Советы по повышению производительности для пакета SDK для Java версии 4 в Azure Cosmos DB
ОБЛАСТЬ ПРИМЕНЕНИЯ: ![]() NoSQL
NoSQL
Внимание
Советы по повышению производительности в этой статье предназначены исключительно для пакета SDK для Java версии 4 в Azure Cosmos DB. Дополнительные сведения см. в заметках о выпуске для пакета SDK для Java версии 4 в Azure Cosmos DB, в репозитории Maven, а также в руководстве по устранению неполадок для пакета SDK для Java версии 4 в Azure Cosmos DB. Если сейчас вы используете более раннюю версию, чем версия 4, руководство Перевод приложения на использование пакета средств разработки Java для Azure Cosmos DB версии 4 поможет вам обновить его до версии 4.
Azure Cosmos DB — быстрая и гибкая распределенная база данных, которая легко масштабируется с гарантированной задержкой и пропускной способностью. Для масштабирования базы данных с помощью Azure Cosmos DB не нужно вносить в архитектуру существенные изменения или писать сложный код. Для увеличения или уменьшения масштаба достаточно вызвать один метод интерфейса API или пакета SDK. Но так как для доступа к Azure Cosmos DB выполняются сетевые вызовы, некоторая оптимизация на стороне клиента поможет повысить производительность при работе с пакета SDK для Java версии 4 в Azure Cosmos DB.
Поэтому, если вы хотите повысить производительность базы данных, рассмотрите следующие варианты:
Сеть
Повышение производительности за счет размещения клиентов в одном регионе Azure
Если это возможно, размещайте приложения, выполняющие вызовы к Azure Cosmos DB, в том же регионе, в котором находится база данных Azure Cosmos DB. Для приблизительного сравнения: вызовы к Azure Cosmos DB в пределах региона выполняются в течение 1–2 мс, но задержка между Восточным и Западным побережьем США превышает 50 мс. Значение задержки может отличаться в зависимости от выбранного маршрута при передаче запроса от клиента к границе центра обработки данных Azure. Минимальная возможная задержка достигается при размещении клиентского приложения в том же регионе Azure, в котором предоставляется конечная точка Azure Cosmos DB. Список доступных регионов см. на странице Регионы Azure.
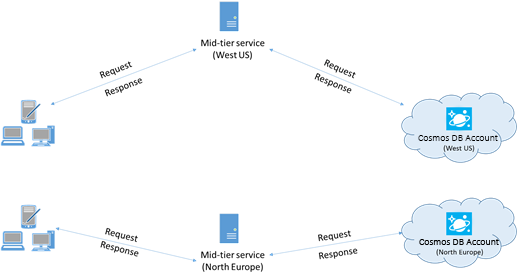
Приложение, взаимодействующее с учетной записью Azure Cosmos DB в нескольких регионах, должно настроить предпочтительные расположения, чтобы запросы направлялись в совмещенный регион.
Включение ускорения сети для уменьшения задержки и jitter ЦП
Настоятельно рекомендуется выполнить инструкции по включению ускорения сети в Windows (выберите инструкции) или Linux (выберите инструкции), чтобы повысить производительность виртуальной машины Azure, уменьшая задержку и jitter ЦП.
Без ускорения сети операции ввода-вывода, передаваемые между виртуальной машиной Azure и другими ресурсами Azure, могут направляться через узел и виртуальный коммутатор, расположенный между виртуальной машиной и ее сетевой картой. Наличие узла и виртуального коммутатора внутри пути данных не только увеличивает задержку и дрожание в коммуникационном канале, но также приводит к краже циклов ЦП у виртуальной машины. Благодаря ускоренной сети виртуальная машина напрямую взаимодействует с сетевым адаптером без посредников. Все сведения о политике сети обрабатываются в оборудовании в сетевом адаптере, обходя узел и виртуальный коммутатор. При включении ускоренной сети, как правило, можно ожидать снижение задержки и увеличение пропускной способности, а также улучшение согласованности задержки и снижение загрузки ЦП.
