Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
ОБЛАСТЬ ПРИМЕНЕНИЯ: ![]() NoSQL
NoSQL
Внимание
Это не последняя версия пакета SDK для Java для Azure Cosmos DB! Необходимо обновить проект до Azure Cosmos DB с пакетом SDK для Java версии 4, а затем ознакомиться с руководством по повышению производительности Azure Cosmos DB с пакетом SDK для Java версии 4. Следуйте инструкциям в руководстве по переходу на Azure Cosmos DB с пакетом SDK для Java версии 4 и руководстве Reactor или RxJava.
Советы по повышению производительности в этой статье относятся только к Azure Cosmos DB Async Java SDK версии 2. Дополнительные сведения см. в заметках о выпуске для Azure Cosmos DB с пакетом SDK для Async Java версии 2, в репозитории Maven, а также в руководстве по устранению неполадок для Azure Cosmos DB с пакетом SDK для Async Java версии 2.
Внимание
С 31 августа 2024 г. будет прекращена поддержка Azure Cosmos DB с пакетом SDK для Async Java версии 2.x. Пакет SDK и все использующие его приложения продолжат работать, просто Azure Cosmos DB прекратит обслуживание и поддержку этого пакета. Для перехода на Azure Cosmos DB с пакетом SDK для Java версии 4 рекомендуется следовать инструкциям, приведенным выше.
Azure Cosmos DB — быстрая и гибкая распределенная база данных, которая легко масштабируется с гарантированной задержкой и пропускной способностью. Для масштабирования базы данных с помощью Azure Cosmos DB не нужно вносить в архитектуру существенные изменения или писать сложный код. Для увеличения или уменьшения масштаба достаточно вызвать один метод интерфейса API или пакета SDK. Но так как для доступа к Azure Cosmos DB выполняются сетевые вызовы, некоторая оптимизация на стороне клиента поможет повысить производительность при работе с Azure Cosmos DB с пакетом SDK для Async Java версии 2.
Поэтому, если вы хотите повысить производительность базы данных, рассмотрите следующие варианты:
Сеть
Режим подключения: использование прямого подключения
Режим подключения к Azure Cosmos DB серьезно влияет на производительность, в частности на задержку на стороне клиента. Важнейший параметр для настройки политики подключения (ConnectionPolicy) на стороне клиента — это ConnectionMode. Для Azure Cosmos DB с Async Java SDK версии 2 доступны два режима подключения (ConnectionModes):
Режим шлюза поддерживается на всех платформах SDK, поэтому он установлен по умолчанию. Поскольку в режиме шлюза используются стандартный порт HTTPS и одна конечная точка, его рекомендуется использовать для приложений, запущенных в корпоративных сетях со строгими ограничениями брандмауэра. Однако компромисс производительности заключается в том, что режим шлюза включает дополнительный сетевой прыжк каждый раз, когда данные считываются или записываются в Azure Cosmos DB. Поэтому режим прямого подключения обеспечивает более высокую производительность благодаря уменьшению количества сетевых переходов.
Параметр ConnectionMode настраивается с помощью параметра ConnectionPolicy во время создания экземпляра DocumentClient.
Асинхронный Java SDK версии 2 (Maven com.microsoft.azure::azure-cosmosdb)
public ConnectionPolicy getConnectionPolicy() {
ConnectionPolicy policy = new ConnectionPolicy();
policy.setConnectionMode(ConnectionMode.Direct);
policy.setMaxPoolSize(1000);
return policy;
}
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);
Повышение производительности за счет размещения клиентов в одном регионе Azure
Если это возможно, размещайте приложения, выполняющие вызовы к Azure Cosmos DB, в том же регионе, в котором находится база данных Azure Cosmos DB. Для приблизительного сравнения: вызовы к Azure Cosmos DB в пределах региона выполняются в течение 1–2 мс, но задержка между Восточным и Западным побережьем США превышает 50 мс. Значение задержки может отличаться в зависимости от выбранного маршрута при передаче запроса от клиента к границе центра обработки данных Azure. Минимальная возможная задержка достигается при размещении клиентского приложения в том же регионе Azure, в котором предоставляется конечная точка Azure Cosmos DB. Список доступных регионов см. на странице Регионы Azure.
Использование пакета SDK
Установка последней версии пакета SDK
Пакеты SDK для Azure Cosmos DB постоянно улучшаются, чтобы обеспечивать самую высокую производительность. Узнайте о последней версии пакета Azure Cosmos DB Async Java SDK v2 и просмотрите улучшения в заметках о выпуске.
