Os seus resultados a partir da única previsão acima devem ser semelhantes aos seguintes. Pode ver avisos ou mensagens de processamento, mas estas mensagens foram removidas dos resultados seguintes para maior clareza.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Parabéns! Agora construiu com sucesso um modelo de aprendizagem automática para recomendar filmes. Podes encontrar o código-fonte deste tutorial no repositório dotnet/samples .
Melhore o seu modelo
Existem várias formas de melhorar o desempenho do seu modelo para obter previsões mais precisas.
Data
Adicionar mais dados de treino que tenham amostras suficientes para cada utilizador e ID de filme pode ajudar a melhorar a qualidade do modelo de recomendação.
A validação cruzada é uma técnica para avaliar modelos que divide aleatoriamente os dados em subconjuntos (em vez de extrair dados de teste do conjunto de dados como fez neste tutorial) e utiliza alguns dos grupos como dados de comboio e outros como dados de teste. Este método supera a divisão do teste de comboio em termos de qualidade do modelo.
Caraterísticas
Neste tutorial, usa apenas os três Features (user id, movie id, e rating) que são fornecidos pelo conjunto de dados.
Embora isto seja um bom ponto de partida, na realidade pode querer adicionar outros atributos ou Features (por exemplo, idade, género, geolocalização, etc.) se estiverem incluídos no conjunto de dados. Adicionar elementos mais relevantes Features pode ajudar a melhorar o desempenho do seu modelo de recomendação.
Se não tiver a certeza de qual Features poderá ser o mais relevante para a sua tarefa de aprendizagem automática, pode também utilizar o Cálculo de Contribuição de Funcionalidades (FCC) e a importância da permutação das características, que ML.NET permitem identificar as mais influentes Features.
Hiperparâmetros do algoritmo
Embora o ML.NET forneça bons algoritmos de treino por defeito, pode aperfeiçoar ainda mais o desempenho ajustando os hiperparâmetros do algoritmo.
Para Matrix Factorization, pode experimentar hiperparâmetros como NumberOfIterations e ApproximationRank para ver se isso lhe dá melhores resultados.
Por exemplo, neste tutorial, as opções do algoritmo são:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Outros algoritmos de recomendação
O algoritmo de fatoração matricial com filtragem colaborativa é apenas uma das abordagens para realizar recomendações de filmes. Em muitos casos, pode não ter os dados de classificações disponíveis e somente o histórico de filmes dos utilizadores. Noutros casos, pode ter mais do que apenas os dados de avaliação do utilizador.
| Algorithm | Scenario | Exemplo |
|---|---|---|
| Fatoração de Matrizes de Classe Única | Usa isto quando só tiveres userID e movieId. Este tipo de recomendação baseia-se no cenário de co-compra, ou seja, produtos frequentemente comprados em conjunto, o que significa que irá recomendar aos clientes um conjunto de produtos com base no seu próprio histórico de encomendas. | >Experimenta |
| Máquinas de Fatoração Sensíveis a Campos | Use isto para fazer recomendações quando tiver mais funcionalidades para além do userId, productId e classificação (como descrição do produto ou preço do produto). Este método também utiliza uma abordagem colaborativa de filtragem. | >Experimenta |
Novo cenário de utilizador
Um problema comum na filtragem colaborativa é o problema do arranque a frio, que ocorre quando se tem um novo utilizador sem dados anteriores para tirar inferências. Este problema é frequentemente resolvido pedindo aos novos utilizadores que criem um perfil e, por exemplo, avaliem filmes que já viram no passado. Embora este método coloque algum peso no utilizador, fornece alguns dados iniciais para novos utilizadores sem histórico de avaliações.
Recursos
Os dados usados neste tutorial são derivados do MovieLens Dataset.
Próximos passos
Neste tutorial, você aprendeu como:
- Selecione um algoritmo de aprendizagem automática
- Prepare e carregue os seus dados
- Construir e treinar um modelo
- Avaliar um modelo
- Implementar e consumir um modelo
Avance para o próximo tutorial para saber mais
Colabore connosco no GitHub
A origem deste conteúdo pode ser encontrada no GitHub, onde também pode criar e rever problemas e pedidos Pull. Para mais informações, consulte o nosso guia do contribuidor.