Отладка заданий Apache Spark в Azure HDInsight
Эта статья содержит сведения о том, как выполнять отслеживание и отладку заданий Apache Spark, выполняющихся в кластерах HDInsight. Отладка с помощью пользовательского интерфейса Apache Hadoop YARN, пользовательского интерфейса Spark и сервера журнала Spark. Вы создадите задание Spark с помощью записной книжки, прилагающейся к кластеру Spark: Машинное обучение. Прогнозный анализ на основе данных контроля качества пищевых продуктов. С помощью описанных ниже действий можно отслеживать приложение, отправленное любым другим методом, например с помощью spark-submit.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark.
Для начала вам следует запустить записную книжку Машинное обучение. Прогнозный анализ на основе данных контроля качества пищевых продуктов. Перейдите по ссылке, чтобы получить инструкции по запуску этой записной книжки.
Отслеживание приложения в пользовательском интерфейсе YARN
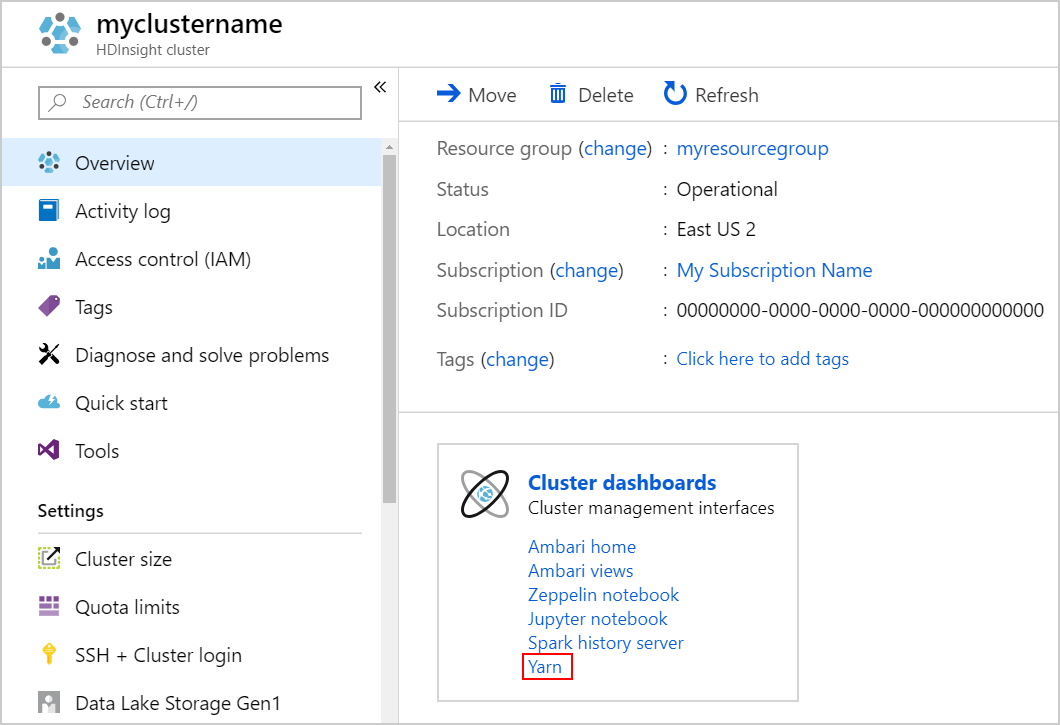
Запустите пользовательский интерфейс YARN. Выберите Yarn в разделе Панели мониторинга кластера.
Совет
Также пользовательский интерфейс YARN можно открыть из пользовательского интерфейса Ambari. Чтобы запустить пользовательский интерфейс Ambari, в разделе Панели мониторинга кластера выберите Домашняя страница Ambari. В пользовательском интерфейсе Ambari перейдите к разделу YARN>Быстрые ссылки> активный Resource Manager > Пользовательский интерфейс Resource Manager.
Так как вы запустили задание Spark с помощью объектов Jupyter Notebook, приложение получило имя remotesparkmagics (это стандартное имя для всех приложений, запускаемых из записных книжек). Выберите идентификатор приложения рядом с именем приложения, чтобы посмотреть дополнительные сведения о задании. Это действие открывает представление приложения.
