Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описано копирование данных из облачного хранилища Google (GCS). Дополнительные сведения см. в вводных статьях о Фабрике данных Azure и Synapse Analytics.
Поддерживаемые возможности
Соединитель Google Cloud Storage поддерживается для следующих возможностей:
| Поддерживаемые возможности | IR |
|---|---|
| Действие копирования (источник/-) | (1) (2) |
| Сопоставление потока данных (источник/-) | ① |
| Поисковая активность | (1) (2) |
| Действие GetMetadata | (1) (2) |
| Удалить активность | (1) (2) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
В частности, этот соединитель Google Cloud Storage поддерживает копирование файлов "как есть" или анализ файлов с использованием поддерживаемых форматов файлов и кодеков сжатия. Он использует возможность взаимодействия, обеспечиваемую совместимостью GCS с S3.
Предварительные условия
Необходимо настроить свою учетную запись Google Cloud Storage следующим образом:
- Включите возможность взаимодействия для своей учетной записи облачного хранилища Google.
- Создайте проект по умолчанию, содержащий данные, которые требуется копировать из целевого контейнера GCS.
- Создайте учетную запись службы и определите соответствующие уровни разрешений, используя облачную систему IAM в GCP.
- Сгенерируйте ключи доступа для этой учетной записи службы.
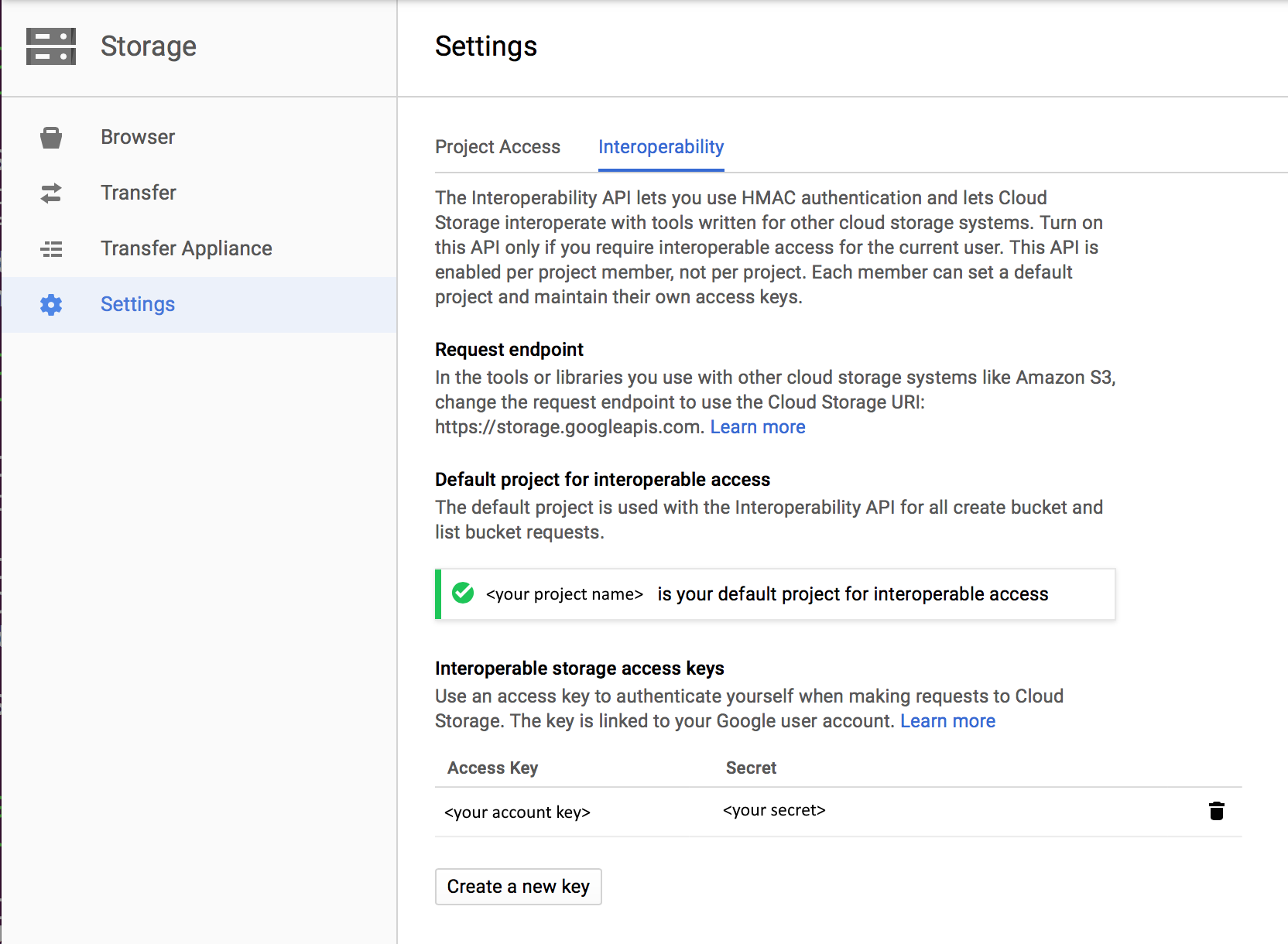
Необходимые разрешения
Для копирования данных из Google Cloud Storage убедитесь в том, что вам предоставлены следующие разрешения для операций с объектами: storage.objects.get и storage.objects.list.
Если вы используете UI для разработки, storage.buckets.list разрешение требуется для операций, таких как тестирование подключения к связанной службе и просмотр с корневого уровня. Если вы не хотите предоставлять это разрешение, можно выбрать в пользовательском интерфейсе параметры "Тестирование подключения к пути к файлу" или "Просмотр по указанному пути".
