Мониторинг Azure Service Fabric
В этой статье рассматриваются следующие вопросы:
- Типы данных мониторинга, которые можно собирать для этой службы.
- Способы анализа данных.
Примечание.
Если вы уже знакомы с этой службой и (или) Azure Monitor и просто хотите знать, как анализировать данные мониторинга, см . раздел "Анализ " в конце этой статьи.
При наличии критически важных приложений и бизнес-процессов, использующих ресурсы Azure, необходимо отслеживать и получать оповещения для системы. Служба Azure Monitor собирает и агрегирует метрики и журналы из каждого компонента системы. Azure Monitor предоставляет представление о доступности, производительности и устойчивости, а также уведомляет вас о проблемах. Вы можете использовать портал Azure, PowerShell, Azure CLI, REST API или клиентские библиотеки для настройки и просмотра данных мониторинга.
- Дополнительные сведения об Azure Monitor см. в обзоре Azure Monitor.
- Дополнительные сведения о том, как отслеживать ресурсы Azure в целом, см. в статье "Мониторинг ресурсов Azure" с помощью Azure Monitor.
Мониторинг Azure Service Fabric
Azure Service Fabric содержит следующие уровни, которые можно отслеживать:
- Мониторинг приложений: приложения , выполняемые на узлах. Приложения можно отслеживать с помощью ключа Application Insights или пакета SDK, EventStore или ASP.NET ведения журнала Core.
- Мониторинг платформы (кластера): клиентские метрики, журналы и события для узлов платформы или кластера , включая метрики контейнеров. Метрики и журналы отличаются для узлов Linux или Windows.
- Мониторинг инфраструктуры (производительности): Работоспособность служб и счетчики производительности для инфраструктуры служб.
Вы можете отслеживать использование приложений, действия, выполняемые платформой Service Fabric, использование ресурсов с счетчиками производительности и общее состояние работоспособности кластера. Журналы Azure Monitor и Application Insights предлагают встроенную интеграцию со Service Fabric.
- Дополнительные сведения о рекомендациях см. в статье "Мониторинг и диагностика" для Azure Service Fabric.
- Руководство по просмотру событий Service Fabric и отчетов о работоспособности, запроса API EventStore и мониторинга счетчиков производительности см . в руководстве по мониторингу кластера Service Fabric в Azure.
- Сведения о настройке журналов Azure Monitor для мониторинга контейнеров Windows, управляемых в Service Fabric, см. в руководстве по мониторингу контейнеров Windows в Service Fabric с помощью журналов Azure Monitor.
Service Fabric Explorer
Service Fabric Explorer, классическое приложение для Windows, macOS и Linux, — это средство с открытым исходным кодом для проверки кластеров Azure Service Fabric и управления ими. Чтобы включить автоматизацию, все действия, которые можно выполнить с помощью Service Fabric Explorer, также можно выполнить с помощью PowerShell или REST API.
Мониторинг приложений
В процессе мониторинга приложений фиксируются особенности использования возможностей и компонентов приложения. Он позволяет перехватить проблемы, влияющие на пользователей. Ответственность за мониторинг приложения лежит на пользователях, разрабатывающих приложение и его службы, так как он привязан к бизнес-логике приложения. Мониторинг приложений может оказаться полезным в следующих случаях.
- Какой трафик моего приложения? — Нужно ли масштабировать службы для удовлетворения потребностей пользователей или устранения потенциального узкого места в приложении?
- Успешно ли выполняются и отслеживаются мои вызовы между службами?
- Какие действия предпринимают пользователи моего приложения? — При разработке новых функций и выявлении ошибок в приложении можно ориентироваться на данные телеметрии.
- Выдает ли мое приложение необработанные исключения?
- Что происходит в службах, выполняющихся в моих контейнерах?
Самое замечательное в мониторинге приложений — это то, что разработчики могут использовать любые инструменты и платформы, так как он выполняется в контексте приложения! Дополнительные сведения о решении Azure для мониторинга приложений с помощью Azure Monitor Application Insights см. в анализе событий с помощью Application Insights.
У нас также есть руководство по настройке мониторинга для приложений .NET. Это руководство содержит инструкции по установке нужных инструментов и просмотру данных диагностики и телеметрии приложения на портале Azure, а также пример написания собственной телеметрии в приложении.