Ограничения: ускоренная сеть должна поддерживаться в ОС виртуальной машины и может быть включена только при остановке и освобождении виртуальной машины. Виртуальная машина не может быть развернута с помощью Azure Resource Manager. Служба приложений не включает ускоренную сеть.
Дополнительные сведения см. в инструкциях по Windows и Linux .
Высокая доступность
Общие рекомендации по настройке высокой доступности в Azure Cosmos DB см. в статье "Высокий уровень доступности" в Azure Cosmos DB.
Помимо хорошей базовой настройки на платформе базы данных, существуют определенные методы, которые можно реализовать в самом пакете SDK для Java, что может помочь в сценариях сбоя. Две важные стратегии — это стратегия доступности на основе порогового значения и разбиение цепи на уровне секции.
Эти методы предоставляют расширенные механизмы для решения конкретных проблем задержки и доступности, которые по умолчанию выходят за рамки возможностей повторных попыток между регионами, встроенных в пакет SDK. Упреждающее управление потенциальными проблемами на уровне запроса и секционирования позволяет значительно повысить устойчивость и производительность приложения, особенно в условиях высокой нагрузки или снижения уровня нагрузки.
Стратегия доступности на основе порогового значения
Стратегия доступности на основе порогового значения может повысить задержку и доступность хвоста, отправив параллельные запросы на чтение в вторичные регионы и принимая самый быстрый ответ. Такой подход может значительно снизить влияние региональных сбоев или условий высокой задержки на производительность приложения. Кроме того, для повышения производительности можно использовать упреждающее управление подключениями и кэшами как в текущем регионе чтения, так и в предпочтительных удаленных регионах.
Пример конфигурации:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Принцип работы.
Первоначальный запрос: во время T1 запрос на чтение выполняется в основной регион (например, восточная часть США). Пакет SDK ожидает ответа до 500 миллисекунда (
thresholdзначение).Второй запрос: если ответа от основного региона в течение 500 миллисекунд нет, параллельный запрос отправляется в следующий предпочтительный регион (например, восточная часть США 2).
Третий запрос: если ни основной, ни дополнительный регион не отвечает в течение 600 миллисекунда (500 мс + 100 мс,
thresholdStepзначение), пакет SDK отправляет другой параллельный запрос в третий предпочтительный регион (например, западная часть США).Самый быстрый ответ выигрывает: любой регион отвечает первым, этот ответ принимается, а другие параллельные запросы игнорируются.
Упреждающее управление подключениями помогает разогревать подключения и кэши для контейнеров в предпочитаемых регионах, уменьшая задержку холодного запуска для сценариев отработки отказа или записи в настройках с несколькими регионами.
Эта стратегия может значительно повысить задержку в сценариях, когда определенный регион медленно или временно недоступен, но это может привести к увеличению затрат с точки зрения единиц запросов, когда требуются параллельные запросы между регионами.
Примечание.
Если первый предпочтительный регион возвращает код состояния не временных ошибок (например, документ не найден, ошибка авторизации, конфликт и т. д.), сама операция завершится сбоем, так как стратегия доступности не будет иметь никакого преимущества в этом сценарии.
Средство разбиения на уровне секции
Средство разбиения канала на уровне секций повышает задержку хвоста и доступность записи путем отслеживания и коротких запросов на неработоспособные физические секции. Это повышает производительность, избегая известных проблемных секций и перенаправления запросов в более здоровые регионы.
Пример конфигурации:
Чтобы включить разбиение цепи на уровне секции, выполните следующие действия.
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
Чтобы задать частоту фонового процесса для проверки недоступных регионов:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
Чтобы задать длительность, для которой секция может оставаться недоступной:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Принцип работы.
Отслеживание сбоев. Пакет SDK отслеживает сбои терминалов (например, 503s, 500s, время ожидания) для отдельных секций в определенных регионах.