Использование одного и того же клиента Azure Cosmos DB в течение всего жизненного цикла приложения
Каждый экземпляр AsyncDocumentClient является потокобезопасным, а также эффективно управляет подключениями и кэширует адреса. Чтобы реализовать возможность управления подключениями и оптимизировать производительность, рекомендуется использовать один экземпляр AsyncDocumentClient для каждого домена в течение жизненного цикла приложения.
Настройка Политики Подключения
По умолчанию запросы Azure Cosmos DB в режиме direct выполняются по протоколу TCP при использовании пакета SDK Async Java для Azure Cosmos DB версии 2. На внутреннем уровне пакет SDK использует специальную архитектуру режима прямого подключения для динамического управления сетевыми ресурсами и обеспечения наилучшей производительности.
В Azure Cosmos DB с пакетом SDK для Async Java версии 2, для повышения производительности базы данных с большинством рабочих нагрузок лучше всего подходит Direct Mode.
- Общие сведения о режиме прямого подключения

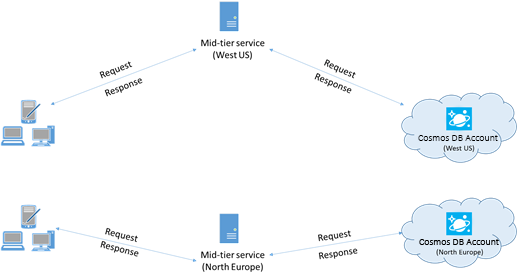
Клиентская архитектура, применяемая в режиме прямого подключения, обеспечивает предсказуемое использование сети и мультиплексированный доступ к репликам Azure Cosmos DB. На схеме выше показано, как прямой режим направляет клиентские запросы на реплики в серверной части Azure Cosmos DB. Архитектура режима прямого подключения выделяет до 10 каналов на стороне клиента на каждую реплику базы данных. Канал представляет собой TCP-соединение, которому предшествует буфер запросов глубиной 30 запросов. Каналы, принадлежащие реплике, динамически распределяются по мере необходимости конечной точкой службы реплики. Когда пользователь выполняет запрос в режиме прямого подключения, TransportClient направляет этот запрос к соответствующей конечной точке службы, опираясь на ключ раздела. Очередь запросов помещает запросы в буфер перед конечной точкой службы.
Параметры конфигурации ConnectionPolicy для режима прямого подключения
Для начала воспользуйтесь рекомендуемыми параметрами конфигурации, приведенными ниже. Обратитесь к команде Azure Cosmos DB, если у вас возникли проблемы с этим конкретным разделом.
Если в качестве эталонной базы данных используется Azure Cosmos DB (то есть база данных используется для многих точечных операций чтения и нескольких операций записи), может оказаться резонным задать для параметра idleEndpointTimeout значение 0 (то есть без времени ожидания).
Параметр конфигурации По умолчанию. размер страницы буфера 8192 connectionTimeout "PT1M" тайм-аут простаивающего канала "PT0S" idleEndpointTimeout "PT1M10S" максимальная производительность буфера 8388608 Максимальное количество каналов на конечную точку 10 Максимальное количество запросов на канал 30 получение времени обнаружения подвисания "PT1M5S" requestExpiryInterval "PT5S" requestTimeout "PT1M" запросить разрешение таймера "PT0.5S" отправитьВремяОбнаруженияПодвисания "PT10S" время ожидания завершения работы "PT15S"
Советы по программированию для режима прямого подключения
Используйте статью Устранение неполадок в Azure Cosmos DB для SDK Async Java версии 2 в качестве основы для решения любых проблем с пакетом SDK.
Некоторые важные советы по программированию при использовании режима прямого подключения
Используйте многопоточность в приложении для эффективной передачи данных по протоколу TCP: после выполнения запроса приложение должно подписываться на получение данных из другого потока. Если этого не делать, это приведет к непроизвольной работе в режиме "полудуплекс", и последующие запросы будут блокироваться в ожидании ответа на предыдущий запрос.
Выполните рабочие нагрузки с большим объемом вычислений в выделенном потоке: по тем же причинам, что и в предыдущем совете, такие операции, как сложная обработка данных, лучше размещать в отдельном потоке. Запрос, который извлекает данные из другого хранилища данных (например, если поток использует одновременно хранилища данных Azure Cosmos DB и Spark), может увеличить задержку, и для него рекомендуется породить дополнительный поток, ожидающий ответа от другого хранилища данных.
