Советы по повышению производительности для Azure Cosmos DB с пакетом SDK для Sync Java версии 2
ОБЛАСТЬ ПРИМЕНЕНИЯ: ![]() NoSQL
NoSQL
Внимание
Это не последняя версия пакета SDK для Java для Azure Cosmos DB! Необходимо обновить проект до Azure Cosmos DB с пакетом SDK для Java версии 4, а затем ознакомиться с руководством по повышению производительности Azure Cosmos DB с пакетом SDK для Java версии 4. Следуйте инструкциям в руководстве по переходу на Azure Cosmos DB с пакетом SDK для Java версии 4 и руководстве Reactor и RxJava.
Эти советы по повышению производительности предназначены только для Azure Cosmos DB с пакетом SDK для Sync Java версии 2. Дополнительные сведения см. в репозитории Maven.
Внимание
С 29 февраля 2024 г. будет прекращена поддержка Azure Cosmos DB с пакетом SDK для Sync Java версии 2.x. Пакет SDK и все использующие его приложения продолжат работать, просто Azure Cosmos DB прекратит обслуживание и поддержку этого пакета. Для перехода на Azure Cosmos DB с пакетом SDK для Java версии 4 рекомендуется следовать инструкциям, приведенным выше.
Azure Cosmos DB — быстрая и гибкая распределенная база данных, которая легко масштабируется с гарантированной задержкой и пропускной способностью. Для масштабирования базы данных с помощью Azure Cosmos DB не нужно вносить в архитектуру существенные изменения или писать сложный код. Для увеличения или уменьшения масштаба достаточно выполнить один вызов API. Дополнительные сведения см. в разделах о подготовке пропускной способности контейнера и о подготовке пропускной способности базы данных. Но так как для доступа к Azure Cosmos DB выполняются сетевые вызовы, то некоторая оптимизация на стороне клиента поможет повысить производительность при работе с Azure Cosmos DB с пакетом SDK для Sync Java версии 2.
Поэтому, если вы хотите повысить производительность базы данных, рассмотрите следующие варианты:
Сеть
Режим подключения: использование DirectHttps
Режим подключения к Azure Cosmos DB серьезно влияет на производительность, в частности на задержку на стороне клиента. Важнейший параметр для настройки политики подключения (ConnectionPolicy) на стороне клиента — это ConnectionMode. Этот параметр может принимать одно из двух значений:
Gateway ("Шлюз", используется по умолчанию);
DirectHttps ("Прямое подключение через HTTPS").
Режим шлюза поддерживается на всех платформах SDK, поэтому он установлен по умолчанию. Так как в режиме шлюза используется стандартный порт HTTPS и одна конечная точка, он будет правильным выбором для приложений, запущенных в корпоративных сетях со строгими ограничениями брандмауэра. Но режим шлюза не обеспечивает максимальную производительность, поскольку задействует дополнительный сетевой узел при каждой операции чтения или записи данных в Azure Cosmos DB. Режим прямого подключения позволит повысить производительность.
Azure Cosmos DB с пакетом SDK для Sync Java версии 2 использует HTTPS в качестве транспортного протокола. HTTPS использует TLS для первоначальной аутентификации и шифрования трафика. При работе с Azure Cosmos DB с пакетом SDK для Sync Java версии 2 нужно открыть только стандартный порт HTTPS 443.
Параметр ConnectionMode настраивается с помощью параметра ConnectionPolicy во время создания экземпляра DocumentClient.