Ведение журнала приложения
Инструментирование кода — не только метод получения аналитических сведений о пользователях, но и единственный способ проверить наличие проблем в приложении, а также выяснить, где требуются исправления. Технически есть возможность подключить отладчик к рабочей службе, но обычно так никто не делает. Поэтому вам нужны подробные данные инструментирования.
Некоторые решения выполняют инструментирование кода автоматически. Они могут вполне успешно работать, но почти всегда требуется инструментирование вручную, которое должно соответствовать используемой бизнес-логике. В итоге у вас должно быть достаточно информации для экспертной отладки приложения. Приложения Service Fabric можно инструментировать на любой платформе ведения журналов. В этом разделе описывается несколько различных подходов к инструментированию кода и выбор одного подхода к другому.
Пакет SDK Application Insights: Application Insights имеет богатую интеграцию со Service Fabric из поля. Пользователи могут добавлять пакеты NuGet ИИ Service Fabric и получать данные и журналы, созданные и собранные готовыми к просмотру на портале Azure. Кроме того пользователям рекомендуется добавлять свои собственные данные телеметрии для диагностики и отладки своих приложений, а также получения сведения о самых используемых службах и частей приложений. Класс TelemetryClient в пакете SDK предоставляет много способов отслеживать данные телеметрии в приложении. Дополнительные сведения см. в разделе "Анализ событий" и визуализация с помощью Application Insights.
Ознакомьтесь с примером инструментирования и добавления аналитики приложений в приложение в нашем руководстве по мониторингу и диагностике приложения .NET.
EventSource: при создании решения Service Fabric из шаблона в Visual Studio создается класс, производный от EventSource (ServiceEventSource или ActorEventSource). При этом создается шаблон, в который вы можете добавлять события для конкретного приложения или службы. Имя EventSourceдолжно быть уникальным, поэтому потребуется изменить стандартное имя MyCompany-<solution>-<project>. Наличие нескольких определений EventSource с одинаковым именем приведет к возникновению проблемы во время выполнения. У каждого определенного события должен быть уникальный идентификатор. Если идентификатор не является уникальным, происходит сбой во время выполнения. Некоторые организации предварительно назначают для идентификаторов диапазоны значений, чтобы избежать конфликтов между командами разработчиков. Дополнительные сведения см. в блоге Вэнса (Vance) или в документации MSDN.
ASP.NET ведения журнала ядра. Важно тщательно спланировать инструментирование кода. Правильный план инструментирования позволит избежать потенциальной дестабилизации базы кода, которая повлечет за собой повторное инструментрирование кода. Чтобы снизить риск, вы можете применить библиотеку инструментирования, например Microsoft.Extensions.Logging, которая входит в Microsoft ASP.NET Core. ASP.NET Core предоставляет интерфейс ILogger, который можно подключить к любому поставщику, с минимальными изменениями существующего кода. Код ASP.NET Core можно использовать на платформах Windows, Linux и в полной версии .NET Framework, то есть код инструментирования будет полностью стандартизирован.
Примеры использования этих подходов см. в статье Добавление ведения журнала в приложение Service Fabric.
Мониторинг платформы (кластера)
Пользователь контролирует, какие данные телеметрии поступают из его приложения, так как он сам пишет код, но что насчет данных диагностики с платформы Service Fabric? Одна из целей создания Service Fabric — это обеспечение работы приложения в случае сбоев оборудования. Это достигается благодаря способности системных служб платформы обнаруживать проблемы с инфраструктурой и быстро выполнять отработку отказа рабочих нагрузок на другие узлы в кластере. Но в этом случае, что делать, если в самих системных службах есть проблемы? Или если при попытке развертывания или перемещения рабочей нагрузки нарушаются правила размещения служб? Диагностика Service Fabric обеспечит вас информацией об этих и других действиях, происходящих в вашем кластере. Примеры сценариев для мониторинга кластера:
Дополнительные сведения о мониторинге платформы (кластера) см. в разделе "Мониторинг кластера".
События Service Fabric
Service Fabric предоставляет полный набор событий диагностика вне поля, доступ к которому можно получить через EventStore или канал операционных событий, предоставляемый платформой. Эти события Service Fabric иллюстрируют действия, выполненные платформой на разных сущностях, таких как узлы, приложения, службы и секции. Эти события доступны как для кластеров Windows, так и для кластеров Linux.