Полный список ролей Google Cloud Storage и соответствующих разрешений см. в статье Роли IAM для облачного хранилища на сайте Google Cloud.
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
Создание связанной службы для облачного хранилища Google с помощью пользовательского интерфейса
Выполните приведенные ниже действия, чтобы создать связанную службу для облачного хранилища Google с помощью пользовательского интерфейса на портале Azure.
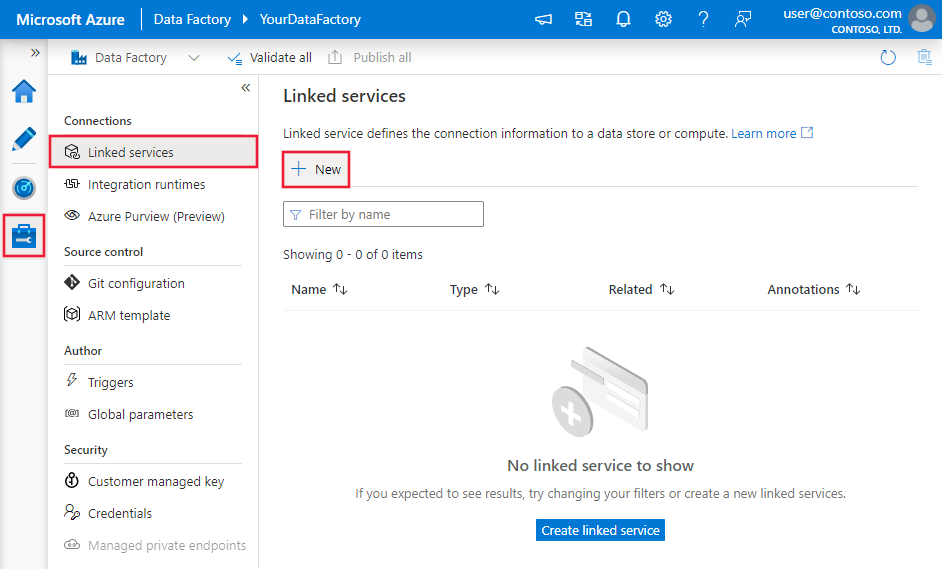
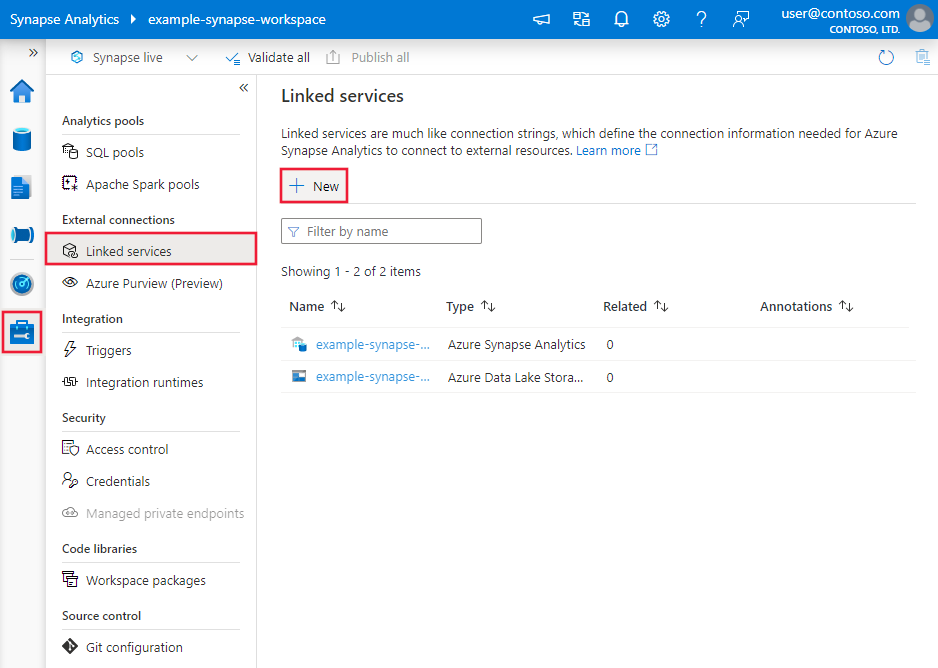
Перейдите на вкладку "Управление" в Фабрике данных Azure или рабочей области Synapse и выберите "Связанные службы", затем щелкните "Создать".
Найдите Google и выберите соединитель для облачного хранилища Google (S3 API).

Настройте сведения о службе, проверьте подключение и создайте связанную службу.
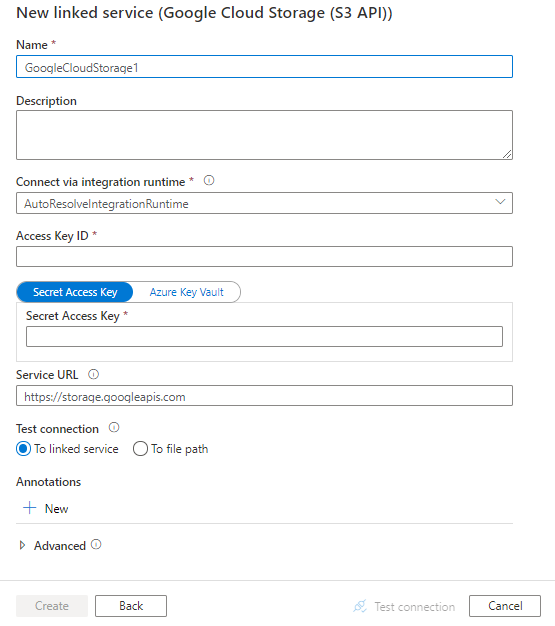
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для определения сущностей Фабрики данных, относящихся к Google Cloud Storage.