- Базовые сетевые операции ввода-вывода в пакете SDK Async Java для Azure Cosmos DB версии 2 управляются Netty. Ознакомьтесь с этими советами по предотвращению шаблонов кодирования, которые блокируют потоки ввода-вывода Netty.
Моделирование данных. Соглашение об уровне обслуживания Azure Cosmos DB предполагает, что размер документа меньше 1 КБ. Оптимизация модели данных и программирования с использованием документов меньшего размера обычно приводит к уменьшению задержки. Если вам потребуется хранение и извлечение документов размером более 1 КБ, рекомендуется, чтобы документы были связаны с данными в Azure Blob Storage.
Настройка параллельных запросов для секционированных коллекций
Azure Cosmos DB с пакетом SDK для Async Java версии 2 поддерживает параллельные запросы, позволяющие обращаться к секционированным коллекциям в параллельном режиме. Дополнительные сведения см. в примерах кода для работы с пакетами SDK. Параллельные запросы предназначены для уменьшения задержки обработки запросов и повышения пропускной способности по сравнению с их последовательными аналогами.
Настройка setMaxDegreeOfParallelism:
Параллельные запросы позволяют одновременно обращаться к нескольким секциям. Однако данные из каждой секционированной коллекции извлекаются в рамках запроса последовательно. С помощью setMaxDegreeOfParallelism установите значение, соответствующее количеству секций, что обеспечит максимальную вероятность высокой производительности запроса при сохранении всех остальных параметров системы. Если вы не знаете количество секций, вы можете использовать setMaxDegreeOfParallelism, чтобы задать высокое значение; система выберет минимальное из двух: количество секций или число, указанное пользователем, в качестве максимальной степени параллелизма.
Следует отметить, что параллельные запросы обеспечивают больше преимуществ, если данные равномерно распределены во всех секциях по отношению к запросу. Если разделённая коллекция сегментирована таким образом, что все или большинство данных, возвращаемых запросом, сосредоточены в нескольких секциях (в худшем случае - в одной), то производительность запроса будет ограничена этими секциями.
Настройка setMaxBufferedItemCount:
Параллельный запрос предназначен для предварительного получения результатов, пока текущий пакет результатов обрабатывается клиентом. Предварительная выборка помогает снизить общую задержку запроса. setMaxBufferedItemCount ограничивает количество предварительно подготовленных результатов. Установка setMaxBufferedItemCount на ожидаемое количество возвращаемых результатов (или более высокое число) позволяет запросу получить максимальное преимущество от предварительной выборки.
Предварительная выборка работает одинаково независимо от MaxDegreeOfParallelism, и существует один буфер для данных из всех разделов.
Реализовать постепенное уменьшение частоты на интервалах getRetryAfterInMilliseconds
Во время тестирования производительности следует увеличивать нагрузку до тех пор, пока небольшое количество запросов не будет ограничено. Если происходит ограничение, клиентское приложение должно подождать, пока не истечет указанный сервером интервал повтора. Это гарантирует, что время ожидания между повторными попытками будет минимальным.
Расширение клиентской нагрузки
При проверке с высокой пропускной способностью (более 50 000 единиц запроса в секунду) клиентское приложение может стать узким местом из-за того, что на компьютере будут достигнуты ограничения по ресурсам ЦП или сети. Если вы достигли этой точки, то можете повысить производительность Azure Cosmos DB, развернув клиентские приложения на нескольких серверах.
Адресация на основе имен
Используйте адресацию на основе имен, когда ссылки имеют формат
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId, вместо самоссылающихся ссылок (_self), которые имеют форматdbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>, чтобы избежать извлечения идентификаторов ресурсов (ResourceIds) всех ресурсов, используемых для создания ссылки. Кроме того, кэширование этих данных не увеличит производительность, так как ресурсы могут создаваться заново (иногда с теми же именами).Настройте размер страницы для запросов и лент чтения для повышения производительности
Если при массовом чтении документов с использованием функции чтения данных (например, readDocuments) или при выполнении SQL-запроса результат оказывается слишком большим, он возвращается частями. По умолчанию результаты возвращаются в пакетах по 100 элементов или 1 МБ, в зависимости от того, что достигнуто первым.
Чтобы уменьшить количество сетевых запросов, необходимых для получения всех применимых результатов, вы можете увеличить размер страницы до 1000, используя заголовок запроса x-ms-max-item-count. Чтобы отобразить только некоторые результаты, например, когда пользовательский интерфейс или приложение API возвращает только десять результатов за раз, размер страницы можно уменьшить до 10. Это позволит снизить пропускную способность, используемую на операции чтения и на выполнение запросов.
