Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом сценарии показано, как подключиться к OneLake через Azure Databricks. После выполнения этого руководства вы сможете читать и записывать данные в Microsoft Fabric lakehouse из рабочей области Azure Databricks.
Необходимые компоненты
Перед подключением необходимо:
- Рабочая область Fabric и lakehouse.
- Рабочая область Azure Databricks уровня "Премиум". Только рабочие области Azure Databricks уровня "Премиум" поддерживают сквозное руководство учетных данных Microsoft Entra, которое требуется для этого сценария.
Настройка рабочей области Databricks
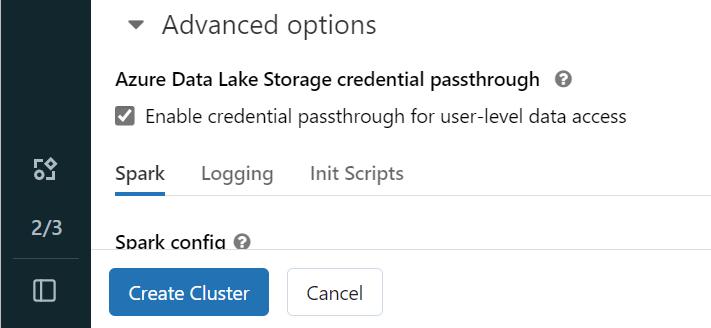
Откройте рабочую область Azure Databricks и выберите "Создать>кластер".
Чтобы выполнить проверку подлинности в OneLake с помощью удостоверения Microsoft Entra, необходимо включить сквозное руководство по учетным данным Azure Data Lake служба хранилища (ADLS) в кластере в разделе "Дополнительные параметры".
Примечание.
Вы также можете подключить Databricks к OneLake с помощью субъекта-службы. Дополнительные сведения об аутентификации Azure Databricks с помощью субъекта-службы см. в статье "Управление субъектами-службами".
Создайте кластер с предпочитаемыми параметрами. Дополнительные сведения о создании кластера Databricks см. в разделе "Настройка кластеров " Azure Databricks".
Откройте записную книжку и подключите ее к созданному кластеру.
Создание записной книжки
Перейдите к Azure Lakehouse и скопируйте путь к файловой системе BLOB-объектов Azure (ABFS) в озеро. Его можно найти в области "Свойства ".
Примечание.
Azure Databricks поддерживает только драйвер Файловой системы BLOB-объектов Azure (ABFS) при чтении и записи в ADLS 2-го поколения и OneLake:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/Сохраните путь к lakehouse в записной книжке Databricks. В этом лейкхаусе вы записываете обработанные данные позже:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Загрузите данные из общедоступного набора данных Databricks в кадр данных. Вы также можете прочитать файл из другого места в Fabric или выбрать файл из другой учетной записи ADLS 2-го поколения.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Фильтрация, преобразование или подготовка данных. В этом сценарии можно обрезать набор данных для ускорения загрузки, объединения с другими наборами данных или фильтрации до определенных результатов.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Напишите отфильтрованный кадр данных в Azure Lakehouse с помощью пути OneLake.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Проверьте успешность записи данных, прочитав только что загруженный файл.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Поздравляем. Теперь вы можете читать и записывать данные в Fabric с помощью Azure Databricks.