Свойства связанной службы
Для связанной службы Google Cloud Storage поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type необходимо задать значение GoogleCloudStorage. | Да |
| accessKeyId | Идентификатор секретного ключа доступа. Сведения о том, как найти ключ доступа и секрет, приводятся в разделе Предварительные требования. | Да |
| секретный ключ доступа | Сам секретный ключ доступа. Присвойте этому полю метку SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | Да |
| URL сервиса | Укажите пользовательскую конечную точку GCS в качестве https://storage.googleapis.com. |
Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Можно использовать среду выполнения интеграции Azure или локальную среду выполнения интеграции (если хранилище данных расположено в частной сети). Если это свойство не задано, используется среда выполнения интеграции Azure по умолчанию. | Нет |
Приведем пример:
{
"name": "GoogleCloudStorageLinkedService",
"properties": {
"type": "GoogleCloudStorage",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"serviceUrl": "https://storage.googleapis.com"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Фабрика данных Azure поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- Формат Excel
- Формат JSON
- Формат ORC
- Формат Parquet
- ФОРМАТ XML
Ниже перечислены свойства, которые поддерживаются для облачного хранилища Google в параметрах location в наборе данных на основе формата:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойству type в разделе location набора данных необходимо присвоить значение GoogleCloudStorageLocation. |
Да |
| Имя_корзины | Имя контейнера GCS. | Да |
| folderPath | Путь к папке в заданном контейнере. Если вы хотите использовать подстановочный знак для фильтрации папок, пропустите этот параметр и укажите его в параметрах источника действия. | Нет |
| fileName | Имя файла в заданном контейнере и путь к папке. Если вы хотите использовать подстановочный знак для фильтрации файлов, пропустите этот параметр и укажите его в параметрах источника действия. | Нет |
Пример:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Google Cloud Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "GoogleCloudStorageLocation",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. В этом разделе содержится список свойств, поддерживаемых источником данных Google Cloud Storage.
Google Cloud Storage в качестве типа источника
Фабрика данных Azure поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- Формат Excel
- Формат JSON
- Формат ORC
- Формат Parquet
- ФОРМАТ XML
Ниже перечислены свойства, которые поддерживаются для Google Cloud Storage в настройках storeSettings при использовании источника копирования на основе формата:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type в разделе storeSettings необходимо задать значение GoogleCloudStorageReadSettings. |
Да |
| Найдите файлы для копирования: | ||
| ВАРИАНТ 1. Статический путь |
