Примечание.
В этой статье используется библиотека открытый код, размещенная на сайте GitHubhttps://github.com/mspnp/spark-monitoring:
Исходная библиотека поддерживает Azure Databricks Runtimes 10.x (Spark 3.2.x) и более ранних версий.
Databricks внесли обновленную версию для поддержки Azure Databricks Runtimes 11.0 (Spark 3.3.x) и выше в l4jv2 ветви по адресу: https://github.com/mspnp/spark-monitoring/tree/l4jv2
Обратите внимание, что выпуск 11.0 не совместим обратно из-за различных систем ведения журнала, используемых в Databricks Runtimes. Не забудьте использовать правильную сборку для среды выполнения Databricks. Библиотека и репозиторий GitHub находятся в режиме обслуживания. Нет планов для дальнейших выпусков, и поддержка проблем будет максимальной. Для получения дополнительных вопросов о библиотеке или стратегии мониторинга и ведения журнала сред Azure Databricks обратитесь в службу azure-spark-monitoring-help@databricks.comмониторинга и ведения журнала.
Это решение демонстрирует шаблоны наблюдаемости и метрики для повышения производительности обработки системы больших данных, использующего Azure Databricks.
Архитектура

Скачайте файл Visio для этой архитектуры.
Рабочий процесс
Решение включает следующие шаги:
Сервер отправляет большой файл GZIP, сгруппированный по клиентам, в папку Source в Azure Data Lake Storage (ADLS).
Затем ADLS отправляет успешно распакованный файл клиента в Сетку событий Azure, которая преобразует данные файла клиента в несколько сообщений.
Сетка событий Azure отправляет сообщения в службу Хранилища очередей Azure, которая сохраняет их в очереди.
Хранилище очередей Azure отправляет очередь на платформу аналитики данных Azure Databricks для обработки.
Azure Databricks распаковывает и обрабатывает данные очереди в обработанном файле, который отправляется обратно в ADLS:
Если обработанный файл является допустимым, он помещается в папку Landing.
В противном случае файл помещается в дерево папок Bad. Сначала файл помещается во вложенную папку Retry, и ADLS пытается повторить обработку файла клиента (шаг 2). Если в ходе двух повторных попыток Azure Databricks по-прежнему возвращает обработанные файлы, которые не являются допустимыми, обработанный файл помещается в вложенную папку Failure.
Когда платформа Azure Databricks распаковывает и обрабатывает данные на предыдущем шаге, она также отправляет журналы и метрики приложений в Azure Monitor для хранения.
Рабочая область Azure Log Analytics применяет запросы Kusto к журналам и метрикам приложений из Azure Monitor для устранения неполадок и подробной диагностики.
Компоненты
- Azure Data Lake Storage — это набор выделенных возможностей для аналитики больших данных.
- Сетка событий Azure позволяет разработчикам легко создавать приложения с архитектурой на основе событий.
- Служба Хранилище очередей Azure предназначена для хранения большого количества произвольных сообщений. Она позволяет получить доступ к сообщениям из любой точки мира с помощью вызовов с проверкой подлинности по протоколу HTTP или HTTPS. Вы можете использовать очереди для создания списка невыполненной работы с целью последующей асинхронной обработки.
- Azure Databricks — это платформа аналитики данных, оптимизированная для облачной платформы Azure. Одна из двух сред, которые предлагает Azure Databricks для разработки приложений, интенсивно использующих данные, — это Рабочая область Azure Databricks, унифицированная платформа аналитики на основе Apache Spark для обработки данных в большом масштабе.
- Azure Monitor собирает и анализирует данные телеметрии приложений, такие как метрики производительности и журналы действий.
- Azure Log Analytics — это средство, используемое для изменения и запуска запросов к журналам, связанных с обработкой данных.
Подробности сценария
Ваша команда разработчиков может использовать шаблоны и метрики отслеживаемости для поиска узких мест и повышения производительности системы больших данных. Вашей команде необходимо выполнить нагрузочное тестирование большого потока метрик в крупномасштабном приложении.
В этом сценарии приводятся рекомендации по настройке производительности. Так как в этом сценарии неэффективно вести журналы для каждого клиента с точки зрения производительности, в нем используется платформа Azure Databricks, которая обеспечивает надежный мониторинг следующих элементов:
- Пользовательские метрики приложений
- События запросов потоковой передачи
- Сообщения журнала приложений
Данные мониторинга Azure Databricks можно отправлять в различные службы ведения журналов, например, в Azure Log Analytics.
