Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Os fluxos de dados são suportados para utilizadores do Power BI Pro, Premium Per User (PPU) e Power BI Premium. Alguns recursos só estão disponíveis com uma assinatura do Power BI Premium (que é uma licença de capacidade Premium ou PPU). Este artigo descreve e detalha as funcionalidades exclusivamente PPU e Premium e os seus usos.
Os seguintes recursos estão disponíveis somente com o Power BI Premium (PPU ou uma assinatura de capacidade Premium):
- Mecanismo de computação aprimorado
- DirectQuery
- Entidades computadas
- Entidades Ligadas
- Atualização incremental
As seções a seguir descrevem cada um desses recursos em detalhes.
Importante
Este artigo aplica-se à primeira geração de fluxos de dados (Gen1) e não se aplica à segunda geração (Gen2) de fluxos de dados, que estão disponíveis no Microsoft Fabric. Para mais informações, consulte Atualizar de Dataflow Gen1 para Dataflow Gen2.
O mecanismo de computação aprimorado
O mecanismo de computação aprimorado no Power BI permite que os assinantes do Power BI Premium usem sua capacidade para otimizar o uso de fluxos de dados. O uso do mecanismo de computação aprimorado oferece as seguintes vantagens:
- Reduz drasticamente o tempo de atualização necessário para etapas de ETL (extrair, transformar, carregar) que demoram muito a executar em entidades computadas, como junções, operações distintas, filtros e agregações por grupo.
- Executa consultas DirectQuery sobre entidades.
Nota
- Os processos de validação e atualização informam os fluxos de dados do esquema do modelo. Para definir você mesmo o esquema das tabelas, use o Editor do Power Query e defina tipos de dados.
- Esse recurso está disponível em todos os clusters do Power BI, exceto WABI-INDIA-CENTRAL-A-PRIMARY
Habilite o mecanismo de computação aprimorado
Importante
O mecanismo de computação aprimorado funciona apenas para capacidades A3 ou maiores do Power BI.
No Power BI Premium, o mecanismo de computação aprimorado é definido individualmente para cada fluxo de dados. Há três configurações para escolher:
Desativado
Otimizado (padrão) - O mecanismo de computação aprimorado está desativado. Ele é ativado automaticamente quando uma tabela no fluxo de dados é referenciada por outra tabela ou quando o fluxo de dados é conectado a outro fluxo de dados no mesmo espaço de trabalho.
Em
Para alterar a configuração padrão e habilitar o mecanismo de computação avançado, execute as seguintes etapas:
No espaço de trabalho, ao lado do fluxo de dados para o qual você deseja alterar as configurações, selecione Mais opções.
No menu Mais opções do fluxo de dados, selecione Configurações.
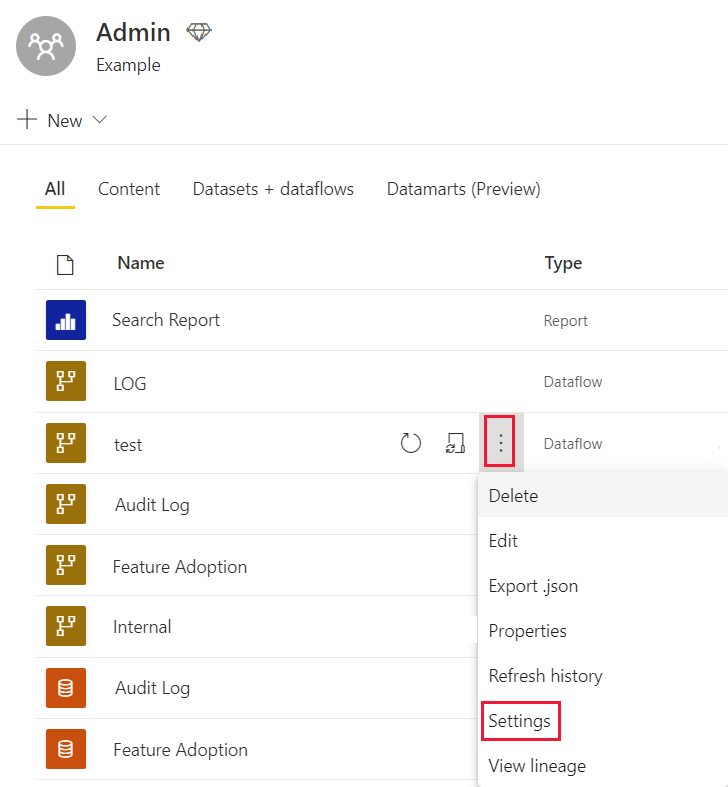
Expanda as configurações do mecanismo de computação Avançado.
