Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Изображения часто содержат полезные сведения, относящиеся к сценариям поиска. Вы можете векторизировать изображения для представления визуального содержимого в индексе поиска. Кроме того, можно использовать обогащение ИИ и наборы навыков для создания и извлечения текста , доступного для поиска, из изображений, в том числе:
- OCR для оптического распознавания символов текста и цифр
- Анализ изображений, описывающий изображения с помощью визуальных функций
- Пользовательские навыки для вызова любой обработки внешних изображений, которые требуется предоставить
С помощью OCR можно извлечь текст и из фотографий или рисунков, например слово STOP в знаке остановки. С помощью анализа изображений можно создать текстовое представление изображения, например одуванчик для фотографии одуванчика , или цвет желтый. Также можно извлечь такие метаданные изображения, как его размер.
В этой статье рассматриваются основы работы с изображениями в наборах навыков, а также описаны несколько распространенных сценариев, таких как работа с внедренными изображениями, пользовательскими навыками и перекладка визуализаций на исходные изображения.
Чтобы работать с содержимым изображения в наборе навыков, вам потребуется:
- Исходные файлы, содержащие изображения
- Индексатор поиска, настроенный для действий с изображением
- Набор навыков со встроенными или настраиваемыми навыками, которые вызывают анализ OCR или изображения
- Индекс поиска с полями для получения проанализированных текстовых выходных данных, а также сопоставления полей выходных данных в индексаторе, который устанавливает связь
При необходимости можно определить проекции для приема выходных данных, проанализированных с помощью изображения, в хранилище знаний для сценариев интеллектуального анализа данных.
Настройка исходных файлов
Обработка изображений управляется индексатором, что означает, что необработанные входные данные должны находиться в поддерживаемом источнике данных.
- Анализ изображений поддерживает JPEG, PNG, GIF и BMP
- OCR поддерживает JPEG, PNG, BMP и TIF
Изображения — это автономные двоичные файлы или внедренные в документы, такие как PDF, RTF или файлы приложений Майкрософт. Из данного документа можно извлечь не более 1000 изображений. Если в документе более 1000 изображений, извлекаются первые 1000 изображений, а затем создается предупреждение.
Хранилище BLOB-объектов Azure является наиболее часто используемым хранилищем для обработки изображений в поиске ИИ Azure. Существует три основных задачи, связанные с извлечением изображений из контейнера BLOB-объектов:
Включите доступ к содержимому в контейнере. Если вы используете полный доступ строка подключения с ключом, ключ дает разрешение на содержимое. Кроме того, вы можете пройти проверку подлинности с помощью идентификатора Microsoft Entra или подключиться в качестве доверенной службы.
Создайте источник данных типа azureblob , который подключается к контейнеру BLOB-объектов, в котором хранятся файлы.
Просмотрите ограничения уровня служб, чтобы убедиться, что исходные данные не ограничены максимальным размером и количеством для индексаторов и обогащения.
Настройка индексаторов для обработки изображений
После настройки исходных файлов включите нормализацию изображений, задав imageAction параметр в конфигурации индексатора. Нормализация изображений помогает сделать изображения более универсальными для последующей обработки. Нормализация изображений включает следующие операции:
- Большие изображения изменяются до максимальной высоты и ширины, чтобы сделать их универсальными.
- Для изображений с метаданными, указывающими ориентацию, поворот изображения настраивается для вертикальной загрузки.
Обратите внимание, что включение imageAction (установка этого параметра на значение, отличное от none) приведет к дополнительной плате за извлечение изображений в соответствии с ценами на поиск Azure AI.
Изменения метаданных записываются в сложном типе, создаваемом для каждого изображения. Вы не можете отказаться от требования нормализации изображений. Навыки, которые итерируют изображения, такие как OCR и анализ изображений, ожидают нормализованных изображений.
Создайте или обновите индексатор , чтобы задать свойства конфигурации:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Задайте значение
dataToExtractcontentAndMetadata(обязательно).Убедитесь, что
parsingModeзадано значение по умолчанию (обязательно).Этот параметр определяет степень детализации документов поиска, созданных в индексе. Режим по умолчанию настраивает одно-одно соответствие таким образом, чтобы один большой двоичный объект был выполнен в одном документе поиска. Если документы большие или если навыки требуют меньших фрагментов текста, можно добавить навык разделения текста, который подразделяет документ на разбиение на разбиение по страницам для целей обработки. Но для сценариев поиска требуется один большой двоичный объект для каждого документа, если обогащение включает обработку изображений.
