Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этом руководстве вы создадите фабрику данных с помощью портала Azure. После этого вы с помощью инструмента «Копирование данных» создадите pipeline, который копирует данные из хранилища BLOB-объектов Azure в базу данных SQL.
Примечание.
Если вы еще не работали с фабрикой данных Azure, ознакомьтесь со статьей Введение в фабрику данных Azure.
В этой инструкции вы выполните следующие шаги:
- Создали фабрику данных.
- Используйте инструмент копирования данных для создания конвейера.
- Следите за процессом конвейера и выполнением активностей.
Требования
- Подписка Azure. Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу.
- Учетная запись службы хранилища Azure: используйте хранилище BLOB-объектов в качестве исходного хранилища данных. Если у вас нет учетной записи хранения Azure, см. инструкции по ее созданию.
- База данных SQL Azure. Используйте База данных SQL в качестве хранилища данных приемника. Если у вас нет Базы данных SQL, см. инструкции по ее созданию.
Подготовка базы данных SQL
Разрешить службам Azure доступ к логическому серверу SQL вашей базы данных Azure SQL.
Убедитесь, что для Базы данных SQL включен параметр Разрешить доступ к серверу службам и ресурсам Azure. Этот параметр позволяет Data Factory записывать данные в экземпляр вашей базы данных. Чтобы проверить и при необходимости включить этот параметр, перейдите к логическому серверу SQL Server, выберите "Безопасность > Брандмауэры и виртуальные сети" и задайте для параметра > состояние >
Примечание.
Параметр Разрешить доступ к серверу службам и ресурсам Azure разрешает доступ к SQL Server по сети любому ресурсу Azure, а не только ресурсам из вашей подписки. Она может быть не подходит для всех сред, но подходит для этого ограниченного руководства. Дополнительные сведения см. в статье Правила брандмауэра Azure SQL Server. В качестве альтернативы используйте частные конечные точки для подключения к службам Azure PaaS без использования общедоступных IP-адресов.
Создать BLOB и таблицу SQL
Подготовьте хранилище BLOB-объектов и Базу данных SQL к изучению этого руководства, выполнив следующие действия.