В этом сценарии описывается прием большого набора данных, сгруппированных по клиентам и сохраненных в архиве GZIP. Подробные журналы Azure Databricks недоступны за пределами пользовательского интерфейса Apache Spark™ в режиме реального времени, поэтому вашей команде потребуется найти способ сохранения всех данных для каждого клиента и их последующего тестирования и сравнения. Для сценария с большим объемом данных важно найти оптимальное сочетание пула исполнителей и размера виртуальных машин (VM) для максимально быстрой обработки данных. Для этого бизнес-сценария приложение в целом полагается на требования к скорости приема и обработки запросов, поэтому пропускная способность системы не будет неожиданно снижаться с увеличением объема обрабатываемых данных. Сценарий должен гарантировать соответствие системы соглашениям об уровне обслуживания (SLA), установленным для ваших клиентов.
Потенциальные варианты использования
Ниже перечислены сценарии, которые могут использовать преимущества этого решения:
- Наблюдение за работоспособностью системы.
- Поддержание производительности.
- Мониторинг повседневного использования системы.
- Выявление тенденций, которые могут привести к проблемам, если не будут устранены.
Рекомендации
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая является набором руководящих принципов, которые можно использовать для улучшения качества рабочей нагрузки. Дополнительные сведения см. в статье Microsoft Azure Well-Architected Framework.
При рассмотрении данной архитектуры учитывайте следующие рекомендации:
Azure Databricks может автоматически выделять вычислительные ресурсы, необходимые для крупных заданий, что позволяет избежать проблем, которые могут возникнуть в других решениях. Например, в случае автомасштабирования, оптимизированного для Databricks, в Apache Spark чрезмерная подготовка может привести к неоптимальному использованию ресурсов. Или вам может быть неизвестно точное число исполнителей, необходимых для задания.
Максимальный размер сообщения в очереди Хранилища очередей Azure составляет 64 КБ. Очередь может содержать несколько миллионов сообщений, вплоть до общего ограничения емкости учетной записи хранения.
Оптимизация затрат
Оптимизация затрат заключается в поиске способов уменьшения ненужных расходов и повышения эффективности работы. Дополнительные сведения см. в разделе Обзор критерия "Оптимизация затрат".
Чтобы оценить затраты на реализацию этого решения, используйте Калькулятор цен Azure.
Развертывание этого сценария
Примечание.
Описанные здесь действия по развертыванию относятся только к Azure Databricks, Azure Monitor и Azure Log Analytics. Развертывание других компонентов не рассматривается в этой статье.
Чтобы получить все журналы и сведения о процессе, настройте Azure Log Analytics и библиотеку мониторинга Azure Databricks. Библиотека мониторинга осуществляет потоковую передачу событий уровня Apache Spark и метрик Spark Structured Streaming из ваших заданий в Azure Monitor. Для использования этих событий и метрик никаких изменений в код приложения вносить не потребуется.
Ниже приведены действия по настройке производительности для системы обработки больших данных:
На портале Azure создайте рабочую область Azure Databricks. Скопируйте и сохраните идентификатор подписки Azure (глобальный уникальный идентификатор (GUID)), имя группы ресурсов, имя рабочей области Databricks и URL-адрес портала рабочей области для последующего использования.
В веб-браузере перейдите по URL-адресу рабочей области Databricks и создайте личный маркер доступа. Скопируйте и сохраните строку маркера (которая начинается с
dapiи содержит 32-разрядное шестнадцатеричное значение) для последующего использования.Клонируйте репозиторий GitHub mspnp/spark-monitoring на локальный компьютер. Этот репозиторий содержит исходный код для следующих компонентов:
- Шаблон Azure Resource Manager (шаблон ARM) для создания рабочей области Azure Log Analytics, которая также устанавливает предварительно созданные запросы для сбора метрик Spark
- Библиотеки мониторинга Azure Databricks
- Пример приложения для отправки метрик и журналов приложений из Azure Databricks в Azure Monitor.
С помощью команды Azure CLI для развертывания шаблона ARM создайте рабочую область Azure Log Analytics с предварительно созданными запросами метрик Spark. В выходных данных команды скопируйте и сохраните имя созданной рабочей области Log Analytics (в формате spark-monitoring-<случайная строка>).
На портале Azure скопируйте идентификатор и ключ рабочей области Log Analytics и сохраните их для последующего использования.
Установите выпуск Community интегрированной среды разработки IntelliJ IDEA, которая имеет встроенную поддержку Java Development Kit (JDK) и Apache Maven. Добавьте подключаемый модуль Scala.
Используя IntelliJ IDEA, выполните сборку библиотек мониторинга Azure Databricks. Чтобы выполнить фактическую сборку, выберите Вид>Окна инструментов>Maven, чтобы открыть окно инструментов Maven, затем выберите Выполнить цель Maven>пакет mvn.