Размер страницы также можно изменить с помощью метода setMaxItemCount.
Используйте надлежащий планировщик (избегайте перехвата потоков Event Loop IO Netty)
Пакет SDK Async Java для Azure Cosmos DB версии 2 использует netty для неблокирования операций ввода-вывода. В пакете SDK используется фиксированное число потоков цикла обработки событий ввода-вывода netty (это число соответствует числу ядер ЦП на компьютере) для выполнения операций ввода-вывода. Объект Observable, возвращаемый API, выводит результат в один из общих потоков цикла обработки событий ввода-вывода netty. Поэтому важно не блокировать общие потоки событий ввода-вывода в Netty. Интенсивное использование ЦП или блокировка операции в потоке цикла обработки событий ввода-вывода netty может вызвать взаимоблокировку или значительно уменьшить пропускную способность пакета SDK.
Например, следующий код выполняет интенсивную работу с использованием ЦП в потоке event loop IO Netty.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribe( resourceResponse -> { //this is executed on eventloop IO netty thread. //the eventloop thread is shared and is meant to return back quickly. // // DON'T do this on eventloop IO netty thread. veryCpuIntensiveWork(); });Если необходимо выполнить обработку полученного результата с интенсивной нагрузкой на ЦП, этого нежелательно делать в потоке цикла обработки событий ввода-вывода netty. Вместо этого можно указать собственный планировщик, чтобы предоставить собственный поток для выполнения ваших задач.
Асинхронный Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
import rx.schedulers; Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribeOn(Schedulers.computation()) subscribe( resourceResponse -> { // this is executed on threads provided by Scheduler.computation() // Schedulers.computation() should be used only when: // 1. The work is cpu intensive // 2. You are not doing blocking IO, thread sleep, etc. in this thread against other resources. veryCpuIntensiveWork(); });В зависимости от типа вашей работы следует использовать соответствующий существующий планировщик RxJava для вашей работы. Читать здесь
Schedulers.Для получения дополнительной информации, пожалуйста, обратитесь к странице GitHub для Azure Cosmos DB Async Java SDK версии 2.
Отключить ведение журнала Netty
Логгирование в библиотеке Netty слишком многословное и его необходимо отключить, так как отключения в конфигурации может быть недостаточно, чтобы избежать дополнительных затрат ЦП. Если вы не используете режим отладки, полностью отключите ведение журналов netty. Поэтому, если вы используете log4j для снижения дополнительных затрат процессора, вызванных
org.apache.log4j.Category.callAppenders()из netty, добавьте следующую строку в код:org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);Лимит на ресурсы открытых файлов ОС
Некоторые дистрибутивы Linux (например, RedHat) ограничивают максимальное число открытых файлов и общее число подключений. Чтобы узнать текущие ограничения, выполните следующую команду:
ulimit -aЧисло открытых файлов (nofile) должно быть достаточно большим, чтобы было достаточно места для настроенного размера пула подключений и других открытых файлов в ОС. Его можно изменить, чтобы позволить использовать больший размер пула подключений.
Откройте файл limits.conf:
vim /etc/security/limits.confДобавьте или измените следующие строки:
* - nofile 100000
Политика индексирования
Исключите неиспользуемые пути из индексирования, чтобы ускорить выполнение операций записи
Политика индексирования Azure Cosmos DB позволяет указать пути к документам для включения или исключения из индексирования с помощью путей индексирования (setIncludedPaths и setExcludedPaths). Возможность управления путями индексирования позволяет оптимизировать производительность записи и снизить затраты на хранение индекса для сценариев с заранее определенными шаблонами запросов. Это связано с тем, что затраты на индексирование непосредственно зависят от количества уникальных путей индексирования. Например, в коде ниже показано, как с помощью оператора подстановочного знака "*" исключить из индексации целый раздел документов (поддерево).
Асинхронный пакет SDK версии 2 для Java (Maven com.microsoft.azure::azure-cosmosdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Дополнительные сведения см. в статье Политики индексации Azure Cosmos DB.