Маркировка как недоступной: если секция в регионе превышает настроенное пороговое значение сбоев, оно помечается как "Недоступно". Последующие запросы к этой секции перенаправляются и перенаправляются в другие более здоровые регионы.
Автоматическое восстановление: фоновый поток периодически проверяет недоступные секции. После определенной длительности эти секции предварительно помечены как "HealthyTentative" и подвергаются тестируемым запросам на проверку восстановления.
Повышение работоспособности или понижение работоспособности: на основе успешного или неудачного выполнения этих тестовых запросов состояние секции либо повышено до "Работоспособно" или понижено до "Недоступно".
Этот механизм помогает непрерывно отслеживать работоспособность секций и гарантирует, что запросы обслуживаются с минимальной задержкой и максимальной доступностью, не удаляясь проблемным секциям.
Примечание.
Средство разбиения цепи применяется только к учетным записям записи с несколькими регионами, так как при помечении секции как Unavailableоперации чтения, так и записи перемещаются в следующий предпочтительный регион. Это позволяет предотвратить чтение и запись из разных регионов, обслуживаемых из одного экземпляра клиента, так как это будет анти-шаблон.
Внимание
Для активации разбиения цепи на уровне секций необходимо использовать пакет SDK java версии 4.63.0 или более поздней.
Сравнение оптимизаций доступности
Стратегия доступности на основе порогов:
- Преимущество. Сокращение задержки хвоста путем отправки параллельных запросов на чтение в вторичные регионы и повышения доступности путем предварительной очистки запросов, которые приводят к истечении времени ожидания сети.
- Компромисс. В связи с дополнительными запросами между регионами (хотя и в периоды, когда пороговые значения нарушаются) взимается дополнительная плата за единицу запросов в секунду.
- Вариант использования. Оптимальный вариант для рабочих нагрузок с высокой нагрузкой на чтение, где снижается задержка, а также некоторые дополнительные затраты (как с точки зрения платы за единицу ЕЗ, так и нагрузку на ЦП клиента) приемлемы. Операции записи также могут воспользоваться преимуществами, если вы решили использовать политику повторных попыток без idempotent и учетную запись с несколькими регионами.
Разбиение цепи на уровне секции:
- Преимущество. Повышение доступности и задержки путем предотвращения неработоспособных секций, обеспечивая маршрутизацию запросов в более здоровые регионы.
- Компромисс. Не несет дополнительных затрат на ЕЗ, но может по-прежнему разрешить некоторую начальную потерю доступности для запросов, которые будут приводить к истечении времени ожидания сети.
- Вариант использования. Идеально подходит для рабочих нагрузок с высокой нагрузкой на запись или смешанных рабочих нагрузок, где согласованная производительность важна, особенно при работе с секциями, которые могут периодически стать неработоспособными.
Обе стратегии можно использовать вместе для повышения доступности чтения и записи и уменьшения задержки хвоста. Средство разбиения цепи на уровне секций может обрабатывать различные временные сценарии сбоя, включая те, которые могут привести к замедлению выполнения реплик без необходимости выполнять параллельные запросы. Кроме того, добавление стратегии доступности на основе пороговых значений приведет к уменьшению задержки хвоста и устранению потери доступности, если дополнительная стоимость ЕЗ допустима.
Реализуя эти стратегии, разработчики могут обеспечить устойчивость приложений, обеспечить высокую производительность и повысить производительность даже во время региональных сбоев или условий высокой задержки.
Согласованность сеансов с областью действия
Обзор
Дополнительные сведения о параметрах согласованности в целом см. в разделе "Уровни согласованности" в Azure Cosmos DB. Пакет SDK java обеспечивает оптимизацию согласованности сеансов для учетных записей записи в нескольких регионах, позволяя ей быть областью действия региона. Это повышает производительность путем снижения задержки межрегиональная репликация путем минимизации повторных попыток на стороне клиента. Это достигается путем управления маркерами сеансов на уровне региона, а не глобально. Если согласованность в приложении может быть ограничена меньшим количеством регионов, реализуя согласованность сеансов в пределах региона, можно добиться повышения производительности и надежности операций чтения и записи в учетных записях с несколькими записями, сведя к минимуму задержки межрегиональная репликация и повторные попытки.