Пакет SDK синхронизации для Java версии 2 (Maven com.microsoft.azure::azure-documentdb)
public ConnectionPolicy getConnectionPolicy() { ConnectionPolicy policy = new ConnectionPolicy(); policy.setConnectionMode(ConnectionMode.DirectHttps); policy.setMaxPoolSize(1000); return policy; } ConnectionPolicy connectionPolicy = new ConnectionPolicy(); DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);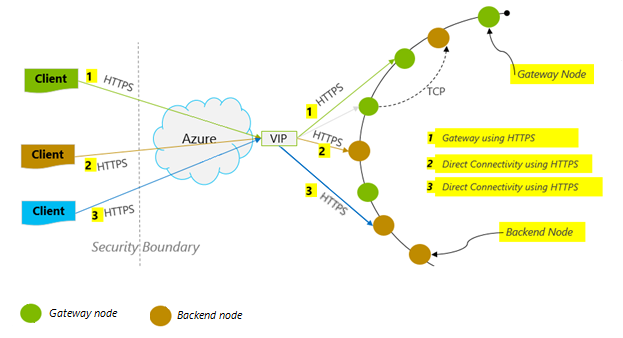
Повышение производительности за счет размещения клиентов в одном регионе Azure
Если это возможно, размещайте приложения, выполняющие вызовы к Azure Cosmos DB, в том же регионе, в котором находится база данных Azure Cosmos DB. Для приблизительного сравнения: вызовы к Azure Cosmos DB в пределах региона выполняются в течение 1–2 мс, но задержка между Восточным и Западным побережьем США превышает 50 мс. Значение задержки может отличаться в зависимости от выбранного маршрута при передаче запроса от клиента к границе центра обработки данных Azure. Минимальная возможная задержка достигается при размещении клиентского приложения в том же регионе Azure, в котором предоставляется конечная точка Azure Cosmos DB. Список доступных регионов см. на странице Регионы Azure.
Использование пакета SDK
Установка последней версии пакета SDK
Пакеты SDK для Azure Cosmos DB постоянно улучшаются, чтобы обеспечивать самую высокую производительность. Чтобы определить последние улучшения пакета SDK, посетите пакет SDK Для Azure Cosmos DB.
Использование одного и того же клиента Azure Cosmos DB в течение всего жизненного цикла приложения
Каждый экземпляр DocumentClient в режиме прямого подключения является потокобезопасным, эффективно управляет подключениями и кэширует адреса. Чтобы реализовать возможность управления подключениями и оптимизировать производительность, рекомендуется использовать один экземпляр DocumentClient для каждого домена в течение жизненного цикла приложения.
При использовании режима шлюза увеличьте размер пула (MaxPoolSize) для каждого узла.
В режиме шлюза Azure Cosmos DB выполняет запросы через HTTPS или REST, а значит на них распространяется стандартное ограничение на количество подключений к одному имени узла или IP-адресу. Возможно, стоит увеличить это значение (до 200–1000), чтобы клиентская библиотека могла использовать несколько одновременных подключений к Azure Cosmos DB. В Azure Cosmos DB с пакетом SDK для Sync Java версии 2 для параметра ConnectionPolicy.getMaxPoolSize по умолчанию установлено значение 100. Используйте setMaxPoolSize, чтобы изменить это значение.
Настройка параллельных запросов для секционированных коллекций
В Azure Cosmos DB с пакетом SDK для Sync Java версии 1.9.0 и выше поддерживаются параллельные запросы, позволяющие обращаться к секционированным коллекциям в параллельном режиме. Дополнительные сведения см. в примерах кода для работы с пакетами SDK. Параллельные запросы предназначены для сокращения задержки при обработке запросов и улучшения пропускной способности посредством их последовательных аналогов.
(а) Применение setMaxDegreeOfParallelism. Параллельный режим запросов позволяет одновременно обращаться к нескольким секциям. Однако данные из каждой секционированной коллекции извлекаются в рамках запроса последовательно. С помощью setMaxDegreeOfParallelism установите значение, соответствующее количеству секций, что обеспечит максимальную вероятность высокой производительности запроса при сохранении всех остальных параметров системы. Если вы не знаете количество секций, просто используйте высокое значение для setMaxDegreeOfParallelism. Система автоматически выберет минимальное из двух значений: количество секций или число, указанное пользователем.
Следует отметить, что параллельные запросы обеспечивают больше преимуществ, если данные равномерно распределены во всех секциях по отношению к запросу. Если секционированная коллекция секционирована таким образом, что все или большинство данных, возвращаемых запросом, сосредоточены в нескольких секциях (один раздел в худшем случае), то производительность запроса будет узким местом в этих разделах.