Копирование из заданного контейнера или папки/пути к файлу, которые указаны в наборе данных. Если вы хотите скопировать все файлы из контейнера или папки, дополнительно укажите wildcardFileName как *. |
|
| ВАРИАНТ 2. Префикс GCS - префикс |
Префикс для имени ключа GCS в заданном контейнере, настроенном в наборе данных для фильтрации исходных файлов GCS. Выбираются ключи GCS, имена которых начинаются с bucket_in_dataset/this_prefix. Используется фильтр на серверной стороне GCS, который более эффективен, чем фильтр с использованием подстановочных знаков. |
Нет |
| Вариант 3. Подстановочный знак - wildcardFolderPath |
Путь к папке с подстановочными знаками в заданном контейнере, настроенном в наборе данных для фильтрации исходных папок. Допустимые знаки подстановки: * (соответствует нулю или нескольким символам) и ? (соответствует нулю или одному символу). Используйте ^, чтобы экранировать, если имя вашей папки содержит подстановочный символ или этот escape-символ. Дополнительные примеры приведены в разделе Примеры фильтров папок и файлов. |
Нет |
| Вариант 3. Подстановочный знак — wildcardFileName |
Имя файла с подстановочными знаками в заданном контейнере и путь к папке (или путь-подстановочный знак) для фильтрации исходных файлов. Допустимые знаки подстановки: * (соответствует нулю или нескольким символам) и ? (соответствует нулю или одному символу). Используйте ^, чтобы экранировать имя файла, если оно содержит подстановочный знак или символ экранирования. Дополнительные примеры приведены в разделе Примеры фильтров папок и файлов. |
Да |
| Вариант 3. Список файлов - fileListPath |
Указывает, что нужно скопировать заданный набор файлов. Укажите текстовый файл со списком файлов, которые необходимо скопировать, по одному файлу в строке (каждая строка должна содержать относительный путь к заданному в наборе данных пути). При использовании этого параметра не указывайте имя файла в наборе данных. Ознакомьтесь с дополнительными примерами в разделе Примеры списков файлов. |
Нет |
| Дополнительные параметры: | ||
| рекурсивный | Указывает, следует ли читать данные рекурсивно из вложенных папок или только из указанной папки. Обратите внимание, что если для свойства recursive задано значение true, а приемником является файловое хранилище, пустые папки и вложенные папки не создаются в приемнике. Допустимые значения: true (по умолчанию) и false. Это свойство не применяется при настройке fileListPath. |
Нет |
| удалитьФайлыПослеЗавершения | Указывает, удаляются ли двоичные файлы из исходного хранилища после успешного перемещения в конечное хранилище. Удаление файла выполняется для каждого файла, поэтому при сбое действия копирования вы увидите, что некоторые файлы уже скопированы в место назначения и удалены из источника, а другие остаются в исходном хранилище. Это свойство допустимо только в сценарии копирования двоичных файлов. По умолчанию имеет значение false. |
Нет |