Льготы
- Снижение задержки. Путем локализации проверки маркера сеанса на уровне региона вероятность дорогостоящих повторных попыток между регионами снижается.
- Улучшенная производительность. Свести к минимуму влияние региональной отработки отказа и задержки репликации, обеспечивая более высокую согласованность чтения и записи и более низкую загрузку ЦП.
- Оптимизированное использование ресурсов. Сокращение нагрузки на ЦП и сеть в клиентских приложениях путем ограничения необходимости повторных попыток и межрегионарных вызовов, что позволяет оптимизировать использование ресурсов.
- Высокий уровень доступности. Сохраняя маркеры сеансов в пределах региона, приложения могут работать гладко, даже если некоторые регионы испытывают более высокую задержку или временные сбои.
- Гарантии согласованности. Гарантирует, что гарантии согласованности сеансов (чтение, монотонное чтение) выполняются более надежно без ненужных повторных попыток.
- Эффективность затрат: уменьшает количество межрегионарных вызовов, тем самым снижая затраты, связанные с передачей данных между регионами.
- Масштабируемость. Позволяет приложениям эффективнее масштабироваться, уменьшая количество конфликтов и затрат, связанных с сохранением глобального маркера сеанса, особенно в настройках нескольких регионов.
Компромиссы
- Увеличение использования памяти. Фильтр блум и хранилище маркеров сеанса для конкретного региона требует дополнительного объема памяти, что может быть соображением для приложений с ограниченными ресурсами.
- Сложность конфигурации. Настройка ожидаемого количества вставок и ложноположительного коэффициента для фильтра блума добавляет слой сложности в процесс настройки.
- Потенциал ложных срабатываний: хотя фильтр блум сводит к минимуму перекрестные повторные попытки, существует по-прежнему небольшая вероятность ложных срабатываний, влияющих на проверку маркера сеанса, хотя скорость может быть контролироваться. Ложное срабатывание означает, что глобальный маркер сеанса разрешается, тем самым увеличивая вероятность повторных попыток между регионами, если локальный регион не попал в этот глобальный сеанс. Гарантии сеанса выполняются даже в присутствии ложных срабатываний.
- Применимость. Эта функция наиболее полезна для приложений с высоким кратностью логических секций и регулярными перезапусками. Приложения с меньшим количеством логических секций или редкими перезапусками могут не видеть существенных преимуществ.
Принцип работы
Установка маркера сеанса
- Завершение запроса. После завершения запроса пакет SDK записывает маркер сеанса и связывает его с регионом и ключом секции.
- Хранилище уровня региона: маркеры сеансов хранятся в вложенном
ConcurrentHashMapхранилище, которое поддерживает сопоставления между диапазонами ключей секции и прогрессом на уровне региона. - Фильтр блума: фильтр блум отслеживает, к каким регионам был доступ каждый логический раздел, помогая локализовать проверку маркера сеанса.
Разрешение маркера сеанса
- Инициализация запроса. Перед отправкой запроса пакет SDK пытается разрешить маркер сеанса для соответствующего региона.
- Проверка маркера. Маркер проверяется на соответствие данным, зависящим от региона, чтобы убедиться, что запрос направляется в самую актуальную реплику.
- Логика повтора. Если маркер сеанса не проверяется в текущем регионе, пакет SDK повторяется с другими регионами, но с учетом локализованного хранилища это менее часто.
