Capacity planning for HDInsight clusters (Планирование загрузки кластеров HDInsight)
Перед развертыванием кластера HDInsight следует спланировать его предполагаемую загрузку, определив необходимые производительность и масштаб. Это помогает оптимизировать удобство использования и затраты. Некоторые решения относительно емкости кластера нельзя изменить после развертывания. В случае изменения параметров производительности кластер можно отключить, а затем повторно создать без потери хранимых в нем данных.
Ниже приведены основные вопросы о планировании загрузки.
- В географическом регионе следует развернуть кластер?
- Какой объем хранилища требуется?
- Какой тип кластера следует выбрать для развертывания?
- Какие размер и тип виртуальной машины следует использовать на узлах кластера?
- Сколько рабочих узлов должен включать в себя кластер?
Выбор региона Azure
Регион Azure определяет место физической подготовки кластера. Чтобы свести к минимуму задержки при чтении и записи, кластер должен быть расположен близко к вашим данным.
Служба HDInsight доступна во многих регионах Azure. Чтобы найти ближайший регион, см. страницу Доступность продуктов по регионам.
Выбор расположения и размера хранилища
Расположение хранилища по умолчанию
Хранилище по умолчанию (учетная запись хранения Azure или Azure Data Lake Storage) должно находиться том же расположении, что и кластер. Служба хранилища Azure доступна во всех расположениях. Data Lake Storage поколения доступно в некоторых регионах. Ознакомьтесь с актуальными сведениями о доступности Data Lake Storage.
Расположение существующих данных
Если вы хотите использовать имеющуюся учетную запись хранения или хранилище Data Lake Storage в качестве хранилища по умолчанию для кластера, то кластер необходимо развернуть в том же расположении.
Объем памяти
К развернутому кластеру можно подключить другие учетные записи службы хранилища Azure. С него также возможен доступ к другим хранилищам Data Lake Storage. Все учетные записи хранения должны находиться в том же расположении, что и кластер. Data Lake Storage может находиться в другом расположении, хотя большие расстояния могут привести к задержкам.
К службе хранилища Azure применяются некоторые ограничения по емкости, тогда как емкость Data Lake Storage поколения практически не ограничена. Кластер может обращаться к разным учетным записям хранения. Типичные примеры использования этой функции:
- когда объем данных, вероятнее всего, превышает емкость одного контейнера больших двоичных объектов;
- когда скорость доступа к контейнеру больших двоичных объектов может превышать пороговое значение, что активирует регулирование;
- когда необходимо, чтобы данные, уже переданные в контейнер больших двоичных объектов, стали доступными для кластера;
- когда требуется изолировать различные части хранилища из соображений безопасности или для упрощения администрирования.
Для повышения производительности используйте только один контейнер на учетную запись хранения.
Выбор типа кластера
Тип кластера определяет рабочую нагрузку, для выполнения которой настроен кластер HDInsight. К типам относятся Apache Hadoop, Apache Kafka или Apache Spark. Подробное описание доступных типов кластеров см. в статье Общие сведения об Azure HDInsight и стеке технологий Hadoop и Spark. Каждый тип кластера имеет определенную топологию развертывания, которая включает в себя требования к размеру и количеству узлов.
Выбор типа и размера виртуальной машины
У каждого типа кластера имеется набор типов узлов, и у каждого типа узла имеются определенные параметры, определяющие размер и тип виртуальной машины.
Чтобы определить оптимальный размер кластера для приложения, можно измерить производительность кластера и увеличить его размер в соответствии с полученными рекомендациями. Например, можно использовать имитацию рабочей нагрузки или запрос предохранителя. Запустите смоделированные рабочие нагрузки в кластерах разных размеров. Постепенно увеличивайте размер до достижения предполагаемой производительности. Запрос предохранителя можно периодически выполнять наряду с прочими рабочими запросами, чтобы определять, достаточно ли в кластере ресурсов.
Дополнительные сведения о выборе подходящего семейства виртуальных машин для рабочей нагрузки см. в статье Выбор подходящего размера виртуальной машины для кластера.
