Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a:✅ Armazém de Dados no Microsoft Fabric
Os pipelines de dados oferecem uma alternativa ao uso do comando COPY por meio de uma interface gráfica do usuário. Um pipeline de dados é um agrupamento lógico de atividades que, juntas, executam uma tarefa de ingestão de dados. Os pipelines permitem gerenciar atividades de extração, transformação e carregamento (ETL) em vez de gerenciar cada uma individualmente.
Neste tutorial, você criará um novo pipeline que carrega dados de exemplo em um Warehouse no Microsoft Fabric.
Nota
Alguns recursos do Azure Data Factory não estão disponíveis no Microsoft Fabric, mas os conceitos são intercambiáveis. Você pode saber mais sobre o Azure Data Factory e Pipelines em Pipelines e atividades no Azure Data Factory e no Azure Synapse Analytics. Para obter um guia de início rápido, visite Guia de início rápido: crie seu primeiro pipeline para copiar dados.
Criar um pipeline de dados
Para criar um novo pipeline navegue até seu espaço de trabalho, selecione o botão +Novo e selecione Pipeline de dados.
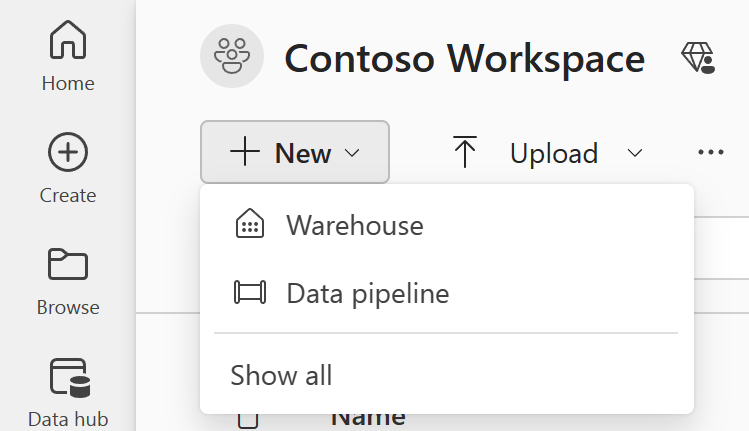
Para criar um novo pipeline, navegue até ao seu espaço de trabalho, selecione o botão + Novo item e selecione Pipeline de dados.
- No espaço de trabalho, selecione + Novo Item e procure o cartão do Pipeline de dados na seção Obter dados.
- Ou selecione Criar no painel de navegação. Procure o cartão do Data pipeline na seção Data Factory.
Na caixa de diálogo Novo pipeline, forneça um nome para o seu novo pipeline e selecione Criar.
** Você chegará na área de tela do pipeline, onde terá opções para começar.
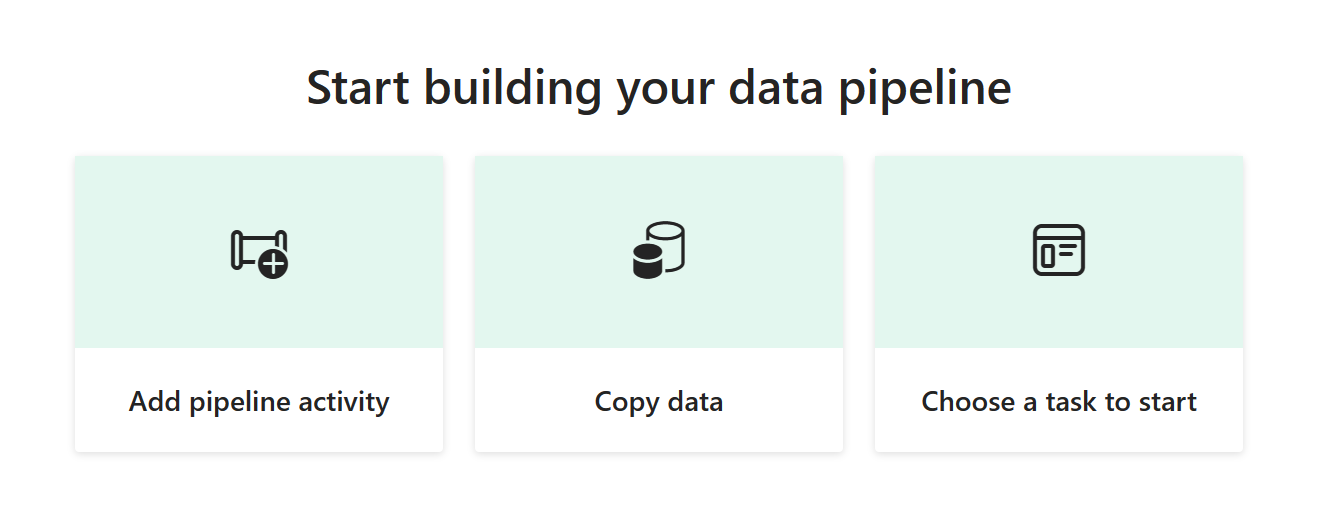
Escolha a opção Assistente de cópia de dados para iniciar o Assistente de cópia.
