Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Примечание.
В этой статье рассматривается инструмент Databricks Connect, предназначенный для Databricks Runtime 13.3 LTS и более поздних версий.
Databricks Connect позволяет подключать популярные среды разработки, такие как IntelliJ IDEA, серверы блокнотов и другие пользовательские приложения к кластерам Azure Databricks. См. раздел "Что такое Databricks Connect?".
В этой статье демонстрируется, как быстро приступить к работе с Databricks Connect для Scala, используя IntelliJ IDEA и плагин Scala .
- Сведения о версии Python этой статьи см. в разделе Databricks Connect для Python.
- Сведения о версии R этой статьи см. в разделе Databricks Connect для R.
Учебник
В следующем руководстве вы создадите проект в IntelliJ IDEA, установите Databricks Connect для Databricks Runtime 13.3 LTS и более поздних версий и выполните простой код для вычислений в рабочей области Databricks из IntelliJ IDEA. Дополнительную информацию и примеры см. в разделе Далее.
Требования
Чтобы завершить работу с этим руководством, необходимо выполнить следующие требования:
Целевая рабочая область Azure Databricks и кластер должны соответствовать требованиям к вычислениям для Databricks Connect.
У вас должен быть доступный идентификатор кластера. Чтобы получить идентификатор кластера, в рабочей области щелкните "Вычислить " на боковой панели и выберите имя кластера. В адресной строке веб-браузера скопируйте строку символов между
clustersиconfigurationв URL-адресе.Локальная среда и вычислительные ресурсы соответствуют требованиям к версии установки Databricks Connect для Scala.
На компьютере разработки установлен пакет средств разработки Java (JDK). Databricks рекомендует, чтобы версия установки JDK соответствовала версии JDK в кластере Azure Databricks. Чтобы узнать версию JDK среды выполнения Databricks в кластере, обратитесь к разделу Системная среда в заметках о выпуске Databricks Runtime или воспользуйтесь матрицей поддержки версий.
Примечание.
Если у вас нет JDK или на компьютере разработки установлено несколько JDK, можно установить или выбрать определенный JDK позже на шаге 1. Выбор установки JDK, которая находится ниже или выше версии JDK в кластере, может привести к непредвиденным результатам, или код может не выполняться вообще.
Установлен IntelliJ IDEA . Это руководство было протестировано с помощью IntelliJ IDEA Community Edition 2023.3.6. Если вы используете другую версию или выпуск IntelliJ IDEA, следующие инструкции могут отличаться.
У вас установлен плагин Scala для IntelliJ IDEA.
Шаг 1. Настройка проверки подлинности Azure Databricks
В этом руководстве используется аутентификация Azure Databricks с помощью OAuth-аутентификации пользователь-машина (U2M) и профиля конфигурации Azure Databricks для подключения к рабочей области Azure Databricks. Чтобы использовать другой тип проверки подлинности, см. раздел "Настройка свойств подключения".
Для настройки проверки подлинности OAuth U2M требуется интерфейс командной строки Databricks, как показано ниже.
Если он еще не установлен, установите Databricks CLI следующим образом:
Linux, macOS
Используйте Homebrew для установки интерфейса командной строки Databricks, выполнив следующие две команды:
brew tap databricks/tap brew install databricksВиндоус
Вы можете использовать winget, Chocolatey или Подсистема Windows для Linux (WSL) для установки CLI Databricks. Если вы не можете использовать
winget, Chocolatey или WSL, следует пропустить эту процедуру и использовать командную строку или PowerShell для установки командной утилиты Databricks из исходного кода.Примечание.
Установка интерфейса командной строки Databricks с помощью Chocolatey является экспериментальной.
Чтобы установить
wingetDatabricks CLI, выполните следующие две команды, а затем перезапустите командную строку (Command Prompt):winget search databricks winget install Databricks.DatabricksCLIЧтобы использовать Chocolatey для установки интерфейса командной строки Databricks, выполните следующую команду:
choco install databricks-cliЧтобы использовать WSL для установки интерфейса командной строки Databricks:
Установите
curlиzipчерез WSL. Дополнительные сведения см. в документации по операционной системе.Используйте WSL для установки интерфейса командной строки Databricks, выполнив следующую команду:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Убедитесь, что интерфейс командной строки Databricks установлен, выполнив следующую команду, которая отображает текущую версию установленного интерфейса командной строки Databricks. Эта версия должна быть 0.205.0 или более поздней:
databricks -vПримечание.
Если вы выполняете
databricks, но получаете ошибку, такую какcommand not found: databricks, или если вы запускаетеdatabricks -v, а указываемый номер версии равен 0.18 или ниже, это означает, что ваш компьютер не может найти правильную версию исполняемого файла интерфейса командной строки Databricks. Чтобы устранить эту проблему, см. Проверка установки CLI.
Инициируйте проверку подлинности OAuth U2M следующим образом:
Используйте Databricks CLI для управления токенами OAuth на локальной машине, выполнив следующую команду для каждой целевой рабочей области.
