Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Проверка входных данных — это прием, используемый для защиты основной логики запросов от неправильных или непредвиденных событий. Запрос обновляется, чтобы явным образом обработать и проверить записи и предотвратить разрушение основной логики.
Для реализации проверки входных данных мы добавили два начальных шага к запросу. Сначала мы убеждаемся, что схема, отправленная в основную бизнес-логику, соответствует ее ожиданиям. Затем мы рассматриваем исключения и при необходимости записываем недопустимые записи в дополнительный набор выходных данных.
Запрос с проверкой входных данных будет структурирован следующим образом:
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Подробный пример запроса с настроенной проверкой входных данных, см. в разделе Пример запроса с проверкой входных данных.
В этой статье показано, как реализовать этот метод.
Контекст
Задания Azure Stream Analytics (ASA) обрабатывают данные, поступающие из потоков. Потоки — это последовательности необработанных данных, которые передаются сериализованными (в формате CSV, JSON, AVRO и т. д.). Для чтения сведений из потока приложению нужно знать конкретный формат сериализации. В ASA формат сериализации событий должен быть определен при настройке входных данных потоковой передачи.
После десериализации данных необходимо применить схему, чтобы придать им значение. Под схемой мы имеем в виду список полей в потоке и соответствующие типы данных. При использовании ASA не нужно задавать схему входящих данных на уровне ввода. ASA поддерживает собственные динамические схемы входных данных. ASA ожидает список полей (столбцов) и их типы, чтобы менять данные для событий (строк). ASA также выводит типы данных, если они не предоставлены явным образом, и пытается неявно привести типы при необходимости.
Динамическая обработка схем — мощная возможность, которая играет ключевую роль в потоковой обработке. Потоки данных часто содержат сведения из нескольких источников с разными типами событий, каждый из которых имеет уникальную схему. Для маршрутизации, фильтрации и обработки событий в таких потоках ASA необходимо принимать все потоки независимо от их схемы.
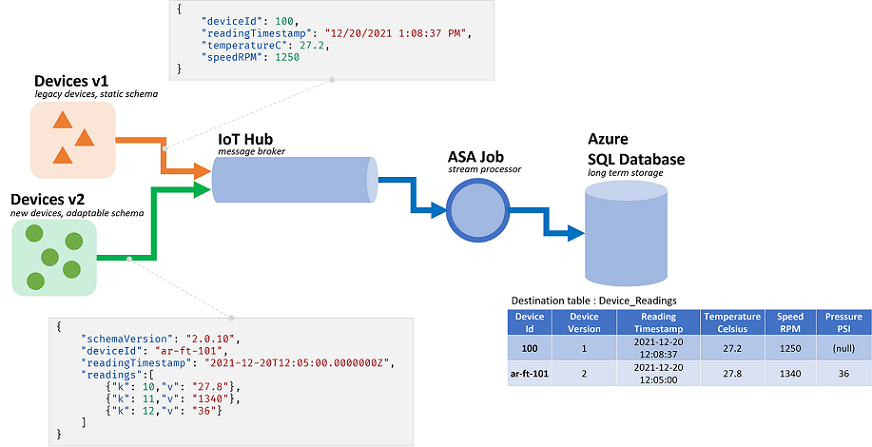
Но у возможностей динамической обработки схем есть потенциальный недостаток. Непредвиденные события могут проходить через главную логику запроса и нарушать ее. Например, можно использовать операцию ROUND для поля типа NVARCHAR(MAX). ASA неявно приведет его к типу float, чтобы сопоставить с сигнатурой ROUND. Здесь мы предполагаем, или надеемся, что это поле всегда будет содержать числовые значения. Но когда мы получаем событие со значением "NaN" в поле или событие без поля, задание может завершиться ошибкой.
С помощью проверки входных данных мы добавляем в наш запрос предварительные шаги для обработки таких неправильных событий. В основном для реализации мы используем операторы WITH и TRY_CAST.