Каналы событий Service Fabric: в Windows события Service Fabric доступны от одного поставщика ETW с набором соответствующих
logLevelKeywordFiltersспособов выбора между операционными и обмен данными и каналами обмена сообщениями. Это способ, в котором мы отделяем исходящие события Service Fabric для фильтрации по мере необходимости. В Linux все события Service Fabric проходят через LTTng и помещаются в одну таблицу службы хранения, в которой они могут быть отфильтрованы нужным образом. Эти каналы содержат проверенные структурированные события, которые помогают лучше понять состояние вашего кластера. Диагностика включается по умолчанию в момент создания кластера, и при этом создается таблица службы хранилища Azure, в которую отправляются события, поступающие из всех каналов для последующего запроса.EventStore — это функция, которая показывает события платформы Service Fabric в Service Fabric Explorer и программно через REST API клиентской библиотеки Service Fabric. Представление моментального снимка о том, что происходит в кластере для каждого узла, службы и приложения, а также запроса на основе времени события. API EventStore доступны только для кластеров Windows, работающих в Azure. На компьютерах Windows эти события передаются в журнал событий, чтобы вы могли видеть события Service Fabric в Просмотр событий.
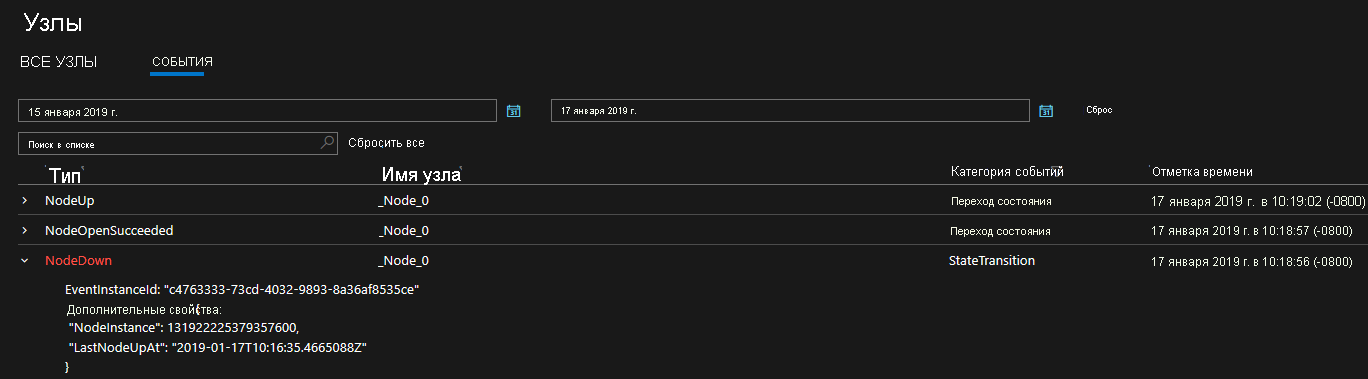
Предоставляемые данные диагностики имеют форму исчерпывающего набора событий. Эти события Service Fabric иллюстрируют действия, выполняемые платформой в различных сущностях, таких как узлы, приложения, службы, секции и т. д. В последнем из приведенных выше сценариев в случае остановки узла платформа выдаст событие NodeDown, и вы можете немедленно получить уведомление от выбранного средства мониторинга. Также во время отработки отказа часто издаются события ApplicationUpgradeRollbackStarted и PartitionReconfigured. Эти события доступны как для кластеров Windows, так и для кластеров Linux.
События отправляются по стандартным каналам как в Windows, так и в Linux и могут считываться любым средством мониторинга, которое их поддерживает. Решение Azure Monitor — журналы Azure Monitor. Вы можете узнать больше об интеграции журналов Azure Monitor, которая включает специальную панель мониторинга для кластера и примеры запросов, из которых можно создавать оповещения. Узнайте больше о создании событий и журналов на уровне платформы.
Мониторинг работоспособности
Платформа Service Fabric включает модель работоспособности, которая обеспечивает расширяемую отчетность о состоянии работоспособности сущностей в кластере. Каждый узел, приложение, служба, секция, реплика или экземпляр имеют постоянно обновляемое состояние работоспособности, которое может иметь значение "ОК", "Предупреждение" или "Ошибка". Думайте о событиях Service Fabric как о командах, выполняемых кластером с различными объектами, а о работоспособности как о характеристике каждого объекта. Событие также издается при каждом изменении работоспособности объекта. Таким образом, вы можете настроить запросы и оповещения для событий работоспособности в выбранном вами инструменте мониторинга, как и любое другое событие.