В следующей команде замените
<workspace-url>на URL-адрес для рабочей области Azure Databricks, напримерhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Интерфейс командной строки Databricks предлагает сохранить сведения, введенные в качестве профиля конфигурации Azure Databricks. Нажмите,
Enterчтобы принять предлагаемое имя профиля, или введите имя нового или существующего профиля. Любой существующий профиль с тем же именем перезаписывается с введенными сведениями. Профили можно использовать для быстрого переключения контекста проверки подлинности в нескольких рабочих областях.Чтобы получить список существующих профилей в отдельном терминале или командной строке, используйте интерфейс командной строки Databricks для выполнения команды
databricks auth profiles. Чтобы просмотреть существующие параметры конкретного профиля, выполните командуdatabricks auth env --profile <profile-name>.В веб-браузере выполните инструкции на экране, чтобы войти в рабочую область Azure Databricks.
В списке доступных кластеров, которые отображаются в терминале или командной строке, используйте клавиши СТРЕЛКА ВВЕРХ и СТРЕЛКА ВНИЗ, чтобы выбрать целевой кластер Azure Databricks в рабочей области, а затем нажмите клавишу
Enter. Вы также можете ввести любую часть отображаемого имени кластера, чтобы отфильтровать список доступных кластеров.Чтобы просмотреть текущее значение маркера OAuth профиля и метку времени окончания срока действия маркера, выполните одну из следующих команд:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Если у вас есть несколько профилей с одинаковым значением
--host, может потребоваться указать параметры--hostи-pвместе, чтобы помочь Databricks CLI найти правильные сведения о маркере OAuth.
Шаг 2. Создание проекта
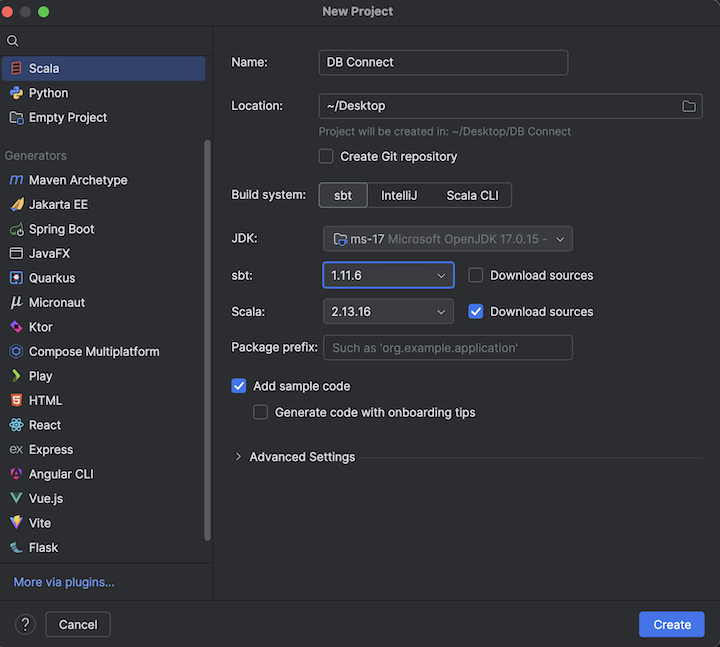
Запустите IntelliJ IDEA.
В главном меню нажмите Файл > Создать > Проект.
Присвойте проекту определенное понятное имя.
В поле "Расположение" щелкните значок папки и заполните инструкции на экране, чтобы указать путь к новому проекту Scala.
Для языка нажмите кнопку Scala.
Для создания системы щелкните sbt.
В раскрывающемся списке JDK выберите существующую установку JDK на компьютере разработки, соответствующую версии JDK в кластере, или нажмите кнопку "Скачать JDK" и следуйте инструкциям на экране, чтобы скачать JDK, соответствующий версии JDK в кластере. См. Требования.
Примечание.
Выбор установки JDK выше или ниже версии JDK в кластере может привести к непредвиденным результатам, или код может не выполняться вообще.
В раскрывающемся списке sbt выберите последнюю версию.
В раскрывающемся списке Scala выберите версию Scala, которая соответствует версии Scala в кластере. См. Требования.
Примечание.
Выбор версии Scala, которая находится ниже или выше версии Scala в кластере, может привести к непредвиденным результатам, или код может не выполняться вообще.
Убедитесь, что установлен флажок "Скачать источники" рядом с Scala.
В качестве префикса пакета введите значение префикса пакета для источников проекта, например
org.example.application.Убедитесь, что установлен флажок "Добавить пример кода ".
Нажмите кнопку Создать.
