Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
Действие HDInsight MapReduce в Azure Data Factory или Synapse Analytics pipeline вызывает программу MapReduce в вашем собственном или по требованию HDInsight кластере. Данная статья основана на материалах статьи о действиях преобразования данных , в которой приведен общий обзор преобразования данных и список поддерживаемых действий преобразования.
Дополнительные сведения см. в руководствах по Azure Data Factory и Synapse Analytics и учебник: Tutorial: преобразование данных перед чтением этой статьи.
Дополнительные сведения о выполнении скриптов Pig и Hive в кластере HDInsight из конвейера с помощью действий Pig и Hive в HDInsight см. в разделе Pig и Hive.
Добавление действия HDInsight MapReduce в конвейер с помощью пользовательского интерфейса
Чтобы использовать в конвейере действие HDInsight MapReduce, выполните следующее:
Выполните поиск MapReduce в панели активности конвейера и перетащите задачу MapReduce на холст конвейера.
Выберите новое действие MapReduce на холсте, если оно еще не выбрано.
Перейдите на вкладку Кластер HDI, чтобы выбрать или создать связанную службу для кластера HDInsight, которая будет использоваться для выполнения действия MapReduce.
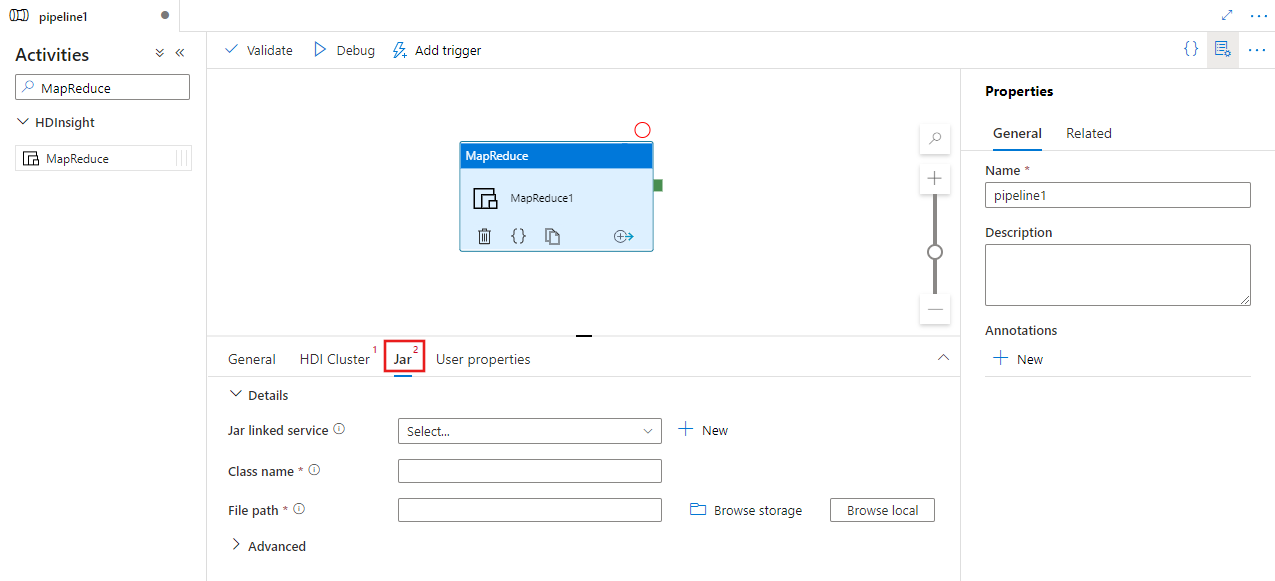
Перейдите на вкладку Jar, чтобы выбрать или создать новую связанную службу Jar с учетной записью Azure Storage, в которую будет размещен скрипт. Укажите имя класса для выполнения и путь к файлу в месте хранения. Можно также настроить дополнительные сведения, в частности расположение библиотек Jar, конфигурацию отладки, аргументы и параметры для отправки в скрипт.
Синтаксис
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Сведения о синтаксисе
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| имя | Название деятельности. | Да |
| описание | Текст, описывающий, для чего используется действие | Нет |
| тип | Для активности MapReduce используется тип HDinsightMapReduce. | Да |
| linkedServiceName | Ссылка на кластер HDInsight, зарегистрированный в качестве связанной службы. Чтобы узнать больше об этой связанной службе, см. статью Связанные службы вычислений. | Да |
| className | Имя класса, который нужно выполнить. | Да |
| jarLinkedService | Ссылается на связанную службу Azure Storage, используемую для хранения JAR-файлов. Поддерживаются только Azure Blob Storage и ADLS Gen2 связанные службы. Если вы не укажете эту связанную службу, используется служба Azure Storage, определенная в связанной службе HDInsight. | Нет |
| jarFilePath | Укажите путь к jar-файлам, хранящимся в Azure Storage, на который ссылается jarLinkedService. Имя файла чувствительно к регистру. | Да |
| jarlibs | Массив строк путей к файлам библиотеки Jar, на которые ссылается задание, и которые хранятся в Azure Storage, определенном в jarLinkedService. Имя файла чувствительно к регистру. | Нет |
| getDebugInfo | Указывает, когда файлы журналов копируются в Azure Storage, используемое кластером HDInsight или указанное jarLinkedService. Допустимые значения: None (Нет), Always (Всегда) или Failure (Ошибка). Значение по умолчанию: None. | Нет |
| аргументы | Указывает массив аргументов для задания Hadoop. Аргументы передаются как аргументы командной строки в каждую задачу. | Нет |
| определяет | Укажите параметры в виде пар "ключ — значение" для использования в скрипте Hive. | Нет |
Пример
С помощью HDInsight MapReduce Activity можно выполнить любой JAR-файл MapReduce в кластере HDInsight. В приведенном ниже образце определения конвейера JSON действие HDInsight настроено на запуск JAR-файла Mahout.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
Вы можете указать необходимые аргументы для программы MapReduce в разделе arguments. Во время выполнения вы увидите несколько дополнительных аргументов (например, mapreduce.job.tags) платформы MapReduce. Чтобы отличать свои аргументы от аргументов MapReduce, вы можете использовать параметр и значение в качестве аргументов, как показано в следующем примере (-s, --input, --output и т. д. — параметры, за которыми сразу следуют их значения).
Связанный контент
Ознакомьтесь со следующими ссылками, в которых описаны способы преобразования данных другими способами: