Формат Parquet в Фабрике данных Azure и Azure Synapse Analytics
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Если необходимо анализировать файлы Parquet или записывать данные в формате Parquet , следуйте инструкциям, приведенным в этой статье.
Формат Parquet поддерживается для следующих соединителей:
- Amazon S3
- Совместимое хранилище Amazon S3
- Хранилище BLOB-объектов Azure
- Azure Data Lake Storage 1-го поколения
- Azure Data Lake Storage 2-го поколения
- Файлы Azure
- Файловая система
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Хранилище Oracle Cloud
- SFTP
Список поддерживаемых функций для всех доступных соединителей см. в статье Обзор соединителей.
Использование локальной среды выполнения интеграции
Внимание
Для копирования посредством локальной среды выполнения интеграции (IR), то есть между локальным и облачным хранилищами данных, если вы не копируете файлы Parquet как есть, на компьютере среды выполнения интеграции необходимо установить 64-разрядную JRE 8 (среду выполнения Java) или OpenJDK. Подробные сведения приведены в следующем абзаце.
Для копирования, запущенного в локальной среде IR с сериализацией/десериализацией файлов Parquet, служба определяет местонахождение среды выполнения Java, сначала проверяя реестр (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) на наличие JRE, если он не найден, после чего проверяя системную переменную JAVA_HOME для OpenJDK.
- Для использования JRE: для 64-разрядного IR требуется 64-разрядная JRE. Ее можно найти здесь.
- Для использования OpenJDK: поддерживается в среде выполнения интеграции, начиная с версии 3.13. Упакуйте jvm.dll со всеми другими необходимыми сборками OpenJDK на компьютере с локальной средой IR и соответствующим образом задайте системную переменную среды JAVA_HOME. Затем перезапустите локальную среду IR, чтобы сразу же применить настройки.
Совет
Если вы копируете данные в формат Parquet или из формата Parquet с помощью локальной среди выполнения интеграции и возникает ошибка: "Ошибка при вызове Java, сообщение: java.lang.OutOfMemoryError:Java heap space", можно добавить переменную среды _JAVA_OPTIONS в компьютере, на котором размещена локальная среда выполнения интеграции для настройки минимального и максимального размера кучи для виртуальной машины Java, чтобы расширить возможности такой копии, а затем повторно запустить конвейер.
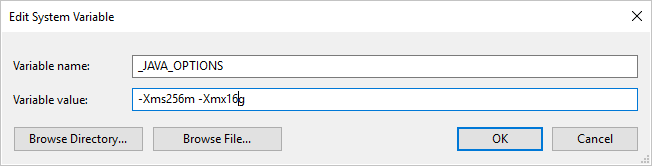
Пример: задайте переменную _JAVA_OPTIONS со значением -Xms256m -Xmx16g. Флаг Xms указывает начальный пул выделения памяти для виртуальной машины Java (JVM), а Xmx указывает максимальный пул выделения памяти. Это означает, что JVM будет запущена с объемом памяти Xms и сможет использовать не более Xmx объема памяти. По умолчанию служба использует минимум 64 МБ и максимум 1 ГБ.
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе содержится список свойств, поддерживаемых набором данных Parquet.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type набора данных необходимо задать значение Parquet. | Да |
| расположение | Параметры расположения файлов. Каждый файловый соединитель имеет собственный тип расположения и поддерживает собственный набор свойств в разделе location. Подробные сведения см. в статье о соединителях —> раздел "Свойства набора данных". |
Да |
| compressionCodec | Кодек сжатия, используемый при записи в файлы Parquet. При чтении из файлов Parquet Фабрика данных автоматически определяет кодек сжатия по метаданным файла. Поддерживаются следующие типы: "нет", "gzip", "закрепление" (по умолчанию) и "lzo". Примечание. В настоящее время действие копирования не поддерживает кодек LZO при чтении и записи файлов Parquet. |
No |
Примечание.
Пробелы в именах столбцов файлов Parquet не допустимы.
Ниже приведен пример набора данных Parquet в хранилище BLOB-объектов Azure:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. В этом разделе приведен список свойств, поддерживаемых источником и приемником Parquet.
Parquet в качестве источника
В разделе источника *source* действия копирования поддерживаются указанные ниже свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение ParquetSource. | Да |
| storeSettings | Группа свойств, определяющих способ чтения данных из хранилища данных. Каждый файловый соединитель поддерживает собственный набор параметров чтения в разделе storeSettings. Подробные сведения см. в статье о соединителях —> раздел "Свойства действия Copy". |
No |
Parquet в качестве приемника
В разделе *sink* действия Copy поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для приемника действия копирования должно иметь значение ParquetSink. | Да |
| formatSettings | Группа свойств. См. таблицу Параметры записи Parquet ниже. | No |
| storeSettings | Группа свойств, определяющих способы записи данных в хранилище данных. Каждый файловый соединитель поддерживает собственный набор параметров записи в разделе storeSettings. Подробные сведения см. в статье о соединителях —> раздел "Свойства действия Copy". |
No |
Поддерживаемые Параметры записи Parquet в formatSettings
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для параметра type свойства formatSettings необходимо задать значение ParquetWriteSettings. | Да |
| maxRowsPerFile | Можно выбрать режим записи данных в папку с разбиением на несколько файлов и указать максимальное число строк в одном таком файле. | No |
| fileNamePrefix | Это свойство применимо, если задано свойство maxRowsPerFile.Оно задает префикс, добавляемый к имени файла при записи данных с разбиением на несколько файлов. Имя присваивается по следующему шаблону: <fileNamePrefix>_00000.<fileExtension>. Если это свойство не задано, то префикс имени файла будет создан автоматически. Это свойство не применяется, если источником является файловое хранилище или хранилище данных с поддержкой разделов. |
No |
Свойства потока данных для сопоставления
В потоках данных для сопоставления можно читать и записывать данные в формате parquet в следующих хранилищах данных: Хранилище BLOB-объектов Azure, Azure Data Lake Storage 1-го поколения, Azure Data Lake Storage 2-го поколения и SFTP, кроме того, чтение данных в формате parquet поддерживается в Amazon S3.
