Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
фабрика Data в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric фабрики данных. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
Если вам требуется анализировать файлы ORC или записывать данные в формате ORC, следуйте инструкциям, приведенным в этой статье.
Формат ORC поддерживается для следующих соединителей: Амазон S3, Мазон S3 Совместимое хранилище, Azure BLOB-объект, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage и SFTP.
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе приведен список свойств, поддерживаемых набором данных ORC.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type набора данных необходимо задать значение Orc. | Да |
| расположение | Параметры расположения файлов. Каждый файловый соединитель имеет собственный тип расположения и поддерживает собственный набор свойств в разделе location.
Подробные сведения см. в статье о соединителях —> раздел "Свойства набора данных". |
Да |
| compressionCodec | Кодек сжатия, используемый при записи в файлы ORC. При чтении из файлов ORC Фабрика данных автоматически определяет кодек сжатия по метаданным файла. Поддерживаются следующие типы: none, zlib, snappy (по умолчанию) и lzo. Обратите внимание, что в настоящее время Copy activity не поддерживает LZO при чтении и записи файлов ORC. |
No |
Ниже приведен пример набора данных ORC на Azure Blob Storage:
{
"name": "OrcDataset",
"properties": {
"type": "Orc",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
}
}
}
}
Обратите внимание на следующие аспекты:
- Сложные типы данных (например, MAP, LIST и STRUCT) в настоящее время поддерживаются только в потоках данных, а не в действии копирования. Чтобы использовать сложные типы в потоках данных, не импортируйте схему файла в набор данных, в результате чего в наборе данных остается пустая схема. Затем в преобразовании "источник" импортируйте проекцию.
- Пробелы в именах столбцов не поддерживаются.
свойства Copy activity
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. В этом разделе приведен список свойств, поддерживаемых источником и приемником ORC.
ORC в качестве источника
В разделе источника *source* действия копирования поддерживаются указанные ниже свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение OrcSource. | Да |
| storeSettings | Группа свойств, определяющих способ чтения данных из хранилища данных. Каждый файловый соединитель поддерживает собственный набор параметров чтения в разделе storeSettings.
See в статье соединителя -> Copy activity раздел свойств. |
No |
ORC в качестве приемника
В разделе *sink* действия Copy поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type приемника действия копирования должно иметь значение OrcSink. | Да |
| formatSettings | Группа свойств. См. таблицу Параметры записи ORC ниже. | No |
| storeSettings | Группа свойств, определяющих способы записи данных в хранилище данных. Каждый файловый соединитель поддерживает собственный набор параметров записи в разделе storeSettings.
See в статье соединителя -> Copy activity раздел свойств. |
No |
Поддерживаемые параметры записи ORC в разделе formatSettings:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для параметра type свойства formatSettings необходимо задать значение OrcWriteSettings. | Да |
| maxRowsPerFile | Можно выбрать режим записи данных в папку с разбиением на несколько файлов и указать максимальное число строк в одном таком файле. | No |
| fileNamePrefix | Это свойство применимо, если задано свойство maxRowsPerFile.Оно задает префикс, добавляемый к имени файла при записи данных с разбиением на несколько файлов. Имя присваивается по следующему шаблону: <fileNamePrefix>_00000.<fileExtension>. Если это свойство не задано, то префикс имени файла будет создан автоматически. Это свойство не применяется, если источником является файловое хранилище или хранилище данных с поддержкой разделов. |
No |
Свойства потока данных для сопоставления
В потоках данных сопоставления можно читать и записывать в формат ORC в следующих хранилищах данных: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 и SFTP и вы можете читать формат ORC в Амазон S3.
Указывать на файлы ORC можно либо с помощью набора данных ORC, либо с помощью встроенного набора данных.
Свойства источника
В приведенной ниже таблице перечислены свойства, поддерживаемые источником данных ORC. Изменить эти свойства можно на вкладке Source options (Параметры источника).