| измененнаяДатаВремяНачало | Фильтр файлов на основе атрибута времени последнего изменения. Будут выбраны все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате "2018-12-01T05:00:00Z". Эти свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не будут применяться к этому набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения меньше указанного значения даты и времени.Это свойство не применяется при настройке fileListPath. |
Нет |
| модифицированноеДатаВремяКонец | То же, что выше. | Нет |
| включить обнаружение разделов | Для файлов, секционированных, укажите, следует ли анализировать секции из пути к файлу и добавлять их в качестве дополнительных исходных столбцов. Допустимые значения: false (по умолчанию) и true. |
Нет |
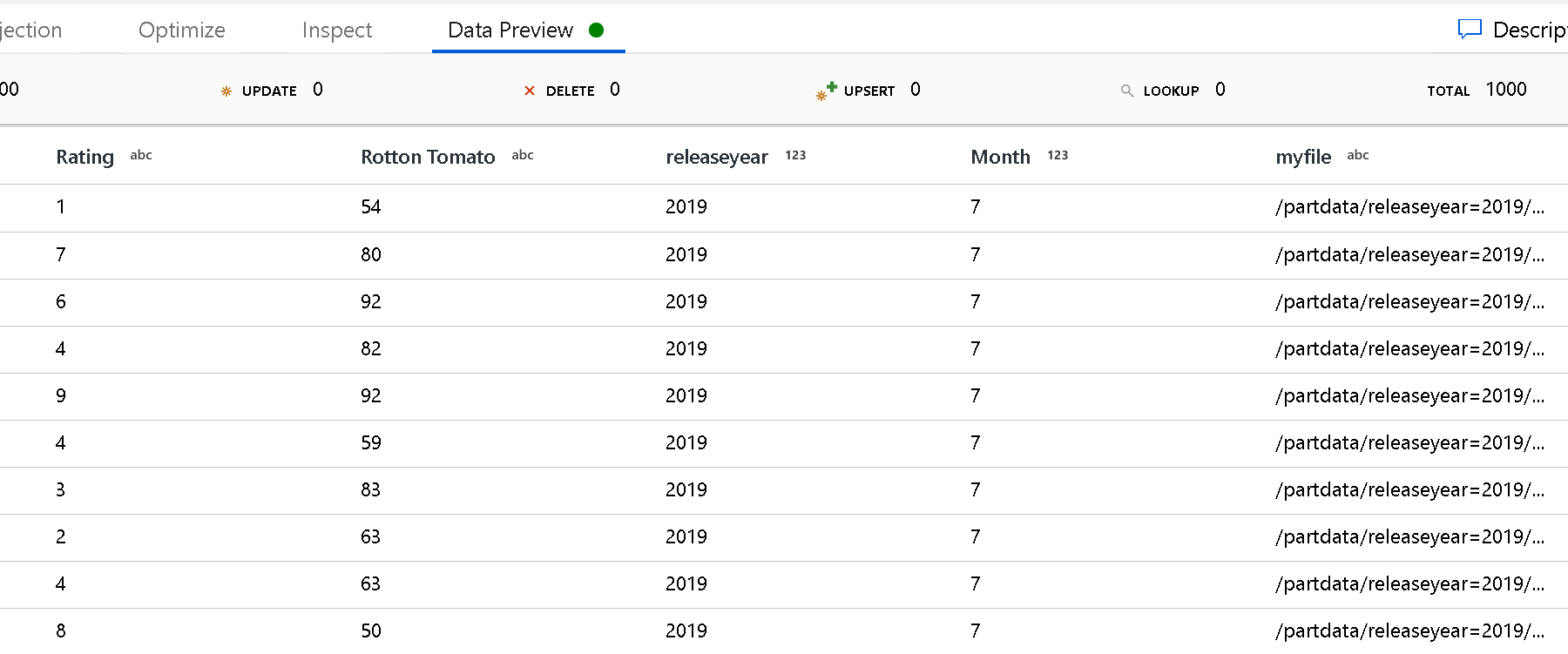
| partitionRootPath | Если обнаружение секций включено, укажите абсолютный корневой путь, чтобы считывать секционированные папки как столбцы данных. Если это не указано, используется значение по умолчанию — При использовании пути к файлу в наборе данных или списке файлов в источнике корневым путем секции считается путь, настроенный в наборе данных. — При использовании фильтра папки с подстановочными знаками корневым путем секции считается часть пути до первого подстановочного знака. Предположим, что вы настроили путь в наборе данных следующим образом: "root/folder/year=2020/month=08/day=27". — Если указать корневой путь секции "root/folder/year=2020", действие копирования в дополнение к указанным в файлах столбцам создаст еще два столбца, month и day, со значениями "08" и "27" соответственно.— Если корневой путь секции не указан, дополнительный столбец не будет создан. |
Нет |
| максимальное количество одновременных подключений | Верхний предел одновременных подключений, установленных для хранилища данных при выполнении действия. Указывайте значение только при необходимости ограничить количество одновременных подключений. | Нет |
Пример:
"activities":[
{
"name": "CopyFromGoogleCloudStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "GoogleCloudStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Примеры фильтров папок и файлов
В этом разделе описывается поведение папки и имени файла при использовании фильтров с подстановочными знаками.
| ведро | ключ | рекурсивный | Структура исходной папки и результат фильтрации (извлекаются файлы, выделенные полужирным шрифтом) |
|---|---|---|---|
| ведро | Folder*/* |
false | ведро ПапкаA Файл1.csv File2.json Подпапка1 File3.csv File4.json File5.csv ДругаяПапкаB Файл6.csv |
| ведро | Folder*/* |
истина | ведро ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv ДругаяПапкаB Файл6.csv |
| ведро | Folder*/*.csv |
неправда | ведро ПапкаA Файл1.csv File2.json Подпапка1 File3.csv File4.json File5.csv ДругаяПапкаB Файл6.csv |
| ведро | Folder*/*.csv |
true | ведро ПапкаA Файл1.csv File2.json Подпапка1 File3.csv File4.json File5.csv Другая папка B Файл6.csv |
Примеры списков файлов
В этом разделе описывается поведение, возникающее при указании пути к списку файлов в качестве источника для действия Copy.