С помощью средства установки пакетов Python установите Azure Databricks CLI и настройте проверку подлинности с помощью личного маркера доступа Databricks, который был скопирован ранее.
Настройте рабочую область Azure Databricks, указав в скрипте инициализации Databricks значения параметров для Databricks и Log Analytics, скопированные ранее, а затем с помощью Azure Databricks CLI скопируйте скрипт инициализации и библиотеки мониторинга Azure Databricks в рабочую область Databricks.
На портале рабочей области Databricks создайте и настройте кластер Azure Databricks.
В IntelliJ IDEA создайте пример приложения с помощью Maven. Затем на портале рабочей области Databricks запустите пример приложения, чтобы создать примеры журналов и метрик для Azure Monitor.
Пока пример задания выполняется в Azure Databricks, перейдите на портал Azure, чтобы просмотреть и запросить типы событий (журналы и метрики приложений) в интерфейсе Log Analytics:
- Выберите Таблицы>Пользовательские журналы, чтобы просмотреть схему таблицы для событий прослушивателя Spark (SparkListenerEvent_CL), событий ведения журнала Spark (SparkLoggingEvent_CL) и метрик Spark (SparkMetric_CL).
- Выберите Обозреватель запросов>Сохраненные запросы>Метрики Spark, чтобы просмотреть и выполнить запросы, которые были добавлены при создании рабочей области Log Analytics.
Дополнительные сведения о просмотре и выполнении предварительно созданных и настраиваемых запросов приведены в следующем разделе.
Запрос журналов и метрик в Azure Log Analytics
Доступ к предварительно созданным запросам
Ниже перечислены имена предварительно созданных запросов для получения метрик Spark.
- % времени ЦП на исполнителя
- % времени десериализации на исполнителя
- % времени виртуальной машины Java на исполнителя
- % времени сериализации на исполнителя
- Байт отправлено на диск
- Трассировок ошибок (неправильная запись или неверные файлы)
- Прочитано байт файловой системы на исполнителя
- Записано байт файловой системы на исполнителя
- Ошибок при выполнении заданий на задание
- Задержка задания на задание (длительность пакета)
- Пропускная способность задания
- Запущенных исполнителей
- Прочитано байт в случайном порядке
- Прочитано байт в случайном порядке на исполнителя
- Прочитано байт в случайном порядке на диске на исполнителя
- Прямая память клиента в случайном порядке
- Память клиента в случайном порядке на исполнителя
- Байт отправлено на диск в случайном порядке на исполнителя
- Объем памяти кучи в случайном порядке на исполнителя
- Байт отправлено в память в случайном порядке на исполнителя
- Задержка этапа на этап (длительность этапа)
- Пропускная способность этапа на этап
- Ошибок потоковой передачи на поток
- Задержка потоковой передачи на поток
- Пропускная способность потоковой передачи: входных строк/с
- Пропускная способность потоковой передачи: обработанных строк/с
- Суммарное выполнение задач на узел
- Время десериализации задачи
- Число ошибок задачи на этап
- Время вычисления для исполнителя задачи (время неравномерного распределения данных)
- Прочитано входных байт задачи
- Задержка задачи на этап (длительность задач)
- Время сериализации результата задачи
- Задержка планировщика задач
- Прочитано байт задачи в случайном порядке
- Записано байт задачи в случайном порядке
- Время чтения в случайном порядке для задачи
- Время записи в случайном порядке для задачи
- Пропускная способность задачи (сумма задач на этап)
- Задач на исполнителя (суммарное количество задач на исполнителя)
- Число задач на этап
Написание пользовательских запросов
Вы также можете создавать собственные запросы на языке запросов Kusto (KQL). Для этого просто нажмите на верхнюю среднюю панель, которую можно редактировать, и измените запрос в соответствии с вашими потребностями.
Следующие два запроса получают данные из событий ведения журнала Spark:
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
Эти два примера представляют собой запросы к журналу метрик Spark:
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
Терминология запросов
В следующей таблице описаны некоторые термины, используемые при создании запросов для журналов и метрик приложений.
| Термин | Идентификатор | Замечания |
|---|---|---|
| Инициализация кластера | Application ID | |
| Queue | ИД запуска | Один идентификатор запуска соответствует нескольким пакетам. |
| Пакетная служба | Идентификатор пакета | Один пакет соответствует двум заданиям. |
| Работа | Идентификатор задания | Одно задание соответствует двум этапам. |
| Этап | Идентификатор этапа | Один этап содержит 100–200 идентификаторов задач в зависимости от задачи (чтение, запись или обработка в случайном порядке). |
| Задачи | Идентификатор задачи | Одна задача назначается одному исполнителю. Одной задаче назначается действие partitionBy для одной секции. Для 200 клиентов потребуется 200 задач. |
Следующие разделы содержат типичные метрики, используемые в этом сценарии для мониторинга пропускной способности системы, состояния выполнения заданий Spark и использования системных ресурсов.