Установите для
imageActionвключенияnormalized_imagesузла в дереве обогащения (обязательно):generateNormalizedImagesдля создания массива нормализованных изображений в рамках взлома документов.generateNormalizedImagePerPage(применяется только к PDF-файлу) для создания массива нормализованных изображений, где каждая страница в PDF-файле отображается на одном выходном изображении. Для файлов, отличных от PDF, поведение этого параметра похоже на то, как если бы вы установилиgenerateNormalizedImages. Однако параметрgenerateNormalizedImagePerPageможет сделать операцию индексирования менее производительной путем проектирования (особенно для больших документов), так как необходимо создать несколько образов.
При необходимости настройте ширину или высоту созданных нормализованных изображений:
normalizedImageMaxWidthв пикселях. Значение по умолчанию — 2000. Максимальное значение равно 10 000.normalizedImageMaxHeightв пикселях. Значение по умолчанию — 2000. Максимальное значение равно 10 000.
Значение по умолчанию 2000 пикселей для нормализованных изображений максимальной ширины и высоты основано на максимальных размерах, поддерживаемых навыком OCR и навыком анализа изображений. Навык OCR поддерживает максимальную ширину и высоту 4200 для языков, отличных от английского языка, и 10 000 для английского языка. Если увеличить максимальные пределы, то обработка может завершиться сбоем на больших изображениях в зависимости от определения набора навыков и языка документов.
При необходимости задайте критерии типа файла, если рабочая нагрузка нацелена на определенный тип файла. Конфигурация индексатора BLOB-объектов включает в себя параметры включения файлов и исключений. Вы можете отфильтровать файлы, которые вы не хотите.
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Сведения о нормализованных изображениях
Если imageAction задано значение, отличное от ни одного, новое normalized_images поле содержит массив изображений. Каждое изображение представляет сложный тип со следующими элементами:
| Элемент изображения | Описание |
|---|---|
| . | Строка нормализованного изображения в формате JPEG в кодировке Base64. |
| Ширина | Ширина нормализованного изображения в пикселях. |
| высота | Высота нормализованного изображения в пикселях. |
| оригинальная ширина | Исходная ширина изображения перед нормализацией. |
| исходнаяВысота | Исходная высота изображения перед нормализацией. |
| вращениеОтИсходного | Поворот против часовой стрелки (в градусах), выполняемый для создания нормализованного изображения. Значение от 0 до 360 градусов. На этом этапе считываются метаданные изображения, созданного камерой или сканером. Обычно поворот выполняется несколько раз на 90 градусов. |
| смещение содержимого | Смещение символов в поле содержимого, откуда было извлечено изображение. Это поле используется только для файлов с внедренными изображениями. Для contentOffset изображений, извлеченных из ДОКУМЕНТОВ PDF, всегда находится в конце текста на странице, из который он был извлечен из документа. Это означает, что изображения отображаются после всего текста на этой странице независимо от исходного расположения изображения на странице. |
| номер страницы | Если изображение было извлечено или визуализировано из PDF-документа, это поле содержит номер страницы в PDF-файле, из которого оно было извлечено или отрисовано, начиная с 1. Если изображение не из PDF-файла, это поле равно 0. |
| boundingPolygon | Если изображение было извлечено или отрендерено из PDF-файла, это поле содержит координаты ограничивающего многоугольника, который охватывает изображение на странице. Многоугольник представлен как вложенный массив точек, где каждая точка имеет координаты x и y, нормализованные для размеров страницы. Это относится только к изображениям, извлеченным с помощью imageAction: generateNormalizedImages. |
Пример значения normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2,
"boundingPolygon": "[[{\"x\":0.0,\"y\":0.0},{\"x\":500.0,\"y\":0.0},{\"x\":0.0,\"y\":300.0},{\"x\":500.0,\"y\":300.0}]]"
}
]
Примечание.
Данные ограничивающего многоугольника представлены в виде строки, содержащей дважды вложенный массив многоугольников в формате JSON. Каждый многоугольник представляет собой массив точек, где каждая точка имеет координаты x и y. Координаты относительно PDF-страницы с источником (0, 0) в левом верхнем углу.
В настоящее время изображения, извлеченные с помощью imageAction: generateNormalizedImages, всегда создают один многоугольник, но двойная вложенная структура поддерживается для согласованности с функцией макета документа, которая поддерживает несколько многоугольников.
Определение наборов навыков для обработки изображений
Этот раздел дополняет справочные статьи о навыках, предоставляя контекст для работы с входными данными навыка, выходными данными и шаблонами, так как они относятся к обработке изображений.
Создайте или обновите набор навыков для добавления навыков.
Добавьте шаблоны для OCR и анализа изображений из портал Azure или скопируйте определения из справочной документации по навыку. Вставьте их в массив навыков определения набора навыков.