Выбор масштаба кластера
Масштаб кластера определяется количеством его узлов виртуальных машин. Для всех типов кластеров есть типы узлов со специальным масштабом и типы узлов, которые поддерживают развертывание (увеличение масштаба). Например,в кластере может потребоваться строго три узла Apache ZooKeeper или два головных узла. Производительность рабочих узлов, которые выполняют распределенную обработку данных, можно повысить за счет добавления других рабочих узлов.
В зависимости от типа кластера, увеличение числа рабочих узлов увеличивает вычислительную мощность (например, добавляет дополнительные ядра). Дополнительные узлы увеличивают общий объем памяти, необходимый кластеру в целом для поддержки хранения обрабатываемых данных в памяти. Как и в случае выбора размера и типа виртуальной машины, правильный масштаб кластера обычно подбирается эмпирически. Используйте имитации рабочих нагрузок или запросы предохранителя.
Кластер можно увеличивать в соответствии с пиковыми требованиями к нагрузке. Затем можно обратно уменьшать его, когда эти дополнительные узлы больше не нужны. Функция автомасштабирования позволяет автоматически масштабировать кластер на основе предварительно заданных метрик и времени. Дополнительные сведения о масштабировании кластеров вручную см. в статье Масштабирование кластеров HDInsight.
Жизненный цикл кластера
Плата взимается на протяжении времени существования кластера. Если кластер требуется вам только в определенные моменты времени, можно создавать кластеры по требованию с помощью Фабрики данных Azure. Можно также создать сценарии PowerShell, которые подготавливают и удаляют кластер, и запланировать выполнение этих сценариев с помощью службы автоматизации Azure.
Примечание.
При удалении кластера также удаляется его метахранилище Hive по умолчанию. Чтобы сохранить метахранилище для следующего повторного создания кластера, используйте внешнее хранилище метаданных, такое как база данных Azure или Apache Oozie.
Изоляция ошибок заданий кластера
Иногда ошибки могут происходить из-за параллельного выполнения нескольких компонентов maps и reduce в кластере с несколькими узлами. Чтобы выявить причину этой проблемы, попробуйте выполнить распределенное тестирование. Выполнение нескольких параллельных заданий в одном кластере рабочих узлов. Затем расширьте этот подход, чтобы одновременно выполнять по нескольку заданий в кластерах, содержащих несколько узлов. Чтобы создать кластер HDInsight с одним узлом в Azure, используйте параметр Custom(size, settings, apps) и значение 1 для Количества рабочих узлов в разделе Размер кластера при подготовке нового кластера на портале.
Просмотр управления квотами для HDInsight
Просмотр детализированного уровня и классификации квоты на уровне семейства виртуальных машин. Просмотрите текущую квоту и сколько квот осталось для региона на уровне семейства виртуальных машин.
Примечание.
Эта функция в настоящее время доступна в HDInsight 4.x и 5.x для региона EUAP восточной части США. Далее следуют другие регионы.
Просмотр текущей квоты:
Просмотрите текущую квоту и сколько квот осталось для региона на уровне семейства виртуальных машин.
В портал Azure в верхней строке поиска найдите и выберите "Квоты".