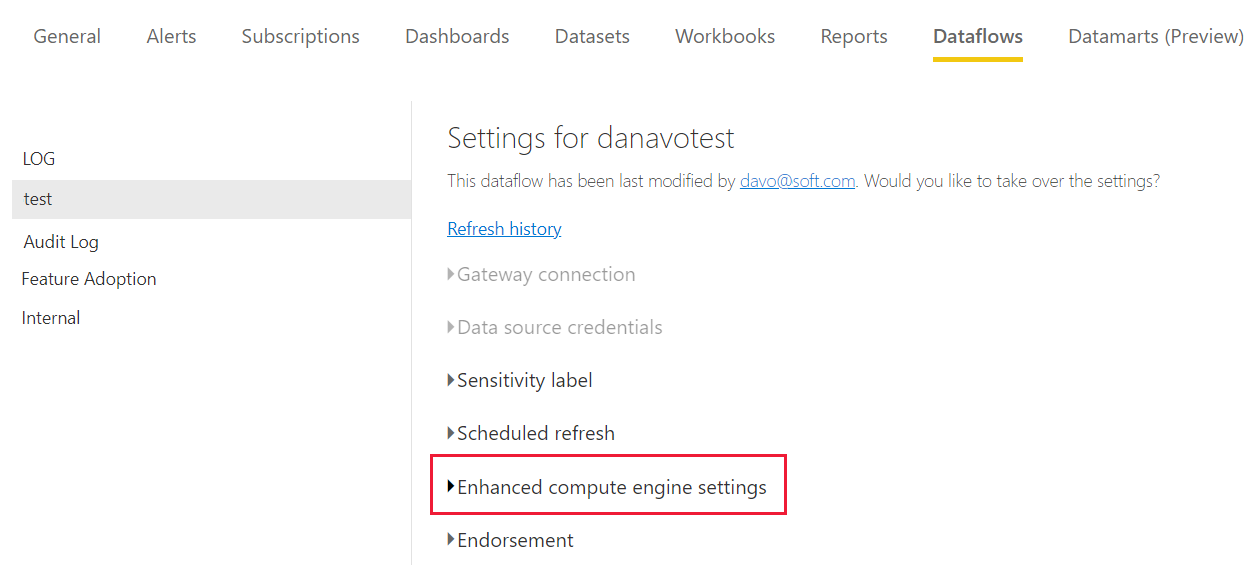
Nas configurações do mecanismo de computação avançado, selecione Ativado e, em seguida, escolha Aplicar.
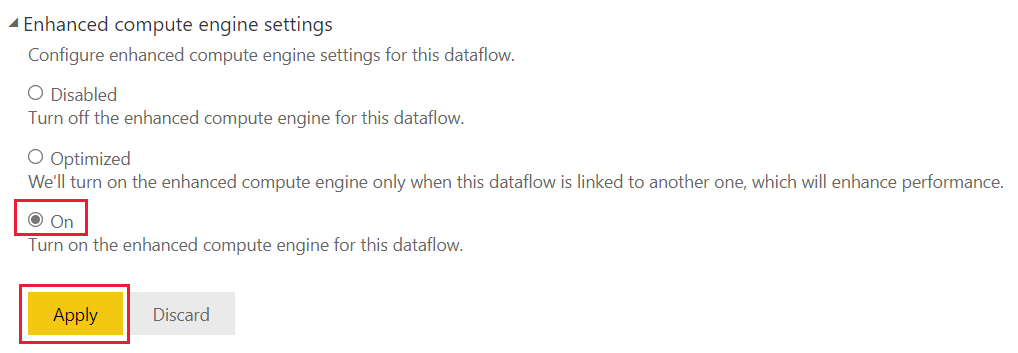
Usar o mecanismo de computação aprimorado
Depois que o mecanismo de computação avançado estiver ativado, retorne aos fluxos de dados e você verá uma melhoria de desempenho em qualquer tabela computada que execute operações complexas, como junções ou operações de agrupamento por operações para fluxos de dados criados a partir de entidades vinculadas existentes na mesma capacidade.
Para fazer o melhor uso do mecanismo de computação, divida o estágio ETL em dois fluxos de dados separados no mesmo espaço de trabalho, da seguinte maneira:
- Fluxo de dados 1 - esse fluxo de dados só deve estar ingerindo todo o necessário de uma fonte de dados.
- Fluxo de dados 2 - execute todas as operações de ETL neste segundo fluxo de dados, mas certifique-se de estar referenciando o fluxo de dados 1, que deve estar na mesma capacidade. Certifique-se também de executar operações que podem dobrar primeiro: filtrar, agrupar por, distinguir, juntar). E execute essas operações antes de qualquer outra operação, para garantir que o mecanismo de computação seja utilizado.