Создайте исходный объект типа BLOB
Запустите Блокнот. Скопируйте следующий текст и сохраните его в файл с именем inputEmp.txt на диске.
FirstName|LastName John|Doe Jane|DoeСоздайте контейнер adfv2tutorial и отправьте в него файл inputEmp.txt. Это можно сделать с помощью портала Azure или разных средств, включая Обозреватель службы хранилища Azure.
Создание таблицы-приемника SQL
Чтобы создать таблицу с именем
dbo.empв База данных SQL, используйте следующий скрипт SQL:CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Создание фабрики данных
В верхнем меню выберите Создать ресурс>Аналитика>Фабрика данных :
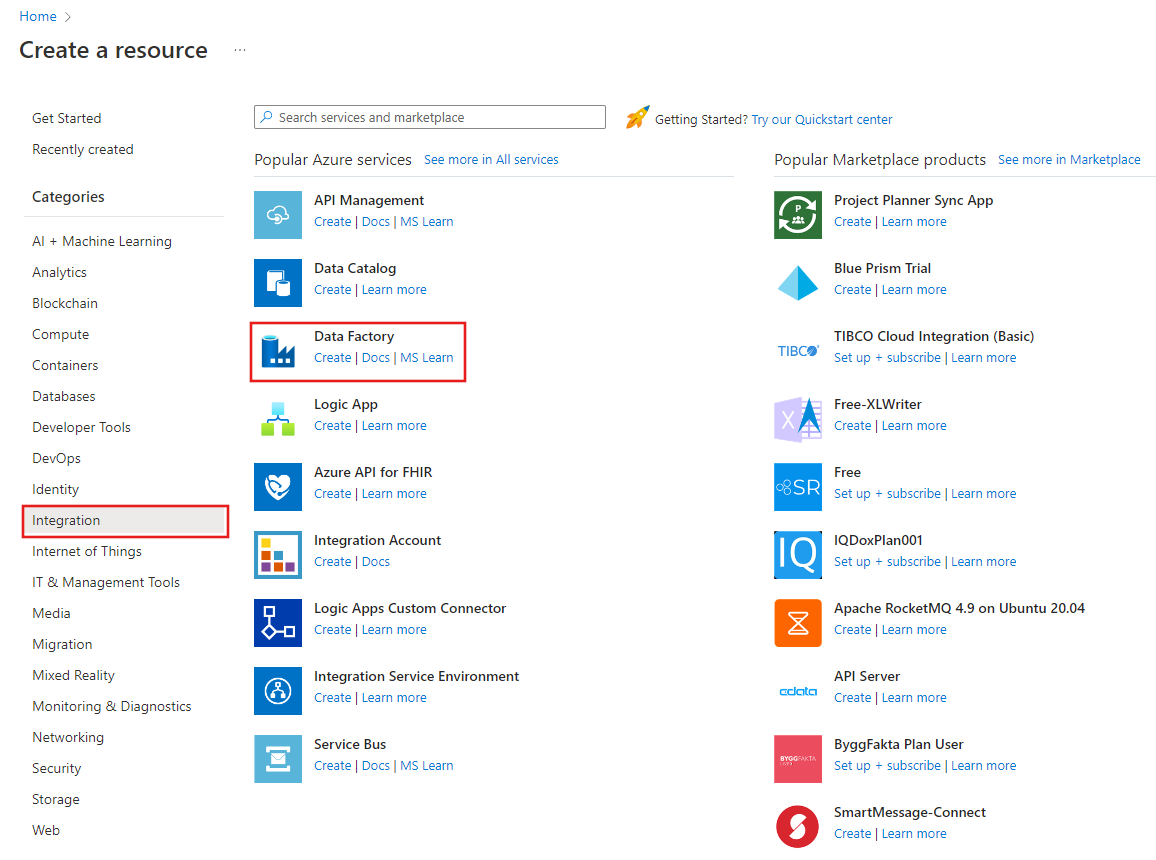
На странице Новая фабрика данных в поле Имя введите ADFTutorialDataFactory.
Имя фабрики данных должно быть глобально уникальным. Вы можете получить следующее сообщение об ошибке.
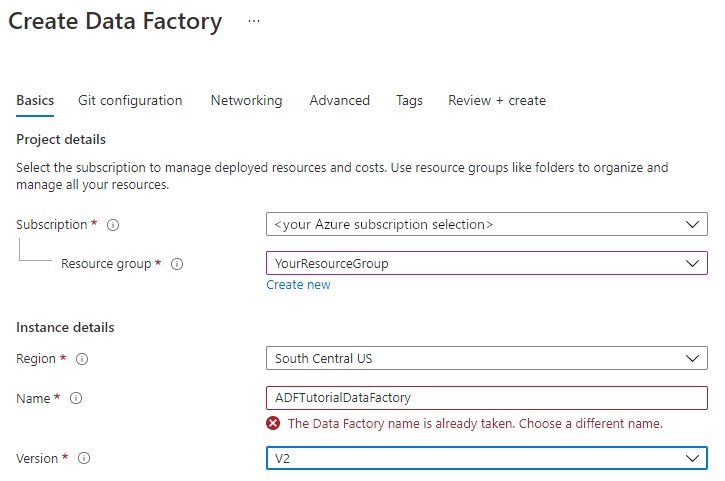
Если вы получите сообщение об ошибке касательно значения имени, введите другое имя для фабрики данных. Например,ваше_имяADFTutorialDataFactory. Правила именования артефактов службы "Фабрика данных" см. в этой статье.
Выберите подписку Azure, для создания новой фабрики данных.
Для группы ресурсов выполните одно из следующих действий:
a. Выберите Использовать существующуюи укажите существующую группу ресурсов в раскрывающемся списке.
б. Выберите Создать новуюи укажите имя группы ресурсов.
Чтобы узнать о группах ресурсов, см. Использование групп ресурсов для управления вашими ресурсами Azure.
В качестве версии выберите V2.
В качестве расположения выберите расположение фабрики данных. В раскрывающемся списке отображаются только поддерживаемые расположения. Хранилища данных (например, служба хранилища Azure и база данных SQL) и вычислительные ресурсы (например, Azure HDInsight), используемые фабрикой данных, могут располагаться в других регионах или расположениях.
Нажмите кнопку создания.
Когда создание завершится, откроется домашняя страница Фабрика данных.

Чтобы запустить пользовательский интерфейс Фабрики данных Azure на отдельной вкладке, нажмите кнопку Открыть на элементе Open Azure Data Factory Studio (Открыть студию Фабрики данных Azure).