Пропускная способность системы
| Имя. | Измерение | единиц(ы) |
|---|---|---|
| Пропускная способность потоковой передачи | Средняя скорость ввода данных по сравнению со средней скоростью обработки данных в минуту | Строк в минуту |
| Длительность задания | Среднее время выполнения заданий Spark в минуту | Время выполнения в минуту |
| Число заданий | Среднее число выполненных заданий Spark в минуту | Число заданий в минуту |
| Длительность этапа | Средняя длительность завершенных этапов в минуту | Время выполнения в минуту |
| Количество этапов | Среднее число завершенных этапов в минуту | Число этапов в минуту |
| Длительность выполнения задачи | Среднее время завершения задач в минуту | Время выполнения в минуту |
| Число задач | Среднее число выполненных задач в минуту | Число задач в минуту |
Состояние выполнения задания Spark
| Имя. | Измерение | единиц(ы) |
|---|---|---|
| Число пулов планировщика | Число различных пулов планировщика в минуту (число работающих очередей) | Число пулов планировщика |
| Число запущенных исполнителей | Число запущенных исполнителей в минуту | Число запущенных исполнителей |
| Трассировка ошибок | Все журналы ошибок с уровнем Error и соответствующими задачами или идентификатором этапа (показаны в thread_name_s) |
Использование системных ресурсов
| Имя. | Измерение | единиц(ы) |
|---|---|---|
| Среднее использование ЦП на одного исполнителя/общее | Процент использования ЦП на исполнителя в минуту | % в минуту |
| Среднее использование прямой памяти (МБ) на узел | Среднее использование прямой памяти на исполнителей в минуту | МБ в минуту |
| Объем памяти, записанной на диск, на узел | Средняя объем памяти, записанной на диск, на исполнителя | МБ в минуту |
| Отслеживание влияния неравномерного распределения данных на длительность | Измерение диапазона и разности 70-го и 90-го процентилей и 90-го и 100-го процентилей в продолжительности задач | Чистая разница между 100 %, 90 % и 70 %; разница в процентах между 100 %, 90 % и 70 % |
Решите, как связать введенные пользователем данные, объединенные в файл архива GZIP, с определенным выходным файлом Azure Databricks, так как Azure Databricks обрабатывает всю пакетную операцию как единое целое. Здесь вы применяете детализацию к данным трассировки. Вы также применяете пользовательские метрики для трассировки одного выходного файла в исходный входной файл.
Более подробные определения каждой метрики см. в разделе Визуализации на панелях мониторинга на этом веб-сайте или в разделе Метрики документации по Apache Spark.
Оценка параметров настройки производительности
Определение базовых показателей
Вы и ваша команда разработчиков должны установить базовые показатели для оценки будущего состояния приложения.
Оцените производительность приложения количественно. В этом сценарии ключевой метрикой является задержка задания, которая является типичной для большинства операций предварительной обработки и приема данных. Попытайтесь ускорить обработку данных и сосредоточьтесь на измерении задержки, как показано на приведенной ниже диаграмме:
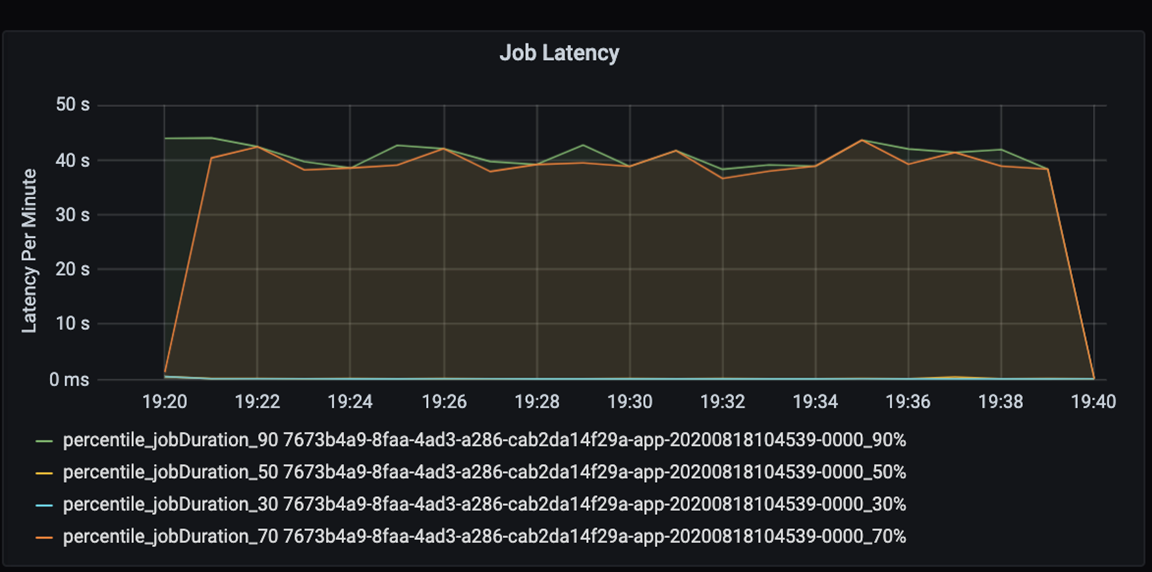
Оцените задержку выполнения задания: получите грубую оценку общей производительности задания и время выполнения задания от начала до завершения (время микропакетной обработки). На приведенной выше диаграмме на обработку задания требуется около 40 секунд (отметка 19:30).