Пропускная способность
Измерение и настройка для снижения использования единиц запроса в секунду
Azure Cosmos DB предоставляет обширный набор операций с документами в коллекции базы данных, в том числе реляционные и иерархические запросы с использованием UDF, хранимых процедур и триггеров. Затраты, связанные с каждой из этих операций, зависят от типа процессора, операций ввода-вывода и памяти, необходимой для завершения операции. Вместо того чтобы думать о закупке и управлении аппаратными ресурсами, вы можете думать о единице запроса (RU) как единой меры для ресурсов, необходимых для выполнения различных операций с базами данных и обслуживания запросов приложений.
Пропускная способность выделяется на основе количества единиц запроса, заданного для каждого контейнера. Удельный расход единиц запросов оценивается в расчете на одну секунду. Частота запросов для приложений, у которых она превышает подготовленные единицы запросов для контейнера, будет ограничена, пока она не упадет ниже зарезервированного для контейнера уровня. Если приложению требуется более высокий уровень пропускной способности, можно увеличить ее путем выделения дополнительных единиц запросов.
Сложность запроса влияет на количество единиц запроса, потребляемых операцией. Количество предикатов, природа предикатов, количество определяемых пользователем функций и размер набора исходных данных — все это влияет на стоимость операций запроса.
Чтобы оценить расходы на любую операцию (создание, обновление или удаление), проверьте значение заголовка x-ms-request-charge. Это значение содержит число единиц запроса, потребляемых соответствующей операцией. Также можно проверить аналогичное свойство RequestCharge в ResourceResponse<T> или FeedResponse<T>.
Асинхронный пакет SDK для Async Java версии 2 (Maven com.microsoft.azure::azure-cosmosdb)
ResourceResponse<Document> response = asyncClient.createDocument(collectionLink, documentDefinition, null, false).toBlocking.single(); response.getRequestCharge();Стоимость запроса, указанная в этом заголовке, представляет собой долю от вашей выделенной пропускной способности. Например, если у вас подготовлено 2000 RU/с, а предыдущий запрос возвращает 1000 документов размером 1 КБ, стоимость операции составляет 1000. Таким образом, перед ограничением частоты выполнения последующих запросов сервер за одну секунду выполняет только два таких запроса. Чтобы узнать больше, ознакомьтесь с единицами запроса и калькулятором единиц запроса.
Обработка ограничения скорости / слишком высокая частота запросов
Выполнение запроса, который превышает лимит зарезервированной пропускной способности для учетной записи, не приводит к снижению производительности сервера, так как пользователь не сможет превысить это зарезервированное значение. Сервер заранее завершит запрос с ошибкой RequestRateTooLarge (код состояния HTTP: 429) и вернет в заголовке x-ms-retry-after-ms время (в миллисекундах), которое пользователь должен подождать, прежде чем повторить запрос.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100Все пакеты SDK имплицитно перехватывают этот ответ, уважают заголовок retry-after, указанный сервером, и повторно отправляют запрос. Если к вашей учетной записи параллельно имеет доступ только один клиент, следующая попытка будет успешной.
Если несколько клиентов суммарно выполняют операции выше установленного лимита запросов, то значение повторных попыток по умолчанию, установленное клиентом на уровне 9, может оказаться недостаточным; в этом случае приложение получит DocumentClientException с кодом состояния 429. Число повторных попыток по умолчанию можно переопределить в свойстве RetryOptions экземпляра ConnectionPolicy. По умолчанию исключение DocumentClientException с кодом состояния 429 возвращается после совокупного времени ожидания 30 секунд, если запрос продолжает выполняться выше уровня запросов. Это происходит, даже если текущее значение количества повторных попыток (по умолчанию (9) или определенное пользователем) меньше максимального значения.
Хотя автоматическая процедура повторных попыток помогает повысить устойчивость и удобство использования для большинства приложений, это может вступать в противоречие при проведении тестов производительности, особенно при измерении задержек. Если эксперимент достигнет ограничения сервера и приведет к тому, что клиентский SDK тихо повторит попытку, наблюдаемая клиентом задержка возрастет. Чтобы избежать пиков задержек во время экспериментов над производительностью, измерьте возврат заряда каждой операции и убедитесь, что запросы работают ниже зарезервированной частоты запросов. Дополнительные сведения см. в разделе Единицы запросов.
Использование меньших документов для более высокой пропускной способности
Стоимость запроса (плата за обработку запроса) для каждой операции напрямую зависит от размера документа. Операции с большими документами обходятся дороже, чем с маленькими документами.
Следующие шаги
Дополнительные сведения о создании приложения с высокой масштабируемостью и производительностью см. в статье Partitioning and scaling in Azure Cosmos DB (Секционирование и масштабирование в Azure Cosmos DB).