Кроме того, мы разрешаем пользователям переопределять работоспособность объектов. Если приложение проходит обновление, и у вас возникли сбои тестов проверки, вы можете написать в Service Fabric Health с помощью API работоспособности, чтобы указать, что ваше приложение больше не работает, и Service Fabric автоматически откатит обновление. Чтобы узнать больше о модели работоспособности, прочитайте этот обзор.
Модули наблюдения
Как правило, модуль наблюдения является отдельной службой, которая может отслеживать работоспособность и нагрузку в службах, проверять связь с конечными точками и сообщать о непредвиденных событиях работоспособности в кластере. Он позволяет предотвратить ошибки, которые невозможно обнаружить только на основе производительности отдельной службы. В модулях наблюдения также удобно размещать код, выполняющий корректирующие действия, не требующие участия пользователя (например, очистку файлов журнала в хранилище через определенные интервалы времени). Если вам нужна полностью реализованная служба наблюдения Servie Fabric c открытым кодом, которая включает в себя простую в использовании модель расширяемости модулей наблюдения и работает в кластерах Windows и Linux, см. проект FabricObserver. FabricObserver — это готовое к использованию программное обеспечение. Мы рекомендуем развертывать FabricObserver в тестовых и рабочих кластерах и расширять его в соответствии с потребностями либо через модель подключаемых модулей, либо создав вилку и добавив собственные встроенные наблюдатели. Рекомендуется использовать первый подход (подключаемые модули).
Мониторинг инфраструктуры (производительности)
Теперь, когда мы рассмотрели диагностику в приложении и платформу, рассмотрим мониторинг оборудования. Мониторинг базовой инфраструктуры является ключевым в понимании состояния кластера и использовании ресурсов. Измерение производительности системы зависит от многих факторов, которые могут быть субъективными в зависимости от рабочих нагрузок. Эти факторы обычно измеряется с помощью счетчиков производительности. Они могут получать информацию из различных источников, включая операционную систему, платформу .NET Framework или платформу Service Fabric. Сценарии, в которых они будут полезны:
- Эффективно ли я использую свое оборудование? Вы хотите использовать оборудование на 90% или на 10% ресурсов ЦП? Это полезно при масштабировании кластера или оптимизации процессов приложения.
- Можно ли прогнозировать проблемы с инфраструктурой? — Возникновению многих проблем предшествуют внезапные изменения (снижения) производительности, поэтому для прогнозирования и диагностики таких проблем можно использовать счетчики производительности, такие как сетевые операции ввода-вывода и использование ЦП.
Список счетчиков производительности, которые необходимо собрать на уровне инфраструктуры, можно найти в статье Метрики производительности.
Для мониторинга событий на уровне кластера рекомендуется использовать журналы Azure Monitor. После настройки агента Log Analytics с рабочей областью вы можете собрать следующее:
- Метрики производительности, такие как использование ЦП.
- Счетчики производительности .NET, такие как использование ЦП на уровне процесса.
- Счетчики производительности Service Fabric, такие как количество исключений из надежной службы.
- Метрики контейнеров, такие как использование ЦП.
Типы ресурсов
Azure использует концепцию типов ресурсов и идентификаторов для идентификации всего в подписке. Типы ресурсов также являются частью идентификаторов ресурсов для каждого ресурса, работающего в Azure. Например, для виртуальной машины используется Microsoft.Compute/virtualMachinesодин тип ресурса. Список служб и связанных с ними типов ресурсов см. в разделе "Поставщики ресурсов".
Azure Monitor аналогично упорядочивает основные данные мониторинга в метрики и журналы на основе типов ресурсов, которые также называются пространствами имен. Различные метрики и журналы доступны для различных типов ресурсов. Служба может быть связана с несколькими типами ресурсов.
Дополнительные сведения о типах ресурсов для Azure Service Fabric см . в справочнике по данным мониторинга Service Fabric.
Хранилище данных
Для Azure Monitor:
- Данные метрик хранятся в базе данных метрик Azure Monitor.
- Данные журнала хранятся в хранилище журналов Azure Monitor. Log Analytics — это средство в портал Azure, которое может запрашивать это хранилище.
- Журнал действий Azure — это отдельное хранилище с собственным интерфейсом в портал Azure.