Если рассмотреть эти 40 секунд подробнее, вы увидите приведенные ниже данные для этапов:
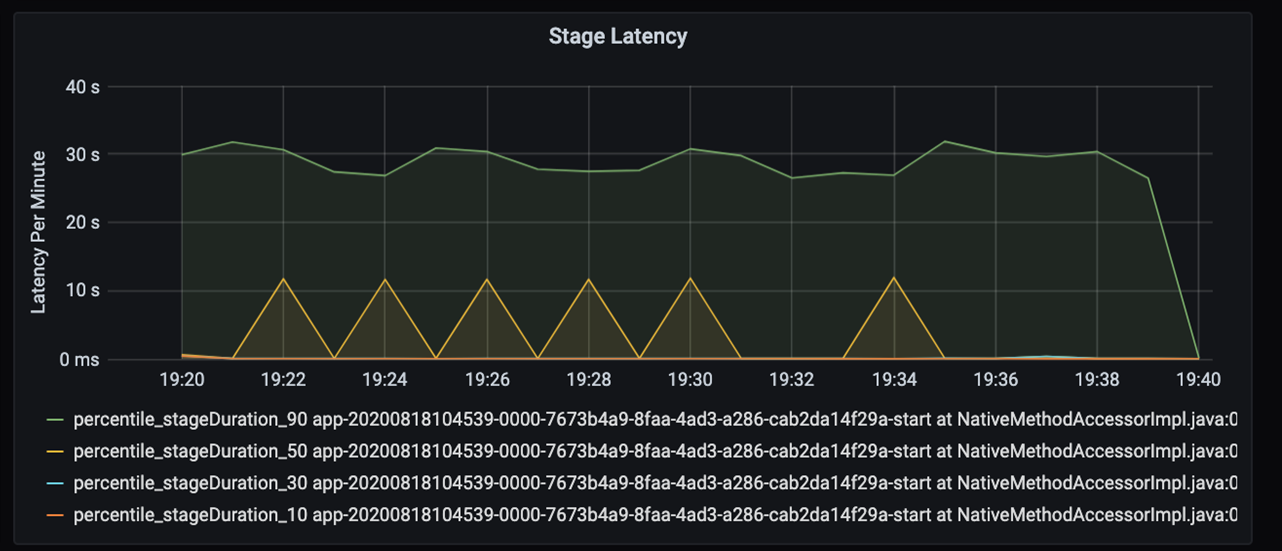
На отметке 19:30 есть два этапа: оранжевый этап продолжительностью 10 секунд и зеленый этап продолжительностью 30 секунд. Отслеживайте пики для этапа, так как пик указывает на задержку на этом этапе.
Если определенный этап выполняется медленно, изучите эту ситуацию. В сценарии секционирования обычно существует по крайней мере два этапа: один этап для чтения файла и другой этап для обработки данных в случайном порядке, секционирования и записи файла. Если задержка возникает преимущественно на этапе записи, то во время секционирования может возникнуть проблема, связанная с узким местом.