Использование пакета SDK
Ниже показано, как инициализировать CosmosClient с помощью согласованности сеансов в области региона:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Включение согласованности сеансов с областью действия региона
Чтобы включить запись сеанса в области региона в приложении, задайте следующее системное свойство:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Настройка фильтра блума
Точно настройте производительность, настроив ожидаемые вставки и ложноположительный показатель для фильтра цветения:
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Последствия для памяти
Ниже приведен сохраненный размер (размер объекта и независимо от того, от чего он зависит) внутреннего контейнера сеанса (управляемого пакетом SDK) с различными ожидаемыми вставками в фильтр блума.
| Ожидаемые вставки | Показатель ложных положительных результатов | Сохраненный размер |
|---|---|---|
| 10, 000 | 0,001 | 21 КБ |
| 100, 000 | 0,001 | 183 КБ |
| 1 млн | 0,001 | 1,8 МБ |
| 10 млн | 0,001 | 17,9 МБ |
| 100 млн | 0,001 | 179 МБ |
| 1 миллиард | 0,001 | 1,8 ГБ |
Внимание
Необходимо использовать версию 4.60.0 пакета SDK для Java или более позднюю, чтобы активировать согласованность сеансов в пределах региона.
Настройка конфигурации прямого подключения и подключения шлюза
Сведения о оптимизации конфигураций подключения в режиме прямого и шлюза см. в статье о настройке конфигураций подключений для пакета SDK java версии 4.
Использование пакета SDK
- Установка последней версии пакета SDK
Пакеты SDK для Azure Cosmos DB постоянно улучшаются, чтобы обеспечивать самую высокую производительность. Чтобы определить последние улучшения пакета SDK, посетите пакет SDK Для Azure Cosmos DB.
Каждый экземпляр клиента Azure Cosmos DB является потокобезопасным, а также эффективно управляет подключениями и кэширует адреса. Чтобы обеспечить эффективное управление подключениями и повысить производительность клиента Azure Cosmos DB, настоятельно рекомендуется использовать один экземпляр клиента Azure Cosmos DB в течение всего времени существования приложения.
При создании CosmosClient используется согласованность по умолчанию, если явно не задано значение Сеанс. Если в логике приложения не требуется согласованность типа Сеанс, задайте для параметра Согласованность значение Случайная. Примечание. Рекомендуется использовать по крайней мере согласованность сеансов в приложениях, использующих обработчик канала изменений Azure Cosmos DB.
- Использование асинхронного API для обеспечения максимальной подготовленной пропускной способности
Пакет SDK для Java версии 4 в Azure Cosmos DB содержит два API — синхронный и асинхронный. Не вдаваясь в подробности, асинхронный API реализует функциональность пакета SDK, тогда как синхронный API представляет собой тонкую оболочку, осуществляющую блокирование вызовов к асинхронному API. Это отличается от более старой версии пакета SDK Async Java для Azure Cosmos DB версии 2, который был только асинхронным, и более старым пакетом SDK для Java для синхронизации Azure Cosmos DB версии 2, который был только синхронизацией и имел отдельную реализацию.
Выбор API определяется во время инициализации клиента: CosmosAsyncClient поддерживает асинхронный API, а CosmosClient — синхронный.
Асинхронный API реализует неблокирование операций ввода-вывода и является оптимальным выбором, если ваша цель заключается в максимальной пропускной способности при выдаче запросов в Azure Cosmos DB.
Использование API синхронизации может быть правильным выбором, если вам нужно или требуется API, который блокирует ответ на каждый запрос или если синхронная операция является доминирующей парадигмой в приложении. Например, синхронный API может потребоваться при сохранении данных в Azure Cosmos DB в приложении микрослужб при условии, что пропускная способность не является критически важной.
Обратите внимание, что пропускная способность API синхронизации снижается с увеличением времени отклика на запрос, в то время как API Async может насыщать возможности полной пропускной способности оборудования.
Совместное размещение по географическому признаку может обеспечить более высокую и согласованную пропускную способность при использовании синхронного API (см. раздел Повышение производительности за счет размещения клиентов в одном регионе Azure), однако это по-прежнему не позволит превзойти пропускную способность для асинхронного API.