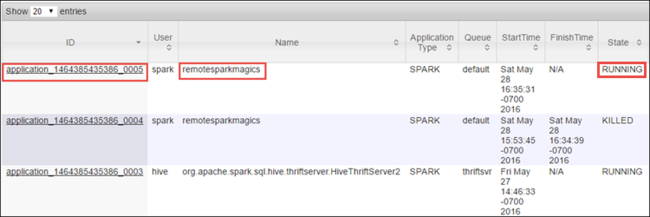
Для приложений, которые запущены из объектов Jupyter Notebook, состояние всегда будет иметь значение Запущено, пока вы не выйдете из записной книжки.
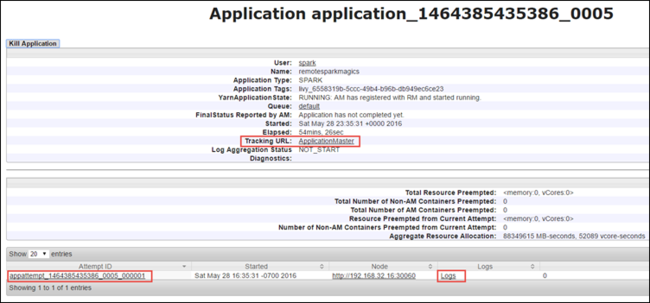
Из представления приложения вы можете ознакомиться с подробными сведениями о контейнерах, связанных с приложением, а также изучить журналы (stdout и stderr). Пользовательский интерфейс Spark можно запустить, щелкнув ссылку в графе URL-адрес отслеживания, как показано ниже.
Отслеживание приложения в пользовательском интерфейсе Spark
В пользовательском интерфейсе Spark вы можете подробно изучить задания Spark, которые создаются запущенным вами приложением.
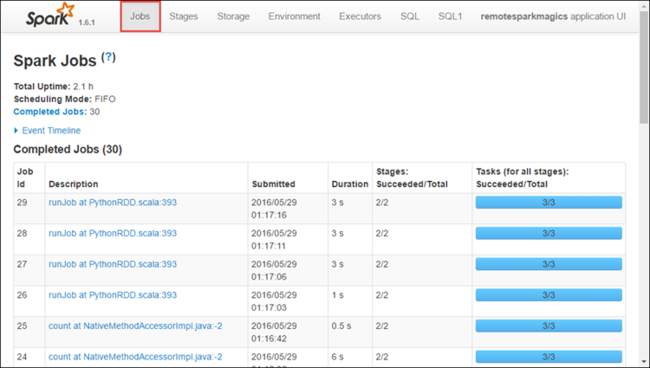
Чтобы запустить пользовательский интерфейс Spark, щелкните ссылку URL-адрес отслеживания в представлении приложения, как показано на снимке экрана выше. Здесь вы увидите все задания Spark, созданные приложением, которое запущено в Jupyter Notebook.
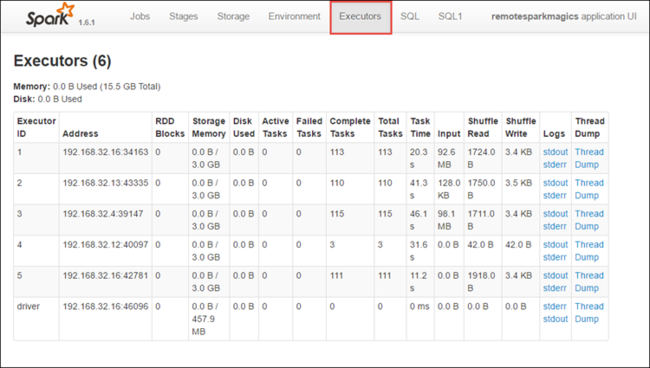
Откройте вкладку Исполнители, чтобы увидеть сведения о вычислениях и хранении для каждого исполнителя. Можно также получить стек вызовов, щелкнув ссылку Дамп потока.
Перейдите на вкладку Этапы, чтобы просмотреть этапы, связанные с приложением.
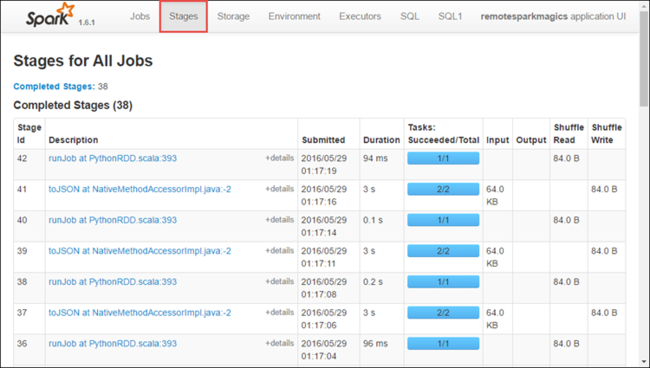
Каждый этап может включать несколько задач. Вы можете просмотреть для них статистику выполнения, как показано ниже.