Сценарий: проверка входных данных для ненадежных производителей событий
Мы создадим задание ASA, которое будет принимать данные из одного концентратора событий. Мы не несем ответственность за производителей данных. В данном случае производители — это устройства Интернета вещей, продаваемые несколькими поставщиками оборудования.
Встретившись с заинтересованными лицами, мы согласовали формат сериализации и схему. Все устройства будут отправлять такие сообщения в общий концентратор событий, вход для задания ASA.
Контракт схемы определяется следующим образом:
| Имя поля | Тип поля | Описание поля |
|---|---|---|
deviceId |
Целое | Уникальный идентификатор устройства |
readingTimestamp |
Datetime | Время сообщения, созданного центральным шлюзом |
readingStr |
Строка | |
readingNum |
Числовое | |
readingArray |
Массив строк |
Вот образец сообщения при сериализации JSON:
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
Мы уже можем увидеть расхождение между контрактом схемы и его реализацией. В формате JSON отсутствует тип данных для даты и времени. Они будут передаваться в виде строк (см. readingTimestamp выше). ASA может легко решить эту проблему, но это подтверждает необходимость проверки и явного приведения типов. Это относится и к данным, сериализованным в CSV, так как все значения передаются в виде строк.
Есть еще одно несоответствие. ASA использует собственную систему типов, которая не соответствует входящей. Если у ASA есть встроенные типы для целых чисел (bigint), даты и времени, строк (nvarchar(max)) и массивов, то числовой формат поддерживается только через float. Это несоответствие не является проблемой для большинства приложений. Но в некоторых пограничных случаях это может привести к небольшому нарушению точности. В данном примере числовое значение преобразуется в строку в новом поле. Затем используется система, поддерживающая фиксированные десятичные числа для обнаружения и исправления возможных нарушений.
Вернемся к нашему запросу. Мы планируем:
- Передать
readingStrв определяемую пользователем функцию JavaScript. - Подсчитать количество записей в массиве.
- Округлить
readingNumдо второго десятичного разряда. - Вставить данные в таблицу SQL.
У целевой SQL таблицы следующая схема:
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
Рекомендуется сопоставлять то, что происходит с каждым полем, по мере того, как оно обрабатывается в задании:
| Поле | Входные данные (JSON) | Унаследованный тип (ASA) | Выходные данные (Azure SQL) | Комментарий |
|---|---|---|---|---|
deviceId |
number | bigint | integer | |
readingTimestamp |
строка | nvarchar(MAX) | datetime2 | |
readingStr |
строка | nvarchar(MAX) | nvarchar(200) | Используется определяемой пользователем функцией |
readingNum |
number | с плавающей запятой | decimal(18,2) | Округляется |
readingArray |
array(string) | Массив nvarchar(MAX) | integer | Подсчитывается |
Необходимые компоненты
Мы разработаем запрос в Visual Studio Code с помощью расширения ASA Tools. В первых шагах этого руководства описано, как установить необходимые компоненты.
В VS Code мы будем использовать локальные выполнения с локальными входными и выходными данными, чтобы избежать затрат и ускорить цикл отладки. Нам не потребуется настраивать концентратор событий или Базу данных SQL Azure.
Базовый запрос
Начнем с базовой реализации без проверки входных данных. Мы добавим ее в следующем разделе.
В VS Code мы создадим проект ASA.
В папке мы input создадим JSON-файл с именем data_readings.json и добавим в него следующие записи:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Затем мы определим локальные входные данные с именем readings, которые будут ссылаться на JSON-файл, созданный выше.
После настройки он должен выглядеть так:
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Выполнив предварительный просмотр данных, мы можем убедиться, что наши записи загружены правильно.