Некоторые пользователи также могут быть незнакомы с Project Reactor, платформой Reactive Streams, используемой для реализации пакета SDK Java для Azure Cosmos DB версии 4 Асинхронного API. Если это так, мы рекомендуем вам ознакомиться с нашим вводным руководством по шаблонам Reactor, а затем ознакомиться с этим введением в реактивное программирование. Если вы уже использовали Azure Cosmos DB с интерфейсом Async, а используемый пакет SDK был Azure Cosmos DB Async Java SDK версии 2, возможно, вы знакомы с ReactiveX/RxJava, но не уверены, что изменилось в Project Reactor. В этом случае ознакомьтесь с нашим реактором и RxJava Guide , чтобы ознакомиться.
В следующих фрагментах кода показано, как инициализировать клиент Azure Cosmos DB для операции с асинхронным API или синхронным API соответственно.
Асинхронный API пакета SDK для Java версии 4 (Maven com.azure::azure-cosmos)
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Горизонтальное увеличение масштаба рабочей нагрузки клиента
Если вы тестируете на высоком уровне пропускной способности, клиентское приложение может стать узким местом из-за ограничения компьютера при использовании ЦП или сети. Если вы достигли этой точки, то можете повысить производительность Azure Cosmos DB, развернув клиентские приложения на нескольких серверах.
Общее правило заключается в том, чтобы не превышать загрузку ЦП >50% на любом конкретном сервере для снижения задержки.
- Использование надлежащего планировщика (избегайте перехвата потоков цикла обработки событий ввода-вывода netty)
Асинхронные функции пакета SDK для Java в Azure Cosmos DB основаны на неблокирующих операциях ввода-вывода netty. В пакете SDK используется фиксированное число потоков цикла обработки событий ввода-вывода netty (это число соответствует числу ядер ЦП на компьютере) для выполнения операций ввода-вывода. Объект Flux, возвращаемый API, выводит результат в один из общих потоков цикла обработки событий ввода-вывода netty. Поэтому важно не блокировать общие потоки цикла обработки событий ввода-вывода netty. Выполнение интенсивной работы ЦП или блокировка операций в потоке netty цикла событий ввода-вывода может привести к взаимоблокировке или значительно снижению пропускной способности пакета SDK.
Например, следующий код выполняет рабочую нагрузку с интенсивной нагрузкой на ЦП в потоке цикла обработки событий ввода-вывода netty:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
После получения результата следует избежать интенсивной работы ЦП в результате в потоке ввода-вывода в цикле событий. Вместо этого можно указать собственный планировщик, чтобы выполнить рабочую нагрузку, используя собственный поток, как показано ниже (для этого требуется import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
В зависимости от типа работы следует использовать соответствующий существующий планировщик реактора для работы. Дополнительные сведения см. здесь: Schedulers.
Дополнительные сведения о модели потоков и планирования проекта Reactor см. в этой записи блога Project Reactor.
Дополнительные сведения о пакете SDK Java для Azure Cosmos DB версии 4 см. в каталоге Azure Cosmos DB пакета SDK azure для Java monorepo на сайте GitHub.
- Оптимизация параметров ведения журнала в приложении
По разным причинам необходимо добавить ведение журнала в поток, который создает высокую пропускную способность запросов. Если ваша цель в полном насыщении подготовленной пропускной способности контейнера запросами, создаваемыми этим потоком, оптимизация ведения журнала может значительно повысить производительность.
- Настройка асинхронного средства ведения журнала
Задержка синхронного средства ведения журнала обязательно учитывается в общем значении задержки для потока, создающего запросы. Асинхронное средство ведения журнала, такое как log4j2, рекомендуется использовать, чтобы отделить служебные данные ведения журнала от потоков приложений с высокой производительностью.