(b) Настройка setMaxBufferedItemCount: параллельный запрос предназначен для предварительного получения результатов, пока текущий пакет результатов обрабатывается клиентом. Предварительная выборка помогает повысить общую задержку запроса. setMaxBufferedItemCount ограничивает количество предварительно подготовленных результатов. Задав параметр setMaxBufferedItemCount ожидаемому количеству возвращаемых результатов (или более высокому числу), это позволяет запросу получить максимальное преимущество от предварительной выборки.
Предварительная выборка работает одинаково независимо от maxDegreeOfParallelism, и существует один буфер для данных из всех секций.
Применение интервала задержки getRetryAfterInMilliseconds.
Во время проверки производительности следует увеличивать нагрузку до тех пор, пока регулирование не будет выполняться при небольшой частоте запросов. При регулировании клиентское приложение должно реализовать интервал частоты повтора для частоты повтора сервера. Это гарантирует, что время ожидания между повторными попытками будет минимальным. Политика повторов реализована в версии 1.8.0 и более поздних версиях Azure Cosmos DB с пакетом SDK для Sync Java. Дополнительные сведения см. в статье о методе getRetryAfterInMilliseconds.
Горизонтальное увеличение масштаба рабочей нагрузки клиента
При проверке с высокой пропускной способностью (более 50 000 единиц запроса в секунду) клиентское приложение может стать узким местом из-за того, что на компьютере будут достигнуты ограничения по ресурсам ЦП или сети. Если вы достигли этой точки, то можете повысить производительность Azure Cosmos DB, развернув клиентские приложения на нескольких серверах.
Адресация на основе имен
Используйте адресацию на основе имен, то есть ссылки в формате
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentIdвместо самоссылающегося форматаdbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>. Это позволит избежать получения идентификаторов для всех ресурсов, требуемых для создания ссылки. Кэширование этих данных не увеличит производительность, поскольку ресурсы могут создаваться заново (иногда с теми же именами).Оптимизация производительности посредством настройки размера страницы для запросов и каналов чтения
Если при массовом чтении документов с помощью функции чтения канала (например readDocuments) или обработке запроса SQL будет получен слишком большой набор результатов, такие результаты возвращаются частями. По умолчанию результаты возвращаются в пакетах (не более 100 элементов и не более 1 МБ в каждом пакете).
Чтобы снизить количество сетевых взаимодействий, необходимых для получения всех нужных результатов, попробуйте увеличить размер страницы до 1000 с помощью заголовка запроса x-ms-max-item-count. Чтобы отобразить только некоторые результаты, например, когда пользовательский интерфейс или приложение API возвращает только десять результатов за раз, размер страницы можно уменьшить до 10. Это позволит снизить пропускную способность, используемую на операции чтения и на выполнение запросов.
Размер страницы также можно изменить с помощью метода setPageSize.
Политика индексирования
Исключите неиспользуемые пути из индексирования, чтобы ускорить выполнение операций записи
Политика индексирования Azure Cosmos DB позволяет указать пути к документам для включения или исключения из индексирования с помощью путей индексирования (setIncludedPaths и setExcludedPaths). Возможность управления путями индексирования позволяет оптимизировать производительность записи и снизить затраты на хранение индекса для сценариев с заранее определенными шаблонами запросов. Это связано с тем, что затраты на индексирование непосредственно зависят от количества уникальных путей индексирования. Например, в коде ниже показано, как с помощью оператора подстановочного знака "*" исключить из индексации целый раздел документов (поддерево).
Пакет SDK синхронизации для Java версии 2 (Maven com.microsoft.azure::azure-documentdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Дополнительные сведения см. в статье Политики индексации Azure Cosmos DB.
Пропускная способность
Измерение и настройка расхода единиц запроса/повторного использования
Azure Cosmos DB предоставляет обширный набор операций с документами в коллекции базы данных, в том числе реляционные и иерархические запросы с использованием UDF, хранимых процедур и триггеров. Затраты, связанные с каждой из этих операций, зависят от типа процессора, операций ввода-вывода и памяти, необходимой для завершения операции. Вместо того чтобы думать о закупке и управлении аппаратными ресурсами, вы можете думать о единице запроса (RU) как единой меры для ресурсов, необходимых для выполнения различных операций с базами данных и обслуживания запросов приложений.