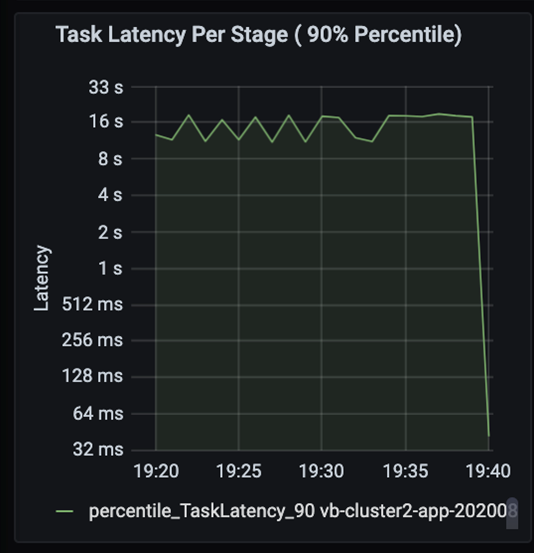
Следите за последовательным выполнением этапов в задачах, при котором запуск более поздних этапов возможен только после завершения более ранних этапов. В пределах этапа если одна задача выполняет секционирование в случайном порядке медленнее по сравнению с другими задачами, то все задачи в кластере должны дожидаться завершения более медленной задачи для завершения этапа. Поэтому задачи позволяют отслеживать неравномерное распределение данных и выявлять возможные узкие места. На приведенной выше диаграмме видно, что все задачи распределены равномерно.
Теперь отслеживайте время обработки. Так как вы используете сценарий потоковой передачи, посмотрите на пропускную способность потоковой передачи.
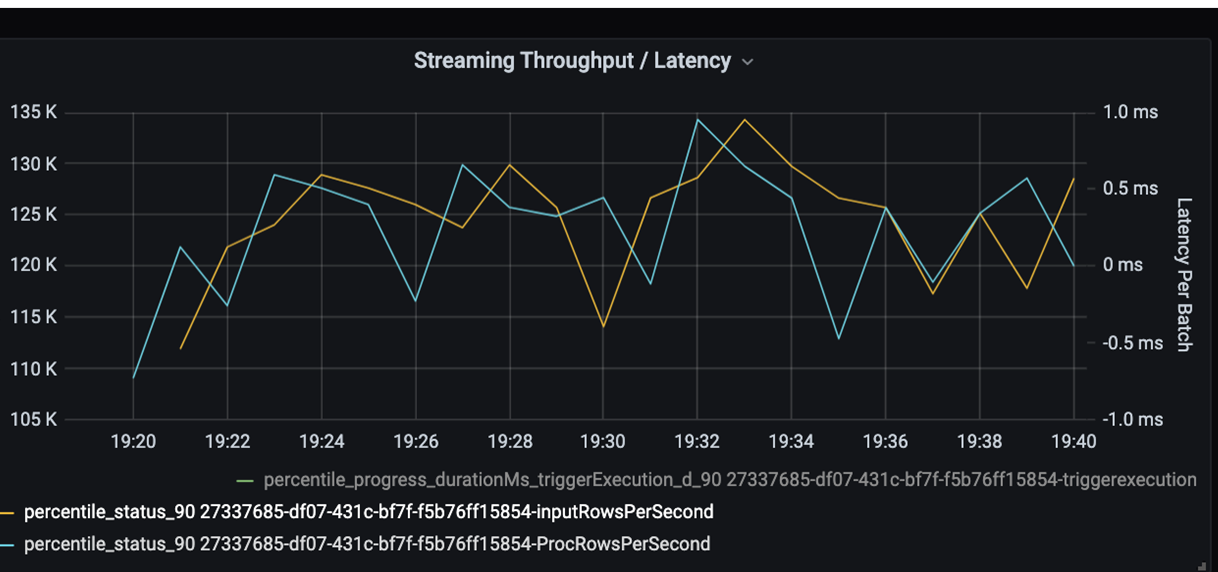
На приведенной выше диаграмме с пропускной способностью потоковой передачи/задержкой пакетной обработки оранжевая линия представляет скорость ввода данных (число входных строк в секунду). Синяя линия представляет скорость обработки данных (число обработанных строк в секунду). В некоторых случаях скорость обработки не является достаточно высокой для обработки данных с указанной скоростью ввода. Это может привести к тому, что входные файлы начнут накапливаться в очереди.
Так как на диаграмме скорость обработки данных не соответствует скорости ввода данных, попробуйте повысить скорость обработки, чтобы успевать обрабатывать все вводимые данные. Одной из возможных причин может быть неравномерное распределение данных клиента в каждом ключе секции, что приводит к появлению узких мест. Для следующего этапа и для реализации потенциального решения воспользуйтесь возможностями масштабирования Azure Databricks.