При использовании встроенного набора данных будут отображаться дополнительные параметры, совпадающие со свойствами, описанными в разделе Свойства набора данных.
| Имя | Описание: | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Формат | Формат должен быть orc |
yes | orc |
format |
| Пути с подстановочными знаками | Будут обработаны все файлы, соответствующие пути с подстановочными знаками. Переопределяет папку и путь к файлу, заданные в наборе данных. | no | String[] | wildcardPaths |
| Корневой путь раздела | Для секционированных файловых данных можно ввести корневой путь к секции, чтобы считывать секционированные папки как столбцы | no | Строка | partitionRootPath |
| Список файлов | Сообщает о том, указывает ли источник на текстовый файл, в котором перечислены файлы для обработки. | no |
true или false |
fileList |
| Столбец для хранения имени файла | Предписывает создать столбец с именем и путем исходного файла. | no | Строка | rowUrlColumn |
| After completion (После завершения) | Инструкции в отношении удаления или перемещения файлов после обработки. Путь к файлу начинается с корня контейнера. | no | Удаление: true или false Перемещение: [<from>, <to>] |
Очистка файлов moveFiles |
| Фильтр по последнему изменению | Задает фильтр для файлов по времени последнего изменения | no | Метка времени | modifiedAfter modifiedBefore |
| Allow no files found (Разрешить ненайденные файлы) | Когда задано значение true, ошибка не возникает, если файлы не найдены | no |
true или false |
ignoreNoFilesFound |
Пример источника
Связанный сценарий потока данных конфигурации источника ORC:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'orc') ~> OrcSource
Свойства приемника
В приведенной ниже таблице перечислены свойства, поддерживаемые приемником ORC. Эти свойства можно изменить на вкладке Параметры.
При использовании встроенного набора данных будут отображаться дополнительные параметры, совпадающие со свойствами, описанными в разделе Свойства набора данных.
| Имя | Описание: | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Формат | Формат должен быть orc |
yes | orc |
format |
| Clear the folder (Очистить папку) | Указывает, очищается ли конечная папка перед записью | no |
true или false |
truncate |
| File name option (Параметр имени файла) | Формат именования записываемого файла данных. По умолчанию — по одному файлу на секцию в формате part-#####-tid-<guid> |
no | Шаблон: строка На секцию: String[] Как данные в столбце: Строка Вывод в один файл: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Пример приемника
Связанный сценарий потока данных конфигурации приемника ORC:
OrcSource sink(
format: 'orc',
filePattern:'output[n].orc',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> OrcSink
Использование локального Integration Runtime
Внимание
Для копирования, предоставляемого локальной Integration Runtime, например между локальными и облачными хранилищами данных, если вы не копируете файлы ORC as-is, Необходимо установить 64-разрядную JRE 8 (среду выполнения Java) или OpenJDK и Microsoft распространяемый пакет Visual C++ 2010 на компьютере IR. Подробные сведения приведены в следующем абзаце.
Для копирования, работающего в локальной среде IR с помощью сериализации или десериализации файлов ORC, служба находит среду выполнения Java, сначала проверяя реестр (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) для JRE, если не найдено, во-вторых, проверка системной переменной JAVA_HOME для OpenJDK.
- Для использования JRE: для 64-разрядного IR требуется 64-разрядная JRE. Ее можно найти здесь.
- Для использования OpenJDK: поддерживается в среде выполнения интеграции, начиная с версии 3.13. Упакуйте jvm.dll со всеми другими необходимыми сборками OpenJDK на компьютере с локальной IR и соответственно установите системную переменную среды JAVA_HOME.
- Для установки распространяемого пакета Visual C++ 2010: распространяемый пакет Visual C++ 2010 не устанавливается с локальной средой выполнения интеграции. Ее можно найти здесь.
Совет
При копировании данных в формат ORC с помощью локального Integration Runtime и ошибки попадания с сообщением "При вызове java произошла ошибка: java.lang. OutOfMemoryError:Java пространство кучи", можно добавить переменную среды _JAVA_OPTIONS на компьютере, на котором размещена локальная среда IR, чтобы настроить размер кучи минимального или максимального размера для JVM, чтобы обеспечить возможность такой копии, а затем повторно запустить конвейер.
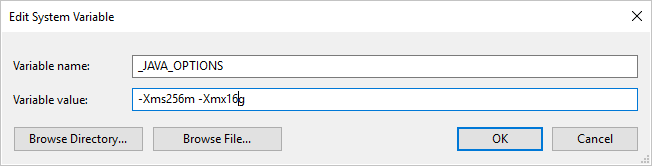
Пример: задайте переменную _JAVA_OPTIONS со значением -Xms256m -Xmx16g. Флаг Xms указывает начальный пул выделения памяти для виртуальной машины Java (JVM), а Xmx указывает максимальный пул выделения памяти. Это означает, что JVM будет запущена с объемом памяти Xms и сможет использовать не более Xmx объема памяти. По умолчанию служба использует минимум 64 МБ и максимум 1 ГБ.