Perguntas e respostas comuns
Pergunta: Ativei o mecanismo de computação aprimorado, mas minhas atualizações são mais lentas. Porquê?
Resposta: Se você habilitar o mecanismo de computação aprimorado, há duas explicações possíveis que podem levar a tempos de atualização mais lentos:
Quando o mecanismo de computação aprimorado está ativado, ele requer alguma memória para funcionar corretamente. Como tal, a memória disponível para executar uma atualização é reduzida e, portanto, aumenta a probabilidade de as atualizações serem enfileiradas. Esse aumento reduz o número de fluxos de dados que podem ser atualizados simultaneamente. Para resolver esse problema, ao habilitar a computação aprimorada, espalhe as atualizações de fluxo de dados ao longo do tempo e avalie se o tamanho da capacidade é adequado, para garantir que haja memória disponível para atualizações simultâneas de fluxo de dados.
Outra razão pela qual você pode encontrar atualizações mais lentas é que o mecanismo de computação só funciona em cima de entidades existentes. Se o seu fluxo de dados fizer referência a uma fonte de dados que não seja um fluxo de dados, você não verá uma melhoria. Não haverá aumento de desempenho, porque em alguns cenários de big data, a leitura inicial de uma fonte de dados seria mais lenta porque os dados precisam ser passados para o mecanismo de computação aprimorado.
Pergunta: Não consigo ver o botão do mecanismo de computação aprimorado. Porquê?
Resposta: O mecanismo de computação aprimorado está sendo lançado em estágios para regiões ao redor do mundo, mas ainda não está disponível em todas as regiões.
Pergunta: Quais são os tipos de dados suportados para o mecanismo de computação?
Resposta: O mecanismo de computação aprimorado e os fluxos de dados atualmente suportam os seguintes tipos de dados. Se o fluxo de dados não usar um dos seguintes tipos de dados, ocorrerá um erro durante a atualização:
- Data/hora
- Número decimal
- Texto
- Número inteiro
- Data/hora/zona
- Verdadeiro/falso
- Date
- Hora
Usar o DirectQuery com fluxos de dados no Power BI
Você pode usar o DirectQuery para se conectar diretamente aos fluxos de dados e, assim, conectar-se diretamente ao seu fluxo de dados sem precisar importar seus dados.
O uso do DirectQuery com fluxos de dados permite os seguintes aprimoramentos para seus processos do Power BI e fluxos de dados:
Evite agendas de atualização separadas - o DirectQuery se conecta diretamente a um fluxo de dados, eliminando a necessidade de criar um modelo semântico importado. Como tal, usar o DirectQuery com seus fluxos de dados significa que você não precisa mais de agendas de atualização separadas para o fluxo de dados e o modelo semântico para garantir que seus dados sejam sincronizados.
Filtrando dados - O DirectQuery é útil para trabalhar em uma exibição filtrada de dados dentro de um fluxo de dados. Você pode usar o DirectQuery com o mecanismo de computação para filtrar dados de fluxo de dados e trabalhar com o subconjunto filtrado necessário. A filtragem de dados permite que você trabalhe com um subconjunto menor e mais gerenciável dos dados em seu fluxo de dados.
Usar o DirectQuery para fluxos de dados
O uso do DirectQuery com fluxos de dados está disponível no Power BI Desktop.
Há pré-requisitos para usar o DirectQuery com fluxos de dados:
- Seu fluxo de dados deve residir em um espaço de trabalho habilitado para Power BI Premium.
- O mecanismo de computação deve estar ligado.
Para saber mais sobre o DirectQuery com fluxos de dados, consulte Usando o DirectQuery com fluxos de dados.
Habilitar o DirectQuery para fluxos de dados
Para garantir que seu fluxo de dados esteja disponível para acesso ao DirectQuery, o mecanismo de computação aprimorado deve estar em seu estado otimizado. Para habilitar o DirectQuery para fluxos de dados, defina a nova opção Configurações avançadas do mecanismo de computação como Ativado.

Depois de aplicar essa configuração, atualize o fluxo de dados para que a otimização entre em vigor.
Considerações e limitações para o DirectQuery
Há algumas limitações conhecidas com o DirectQuery e os fluxos de dados:
Atualmente, não há suporte para modelos compostos/mistos com fontes de dados de importação e DirectQuery.
Grandes fluxos de dados podem enfrentar problemas de tempo limite ao visualizar representações visuais. Grandes fluxos de dados que têm problemas com problemas de tempo limite devem usar o modo de importação.
Em Configurações da fonte de dados, o conector de fluxo de dados mostrará credenciais inválidas se você estiver usando o DirectQuery. Esse aviso não afeta o comportamento e o modelo semântico funcionará corretamente.