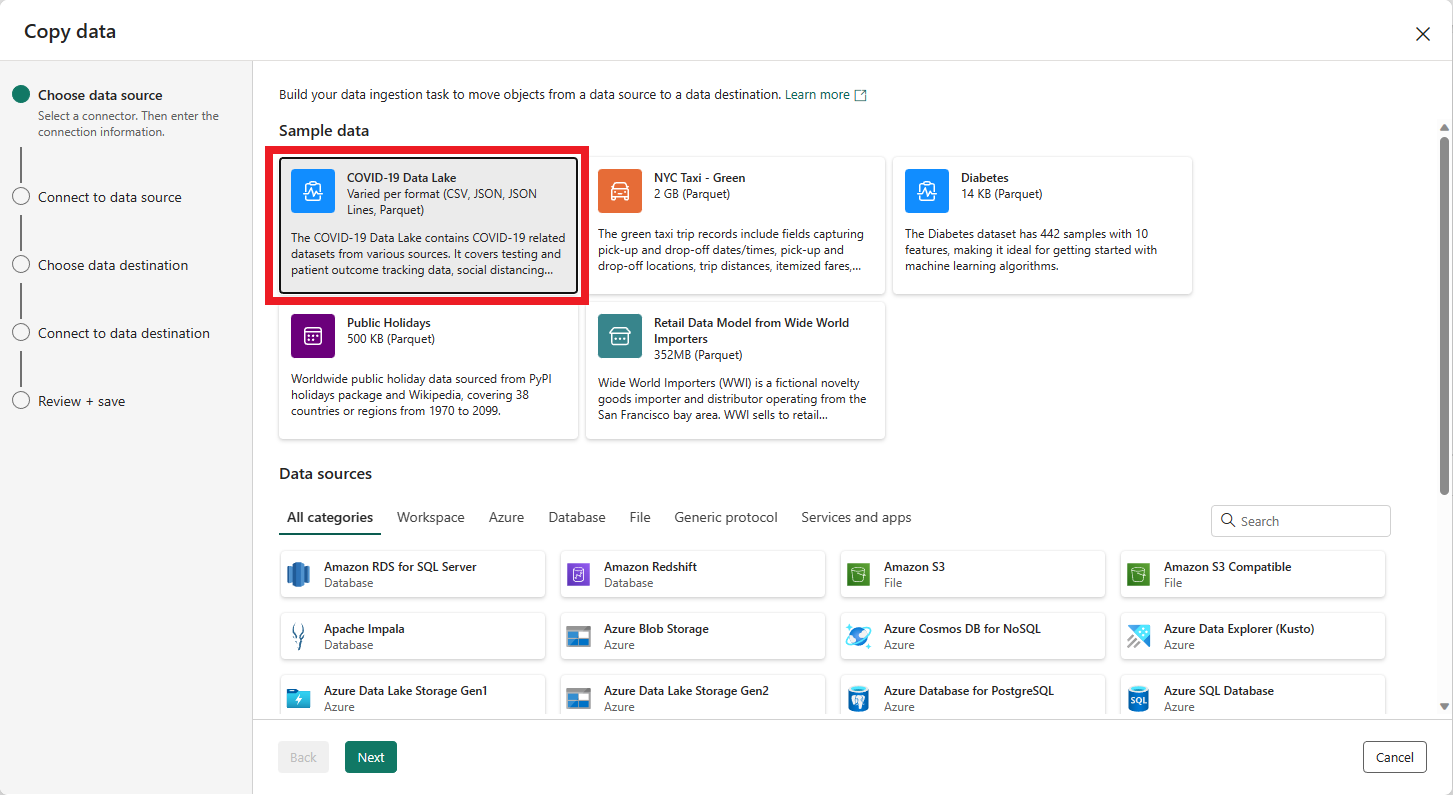
A primeira página do Assistente de cópia de dados ajuda você a escolher seus próprios dados de várias fontes de dados ou selecionar um dos exemplos fornecidos para começar. Selecione Dados de exemplo na barra de menus desta página. Para este tutorial, usaremos o exemplo COVID-19 Data Lake . Selecione esta opção e selecione Avançar.