- Отключение ведения журнала Netty
Ведение журнала библиотеки Netty является чатом и необходимо отключить (отключение входа в конфигурацию может быть недостаточно), чтобы избежать дополнительных затрат на ЦП. Если вы не используете режим отладки, полностью отключите ведение журналов netty. Поэтому если вы используете Log4j для удаления дополнительных затрат на ЦП, вызванных org.apache.log4j.Category.callAppenders() netty, добавьте следующую строку в базу кода:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Лимит на ресурсы открытых файлов ОС
Некоторые дистрибутивы Linux (например, RedHat) ограничивают максимальное число открытых файлов и общее число подключений. Чтобы узнать текущие ограничения, выполните следующую команду:
ulimit -a
Количество открытых файлов (nofile) должно быть достаточно большим, чтобы иметь достаточно места для настроенного размера пула подключений и других открытых файлов ОС. Это число можно изменить для включения поддержки пула подключений большего размера.
Откройте файл limits.conf:
vim /etc/security/limits.conf
Добавьте или измените следующие строки:
* - nofile 100000
- Указание ключа секции в операциях точечной записи
Чтобы повысить производительность операций точечной записи, укажите ключ секции элемента в вызове API точечной записи, как показано ниже:
Асинхронный API пакета SDK для Java версии 4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
Вместо предоставления только экземпляра элемента, как показано ниже:
Асинхронный API пакета SDK для Java версии 4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item).block();
Последний вариант поддерживается, но добавляет задержку в приложение; пакет SDK должен проанализировать элемент и извлечь ключ секции.
Операции запросов
Сведения об операциях запросов см. в советах по производительности запросов.
Политика индексации
- Исключите неиспользуемые пути из индексирования, чтобы ускорить выполнение операций записи
Политика индексирования Azure Cosmos DB позволяет указать пути к документам для включения или исключения из индексирования с помощью путей индексирования (setIncludedPaths и setExcludedPaths). Возможность управления путями индексирования позволяет оптимизировать производительность записи и снизить затраты на хранение индекса для сценариев с заранее определенными шаблонами запросов. Это связано с тем, что затраты на индексирование непосредственно зависят от количества уникальных путей индексирования. Например, в коде ниже показано, как с помощью оператора подстановочного знака "*" включить в индексацию и исключить из нее целый раздел документов (поддерево).
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Дополнительные сведения см. в статье Политики индексации Azure Cosmos DB.
Пропускная способность
- Измерение и настройка расхода единиц запроса/повторного использования
Azure Cosmos DB предоставляет обширный набор операций с документами в коллекции базы данных, в том числе реляционные и иерархические запросы с использованием UDF, хранимых процедур и триггеров. Затраты, связанные с каждой из этих операций, зависят от типа процессора, операций ввода-вывода и памяти, необходимой для завершения операции. Вместо того чтобы думать о закупке и управлении аппаратными ресурсами, вы можете думать о единице запроса (RU) как единой меры для ресурсов, необходимых для выполнения различных операций с базами данных и обслуживания запросов приложений.
Пропускная способность выделяется на основе количества единиц запроса, заданного для каждого контейнера. Удельный расход единиц запросов оценивается в расчете на одну секунду. Частота запросов для приложений, у которых она превышает подготовленные единицы запросов для контейнера, будет ограничена, пока она не упадет ниже зарезервированного для контейнера уровня. Если приложению требуется более высокий уровень пропускной способности, можно увеличить ее путем выделения дополнительных единиц запросов.
Сложность запроса влияет на количество единиц запроса, потребляемых операцией. Количество предикатов и их характер, количество определяемых пользователем функций и размер набора исходных данных — все это влияет на плату за операции запроса.
Чтобы оценить расходы на любую операцию (создание, обновление или удаление), проверьте значение заголовка x-ms-request-charge. Это значение содержит число единиц запроса, потребляемых соответствующей операцией. Также можно проверить аналогичное свойство RequestCharge в ResourceResponse<T> или FeedResponse<T>.