Используйте инструмент 'Копирование данных' для создания конвейера
На домашней странице Azure Data Factory выберите плитку Импорт, чтобы запустить средство копирования данных.
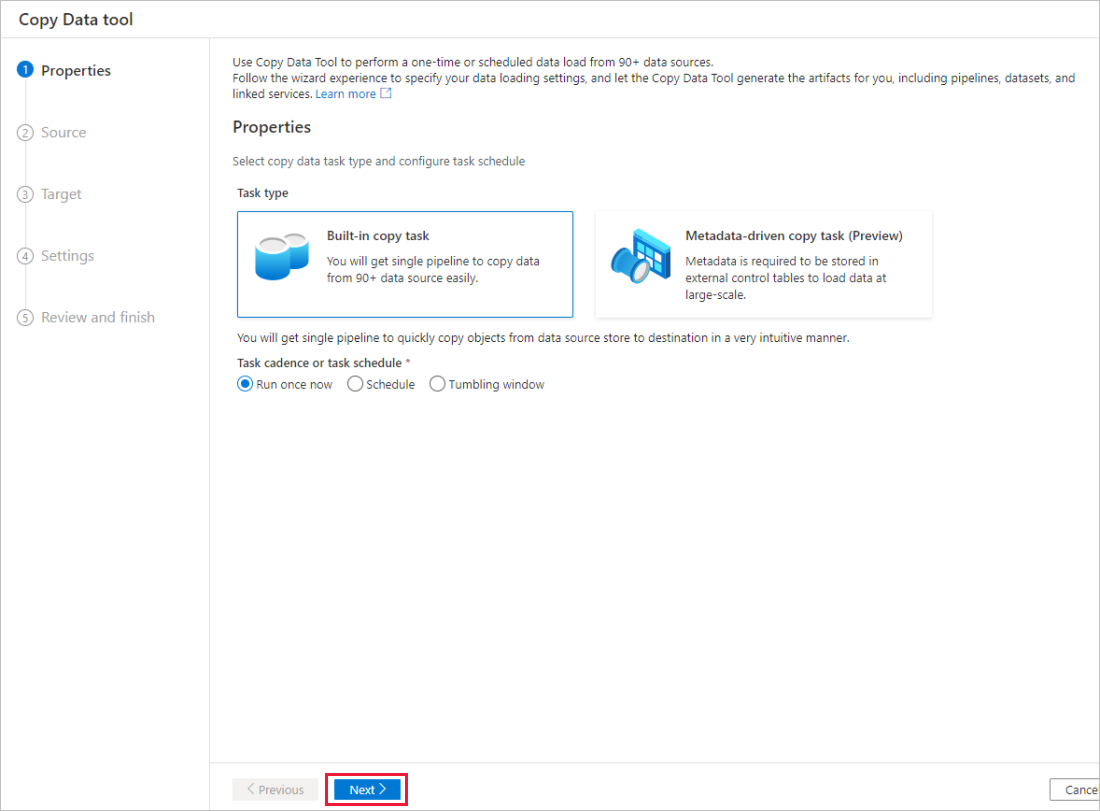
На странице Свойства средства копирования данных в разделе Тип задачи выберите Встроенная задача копирования, а затем нажмите кнопку Далее.