При необходимости включите ключ с несколькими службами в свойство служб искусственного интеллекта Azure набора навыков. Поиск ИИ Azure выполняет вызовы оплачиваемого ресурса служб ИИ Azure для OCR и анализа изображений для транзакций, превышающих бесплатный лимит (20 на индексатор в день). Службы ИИ Azure должны находиться в том же регионе, что и служба поиска.
Если исходные изображения внедрены в PDF-файлы или файлы приложений, например PPTX или DOCX, необходимо добавить навык слияния текста, если вы хотите, чтобы выходные данные изображения и текстовые выходные данные были вместе. Работа с внедренными изображениями рассматривается далее в этой статье.
После создания базовой платформы набора навыков и настройки служб ИИ Azure можно сосредоточиться на каждом навыке изображения, определении входных данных и контексте источника и сопоставлении выходных данных с полями в индексе или хранилище знаний.
Примечание.
Пример набора навыков, объединяющего обработку изображений с нижней частью обработки естественного языка, см . в руководстве ПО REST: использование REST и ИИ для создания содержимого с возможностью поиска из БОЛЬШИХ двоичных объектов Azure. В нем показано, как передавать выходные данные изображения навыка в распознавание сущностей и извлечение ключевых фраз.
Входные данные для обработки изображений
Как отмечалось, изображения извлекаются во время взлома документов, а затем нормализуются как предварительный шаг. Нормализованные изображения являются входными данными для любого навыка обработки изображений и всегда представлены в обогащенном дереве документов одним из двух способов:
/document/normalized_images/*предназначен для документов, которые обрабатываются целиком./document/normalized_images/*/pagesпредназначен для документов, обрабатываемых в блоках (страницах).
Если вы используете OCR и анализ изображений в одном и том же, входные данные имеют практически одно и то же построение:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Сопоставление выходных данных с полями поиска
В наборе навыков выходные данные навыка анализа изображений и навыка OCR всегда являются текстом. Выходной текст представлен как узлы во внутреннем обогащенном дереве документов, и каждый узел должен быть сопоставлен с полями в индексе поиска или проекциями в хранилище знаний, чтобы сделать содержимое доступным в приложении.
В наборе навыков просмотрите
outputsраздел каждого навыка, чтобы определить, какие узлы существуют в обогащенном документе:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Создайте или обновите индекс поиска, чтобы добавить поля для принятия выходных данных навыка.
В следующем примере коллекции полей содержимое — содержимое BLOB-объектов. Metadata_storage_name содержит имя файла (задано
retrievableзначение true). Metadata_storage_path является уникальным путем большого двоичного объекта и является ключом документа по умолчанию. Merged_content выходные данные из слияния текста (полезны при внедрении изображений).Text и layoutText — это выходные данные навыка OCR и должны быть строковой коллекцией, чтобы записать все созданные OCR выходные данные для всего документа.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Обновите индексатор , чтобы сопоставить выходные данные набора навыков (узлы в дереве обогащения) с полями индекса.
Обогащенные документы являются внутренними. Чтобы инициализировать узлы в обогащенном дереве документов, настройте сопоставление полей вывода, указывающее, какое поле индекса получает содержимое узла. Обогащенные данные получают доступ к приложению через поле индекса. В следующем примере показан текстовыйузел (выходные данные OCR) в обогащенном документе, сопоставленном с текстовым полем в индексе поиска.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Запустите индексатор, чтобы вызвать извлечение исходного документа, обработку изображений и индексирование.
проверите результаты;
Выполните запрос к индексу, чтобы проверить результаты обработки изображений. Используйте обозреватель поиска в качестве клиента поиска или любого средства, отправляющего HTTP-запросы. Следующий запрос выбирает поля, содержащие выходные данные обработки изображений.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR распознает текст в файлах изображений. Это означает, что поля OCR (text и layoutText) пусты, если исходные документы являются чистыми текстовыми или чистыми изображениями. Аналогичным образом поля анализа изображений (imageCaption и imageTags) пусты, если входные данные исходного документа являются строго текстовыми. Выполнение индексатора выдает предупреждения, если входные данные изображения пусты. Такие предупреждения должны ожидаться, когда узлы не заполнены в обогащенном документе. Помните, что индексирование BLOB-объектов позволяет включать или исключать типы файлов, если вы хотите работать с типами контента в изоляции. Эти параметры можно использовать для уменьшения шума во время выполнения индексатора.
Альтернативный запрос на проверку результатов может включать содержимое и merged_content поля. Обратите внимание, что эти поля включают содержимое для любого файла BLOB-объектов, даже тех, где не выполнялась обработка изображений.