Шаг 3. Добавление пакета Databricks Connect
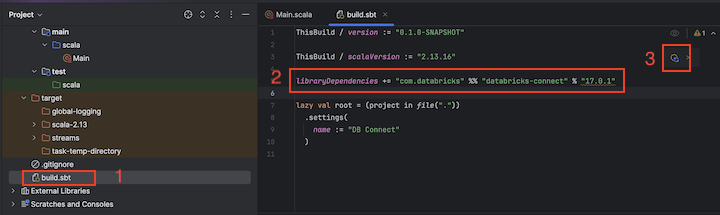
При открытом новом проекте Scala в инструментальном окне Проект (Вид > Инструментальные окна > Проект), откройте файл с именем
build.sbt, в project-name> target.Добавьте следующий код в конец
build.sbtфайла, который объявляет зависимость проекта от определенной версии библиотеки Databricks Connect для Scala, совместимой с версией среды выполнения Databricks в кластере:libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"Замените
14.3.1версию библиотеки Databricks Connect, которая соответствует версии Databricks Runtime в кластере. Например, Databricks Connect 14.3.1 соответствует Databricks Runtime 14.3 LTS. Номера версий библиотеки Databricks Connect можно найти в центральном репозитории Maven.Щелкните значок уведомления «Загрузить изменения sbt», чтобы обновить ваш проект Scala с новым расположением библиотеки и зависимостями.
Дождитесь, пока
sbtиндикатор хода выполнения не исчезнет в нижней части интегрированной среды разработки. Процессsbtзагрузки может занять несколько минут.
Шаг 4. Добавление кода
В окне инструмента Project откройте файл с именем
Main.scala, в project-name> src > main > scala.Замените существующий код в файле следующим кодом, а затем сохраните файл в зависимости от имени профиля конфигурации.
Если профиль конфигурации из шага 1 называется
DEFAULT, замените существующий код в файле следующим кодом, а затем сохраните файл:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Если профиль конфигурации из шага 1 не называется
DEFAULT, замените существующий код в файле следующим кодом. Замените заполнитель<profile-name>именем профиля конфигурации на шаге 1, а затем сохраните файл:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
Шаг 5. Запуск кода
- Запустите целевой кластер в удаленной рабочей области Azure Databricks.
- После запуска кластера в главном меню нажмите кнопку "Запустить > main".
- В окне Run (Вид > Окна инструментов > Run), на вкладке Main отображаются первые 5 строк таблицы
samples.nyctaxi.trips.
Шаг 6. Отладка кода
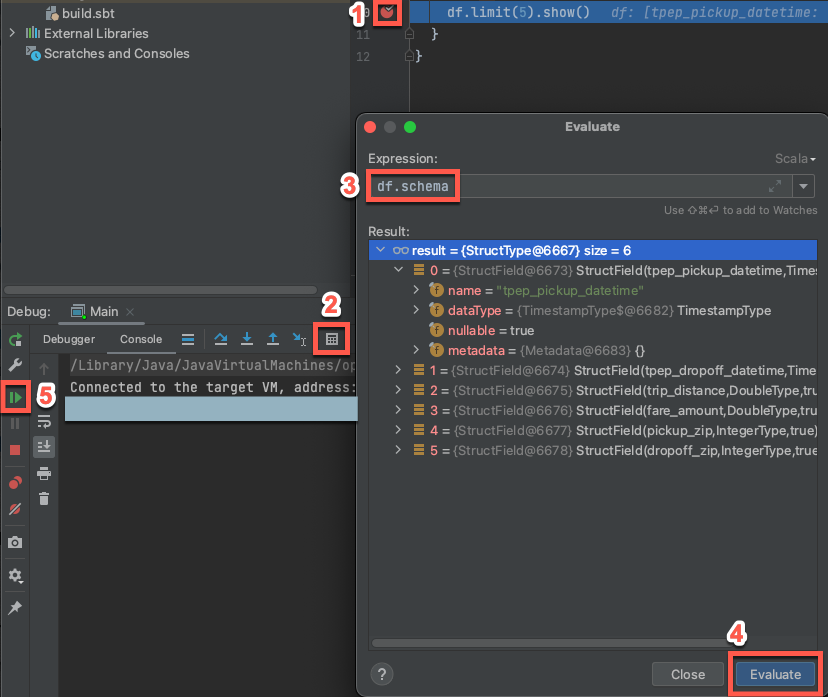
- Если целевой кластер по-прежнему запущен, в указанном коде щелкните в поле рядом с
df.limit(5).show(), чтобы установить точку останова. - В главном меню нажмите "Запустить > отладку 'Main'".
- В окне инструмента , на вкладке >, щелкните значок калькулятора (>).
- Введите выражение
df.schemaи нажмите кнопку "Оценить ", чтобы отобразить схему кадра данных. - На боковой панели окна средства отладки щелкните значок зеленой стрелки (возобновить программу).
-
В области консоли отображаются первые 5 строк
samples.nyctaxi.tripsтаблицы.
Следующие шаги
Дополнительные сведения о Databricks Connect см. в следующих статьях:
- Сведения об использовании типов проверки подлинности Azure Databricks, отличных от маркера личного доступа Azure Databricks, см. в разделе "Настройка свойств подключения".
- Чтобы просмотреть дополнительные простые примеры кода, смотрите Примеры кода для Databricks Connect для Scala.
- Дополнительные примеры кода см. в примерах приложений для репозитория Databricks Connect в GitHub, в частности:
- Чтобы перейти с Databricks Connect для Databricks Runtime 12.2 LTS и ниже на Databricks Connect для Databricks Runtime 13.3 LTS и более поздних версий, см. Миграция на Databricks Connect для Scala.
- См. также сведения об устранении неполадок и ограничениях.