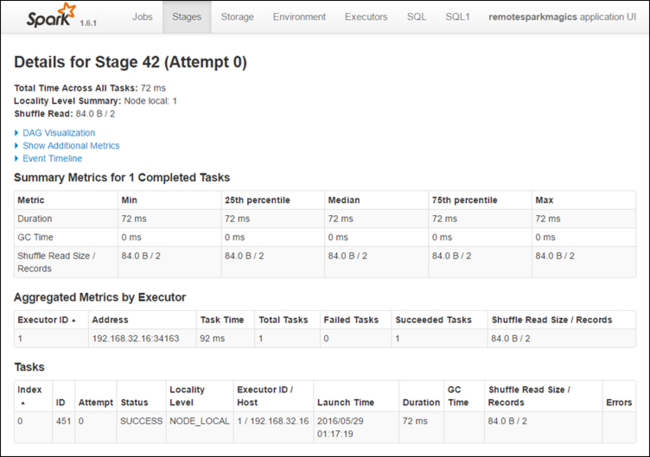
На странице сведений об этапе вы можете открыть визуализацию DAG. Для этого разверните ссылку Визуализация DAG в верхней части страницы, как показано ниже.
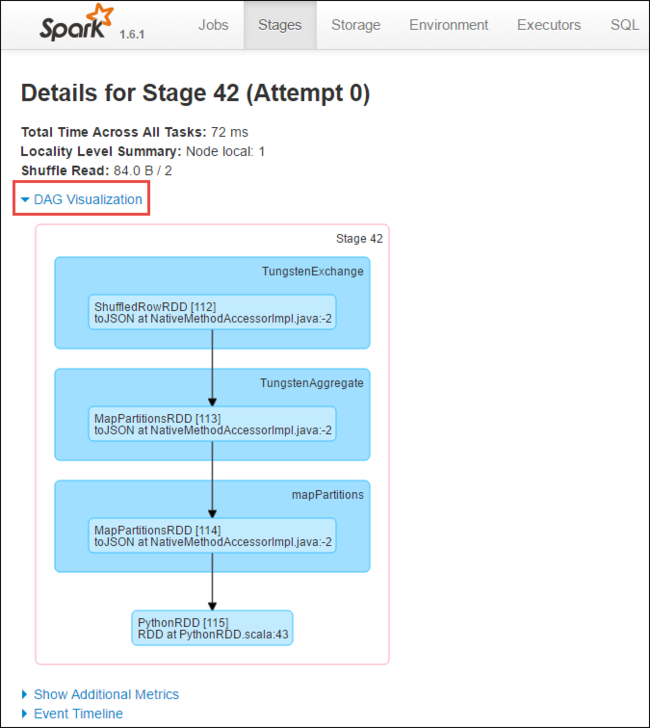
Направленный ациклический граф (DAG) представляет различные этапы в приложении. Каждый синий блок графа соответствует определенной операции Spark, вызываемой из приложения.
На странице сведений об этапах можно также запустить представление временной шкалы для приложения. Для этого разверните ссылку Представление временной шкалы в верхней части страницы, как показано ниже.
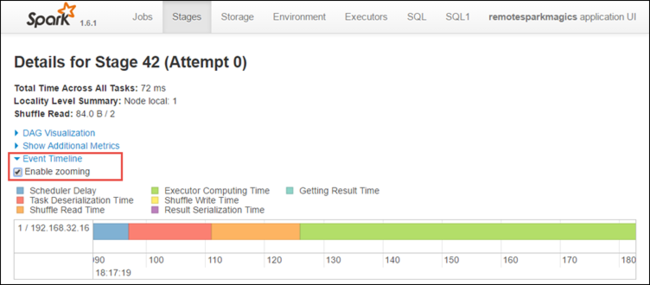
На этом изображении события Spark представлены в формате временной шкалы. Это представление доступно на трех уровнях: для заданий, в пределах одного задания и в пределах этапа. На рисунке выше представлен пример представления временной шкалы для одного этапа.