Асинхронный API пакета SDK для Java версии 4 (Maven com.azure::azure-cosmos)
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
Стоимость запроса, указанная в этом заголовке, учитывается как часть подготовленной пропускной способности. Например, если у вас подготовлено 2000 ЕЗ/с, а если предыдущий запрос возвращает 1000 1 КБ документов, стоимость операции составляет 1000. Таким образом, перед ограничением частоты выполнения последующих запросов сервер за одну секунду выполняет только два таких запроса. Чтобы узнать больше, ознакомьтесь с единицами запроса и калькулятором единиц запроса.
- Обработка ограничения скорости / слишком высокая частота запросов
Выполнение запроса, который превышает лимит зарезервированной пропускной способности для учетной записи, не приводит к снижению производительности сервера, так как пользователь не сможет превысить это зарезервированное значение. Сервер заранее завершит запрос с ошибкой RequestRateTooLarge (код состояния HTTP: 429) и вернет в заголовке x-x-ms-retry-after-ms время (в миллисекундах), спустя которое можно повторно выполнить этот запрос.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Пакеты SDK перехватят этот ответ, обработают заголовок retry-after, указанный сервером, и отправят запрос повторно. Если к вашей учетной записи параллельно имеет доступ только один клиент, следующая попытка будет успешной.
Если у вас есть более одного клиента, согласованно работающего над скоростью запроса, количество повторных попыток по умолчанию, установленное в настоящее время на уровне 9 внутри клиента, может не быть достаточно; В этом случае клиент вызывает CosmosClientException с кодом состояния 429 для приложения. Число повторных попыток по умолчанию можно изменить с помощью setMaxRetryAttemptsOnThrottledRequests() экземпляра ThrottlingRetryOptions . По умолчанию в случае превышения заданного счетчика повторов исключение CosmosClientException с кодом состояния 429 возвращается через 30 секунд (совокупное время ожидания). Это происходит, даже если текущее значение количества повторных попыток (по умолчанию (9) или определенное пользователем) меньше максимального значения.
Хотя автоматическая процедура отправки повторного запроса позволяет улучшить устойчивость приложений и повысить удобство работы с ними, она может снизить производительность, что, в свою очередь, станет причиной появления более длительных задержек. Если настройка производительности повлияла на регулирование сервера и стала причиной автоматической отправки запросов пакетом SDK, это может стать причиной появления пиков задержек на стороне клиента. Чтобы избежать пиков задержек во время настройки производительности, проверьте расход ресурсов на каждую операцию и убедитесь, что значение частоты запросов не превышено. Дополнительные сведения см. в статье Единицы запросов в DocumentDB.
- Использование меньших документов для более высокой пропускной способности
Стоимость запроса (плата за обработку запроса) для каждой операции напрямую зависит от размера документа. За операции с большими документами взимается больше единиц запроса, чем за операции с мелкими документами. В идеале вы можете разработать приложение и рабочие процессы, чтобы размер элемента составил ~1 КБ или аналогичный порядок или величину. Для больших элементов приложений с учетом задержки следует избегать. Документы с несколькими МБ замедляют работу приложения.
Следующие шаги
Дополнительные сведения о создании приложения с высокой масштабируемостью и производительностью см. в статье Partitioning and scaling in Azure Cosmos DB (Секционирование и масштабирование в Azure Cosmos DB).
Если вы планируете ресурсы для миграции в Azure Cosmos DB, Для планирования ресурсов можно использовать сведения об имеющемся кластере базы данных.
- Если вам известно только количество виртуальных ядер и серверов в существующем кластере баз данных, см. сведения об оценке единиц запросов на основе виртуальных ядер и серверов.
- Если вам известна стандартная частота запросов для текущей рабочей нагрузки базы данных, ознакомьтесь со статьей о расчете единиц запросов с помощью планировщика ресурсов Azure Cosmos DB