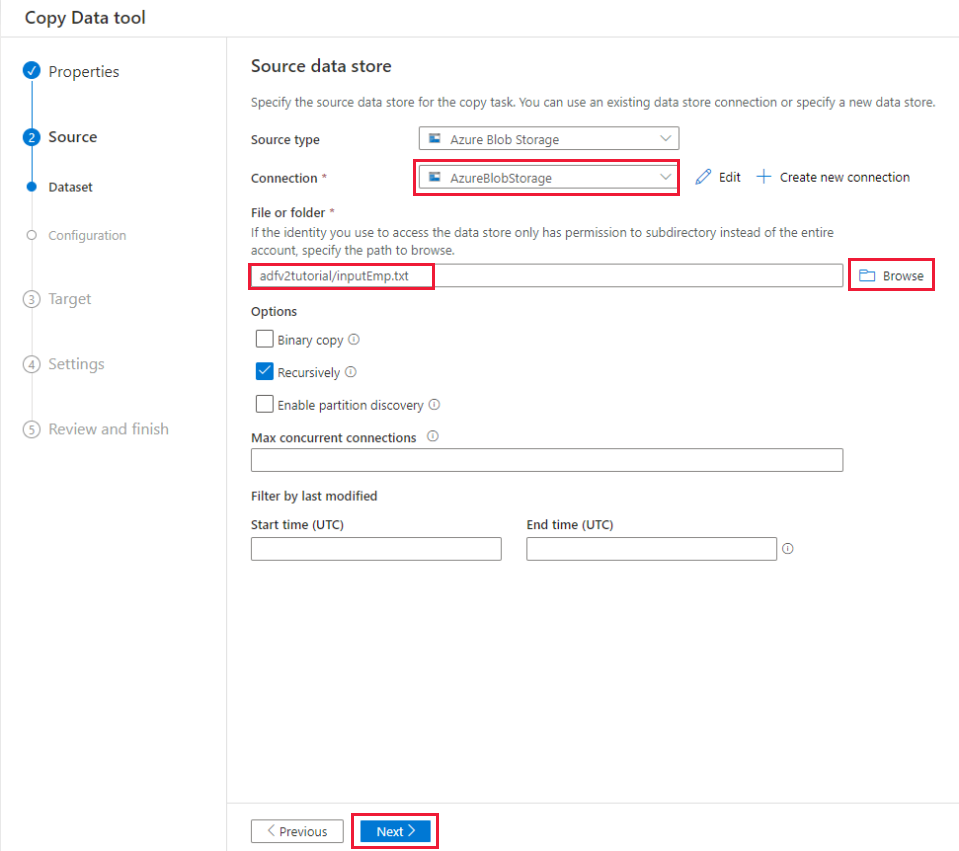
На странице Исходное хранилище данных сделайте следующее:
a. Выберите + Создать подключение, чтобы добавить подключение.
б. В галерее выберите Хранилище BLOB-объектов Azure и выберите Продолжить.
с. На странице Новое подключение (Хранилище BLOB-объектов Azure) выберите свою подписку Azure из списка Подписка Azure и выберите учетную запись хранения из списка Имя учетной записи хранения. Проверьте подключение и выберите Создать.
д. В блоке Подключение выберите созданную связанную службу в качестве источника.
д) В разделе Файл или папка нажмите кнопку Обзор, чтобы перейти к папке adfv2tutorial, выберите файл inputEmp.txt и нажмите кнопку OK.
е) Чтобы перейти к следующему шагу, нажмите кнопку Далее.
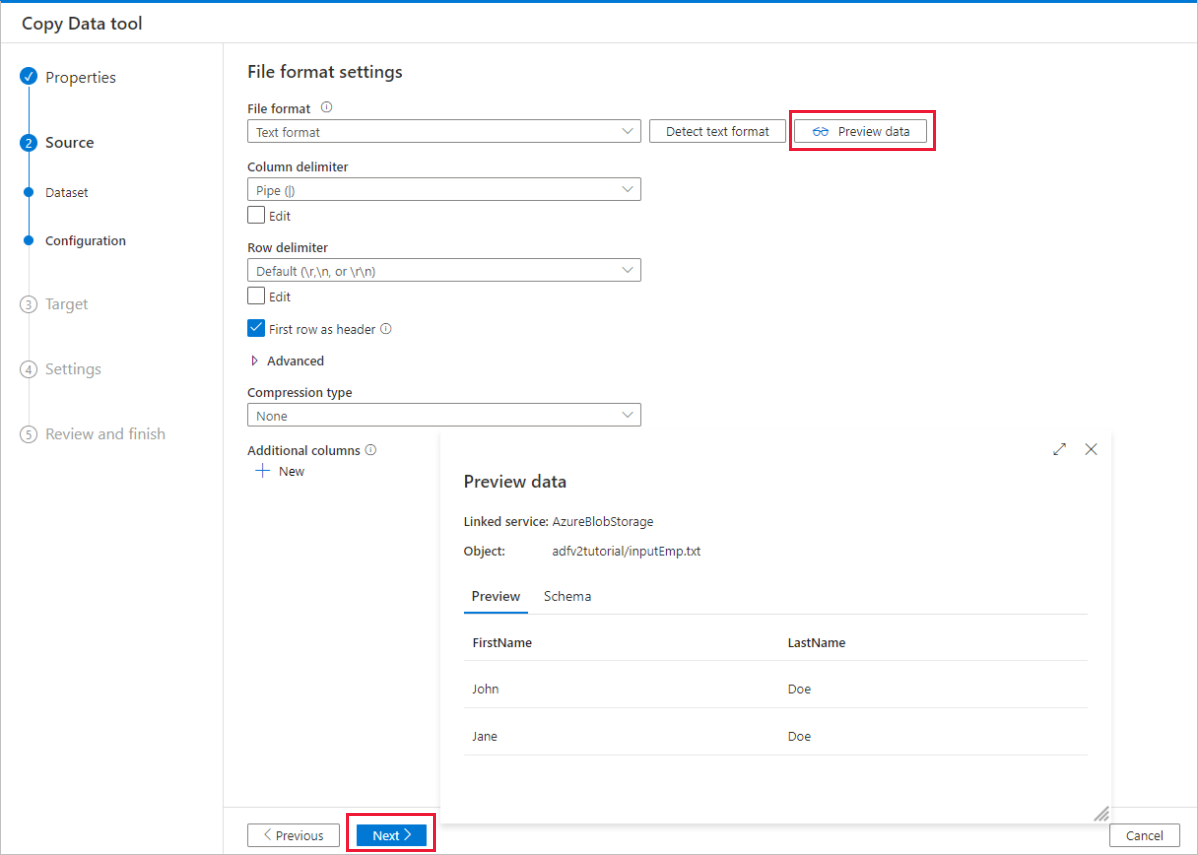