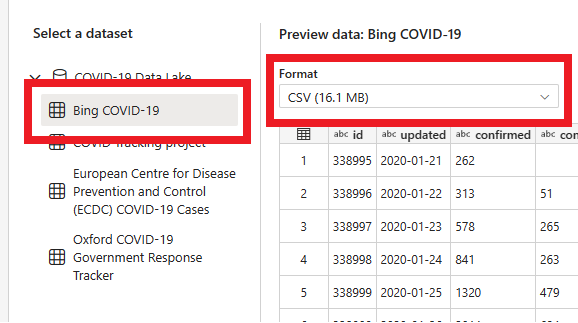
Na próxima página, você pode selecionar um conjunto de dados, o formato de arquivo de origem e visualizar o conjunto de dados selecionado. Selecione Bing COVID-19, o formato CSV , e selecione Avançar.
A próxima página, Destinos de dados, permite configurar o tipo do espaço de trabalho de destino. Carregaremos dados num armazém no nosso espaço de trabalho. Selecione o armazém desejado na lista suspensa e selecione Avançar.
A última etapa para configurar o destino é fornecer um nome para a tabela de destino e configurar os mapeamentos de coluna. Aqui você pode optar por carregar os dados para uma nova tabela ou para uma existente, fornecer um esquema e nomes de tabela, alterar nomes de colunas, remover colunas ou alterar seus mapeamentos. Você pode aceitar os padrões ou ajustar as configurações de acordo com sua preferência.
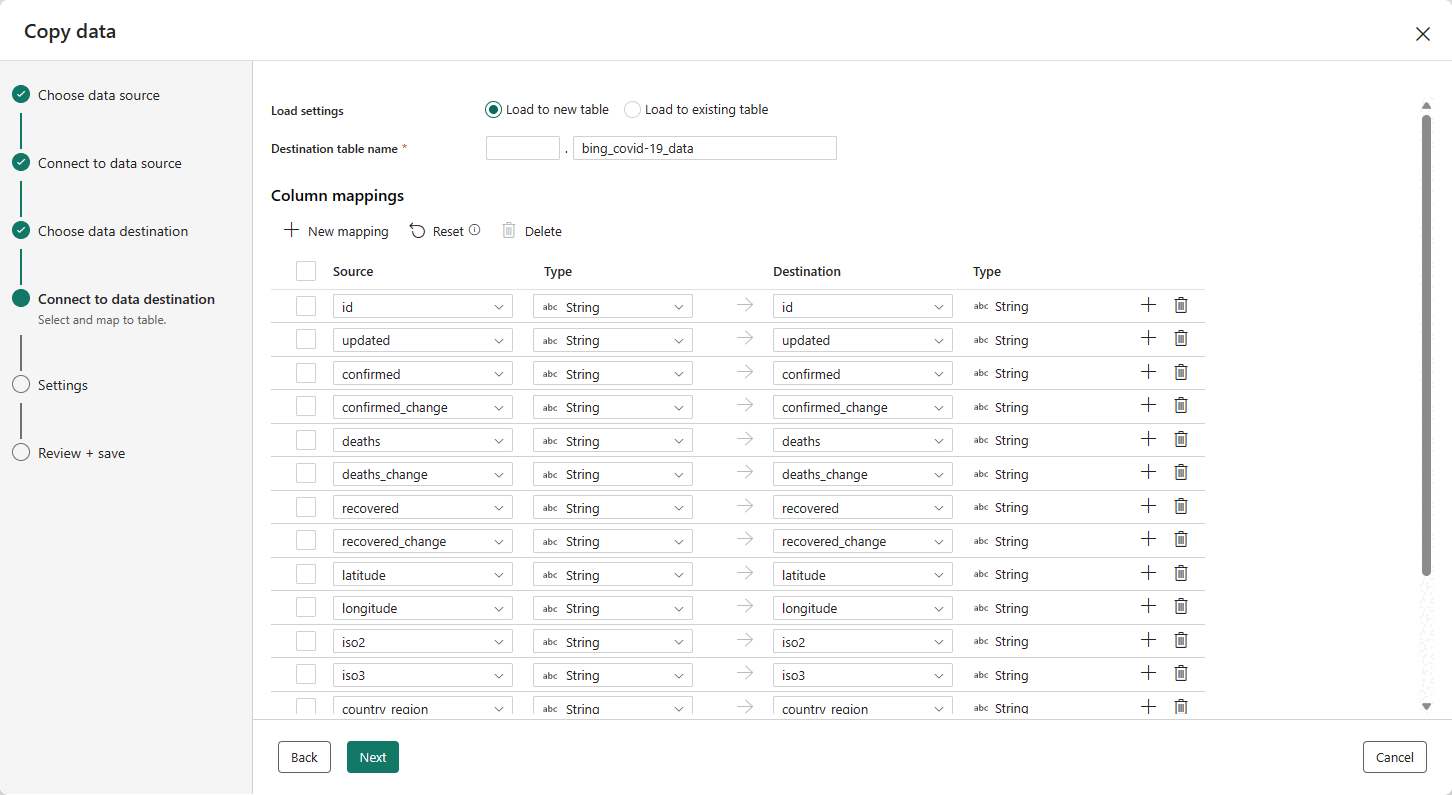
Quando terminar de rever as opções, selecione Seguinte.
A próxima página oferece a opção de utilizar o estágio , ou fornecer opções avançadas para a operação de cópia de dados (que utiliza o comando T-SQL COPY). Reveja as opções sem as alterar e selecione Seguinte.
A última página do assistente oferece um resumo da atividade de cópia. Selecione a opção Iniciar transferência de dados imediatamente e selecione Salvar + Executar.
Você é direcionado para a área de tela do pipeline, onde uma nova atividade de Copiar Dados já está configurada para você. O pipeline começa a ser executado automaticamente. Você pode monitorar o status do pipeline no painel Saída :
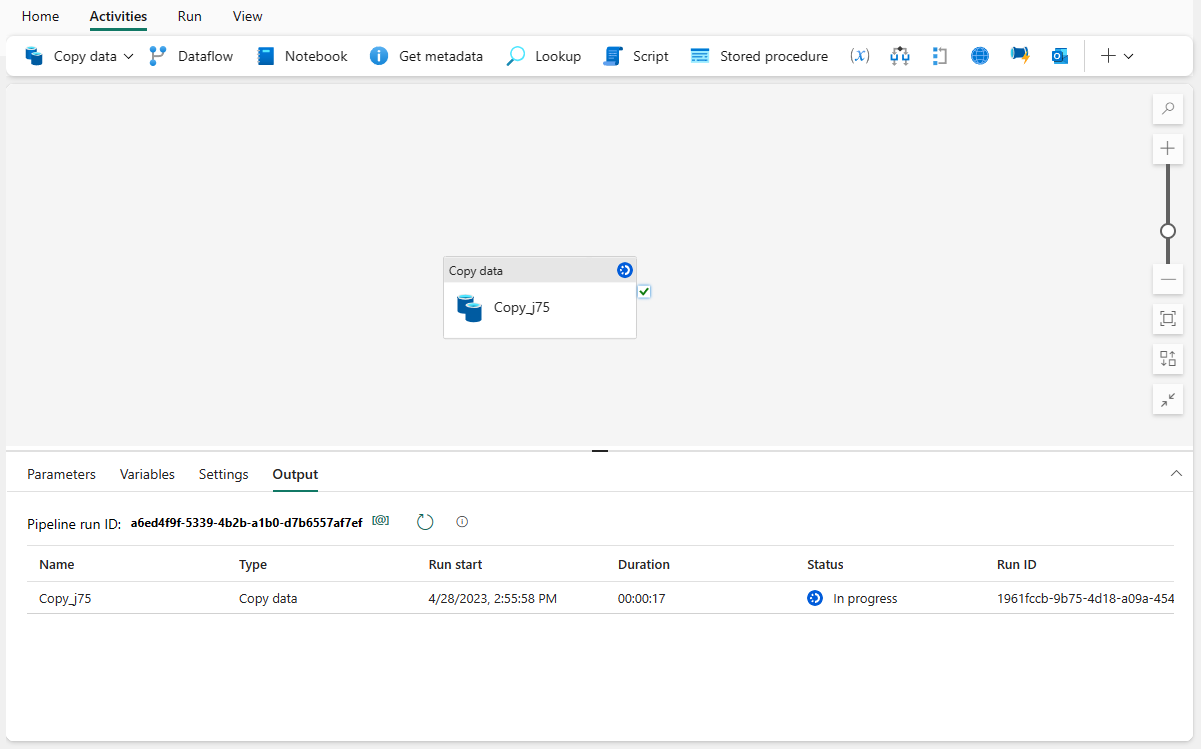
Após alguns segundos, o seu pipeline é concluído com êxito. Navegando de volta ao seu armazém, você pode selecionar sua tabela para visualizar os dados e confirmar que a operação de cópia foi concluída.




Para obter mais informações sobre a ingestão de dados em seu Warehouse no Microsoft Fabric, visite:
- Carregamento de dados no Data Warehouse
- Carregar dados no seu Armazém de Dados usando a instrução COPY
- Ingerir dados em seu Warehouse usando Transact-SQL