На странице "Квота" выберите Azure HDInsight
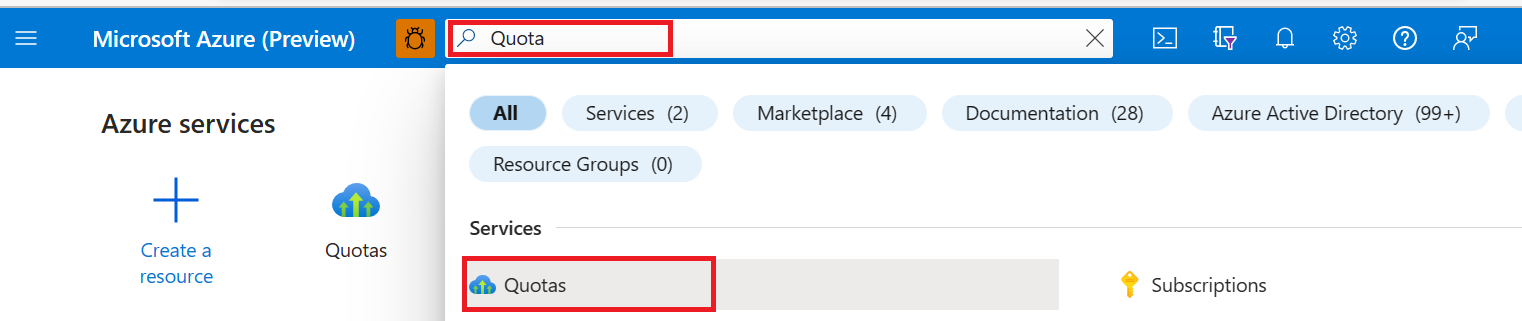
В раскрывающемся списке выберите подписку и регион
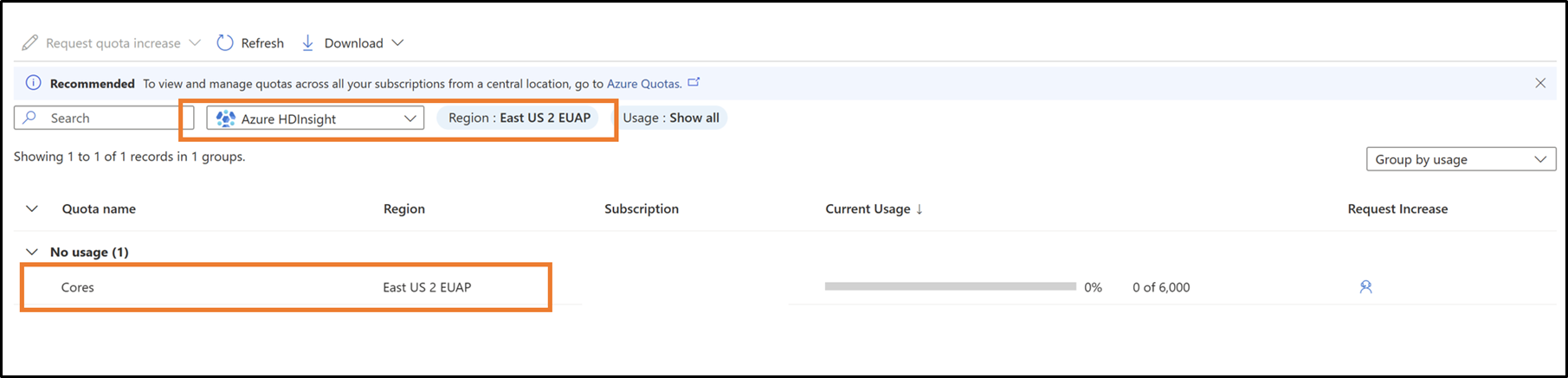
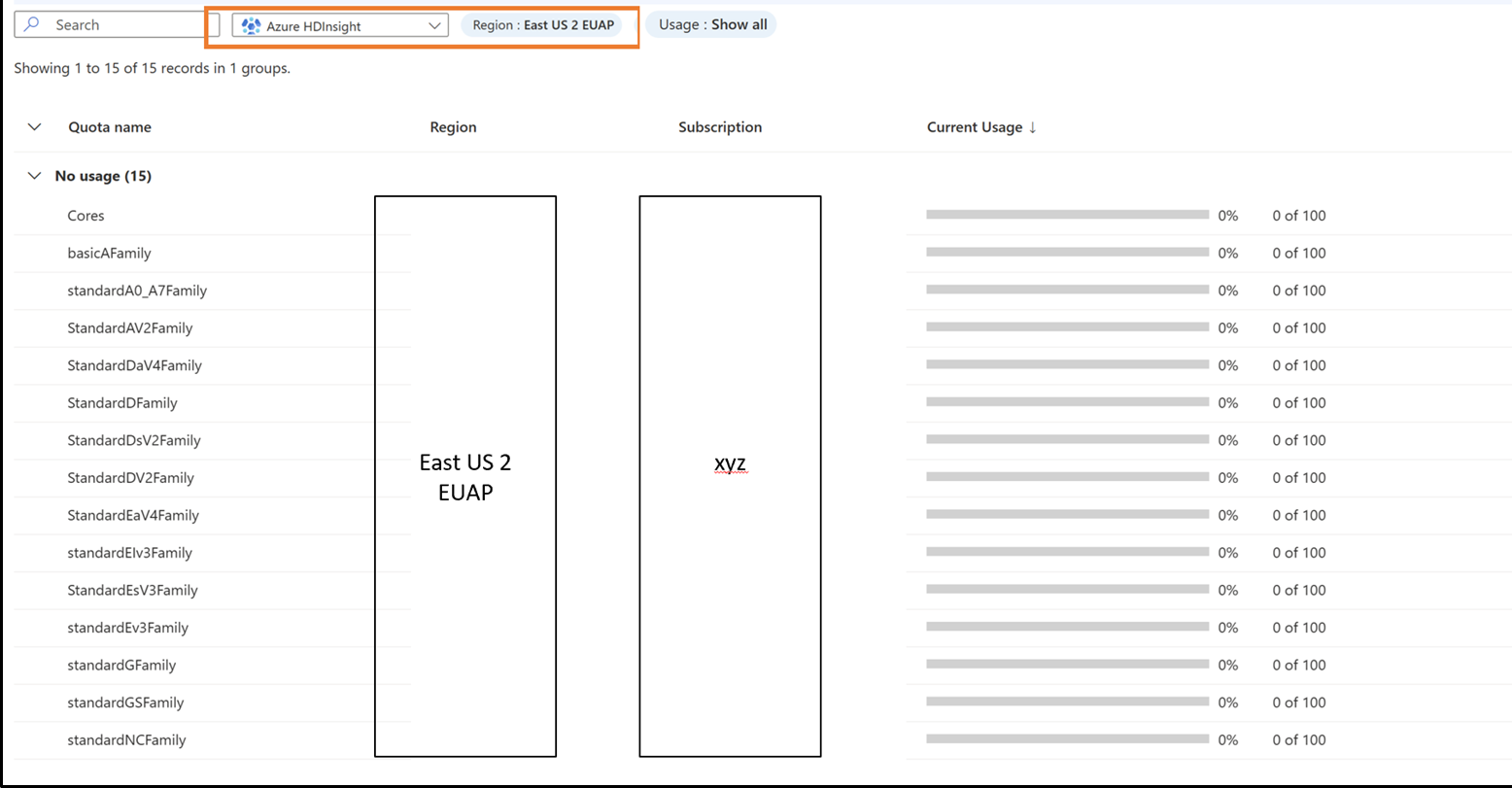
Запрос новых квот для семейства виртуальных машин и региона
- Щелкните строку, для которой нужно просмотреть сведения о квоте.
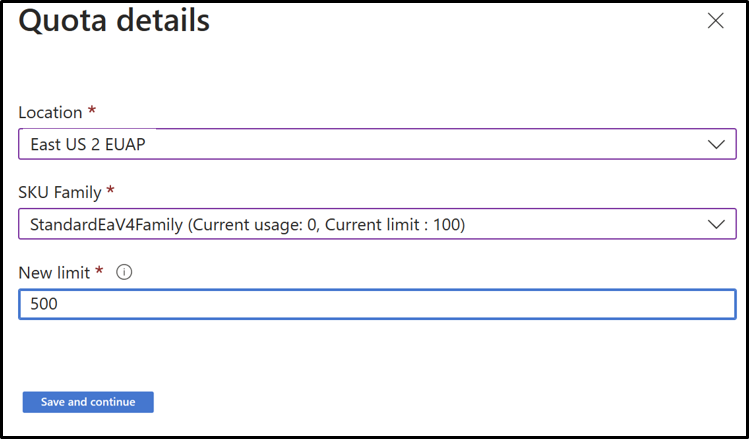




Планы продаж
Дополнительные сведения об управлении квотами подписки см. в разделе Запрос на увеличение квоты.
Следующие шаги
- Настройка кластеров в HDInsight с помощью Apache Hadoop, Spark, Kafka и т. д. Узнайте, как настроить и настроить кластеры в HDInsight.
- Мониторинг производительности кластера: изучите основные сценарии, которые могут влиять на емкость кластера HDInsight и требуют его мониторинга.