Анализ секционирования
Сначала необходимо определить правильное число исполнителей масштабирования, необходимых для Azure Databricks. Примените эмпирическую оценку при назначении каждой секции выделенных ресурсов ЦП в запущенных исполнителях. Например, если у вас есть 200 ключей секций, то число процессоров, умноженное на число исполнителей, должно равняться 200. (Например, восемь ЦП в сочетании с 25 исполнителями были бы хорошим совпадением.) При использовании 200 ключей секций каждый исполнитель может работать только над одной задачей, что снижает вероятность узких мест.
Поскольку в этом сценарии используется ряд медленных секций, изучите широкий разброс в продолжительности выполнения задач. Проверьте наличие пиков в продолжительности выполнения задач. Каждая задача обрабатывает одну секцию. Если задаче требуется больше времени, секция может стать слишком большой и привести к появлению узкого места.
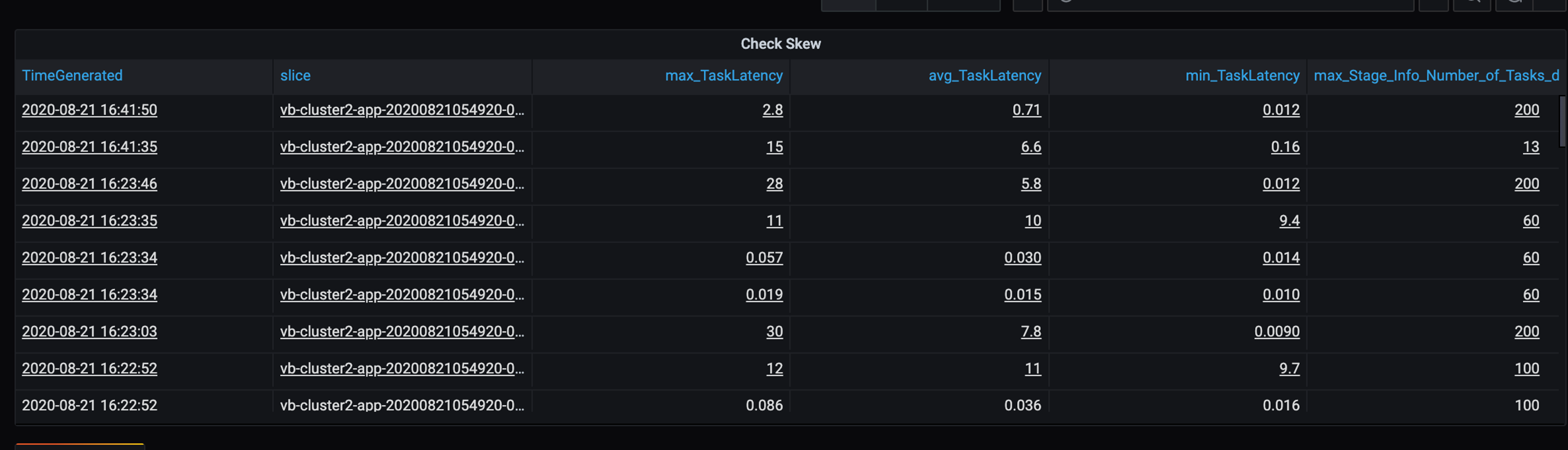
Трассировка ошибок
Добавьте панель мониторинга для трассировки ошибок, чтобы выявлять ошибки обработки данных, связанные с клиентами. При предварительной обработке данных бывают случаи, когда файлы повреждены, а записи в файле не соответствуют схеме данных. На следующей панели мониторинга отображаются многие поврежденные файлы и неправильные записи.