На странице File format settings (Параметры формата файла) установите флажок First row as heade (Первая строка в качестве заголовка). Обратите внимание, что средство автоматически обнаруживает разделители столбцов и строк, а также позволяет просмотреть данные и схему входных данных, нажав кнопку Просмотр данных на этой странице. Затем выберите Далее.
На странице Целевое хранилище данных сделайте следующее:
a. Выберите + Создать подключение, чтобы добавить подключение.
б. В галерее выберите Базу данных SQL Azure, а затем выберите Продолжить.
с. На странице Новое подключение (База данных SQL Azure) выберите подписку Azure, имя сервера и имя базы данных из раскрывающегося списка. Затем в разделе Тип проверки подлинности выберите Проверка подлинности SQL, укажите имя пользователя и пароль. Проверьте подключение и нажмите кнопку Создать.
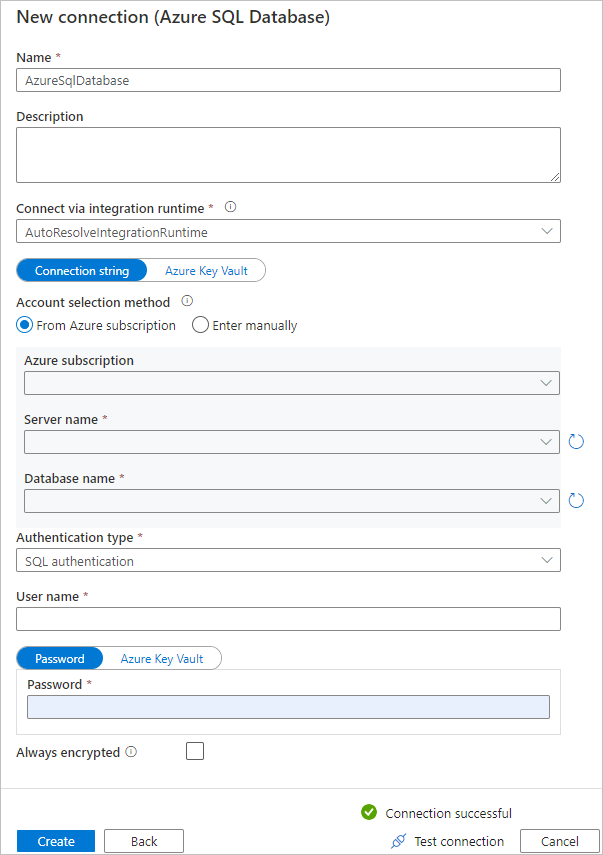
д. Выберите созданную связанную службу в качестве приемника, а затем нажмите кнопку Далее.