Совет
Если установить флажок Изменять масштаб , представление временной шкалы можно будет прокручивать влево и вправо.
Другие вкладки в пользовательском интерфейсе Spark содержат полезные сведения о самом экземпляре Spark.
- Вкладка "Хранилище": если приложение создает RDD, соответствующую информацию вы найдете на этой вкладке.
- Вкладка среды. Эта вкладка содержит полезные сведения о экземпляре Spark, например:
- Версия Scala
- каталог журнала событий, связанный с кластером;
- число ядер исполнителя для приложения;
Поиск сведений о выполненных заданиях с помощью сервера журнала Spark
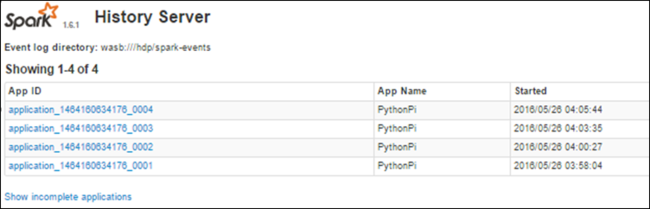
Когда задание завершается, сведения о нем сохраняются на сервере журнала Spark.
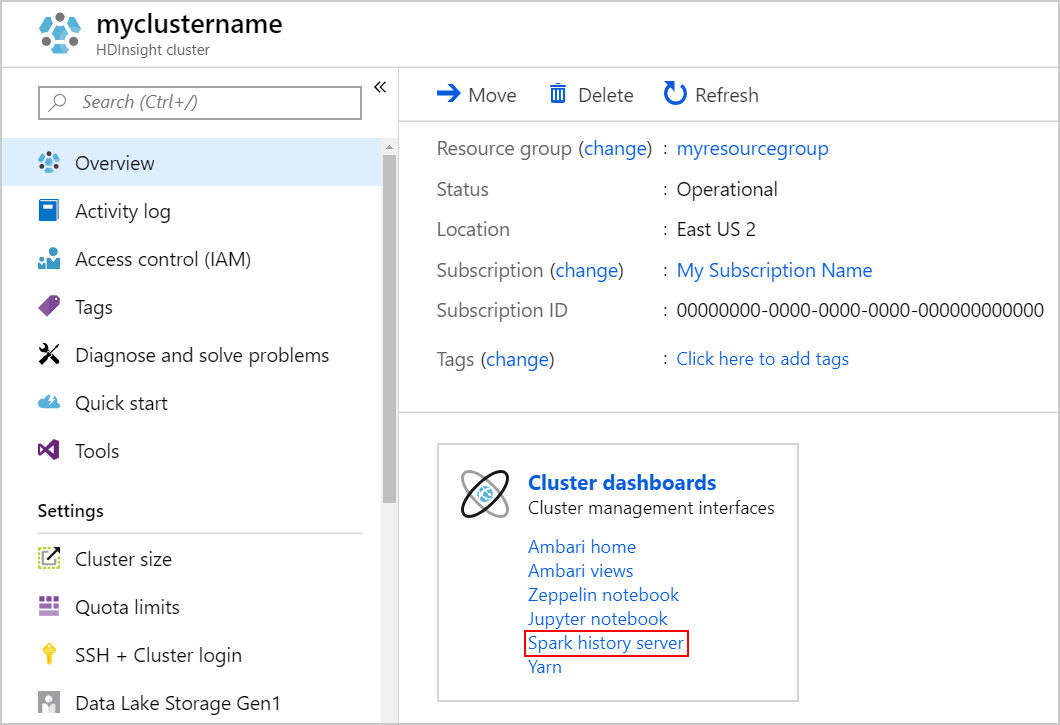
Чтобы открыть сервер журнала Spark, на странице Обзор в разделе Панели мониторинга кластера щелкните Сервер журнала Spark.
Совет
Также пользовательский интерфейс сервера журнала Spark можно открыть из пользовательского интерфейса Ambari. Чтобы запустить пользовательский интерфейс Ambari, в колонке "Обзор" в разделе Панели мониторинга кластера щелкните Домашняя страница Ambari. В пользовательском интерфейсе Ambari перейдите к разделу Spark2 >Быстрые ссылки >Пользовательский интерфейс сервера журнала Spark2.
Отобразится список всех завершенных приложений. Выберите идентификатор приложения, чтобы открыть подробные сведения о приложении.