Сведения о выходных данных навыка
Выходные данные навыка: text (OCR), layoutText (OCR), merged_content( captions анализ изображений), tags (анализ изображений):
textсохраняет выходные данные, созданные OCR. Этот узел должен быть сопоставлен с полем типаCollection(Edm.String). Существует одноtextполе для каждого документа поиска, состоящее из строк с разделителями-запятыми для документов, содержащих несколько изображений. На следующем рисунке показаны выходные данные OCR для трех документов. Сначала это документ, содержащий файл без изображений. Во-вторых, это документ (файл изображения), содержащий одно слово, Корпорация Майкрософт. Третий — это документ, содержащий несколько изображений, некоторые без текста ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutTextхранит сведения о расположении текста на странице, созданном OCR, как описано с точки зрения ограничивающих прямоугольников и координат нормализованного изображения. Этот узел должен быть сопоставлен с полем типаCollection(Edm.String). В документе поиска есть одноlayoutTextполе, состоящее из строк с разделителями-запятыми.merged_contentсохраняет выходные данные навыка слияния текста и должно быть одно большое поле типаEdm.String, содержащее необработанный текст из исходного документа, с внедреннымtextвместо изображения. Если файлы доступны только для текста, то анализ текста и изображения неmerged_contentcontentимеют ничего общего с (свойство BLOB-объекта, содержащее содержимое большого двоичного объекта).imageCaptionзаписывает описание изображения как отдельных тегов и более длинное текстовое описание.imageTagsсохраняет теги о изображении в виде коллекции ключевых слов, одну коллекцию для всех изображений в исходном документе.
На следующем снимках экрана показана иллюстрация PDF-файла, включающего текст и внедренные изображения. В документе трещины обнаружены три внедренных изображения: стая чайок, карты, орла. Другой текст в примере (включая заголовки, заголовки и текст текста) был извлечен как текст и исключен из обработки изображений.
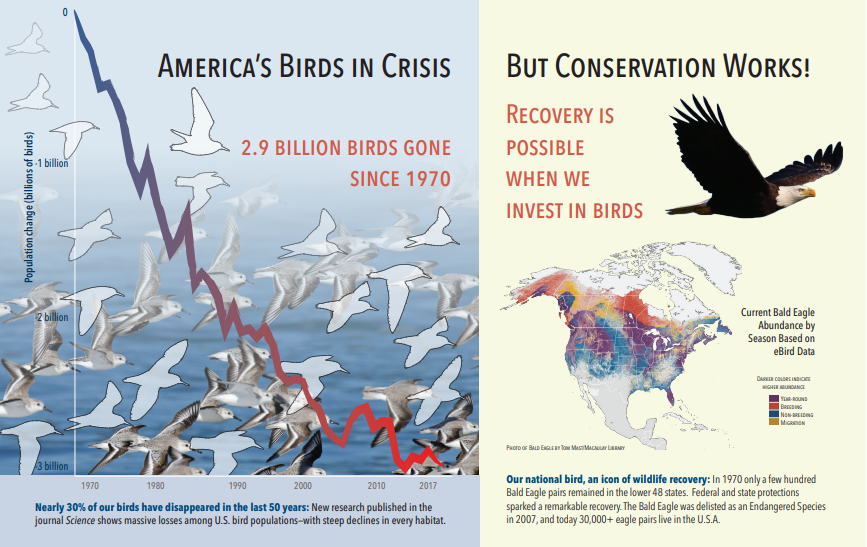
Выходные данные анализа изображений показаны в следующем формате JSON (результат поиска). Определение навыка позволяет указать, какие визуальные функции являются интересующими. В этом примере были созданы теги и описания, но есть больше выходных данных для выбора.
imageCaptionвыходные данные — это массив описаний, один на изображение, обозначающийсяtagsодним словом и длинными фразами, описывающими изображение. Обратите внимание, что теги, состоящие из стаи морских гулей, плавают в воде, или близко к птице.imageTagsвыходные данные — это массив отдельных тегов, перечисленных в порядке создания. Обратите внимание, что теги повторялись. Нет агрегирования или группировки.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Сценарий. Внедренные образы в PDF-файлах
Когда изображения, которые нужно обрабатывать, внедряются в другие файлы, например PDF или DOCX, конвейер обогащения извлекает только изображения, а затем передает их в OCR или анализ изображений для обработки. Извлечение изображений происходит на этапе взлома документа, и после разделения изображений они остаются отдельными, если вы явно не объединяете обработанные выходные данные обратно в исходный текст.