Предположим, что у вас есть следующая исходная структура папок и вы хотите скопировать файлы, выделенные полужирным шрифтом:
| Пример исходной структуры | Содержимое файла FileListToCopy.txt | Настройка |
|---|---|---|
| ведро ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv Метаданные FileListToCopy.txt |
Файл1.csv Вложенная_папка1/Файл3.csv Вложенная_папка1/Файл5.csv |
В наборе данных: – Контейнер: bucket– Путь к папке: FolderAВ источнике действия копирования: – Путь к списку файлов: bucket/Metadata/FileListToCopy.txt Путь к списку файлов указывает на текстовый файл, который находится в том же хранилище данных и содержит список файлов, предназначенных для копирования. В этом списке указан один файл в каждой строке с относительным путем к пути, указанному в наборе данных. |
Сопоставление свойств потока данных
При преобразовании данных в потоках данных сопоставления можно считывать файлы из Google Cloud Storage в следующих форматах:
Конкретные параметры приведены в документации для соответствующего формата. Дополнительные сведения см. в статье Преобразование источника в потоке сопоставления данных.
Преобразование источника
При преобразовании исходных данных можно читать из контейнера, папки или отдельного файла в Google Cloud Storage. Используйте вкладку Параметры источника для управления чтением файлов.
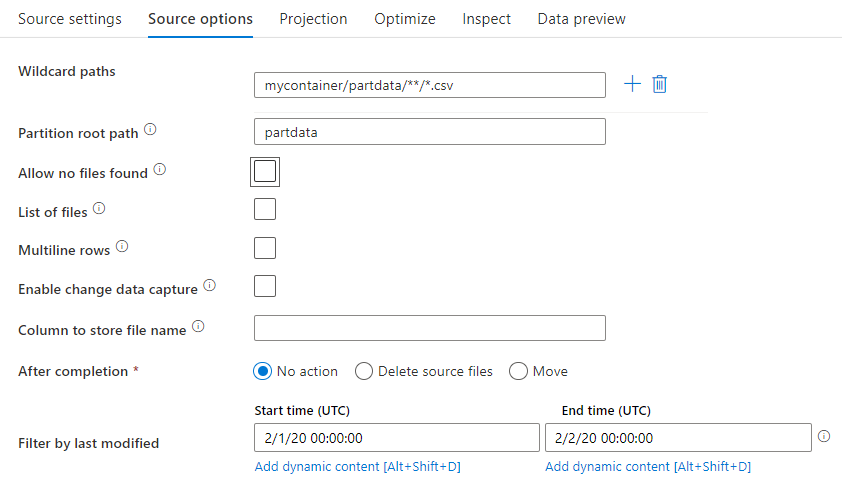
Пути с подстановочными знаками. Использование шаблона с подстановочными знаками позволяет службе просмотреть каждую соответствующую папку и файл в рамках единого преобразования источника. Это эффективный способ обработки нескольких файлов в одном потоке. Добавьте несколько шаблонов сопоставления с подстановочными знаками с помощью значка "плюс", который появляется при наведении указателя мыши на существующий шаблон с подстановочными знаками.
В исходном контейнере выберите файлы, соответствующие шаблону. В наборе данных можно указать только контейнер. Путь с подстановочными знаками должен также включать путь к папке из корневой папки.
Примеры подстановочных знаков:
*— представляет любой набор символов.**— представляет рекурсивную вложенность каталога.?— заменяет один символ.[]— соответствует одному или нескольким символам в квадратных скобках./data/sales/**/*.csv— возвращает все файлы .csv в папке /data/sales./data/sales/20??/**/— возвращает все файлы, созданные в 20 веке./data/sales/*/*/*.csv— возвращает файлы .csv, расположенные двумя уровнями ниже папки /data/sales./data/sales/2004/*/12/[XY]1?.csv— возвращает все файлы .csv, созданные в декабре 2004 года, которые начинаются с X или Y с двузначным числом в качестве префикса.