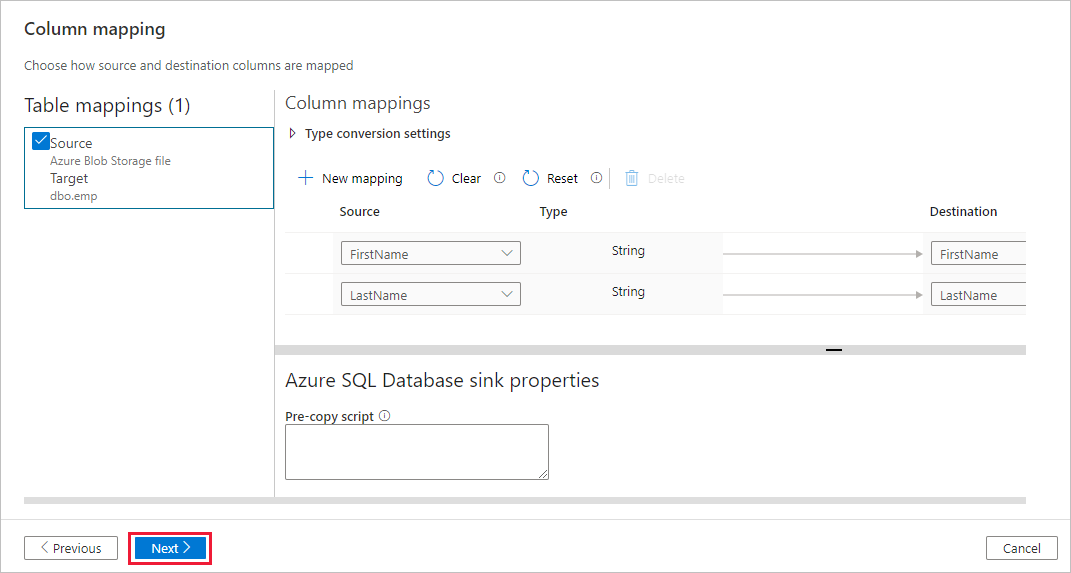
На странице "Целевое хранилище данных" выберите "Использовать существующую таблицу " и выберите таблицу
dbo.emp. Затем выберите Далее.На странице Сопоставление столбцов вы можете увидеть, что второй и третий столбцы файла входных данных сопоставлены со столбцами FirstName и LastName в таблице EMP. Измените сопоставление, чтобы убедиться в отсутствии ошибок, а затем выберите Далее.
На странице Параметры в разделе Имя задачи введите имя CopyFromBlobToSqlPipeline, а затем нажмите кнопку Далее.
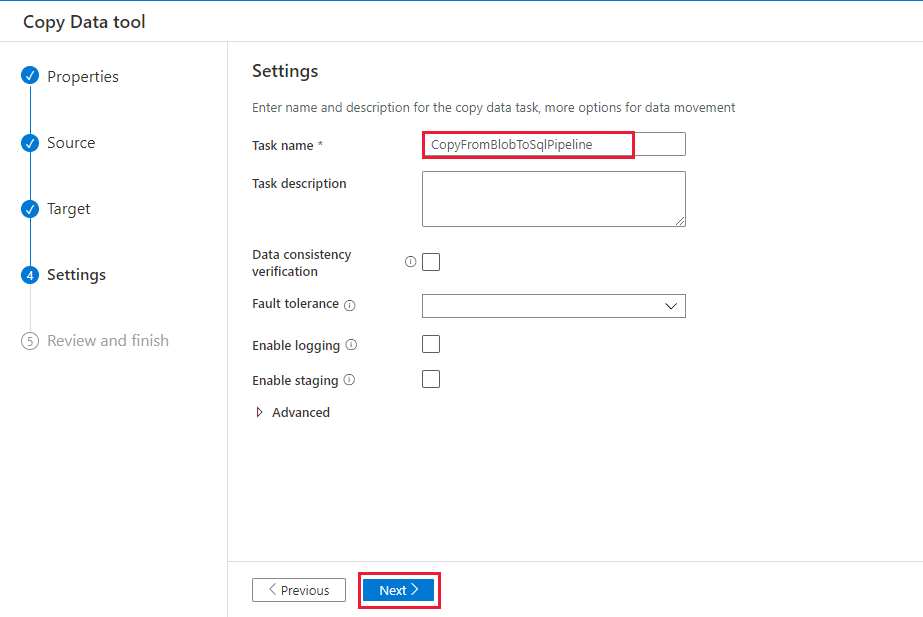
Просмотрите параметры на странице Сводка, а затем нажмите кнопку Далее.