Quando um fluxo de dados tem 340 colunas ou mais, usar o conector de fluxo de dados no Power BI Desktop com a configuração do mecanismo de computação avançado habilitada resulta na desativação da opção DirectQuery para o fluxo de dados. Para usar o DirectQuery nessas configurações, use menos de 340 colunas.
Entidades computadas
Você pode executar cálculos em armazenamento ao usar dataflows com uma subscrição Power BI Premium. Esse recurso permite que você execute cálculos em seus fluxos de dados existentes e retorne resultados que permitem que você se concentre na criação e análise de relatórios.
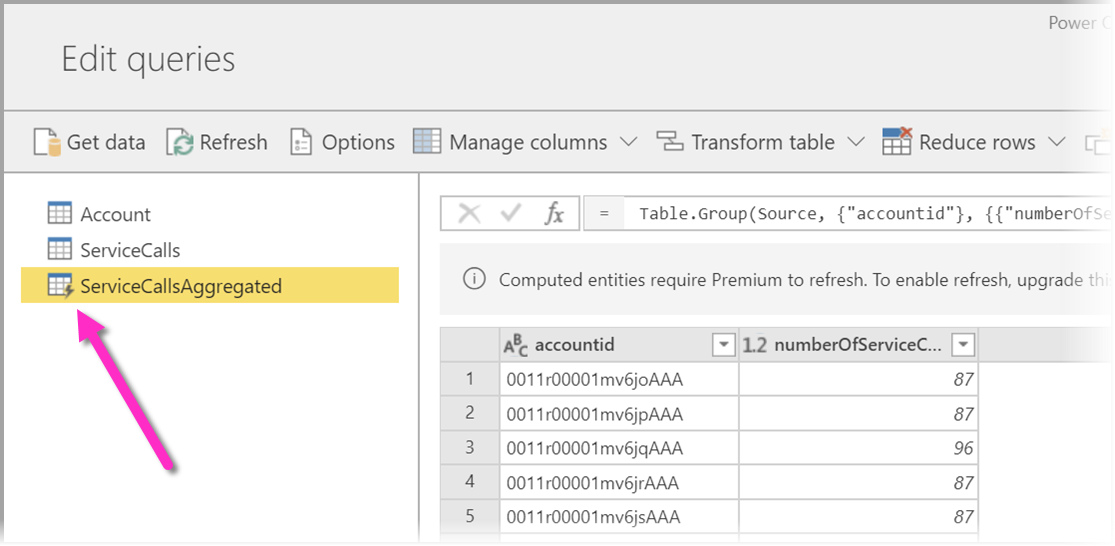
Para executar cálculos no armazenamento, primeiro você deve criar o fluxo de dados e trazer dados para esse armazenamento de fluxo de dados do Power BI. Depois de ter um fluxo de dados que contém dados, você pode criar entidades computadas, que são entidades que executam cálculos no armazenamento.
Considerações e limitações das entidades computadas
Quando você trabalha com fluxos de dados criados na conta do Azure Data Lake Storage Gen2 de uma organização, as entidades vinculadas e as entidades computadas só funcionam corretamente quando as entidades residem na mesma conta de armazenamento.
As entidades computadas só são suportadas em um único espaço de trabalho.
Como prática recomendada, ao fazer cálculos em dados unidos por dados locais e na nuvem, crie um novo fluxo de dados para cada fonte (um para local e outro para nuvem) e, em seguida, crie um terceiro fluxo de dados para mesclar/computar sobre essas duas fontes de dados.
Entidades ligadas
Você pode fazer referência a fluxos de dados existentes no mesmo espaço de trabalho usando entidades vinculadas com uma assinatura do Power BI Premium, que permite executar cálculos nessas entidades usando entidades computadas ou permite criar uma tabela de "única fonte da verdade" que você pode reutilizar em vários fluxos de dados.
Atualização incremental
Os fluxos de dados podem ser definidos para atualizar incrementalmente para evitar ter que extrair todos os dados em cada atualização. Para fazer isso, selecione o fluxo de dados e escolha o ícone Atualização incremental.

A definição de atualização incremental adiciona parâmetros ao fluxo de dados para especificar o intervalo de datas. Para obter informações detalhadas sobre como configurar a atualização incremental, consulteUsando a atualização incremental com fluxos de dados.
Considerações sobre quando não definir a atualização incremental
Não defina um fluxo de dados para atualização incremental nas seguintes situações:
- As entidades vinculadas não devem usar a atualização incremental se fizerem referência a um fluxo de dados.
Conteúdos relacionados
Os seguintes artigos fornecem mais informações sobre fluxos de dados e o Power BI: