Что такое Azure HDInsight?
Azure HDInsight — это управляемая комплексная облачная служба аналитики с открытым кодом, предназначенная для предприятий. С помощью HDInsight можно использовать платформы с открытым кодом, такие как Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop и т. д. в среде Azure.
Что такое HDInsight и технологическая платформа Hadoop?
Azure HDInsight — это управляемая платформа кластера, которая упрощает запуск платформ больших данных, таких как Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop и других платформ в среде Azure. Он предназначен для обработки больших объемов данных с высокой скоростью и эффективностью.
Почему следует использовать Azure HDInsight
| Возможность | Description |
|---|---|
| Полностью облачное решение | Azure HDInsight позволяет создавать оптимизированные кластеры для Spark, интерактивного запроса (LLAP), Kafka, HBase и Hadoop в Azure. HDInsight также предоставляет полное соглашение об уровне обслуживания для всех рабочих нагрузок. |
| Экономия и масштабируемость | HDInsight позволяет увеличивать и уменьшать масштаб рабочих нагрузок. Чтобы сократить затраты, создавайте кластеры по требованию и платите только за те ресурсы, которые используете. Вы также можете создавать конвейеры данных, чтобы реализовать задания. Разделение сред вычисления и хранения повышает производительность и гибкость. |
| Безопасность и соответствие нормативам | HDInsight позволяет защитить корпоративные ресурсы данных с помощью Azure виртуальная сеть, шифрования и интеграции с идентификатором Microsoft Entra. HDInsight также соответствует наиболее распространенным отраслевым и государственным стандартам. |
| Наблюдение | Azure HDInsight интегрируется с журналами Azure Monitor и предоставляет единый интерфейс для мониторинга всех кластеров. |
| Глобальная доступность | Служба HDInsight доступна в большем числе регионов, чем любое другое предложение аналитики больших данных. Служба Azure HDInsight также доступна в Azure для государственных организаций, Китая и Германии, что позволяет обеспечить соответствие требованиям организации в основных независимых регионах. |
| Продуктивность | Azure HDInsight предоставляет многофункциональные наборы инструментов, которые повышают эффективность работы, для Hadoop и Spark в предпочитаемой среде разработки. К этим средам разработки относятся Visual Studio, VS Code, Eclipse и IntelliJ для Scala, Python, Java и .NET. |
| Расширяемость | Чтобы расширить кластеры HDInsight, вы можете устанавливать компоненты (Hue, Presto и т. д.) с помощью действий скриптов, добавлять граничные узлы или выполнять интеграцию с другими сертифицированными приложениями для обработки больших данных. HDInsight обеспечивает прозрачную интеграцию с наиболее распространенными решениями для больших данных с помощью развертывания одним щелчком. |
Что такое большие данные?
Большие данные в различных форматах объединяются в крупные тома с большей скоростью обработки, чем когда-либо. Такие данные могут быть историческими (хранимыми) или в реальном времени (потоковая передача из источника). Наиболее распространенные варианты использования больших данных см. в разделе о Сценарии использования HDInsight.
Типы кластеров в HDInsight
HDInsight включает определенные типы кластеров и возможности их настройки, такие как добавление компонентов, служебных программ и языков. HDInsight предлагает следующие типы кластеров.
| Тип кластера | Description | Начать |
|---|---|---|
| Apache Hadoop | Платформа, в которой используется управление ресурсами HDFS и YARN, а также простая модель программирования MapReduce для параллельной обработки и анализа пакетных данных. | Создание кластера Apache Hadoop |
| Apache Spark | Платформа параллельной обработки с открытым кодом, которая поддерживает обработку в памяти, чтобы повысить производительность приложений для анализа больших данных. Дополнительные сведения см. в обзоре по Apache Spark в HDInsight. | Создание кластера Apache Spark |
| Apache HBase | База данных NoSQL, созданная на основе Hadoop и обеспечивающая прямой доступ и строгую согласованность для больших объемов неструктурированных и частично структурированных данных (с потенциальным размером таблиц в миллиарды строк и миллионы столбцов). Дополнительные сведения см. в статье Что такое HBase в HDInsight: база данных NoSQL, которая предоставляет возможности, схожие BigTable, для Hadoop. | Создание кластера Apache HBase |
| Apache Interactive Query | Кэширование в памяти для обеспечения интерактивных и ускоренных запросов Hive. См. инструкции по использованию Interactive Query в HDInsight. | Создание кластера интерактивных запросов |
| Apache Kafka | Платформа с открытым исходным кодом используется для создания конвейеров и приложений потоковой передачи данных. Kafka также предоставляет функциональные возможности очереди сообщений, с помощью которых можно публиковать потоки данных и подписываться на них. См. статью Введение в Apache Kafka в HDInsight (предварительная версия). | Создание кластера Apache Kafka |
Сценарии использования HDInsight
Azure HDInsight можно применять в различных сценариях обработки больших данных. Это могут быть исторические данные (данные, которые уже собираются и хранятся) или данные в режиме реального времени (данные, которые передаются непосредственно из источника). Сценарии обработки таких данных можно представить в указанных ниже категориях.
Пакетная обработка (ETL)
Извлечение, преобразование и загрузка — это процесс, при котором неструктурированные или структурированные данные извлекаются из разнородных источников данных. Затем они структурируются и загружаются в хранилище данных. Преобразованные данные могут применяться для обработки и анализа или в хранилище данных.
Хранение данных
При помощи HDInsight вы можете выполнять интерактивные запросы структурированных и неструктурированных данных в любом формате и объемом в несколько петабайт. Также можно создавать модели и подключать их к средствам бизнес-аналитики.
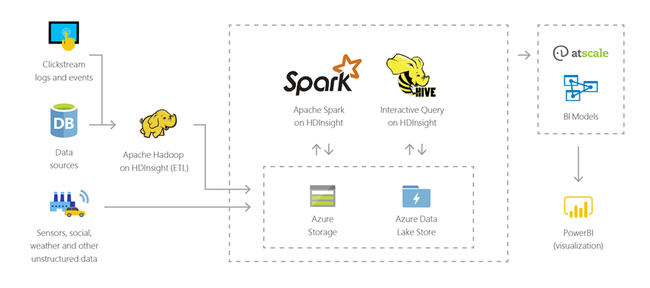
Интернет вещей (IoT)
HDInsight можно использовать для обработки потоковых данных, полученных в режиме реального времени от различных типов устройств. Чтобы узнать больше, прочтите эту запись блога Azure, представляющую собой объявление о выходе общедоступной предварительной версии Apache Kafka в HDInsight с управляемыми дисками Azure.
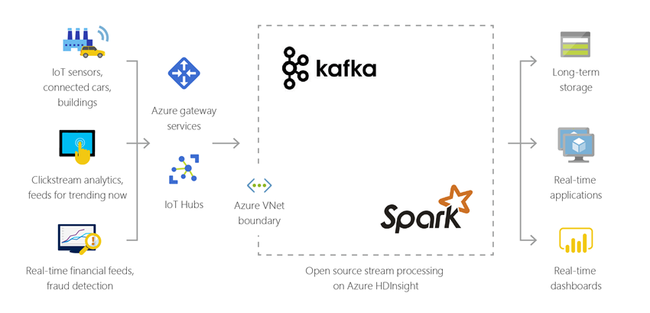
Гибридный трафик
С помощью HDInsight вы можете расширить локальную инфраструктуру для работы с большими данными в Azure и применять возможности расширенной аналитики, доступные в облаке.
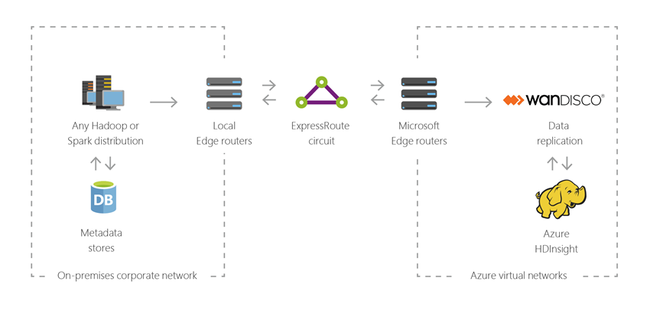
Компоненты HDInsight с открытым кодом
Azure HDInsight позволяет создавать кластеры с платформами с открытым кодом, такими как Spark, Hive, LLAP, Kafka, Hadoop и HBase. По умолчанию эти кластеры включают различные компоненты с открытым кодом, такие как Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie и Apache ZooKeeper.
Языки программирования, поддерживаемые в HDInsight
Кластеры HDInsight, в том числе Spark, HBase, Kafka, Hadoop и другие, поддерживают несколько языков программирования. Не все языки программирования устанавливаются по умолчанию. Для установки библиотек, модулей или пакетов, которые не установлены по умолчанию, используйте действие скрипта.
| Язык программирования | Информация |
|---|---|
| Поддержка языков программирования по умолчанию | По умолчанию кластеры HDInsight поддерживают следующие языки:
|
| Языки виртуальных машин Java | На виртуальной машине Java могут работать многие другие языки. Однако при запуске некоторых из этих языков вам может потребоваться установить дополнительные компоненты в кластере. В кластерах HDInsight поддерживаются следующие языки на основе JVM:
|
| Языки для Hadoop | Кластеры HDInsight поддерживают следующие языки, относящиеся к стеку технологий Hadoop:
|
Средства разработки для HDInsight
Вы можете создавать и отправлять запросы данных HDInsight и задания с помощью таких средств разработки HDInsight, как IntelliJ, Eclipse, Visual Studio Code и Visual Studio, просто интегрировав их с Azure.
- Набор средств Azure для IntelliJ 10
- Набор средств Azure для Eclipse 6
- Средства Azure HDInsight для VS Code 13
- Средства озера данных Azure для Visual Studio 9
Бизнес-аналитика в HDInsight
Знакомые инструменты бизнес-аналитики позволяют получать и анализировать данные, а также составлять на их основе отчеты в тесной интеграции с HDInsight с помощью надстройки Power Query или драйвера Microsoft Hive ODBC.
Использование средств визуализации данных с помощью Apache Spark BI в Azure HDInsight.
Визуализация данных Apache Hive с Microsoft Power BI с использованием ODBC в Azure HDInsight
Visualize Interactive Query Hive data with Microsoft Power BI using DirectQuery in Azure HDInsight (Визуализация данных Hive из кластера Interactive Query с помощью Microsoft Power BI и DirectQuery в Azure HDInsight)
Подключение Excel к Apache Hadoop с помощью Power Query (требуется Windows)
Подключение Excel к Apache Hadoop с помощью Microsoft Hive ODBC Driver (требуется Windows)
Место расположения данных в регионе
Spark, Hadoop и LLAP не хранят данные клиентов, поэтому эти службы автоматически удовлетворяют требованиям к месту расположения данных в регионе, указанным в Центре управления безопасностью.
В Kafka и HBase хранятся данные клиентов. Эти данные автоматически хранятся в Kafka и HBase в одном регионе, поэтому эта служба удовлетворяет требованиям к месту расположения данных в регионе, указанным в Центре управления безопасностью.
Привычные инструменты бизнес-аналитики позволяют получать и анализировать данные, а также составлять на их основе отчеты в тесной интеграции с HDInsight с помощью надстройки Power Query или Microsoft Hive ODBC Driver.