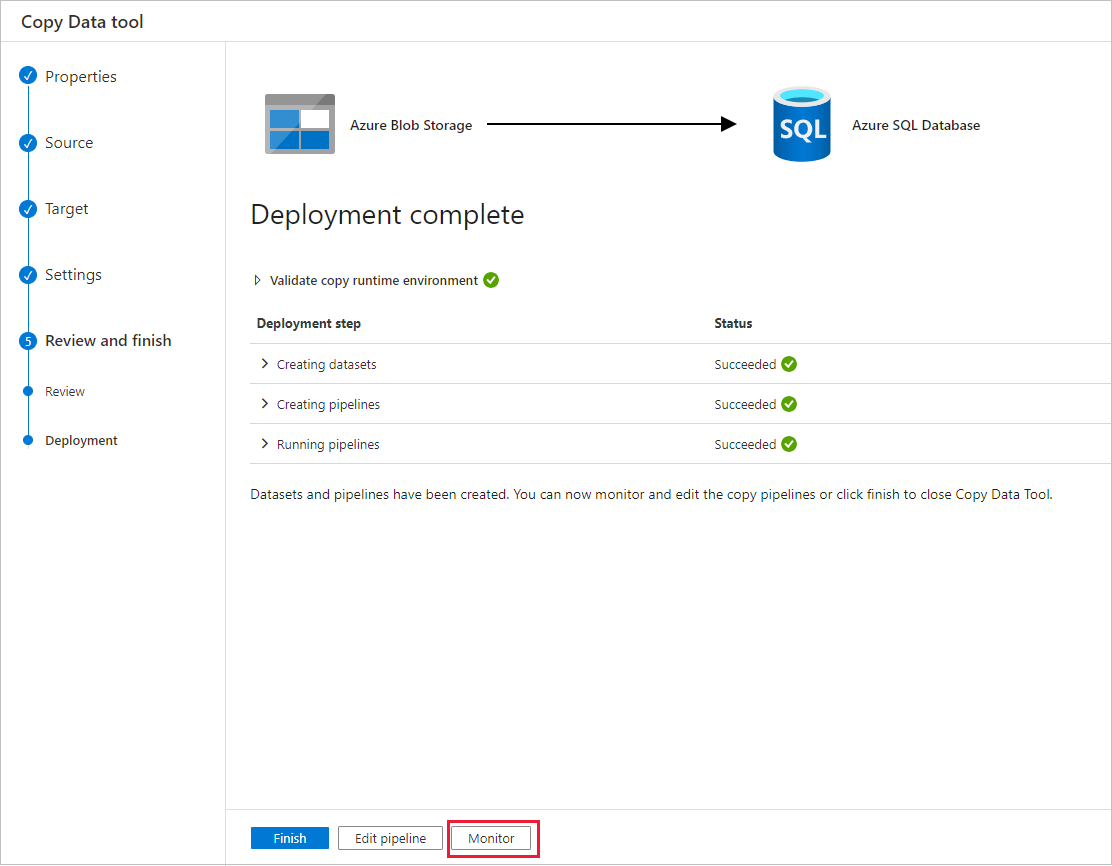
На странице Развертывание выберите Мониторинг, чтобы отслеживать созданный конвейер (задачу).
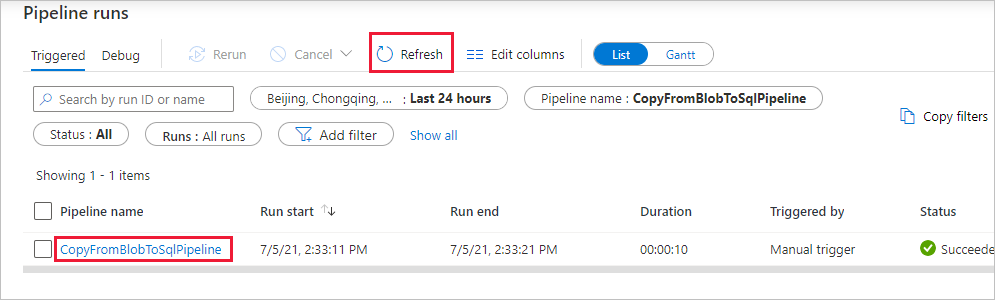
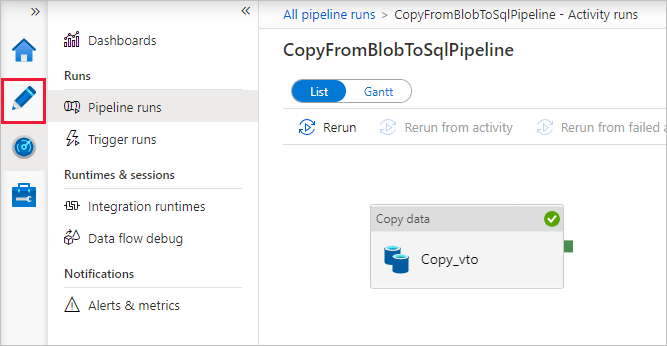
На странице "Запуски конвейера" выберите Обновить, чтобы обновить список. Щелкните ссылку в разделе Имя конвейера, чтобы просмотреть сведения о выполнении действия или перезапустить конвейер.