При необходимости можно перенаправить данные журнала метрик и действий в хранилище журналов Azure Monitor. Затем с помощью Log Analytics можно запрашивать данные и сопоставлять их с другими данными журнала.
Многие службы могут использовать параметры диагностики для отправки данных метрик и журналов в другие расположения хранилища за пределами Azure Monitor. Примеры включают служба хранилища Azure, размещенные партнерские системы и системы партнеров, отличные от Azure, с помощью Центров событий.
Подробные сведения о том, как Azure Monitor хранит данные, см. на платформе данных Azure Monitor.
Метрики платформы Azure Monitor
Azure Monitor предоставляет метрики платформы для многих служб. Список всех метрик, которые можно собрать для всех ресурсов в Azure Monitor, см. в статье "Поддерживаемые метрики в Azure Monitor".
Эта служба не собирает метрики платформы.
Метрики, отличные от Azure Monitor
Эта служба предоставляет другие метрики, которые не включены в базу данных метрик Azure Monitor.
Метрики гостевой ОС
Метрики гостевой операционной системы (OS), работающей на узлах кластера Service Fabric, должны собираться с помощью одного или нескольких агентов, работающих в гостевой ОС. Метрики гостевой ОС включают счетчики производительности, которые отслеживают нагрузку на ЦП или память гостевой ОС, данные о которой часто используются для автомасштабирования или создания оповещений.
Рекомендуется использовать и настроить агент Azure Monitor для отправки метрик производительности гостевой ОС с помощью API пользовательских метрик в базу данных метрик Azure Monitor. Метрики гостевой ОС можно отправлять в журналы Azure Monitor с помощью того же агента. Затем вы можете запросить эти метрики и журналы с помощью Log Analytics.
Примечание.
Агент Azure Monitor заменяет расширение Диагностика Azure и агент Log Analytics для маршрутизации гостевой ОС. Дополнительные сведения см. в статье Общие сведения об агентах Azure Monitor.
Журналы ресурсов Azure Monitor
Журналы ресурсов предоставляют аналитические сведения об операциях, выполненных ресурсом Azure. Журналы создаются автоматически, но их необходимо перенаправить в журналы Azure Monitor, чтобы сохранить или запросить их. Журналы организованы по категориям. Заданное пространство имен может содержать несколько категорий журналов ресурсов, которые можно собирать.
Эта служба не собирает журналы ресурсов, но их можно найти в данных мониторинга из ресурсов Azure.
Журналы и события Service Fabric
Service Fabric может собирать следующие журналы:
- Для кластеров Windows можно настроить мониторинг кластера с помощью агента диагностики и журналов Azure Monitor.
- Для кластеров Linux журналы Azure Monitor также являются рекомендуемыми средствами для мониторинга платформы и инфраструктуры Azure. Для платформы Linux диагностика требуется другая конфигурация. Дополнительные сведения см. в разделе "События кластера Linux Service Fabric" в системном журнале.
- Агент Azure Monitor можно настроить для отправки журналов гостевой ОС в журналы Azure Monitor, где их можно запрашивать с помощью Log Analytics.
- Журналы контейнеров Service Fabric можно записывать в stdout или stderr , чтобы они были доступны в журналах Azure Monitor.
- Вы можете настроить решение мониторинга контейнеров для журналов Azure Monitor для просмотра событий контейнера.
Другие решения для ведения журнала
Хотя мы рекомендуем два решения, журналы Azure Monitor и Application Insights, встроены в интеграцию со Service Fabric, многие события записываются через поставщиков ETW и расширяемы с другими решениями для ведения журнала. Стоит также обратить внимание на Elastic Stack (особенно если кластер будет выполняться в автономной среде), Dynatrace или любую другую платформу по вашему выбору. Список интегрированных партнеров см. в статье "Партнеры по мониторингу Azure Service Fabric".
Основные моменты, на которые следует обратить внимание при выборе платформы: удобство пользовательского интерфейса, возможности запроса данных, доступные визуализации и панели мониторинга, а также наличие дополнительных инструментов для улучшения мониторинга.
Журнал действий Azure
Журнал действий содержит события уровня подписки, отслеживающие операции для каждого ресурса Azure, как видно извне этого ресурса; например, создание нового ресурса или запуск виртуальной машины.
Коллекция: события журнала действий автоматически создаются и собираются в отдельном хранилище для просмотра в портал Azure.