Слияние текста используется для размещения выходных данных обработки изображений обратно в документ. Несмотря на то, что слияние текста не является жестким требованием, он часто вызывается таким образом, чтобы выходные данные изображения (текст OCR, текст OCR, теги изображений, подписи изображений) можно повторно вводить в документ. В зависимости от навыка выходные данные изображения заменяют внедренное двоичное изображение эквивалентом текста на месте. Выходные данные анализа изображений можно объединить в расположении изображения. Выходные данные OCR всегда отображаются в конце каждой страницы.
Следующий рабочий процесс описывает процесс извлечения изображений, анализа, объединения и расширения конвейера для отправки выходных данных, обработанных изображением, в другие навыки на основе текста, такие как распознавание сущностей или преобразование текста.
После подключения к источнику данных индексатор загружает и разбивает исходные документы, извлекает изображения и текст, а также очереди каждого типа контента для обработки. Обогащенный документ, состоящий только из корневого узла (документа).
Изображения в очереди нормализуются и передаются в обогащенные документы как узел документа или normalized_images.
Обогащения изображений выполняются
"/document/normalized_images"в качестве входных данных.Выходные данные изображения передаются в обогащенное дерево документов с каждым выходом в виде отдельного узла. Выходные данные зависят от навыка (text и layoutText для OCR; тегов и подписей для анализа изображений).
Необязательно, но рекомендуется, если вы хотите, чтобы документы поиска включали текст и текст источника изображения вместе, выполняется слияние текста, сочетая текстовое представление этих изображений с необработанным текстом, извлеченным из файла. Фрагменты текста объединяются в одну большую строку, где текст вставляется сначала в строку, а затем выходные данные текста OCR или теги изображений и субтитры.
Выходные данные слияния текста теперь являются окончательным текстом для анализа всех подчиненных навыков, выполняющих обработку текста. Например, если набор навыков включает как распознавание объектов, так и распознавание сущностей, то входные данные распознавания сущностей должны быть
"document/merged_text"(целевое имя выходных данных навыка слияния текста).После выполнения всех навыков обогащенный документ будет завершен. На последнем шаге индексаторы ссылаются на сопоставления полей вывода для отправки обогащенного содержимого отдельным полям в индексе поиска.
В следующем примере набора навыков создается merged_text поле, содержащее исходный текст документа с внедренным текстом OCRed вместо внедренных изображений. Он также включает навык распознавания сущностей, который используется merged_text в качестве входных данных.
Синтаксис текста запроса
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Теперь, когда у вас есть merged_text поле, его можно сопоставить как поле с возможностью поиска в определении индексатора. Все содержимое файлов, включая текст изображений, будет доступно для поиска.
Сценарий: визуализация ограничивающих прямоугольник
Другой распространенный сценарий — визуализация сведений о макете результатов поиска. Например, можно выделить участок с обнаруженным в изображении фрагментом текста как часть результатов поиска.
Так как шаг OCR выполняется на нормализованных изображениях, координаты макета находятся в нормализованном пространстве изображения, но если необходимо отобразить исходное изображение, преобразуйте точки координат в макет в исходную систему координат изображения.
Следующий алгоритм иллюстрирует шаблон:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Сценарий: навыки пользовательского образа
Изображения также могут передаваться в пользовательские навыки и возвращаться из них. Набор навыков base64 кодирует изображение, передаваемое в пользовательский навык. Чтобы использовать изображение в пользовательском навыке, задайте "/document/normalized_images/*/data" в качестве входных данных для пользовательского навыка. В коде пользовательского навыка декодируйте строку из Base64 перед ее преобразованием в изображение. Чтобы вернуть изображение в набор навыков, сначала закодируйте его в Base64.
Изображение возвращается в виде объекта со следующими свойствами.
{
"$type": "file",
"data": "base64String"
}
Репозиторий примеров Python службы "Поиск Azure" содержит полный пример, реализованный в Python пользовательского навыка, который дополняет образы.
Передача изображений в пользовательские навыки
В сценариях, где для работы с изображениями требуется пользовательский навык, можно передавать изображения в пользовательский навык и возвращать текст или изображения. Следующий набор навыков представлен в примере.
Следующий набор навыков принимает нормализованное изображение (полученное во время распознавания документа) и выводит срезы изображения.
Пример набора навыков
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Пример пользовательского навыка
Пользовательский навык находится за пределами набора навыков. В этом случае это код Python, который сначала циклит пакет записей запросов в пользовательском формате навыка, а затем преобразует строку в кодировке Base64 в изображение.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Аналогично возврату изображения возвращается строка в кодировке Base64 в объекте JSON со свойством $typeфайла.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}