Свойства источника
В таблице, приведенной ниже, указаны свойства, поддерживаемые источником данных parquet. Изменить эти свойства можно на вкладке Source options (Параметры источника).
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Формат | Формат должен быть parquet |
yes | parquet |
format |
| Пути с подстановочными знаками | Будут обработаны все файлы, соответствующие пути с подстановочными знаками. Переопределяет папку и путь к файлу, заданные в наборе данных. | no | String[] | wildcardPaths |
| Корневой путь раздела | Для секционированных файловых данных можно ввести корневой путь к секции, чтобы считывать секционированные папки как столбцы | no | Строка | partitionRootPath |
| Список файлов | Сообщает о том, указывает ли источник на текстовый файл, в котором перечислены файлы для обработки. | no | true или false |
fileList |
| Столбец для хранения имени файла | Предписывает создать столбец с именем и путем исходного файла. | no | Строка | rowUrlColumn |
| After completion (После завершения) | Инструкции в отношении удаления или перемещения файлов после обработки. Путь к файлу начинается с корня контейнера. | no | Удаление: true или false Перемещение: [<from>, <to>] |
Очистка файлов moveFiles |
| Фильтр по последнему изменению | Задает фильтр для файлов по времени последнего изменения | no | Метка времени | modifiedAfter modifiedBefore |
| Allow no files found (Разрешить ненайденные файлы) | Когда задано значение true, ошибка не возникает, если файлы не найдены | no | true или false |
ignoreNoFilesFound |
Пример источника
На приведенном ниже рисунке показан пример конфигурации источника Parquet в потоках данных для сопоставления.
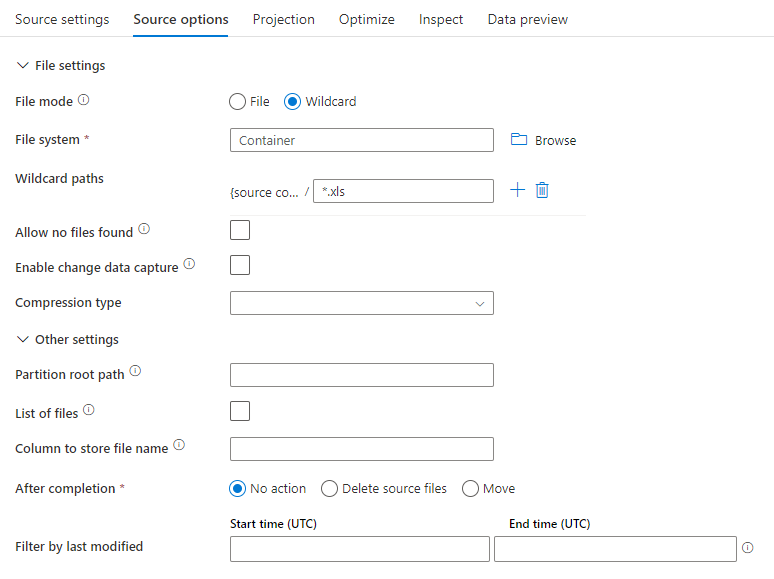
Связанный скрипта потока данных:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Свойства приемника
В таблице, приведенной ниже, указаны свойства, поддерживаемые приемником данных parquet. Эти свойства можно изменить на вкладке Параметры.
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Формат | Формат должен быть parquet |
yes | parquet |
format |
| Clear the folder (Очистить папку) | Указывает, очищается ли конечная папка перед записью | no | true или false |
truncate |
| File name option (Параметр имени файла) | Формат именования записываемого файла данных. По умолчанию — по одному файлу на секцию в формате part-#####-tid-<guid> |
no | Шаблон: строка На секцию: String[] Как данные в столбце: Строка Вывод в один файл: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Пример приемника
На приведенном ниже рисунке показан пример конфигурации приемника parquet в потоках данных для сопоставления.
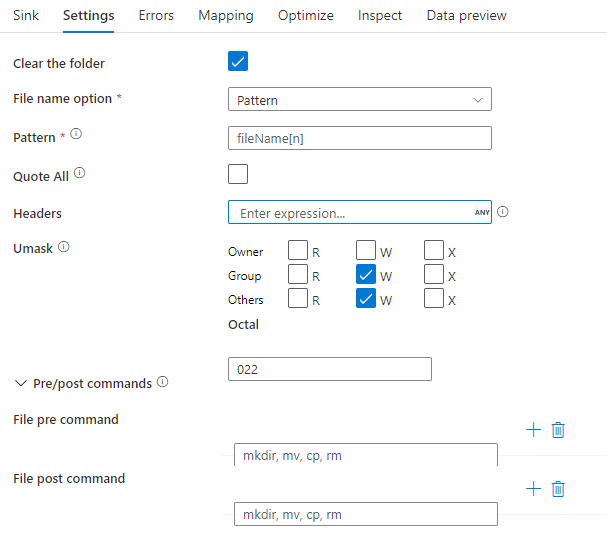
Связанный скрипта потока данных:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Поддержка типов данных
Сложные типы данных Parquet (например, MAP, LIST и STRUCT) в настоящее время поддерживаются только в потоках данных, а не в действии копирования. Чтобы использовать сложные типы в потоках данных, не импортируйте схему файла в набор данных, в результате чего в наборе данных остается пустая схема. Затем в преобразовании "источник" импортируйте проекцию.
Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по