Маршрутизация. Вы можете отправлять данные журнала действий в журналы Azure Monitor, чтобы их можно было анализировать вместе с другими данными журнала. Также доступны другие расположения, такие как служба хранилища Azure, Центры событий Azure и некоторые партнеры по мониторингу Майкрософт. Дополнительные сведения о маршрутизации журнала действий см. в разделе "Обзор журнала действий Azure".
Анализ данных мониторинга
Существует множество средств для анализа данных мониторинга.
Средства Azure Monitor
Azure Monitor поддерживает следующие основные средства:
Обозреватель метрик— средство в портал Azure, позволяющее просматривать и анализировать метрики для ресурсов Azure. Дополнительные сведения см. в разделе "Анализ метрик" с помощью обозревателя метрик Azure Monitor.
Log Analytics— средство в портал Azure, позволяющее запрашивать и анализировать данные журнала с помощью языка запросов Kusto (KQL). Дополнительные сведения см. в статье Начало работы с запросами журнала в Azure Monitor.
Журнал действий, имеющий пользовательский интерфейс в портал Azure для просмотра и базового поиска. Для более подробного анализа необходимо направлять данные в журналы Azure Monitor и выполнять более сложные запросы в Log Analytics.
Средства, которые позволяют более сложной визуализации, включают:
- Панели мониторинга, позволяющие объединить различные виды данных в одну область в портал Azure.
- Книги, настраиваемые отчеты, которые можно создать в портал Azure. Книги могут включать текст, метрики и запросы журналов.
- Grafana — открытое средство платформы, которое работает на операционных панелях мониторинга. С помощью Grafana можно создавать панели мониторинга, содержащие данные из нескольких источников, отличных от Azure Monitor.
- Power BI— служба бизнес-аналитики, которая предоставляет интерактивные визуализации в различных источниках данных. Вы можете настроить Power BI на автоматический импорт данных журналов из Azure Monitor, чтобы воспользоваться этими визуализациями.
Общие сведения о сценариях аналитики мониторинга Service Fabric см. в статье "Диагностика распространенных сценариев с помощью Service Fabric".
Средства экспорта Azure Monitor
Вы можете получить данные из Azure Monitor в другие средства с помощью следующих методов:
Метрики. Используйте REST API для метрик для извлечения данных метрик из базы данных метрик Azure Monitor. API поддерживает выражения фильтров для уточнения полученных данных. Дополнительные сведения см . в справочнике по REST API Azure Monitor.
Журналы: используйте REST API или связанные клиентские библиотеки.
Другим вариантом является экспорт данных рабочей области.
Сведения о начале работы с REST API для Azure Monitor см . в пошаговом руководстве по REST API мониторинга Azure.
Запросы Kusto
Данные мониторинга можно анализировать в хранилище журналов Azure Monitor или Log Analytics с помощью языка запросов Kusto (KQL).
Внимание
При выборе журналов в меню службы на портале Log Analytics откроется область запроса, заданная текущей службой. Эта область означает, что запросы журналов будут включать только данные из этого типа ресурса. Если вы хотите выполнить запрос, содержащий данные из других служб Azure, выберите журналы в меню Azure Monitor . Подробные сведения см. в статье Область запросов журнала и временной диапазон в Azure Monitor Log Analytics.
Список распространенных запросов для любой службы см. в интерфейсе запросов Log Analytics.
Примеры запросов
Следующие запросы возвращают события Service Fabric, включая действия на узлах. Сведения о других полезных запросах см. в разделе "События Service Fabric".
Этот запрос возвращает операционные события, записанные за последний час:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Возвращает отчеты о работоспособности с помощью HealthState == 3 (ошибка) и извлекает дополнительные свойства из EventMessage поля:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Этот запрос возвращает операционные события Service Fabric, агрегированные с конкретной службой и узлом:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
видны узлы
Оповещения Azure Monitor заранее уведомляют вас о конкретных условиях, обнаруженных в данных мониторинга. Оповещения позволяют выявлять и устранять проблемы в системе, прежде чем клиенты заметят их. Дополнительные сведения см. в оповещениях Azure Monitor.
Существует множество источников распространенных оповещений для ресурсов Azure. Примеры распространенных оповещений для ресурсов Azure см. в примерах запросов оповещений журнала. Сайт базовых оповещений Azure Monitor (AMBA) предоставляет полуавтомативный метод реализации важных оповещений метрик платформы, панелей мониторинга и рекомендаций. Сайт применяется к постоянно расширяющемуся подмножество служб Azure, включая все службы, которые являются частью целевой зоны Azure (ALZ).