Мы создадим новую определяемую пользователем функцию JavaScript с именем udfLen, щелкнув папку Functions правой кнопкой мыши и выбрав пункт ASA: Add Function. Код, который мы будем использовать:
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
В локальных выполнениях не нужно определять выходные данные. Нам даже не нужно использовать INTO, если у нас один набор выходных данных. В файле .asaql можно заменить существующий запрос следующим:
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Давайте кратко рассмотрим отправленный запрос:
- Чтобы подсчитать количество записей в каждом массиве, сначала необходимо распаковать их. Мы будем использовать CROSS APPLY и GetArrayElements() (дополнительные примеры здесь)
- Так мы выделим в запросе два набора данных: исходные входные данные и значения массива. Чтобы не путать поля, мы определяем псевдонимы (
AS r). - Чтобы на самом деле посчитать (с помощью
COUNT) значения массива, нам нужно агрегировать их, используя GROUP BY. - Для этого необходимо определить временной интервал. Поскольку для нашей логики это не требуется, нам подойдет окно моментального снимка.
- Так мы выделим в запросе два набора данных: исходные входные данные и значения массива. Чтобы не путать поля, мы определяем псевдонимы (
- Мы также должны применить операцию
GROUP BYко всем полям и спроецировать их вSELECT. Явно проецируемые поля являются хорошей практикой, так какSELECT *позволить ошибкам передаваться из входных данных в выходные данные.- При определении временного интервала, возможно, потребуется задать метку времени с помощью TIMESTAMP BY. В данном случае это не требуется для работы нашей логики. Для локальных выполнений без
TIMESTAMP BYвсе записи загружается в одну метку времени — время начала выполнения.
- При определении временного интервала, возможно, потребуется задать метку времени с помощью TIMESTAMP BY. В данном случае это не требуется для работы нашей логики. Для локальных выполнений без
- Мы используем определяемую пользователем функцию для фильтрации показаний, где у
readingStrменее двух символов. Здесь следовало бы применять LEN. Мы используем определяемую пользователем функцию только в целях демонстрации.
Можно запустить выполнение и следить за обрабатываемыми данными:
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Строка | 1,71 | 2 |
| 2 | 2021-12-10T10:01:00 | Другая строка | 2.38 | 1 |
| 3 | 2021-12-10T10:01:20 | Третья строка | -4,85 | 3 |
| 1 | 2021-12-10T10:02:10 | Четвертая строка | 1,21 | 2 |
Теперь, когда мы знаем, что наш запрос работает, давайте протестируем его на большем количестве данных. Давайте заменим содержимое data_readings.json следующими записями:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Здесь можно увидеть следующие проблемы:
- Устройство 1 выполнило все правильно.
- Устройство 2 забыло включить
readingStr. - Устройство 3 отправило
NaNкак число. - Устройство 4 отправило пустую запись вместо массива.
Выполнение задания теперь должно завершаться ошибкой. Мы получим одно из следующих сообщений.
Для устройства 2:
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
Для устройства 3:
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
Для устройства 4:
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
Каждый раз неправильная запись попадает из входных данных в основную логику запроса без проверки. Теперь мы понимаем пользу проверки входных данных.
Реализация проверки входных данных
Давайте дополним наш запрос, чтобы проверять входные данные.
Первый этап проверки входных данных — определение ожидаемой схемы для основной бизнес-логики. Если обратиться к первоначальному требованию, наша основная логика должна:
- Передать
readingStrв определяемую пользователем функцию JavaScript для измерения длины. - Подсчитать количество записей в массиве.
- Округлить
readingNumдо второго десятичного разряда. - Вставить данные в таблицу SQL.
Для каждого пункта мы можем перечислить ожидания:
- Для определяемой пользователем функции требуется аргумент в виде строки (здесь — nvarchar (max)), который не может иметь значение NULL.
GetArrayElements()требуется аргумент в виде массива или значение NULL.Roundтребуется аргумент типа bigint или float или значение NULL.- Вместо того, чтобы полагаться на неявное приведение ASA, необходимо сделать это самостоятельно и обработать конфликты типов в запросе.
Одним из способов — адаптировать основную логику для обработки этих исключений. Но мы считаем, что наша основная логика работает идеально. Поэтому давайте проверять входные данные.