Корневой путь раздела. Если в источнике файлов имеются секционированные папки формата key=value (например, year=2019), то верхний уровень этого дерева секционированной папки можно назначить имени столбца в потоке данных.
Во-первых, задайте подстановочный знак, чтобы включить все пути, которые являются в секционированных папках, а также конечные файлы, которые требуется прочитать.
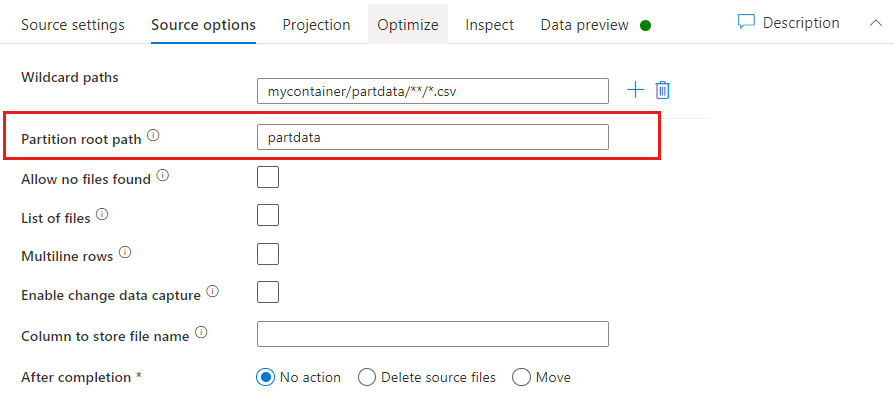
Для определения верхнего уровня структуры папок используйте параметр Корневой путь раздела. При просмотре содержимого данных с помощью предварительного просмотра данных вы увидите, что служба добавит разрешенные секции, найденные на каждом уровне папок.
Список файлов: это набор файлов. Создайте текстовый файл, который включает список относительных путей файлов к обработке. Укажите на этот текстовый файл.
Столбец для хранения имени файла: сохраните имя исходного файла в столбце в данных. Укажите здесь новое имя столбца для хранения строки имени файла.
После завершения: выберите, ничего не делать с исходным файлом после запуска потока данных, удалить его или переместить. Пути для перемещения являются относительными.
Чтобы переместить исходные файлы в другое расположение после обработки, сначала выберите "Переместить" для операции с файлом. Затем задайте исходный каталог. Если вы не используете подстановочные знаки в пути, то параметр "откуда" будет совпадать с исходной папкой.
Если имеется исходный путь с подстановочным знаком, синтаксис будет выглядеть следующим образом.
/data/sales/20??/**/*.csv
«от» можно задать как:
/data/sales
Вы можете указать «по адресу» как:
/backup/priorSales
В этом случае все файлы, источником которых является папка /data/sales, перемещаются в папку /backup/priorSales.
Примечание.
Операции с файлами выполняются только тогда, когда поток данных запускается в процессе выполнения конвейера (отладка конвейера или запуск выполнения), использующего действие "Выполнить поток данных" в конвейере. Операции с файлами не выполняются в режиме отладки потока данных.
Фильтр по последнему изменению: вы можете фильтровать файлы, обрабатываемые путем указания диапазона дат последнего изменения. Все значения даты и времени указаны в формате UTC.
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Свойства действия GetMetadata
Подробные сведения об этих свойствах см. в статье Действие GetMetadata.
Удаление свойств активности
Подробные сведения о свойствах см. в разделе Удаление действий.
Устаревшие модели
Если для копирования данных из Google Cloud Storage вы используете соединитель Amazon S3, он все еще поддерживается "как есть" для обеспечения обратной совместимости. Рекомендуется использовать новую модель, упомянутую ранее. В пользовательском интерфейсе разработки уже используется именно эта новая модель.
Связанный контент
Список хранилищ данных, поддерживаемых действием копирования в качестве источников и приемников, приведен в разделе Поддерживаемые хранилища данных.