Общая схема оповещений стандартизирует потребление уведомлений об оповещениях Azure Monitor. Дополнительные сведения см. в разделе "Общая схема оповещений".
Типов оповещений
Вы можете получать оповещения о любых источниках данных метрик или журналов на платформе данных Azure Monitor. Существует множество различных типов оповещений в зависимости от служб, которые вы отслеживаете, и данных мониторинга, которые вы собираете. Различные типы оповещений имеют различные преимущества и недостатки. Дополнительные сведения см. в разделе "Выбор правильного типа оповещений мониторинга".
В следующем списке описаны типы оповещений Azure Monitor, которые можно создать:
- Оповещения метрик оценивают метрики ресурсов через регулярные интервалы. Метрики могут быть метриками платформы, пользовательскими метриками, журналами из Azure Monitor, преобразованными в метрики или метриками Application Insights. Оповещения метрик также могут применять несколько условий и динамические пороговые значения.
- Оповещения журнала позволяют пользователям использовать запрос Log Analytics для оценки журналов ресурсов на предопределенной частоте.
- Оповещения журнала действий активируются при возникновении нового события журнала действий, соответствующего определенным условиям. Работоспособность ресурсов оповещения и оповещения о работоспособности служб — это оповещения журнала действий, которые сообщают о работоспособности службы и ресурсов.
Некоторые службы Azure также поддерживают оповещения интеллектуального обнаружения, оповещения Prometheus или рекомендуемые правила генерации оповещений.
Для некоторых служб можно отслеживать масштаб, применяя одно правило генерации оповещений метрик к нескольким ресурсам одного типа, которые существуют в одном регионе Azure. Для каждого отслеживаемого ресурса отправляются отдельные уведомления. Сведения о поддерживаемых службах и облаках Azure см. в статье "Мониторинг нескольких ресурсов с помощью одного правила генерации оповещений".
Правила генерации оповещений Service Fabric
В следующей таблице перечислены некоторые правила генерации оповещений для Service Fabric. Эти оповещения являются лишь примерами. Вы можете задать оповещения для любой метрики, записи журнала или записи журнала действий, указанной в справочнике по данным мониторинга Service Fabric или списке событий Service Fabric.
| Тип оповещения | Условие | Description |
|---|---|---|
| Событие узла | Узел выходит из строя | ServiceFabricOperationalEvent, где EventID >= 25622 и EventID <= 25626. Эти идентификаторы событий находятся в справочнике по событиям узла. |
| Данные журнала | Откат обновления приложения | ServiceFabricOperationalEvent, где EventID == 29623 или EventID == 29624. Эти идентификаторы событий находятся в справочнике по событиям приложения. |
| Работоспособность ресурса | Служба обновления недоступна или недоступна | Кластер переходит в состояние UpgradeServiceUnreachable. |
Рекомендации Помощника
Для некоторых служб, если критические условия или неизбежные изменения происходят во время операций ресурсов, на странице обзора службы на портале отображается оповещение. Дополнительные сведения и рекомендуемые исправления для оповещения в рекомендациях Помощника см. в разделе "Мониторинг" в меню слева. Во время обычных операций рекомендации помощника не отображаются.
Дополнительные сведения о Помощнике по Azure см. в обзоре Помощника по Azure.
Рекомендуемая настройка
Теперь, когда мы рассмотрели каждую область мониторинга и примеры сценариев, перечислим инструменты мониторинга Azure с настройками, необходимыми для мониторинга всех указанных выше областей.
- Мониторинг приложений с помощью Application Insights
- Мониторинг кластеров с помощью агента диагностики и журналов Azure Monitor
- Мониторинг инфраструктуры с помощью журналов Azure Monitor
Вы также можете использовать и изменить пример шаблона ARM для автоматизации развертывания всех необходимых ресурсов и агентов.
Связанный контент
- Дополнительные сведения о метриках, журналах и других важных значениях, созданных для Service Fabric, см . в справочнике по данным мониторинга Service Fabric.
- Общие сведения о мониторинге ресурсов Azure см. в статье "Мониторинг ресурсов Azure" с помощью Azure Monitor .
- См. список событий Service Fabric.