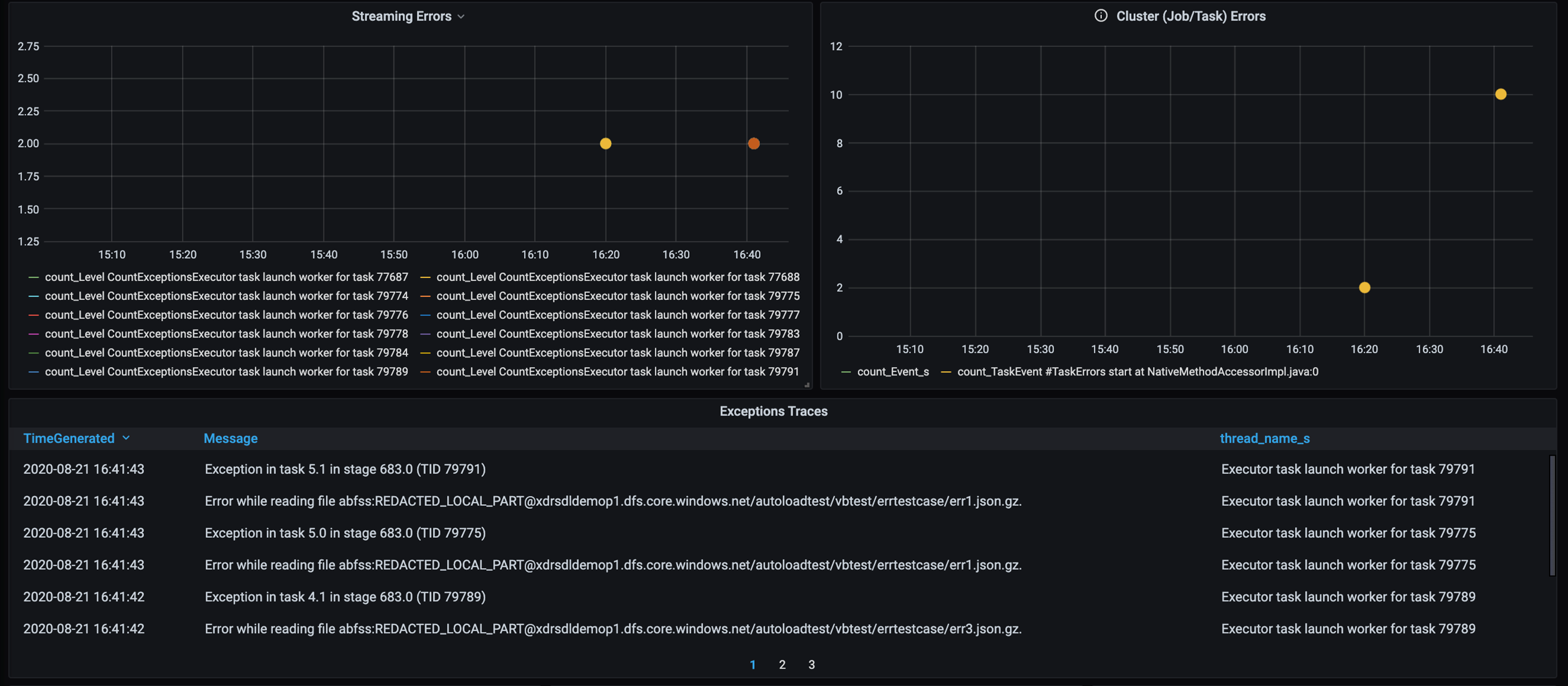
На этой панели мониторинга отображаются количество ошибок, сообщение об ошибке и идентификатор задачи для отладки. С помощью сообщения можно легко найти ошибку в файле ошибок. При чтении возникли ошибки в нескольких файлах. Вы можете просмотреть общую временную шкалу и исследовать конкретные точки на диаграмме (16:20 и 16:40).
Другие узкие места
Дополнительные примеры и рекомендации см. в разделе Устранение узких мест производительности в Azure Databricks.
Сводка по оценке производительности
В этом сценарии с помощью этих метрик удалось обнаружить следующее:
- На диаграмме задержки этапа запись этапов занимает большую часть времени обработки.
- На диаграмме задержки задачи задержка задач является примерно одинаковой.
- На диаграмме пропускной способности потоковой передачи скорость вывода ниже, чем скорость ввода в некоторых точках.
- В таблице длительности задач существует наблюдается широкий разброс для задач из-за несбалансированности данных клиента.
- Чтобы оптимизировать производительность на этапе секционирования, количество исполнителей масштабирования должно соответствовать количеству секций.
- Существуют ошибки трассировки, такие как неправильные файлы и неправильные записи.
Для диагностики этих проблем используются следующие метрики:
- Задержка задания
- Задержка этапа
- Задержка задачи
- Пропускная способность потоковой передачи
- Продолжительность выполнения задачи (максимальная, средняя, минимальная) на этап
- Трассировка ошибок (количество, сообщение, идентификатор задачи)
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участниками.
Автор субъекта:
- Дэвид Макги | Главный диспетчер программ
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.
Следующие шаги
- Ознакомьтесь с руководством по Log Analytics.
- Мониторинг Azure Databricks в рабочей области Azure Log Analytics
- Развертывание Azure Log Analytics с метриками Spark
- Шаблоны наблюдаемости
Связанные ресурсы
- Send Azure Databricks application logs to Azure Monitor (Отправка журналов приложения Azure Databricks в Azure Monitor)
- Use dashboards to visualize Azure Databricks metrics (Визуализация метрик Azure Databricks с помощью панелей мониторинга)
- Рекомендации по мониторингу облачных приложений
- Шаблон повтора