Пропускная способность выделяется на основе количества единиц запроса, заданного для каждого контейнера. Удельный расход единиц запросов оценивается в расчете на одну секунду. Частота запросов для приложений, у которых она превышает подготовленные единицы запросов для контейнера, будет ограничена, пока она не упадет ниже зарезервированного для контейнера уровня. Если приложению требуется более высокий уровень пропускной способности, можно увеличить ее путем выделения дополнительных единиц запросов.
Сложность запроса влияет на количество единиц запроса, потребляемых операцией. Количество предикатов и их характер, количество определяемых пользователем функций и размер набора исходных данных — все это влияет на плату за операции запроса.
Чтобы оценить расходы на любую операцию (создание, обновление или удаление), проверьте значение заголовка x-ms-request-charge (или аналогичного свойства RequestCharge на вкладке ResourceResponse<T> или FeedResponse<T>). Это значение содержит число единиц запроса, потребляемых соответствующей операцией.
Пакет SDK синхронизации для Java версии 2 (Maven com.microsoft.azure::azure-documentdb)
ResourceResponse<Document> response = client.createDocument(collectionLink, documentDefinition, null, false); response.getRequestCharge();Стоимость запроса, указанная в этом заголовке, учитывается как часть подготовленной пропускной способности. Например, если у вас подготовлено 2000 ЕЗ/с, а если предыдущий запрос возвращает 1000 1 КБ-документов, стоимость операции составляет 1000. Таким образом, перед ограничением частоты выполнения последующих запросов сервер за одну секунду выполняет только два таких запроса. Чтобы узнать больше, ознакомьтесь с единицами запроса и калькулятором единиц запроса.
Обработка ограничения скорости / слишком высокая частота запросов
Выполнение запроса, который превышает лимит зарезервированной пропускной способности для учетной записи, не приводит к снижению производительности сервера, так как пользователь не сможет превысить это зарезервированное значение. Сервер заранее завершит запрос с ошибкой RequestRateTooLarge (код состояния HTTP: 429) и вернет в заголовке x-x-ms-retry-after-ms время (в миллисекундах), спустя которое можно повторно выполнить этот запрос.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100Пакеты SDK перехватят этот ответ, обработают заголовок retry-after, указанный сервером, и отправят запрос повторно. Если к вашей учетной записи параллельно имеет доступ только один клиент, следующая попытка будет успешной.
По умолчанию количество повторных попыток отправки запроса составляет 9 (это значение задается клиентом). Если к вашей учетной записи имеют доступ несколько клиентов и они выполняют запросы одновременно, этого значения может быть недостаточно. В этом случае клиент выдаст для приложения исключение DocumentClientException с кодом состояния 429. Число повторных попыток по умолчанию можно переопределить в свойстве RetryOptions экземпляра ConnectionPolicy. По умолчанию в случае превышения заданного счетчика повторов исключение DocumentClientException с кодом состояния 429 возвращается через 30 секунд (совокупное время ожидания). Это происходит, даже если текущее значение количества повторных попыток (по умолчанию (9) или определенное пользователем) меньше максимального значения.
Хотя автоматическая процедура отправки повторного запроса позволяет улучшить устойчивость приложений и повысить удобство работы с ними, она может снизить производительность, что, в свою очередь, станет причиной появления более длительных задержек. Если настройка производительности повлияла на регулирование сервера и стала причиной автоматической отправки запросов пакетом SDK, это может стать причиной появления пиков задержек на стороне клиента. Чтобы избежать пиков задержек во время настройки производительности, проверьте расход ресурсов на каждую операцию и убедитесь, что значение частоты запросов не превышено. Дополнительные сведения см. в статье Единицы запросов в DocumentDB.
Использование меньших документов для более высокой пропускной способности
Стоимость запроса (плата за обработку запроса) для каждой операции напрямую зависит от размера документа. За операции с большими документами взимается больше единиц запроса, чем за операции с мелкими документами.
Следующие шаги
Дополнительные сведения о создании приложения с высокой масштабируемостью и производительностью см. в статье Partitioning and scaling in Azure Cosmos DB (Секционирование и масштабирование в Azure Cosmos DB).
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по