Сначала мы используем оператор WITH, чтобы добавить слой проверки входных данных в качестве первого шага запроса. Мы будем использовать TRY_CAST, чтобы преобразовывать поля к ожидаемому типу и присваивать им значение NULL, если преобразование завершилось ошибкой:
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
Для входного файла, который мы использовали последним (тот, что с ошибками), запрос вернет следующий набор:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Строка | 1,7145 | ["A","B"] | 1 | 2021-12-10T10:00:00.0000000Z | Строка | 1,7145 | ["A","B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2,378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2,378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Третья строка | Nan | ["D","E","F"] | 3 | 2021-12-10T10:01:20.0000000Z | Третья строка | NULL | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | Четвертая строка | 1,2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | Четвертая строка | 1,2126 | NULL |
Мы уже видим, что две наши ошибки устранены. Мы преобразовали NaN и {} в NULL. Теперь мы уверены, что эти записи будут правильно вставлены в целевую таблицу SQL.
Сейчас необходимо решить, что делать с записями, у которых нет значений или недопустимые значения. После некоторого обсуждения мы решили отклонять записи с пустым или недопустимым значением readingArray или отсутствующим значением readingStr.
Поэтому мы добавим второй слой, который будет рассматривать записи после проверки и перед отправкой в основную логику:
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
Рекомендуется использовать один оператор WHERE для обоих наборов выходных данных и — NOT (...) для второго. Таким образом, мы предотвратим потерю записей, так как их нельзя будет исключить одновременно из обоих наборов выходных данных.
Теперь мы получаем два набора выходных данных. Debug1 содержит записи, которые будут отправлены в основную логику:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Строка | 1,7145 | ["A","B"] |
| 3 | 2021-12-10T10:01:20.0000000Z | Третья строка | NULL | ["D","E","F"] |
Debug2 содержит записи, которые будут отклонены:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2,378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2,378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | Четвертая строка | 1,2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | Четвертая строка | 1,2126 | NULL |
Последний этап — возвращение нашей основной логики. Мы также добавим выходные данные, где собраны отклоненные записи. Здесь лучше использовать выходной адаптер, который не выполняет принудительную строгую типизацию в отличие от учетной записи хранения.
Полный код запроса представлен в последнем разделе.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
Мы получим следующий набор для SQLOutput без ошибок:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Строка | 1,7145 | 2 |
| 3 | 2021-12-10T10:01:20.0000000Z | Третья строка | NULL | 3 |
Другие две записи отправляются в BlobOutput для проверки человеком и последующей обработки. Теперь наш запрос безопасный.
Пример запроса с проверкой входных данных
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Расширение проверки входных данных
Функцию GetType можно использовать для явной проверки типа. Она хорошо работает с оператором CASE в проекции или WHERE на уровне наборов. Функцию GetType также можно использовать для динамической проверки входящей схемы относительно репозитория метаданных. Репозиторий можно загрузить с помощью эталонного набора данных.
Модульное тестирование поможет проверить устойчивость нашего запроса. Мы создадим серию тестов, состоящих из входных файлов и ожидаемых выходных данных. Тест пройден, если результаты нашего запроса совпадают с этими данными. В ASA модульное тестирование выполняется с помощью модуля npm asa-streamanalytics-cicd. Тестовые случаи с различными неправильными событиями должны создаваться и проверяться в конвейере развертывания.
Наконец, можно выполнить в VS Code некоторые простые тесты интеграции. Мы можем вставить записи в таблицу SQL с помощью локального выполнения с выводом данных в реальном времени.
Поддержка
За дополнительной информацией перейдите на страницу вопросов и ответов об Azure Stream Analytics.
Следующие шаги
- Настройка конвейеров CI/CD и модульного тестирования с помощью пакета NPM
- Обзор локальных выполнений Stream Analytics в Visual Studio Code с помощью инструментов ASA
- Локальное тестирование запросов Stream Analytics с использованием примера данных и Visual Studio Code
- Локальное тестирование запросов Stream Analytics с использованием источника динамических входных потоковых данных в Visual Studio Code
- Просмотр заданий Azure Stream Analytics в Visual Studio Code (предварительная версия)