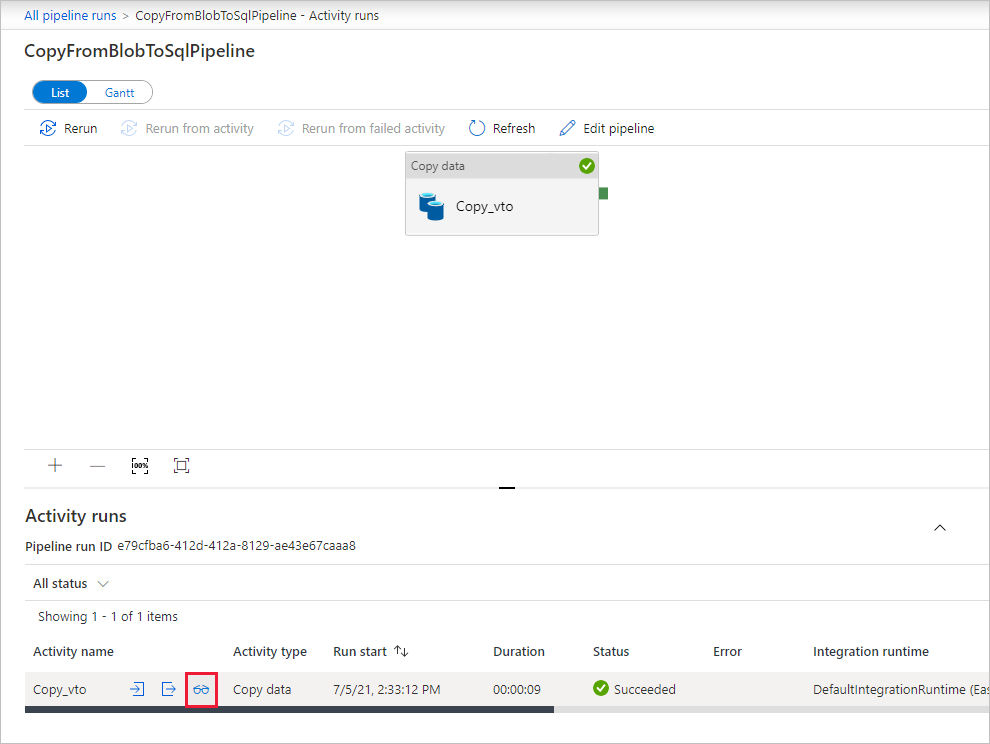
На странице "Запуски активности" выберите ссылку Сведения (значок очков) в столбце Название активности, чтобы получить больше информации об операции копирования. Чтобы вернуться к представлению "Запуски конвейера", в меню навигации щелкните ссылку Все запуски конвейеров. Чтобы обновить список, нажмите кнопку Обновить.
Убедитесь, что данные вставлены в таблицу dbo.emp в Базе данных SQL.
Выберите вкладку Автор слева, чтобы переключиться в режим правки. В этом редакторе вы можете обновлять параметры связанных служб, наборов данных и конвейеров, созданных с помощью средства. Дополнительные сведения о редактировании этих сущностей с помощью пользовательского интерфейса фабрики данных вы найдете в версии этого руководства для портала Azure.
Связанный контент
Поток данных в этом примере копирует данные из BLOB-хранилища в базу данных SQL. Вы научились выполнять следующие задачи:
- Создали фабрику данных.
- Используйте инструмент копирования данных для создания конвейера.
- Следите за процессом конвейера и выполнением активностей.
Перейдите к следующему руководству, чтобы узнать о копировании данных из локальной среды в облако: