Export Dataverse údajov vo formáte Delta Lake
Pomocou Azure Synapse Link for Dataverse exportujte svoje Microsoft Dataverse údaje do Azure Synapse Analytics vo formáte Delta Lake. Potom preskúmajte svoje údaje a urýchlite čas potrebný na získanie informácií. Tento článok poskytuje nasledujúce informácie a ukazuje, ako vykonať nasledujúce úlohy:
- Vysvetľuje Delta Lake and Parquet a prečo by ste mali exportovať údaje v tomto formáte.
- Exportujte svoje Dataverse údaje do svojho Azure Synapse Analytics pracovného priestoru vo formáte Delta Lake pomocou Azure Synapse Link.
- Monitorujte Azure Synapse Link a konverziu údajov.
- Pozrite si svoje údaje z Azure Data Lake Storage Gen2.
- Zobrazte svoje údaje zo Synapse Workspace.
Dôležité
- Ak inovujete z CSV na Delta Lake s existujúcimi vlastnými zobrazeniami, odporúčame vám aktualizovať skript tak, aby nahradil všetky rozdelené tabuľky na nerozdelené. Urobte to tak, že vyhľadáte inštancie
_partitioneda nahraďte ich prázdnym reťazcom. - Pre konfiguráciu Dataverse je predvolene povolené iba pripojenie na export údajov CSV v režime
appendonly. Tabuľka Delta Lake však bude mať štruktúru aktualizácie na mieste, pretože konverzia Delta Lake prichádza s pravidelným procesom zlučovania. - S vytvorením bazénov Spark nevznikajú žiadne náklady. Poplatky sa účtujú až po vykonaní úlohy Spark v cieľovom fonde Spark a po vytvorení inštancie Spark na požiadanie. Tieto náklady súvisia s používaním Azure Synapse pracovného priestoru Spark a sú fakturované mesačne. Náklady na realizáciu Spark computingu závisia hlavne od časového intervalu pre prírastkovú aktualizáciu a od objemu dát. Viac informácií: Azure Synapse Analytics cena
- Pri rozhodovaní o použití tejto funkcie je dôležité vziať do úvahy tieto dodatočné náklady, pretože nie sú voliteľné a ak chcete túto funkciu naďalej používať, musíte ich zaplatiť.
- Koniec životnosti (EOLA) pre Azure Synapse Runtime for Apache Spark 3.1 bol ohlásený 26. januára 2023. V súlade s politikou životného cyklu Synapse runtime for Apache Spark bude Azure Synapse runtime for Apache Spark 3.1 k 26. januáru 2024 ukončené a deaktivované. Po dátume EOL nie sú vyradené runtime k dispozícii pre nové fondy Spark a existujúce pracovné postupy sa nedajú spustiť. Metadáta dočasne zostanú v pracovnom priestore Synapse. Viac informácií: Azure Synapse Runtime for Apache Spark 3.1 (EOLA). Ak chcete, aby bol váš Synapse Link pre Dataverse s exportom do formátu Delta Lake inovovaný na Spark 3.3, vykonajte inováciu svojich existujúcich profilov priamo na mieste. Ďalšie informácie: Inovácia na mieste na Apache Spark 3.3 s Delta Lake 2.2
- Od 4. januára 2024 bude pri prvotnom vytváraní prepojenia podporovaná iba verzia Spark Pool 3.3.
Poznámka
Stav Azure Synapse Link v Power Apps (make.powerapps.com) odráža stav konverzie jazera Delta:
Countzobrazuje počet záznamov v tabuľke Delta Lake.Last synchronized onDatetime predstavuje časovú pečiatku poslednej úspešnej konverzie.Sync statussa po synchronizácii údajov a konverzii Delta Lake zobrazí ako aktívne, čo znamená, že údaje sú pripravené na spotrebu.
Čo je jazero Delta?
Delta Lake je projekt s otvoreným zdrojovým kódom, ktorý umožňuje vybudovať architektúru Lakehouse na vrchole dátových jazier. Delta Lake poskytuje ACID (atomicita, konzistencia, izolácia a trvanlivosť) transakcie, škálovateľné spracovanie metadát a zjednocuje streamovanie a dávkové spracovanie dát nad existujúcimi dátovými jazerami. Azure Synapse Analytics je kompatibilný s Linux Foundation Delta Lake. Aktuálna verzia Delta Lake, ktorá je súčasťou Azure Synapse , má jazykovú podporu pre Scala, PySpark a .NET. Viac informácií: Čo je jazero Delta?. Viac sa môžete dozvedieť aj z videa Úvod do delta tabuliek.
Apache Parquet je základný formát pre Delta Lake, ktorý vám umožňuje využiť efektívne schémy kompresie a kódovania, ktoré sú pre tento formát prirodzené. Formát súboru Parket používa kompresiu po stĺpcoch. Je efektívny a šetrí úložný priestor. Dotazy, ktoré načítavajú konkrétne hodnoty stĺpcov, nemusia čítať celé údaje riadka, čím sa zvyšuje výkon. Bezserverová oblasť SQL preto potrebuje na čítanie údajov menej času a menej požiadaviek na úložisko.
Prečo používať jazero Delta?
- Škálovateľnosť: Delta Lake je postavená na licencii Open-source Apache, ktorá je navrhnutá tak, aby spĺňala priemyselné štandardy na spracovanie rozsiahlych úloh spracovania údajov.
- Spoľahlivosť: Delta Lake poskytuje transakcie ACID, čím zaisťuje konzistentnosť a spoľahlivosť údajov aj pri zlyhaní alebo súbežnom prístupe.
- Výkon: Delta Lake využíva stĺpcový formát úložiska Parquet, ktorý poskytuje lepšiu kompresiu a techniky kódovania, čo môže viesť k lepšiemu výkonu dotazov v porovnaní s dotazovacími súbormi CSV.
- Cenovo výhodné: Formát súborov Delta Lake je vysoko komprimovaná technológia ukladania údajov, ktorá firmám ponúka značné potenciálne úspory pri ukladaní. Tento formát je špeciálne navrhnutý na optimalizáciu spracovania údajov a potenciálne zníženie celkového množstva spracovaných údajov alebo času chodu potrebného na výpočty na požiadanie.
- Súlad s ochranou údajov: Delta Lake s Azure Synapse Link poskytuje nástroje a funkcie vrátane mäkkého a tvrdého odstránenia, aby boli v súlade s rôznymi nariadeniami o ochrane osobných údajov vrátane Všeobecné nariadenie o ochrane údajov (GDPR).
Ako funguje Delta Lake s Azure Synapse Link for Dataverse?
Pri nastavovaní Azure Synapse Link for Dataverse môžete povoliť export do Delta Lake a pripojiť sa k pracovnému priestoru Synapse a bazénu Spark. Azure Synapse Link exportuje vybrané Dataverse tabuľky vo formáte CSV v určených časových intervaloch a spracuje ich prostredníctvom úlohy Spark konverzie Delta Lake. Po dokončení tohto procesu konverzie sa údaje CSV vyčistia, aby sa ušetrilo miesto. Okrem toho je na dennej báze naplánované spustenie série údržba úloh, ktoré automaticky vykonávajú procesy zhutňovania a vysávania, aby sa zlúčili a vyčistili dátové súbory, aby sa ďalej optimalizovalo úložisko a zlepšil sa výkon dotazov.
Požiadavky
- Dataverse: Musíte mať Dataverse správcu systému rola zabezpečenia. Okrem toho tabuľky, ktoré chcete exportovať cez Azure Synapse Link , musia mať povolenú vlastnosť Sledovať zmeny . Viac informácií: Rozšírené možnosti
- Azure Data Lake Storage Gen2: Musíte mať účet Azure Data Lake Storage Gen2 a rolu prístupu Vlastník a Prispievateľ dát do úložiska Blob. Váš účet úložiska musí povoliť Hierarchický priestor názvov a prístup k verejnej sieti pre úvodné nastavenie aj delta synchronizáciu. Povoliť prístup kľúča účtu úložiska je potrebné iba na úvodné nastavenie.
- Pracovný priestor Synapse: Musíte mať pracovný priestor Synapse a Vlastník rolu v riadení prístupu (IAM) a Správcu Synapse rolový prístup v rámci Synapse Studio. Pracovný priestor Synapse musí byť v rovnakej oblasti ako váš účet Azure Data Lake Storage Gen2. Účet úložiska musí byť pridaný ako prepojená služba v aplikácii Synapse Studio. Ak chcete vytvoriť pracovný priestor Synapse, prejdite na Vytvorenie pracovného priestoru Synapse.
- Spark Pool v pripojenom Azure Synapse pracovnom priestore s Apache Spark Verzia 3.3 pomocou tejto odporúčanej konfigurácie Spark Pool. Informácie o tom, ako vytvoriť fond Spark, nájdete v časti Vytvoriť nový Apache Spark pool.
- Minimálna požiadavka na Microsoft Dynamics 365 verziu na používanie tejto funkcie je 9.2.22082. Ďalšie informácie: Aktivujte si aktualizácie skorého prístupu
Odporúčaná konfigurácia Spark Pool
Túto konfiguráciu možno považovať za bootstrap krok pre prípady priemerného použitia.
- Veľkosť uzla: malá (4 vCores / 32 GB)
- Autoscale: Povolené
- Počet uzlov: 5 až 10
- Automatické pozastavenie: povolené
- Počet minút nečinnosti: 5
- Apache Spark: 3.3
- Dynamicky prideľovať vykonávateľov: Povolené
- Predvolený počet vykonávateľov: 1 až 9
Pripojte sa Dataverse k pracovnému priestoru Synapse a exportujte údaje vo formáte Delta Lake
Power Apps Prihláste sa a vyberte požadované prostredie.
Na ľavej navigačnej table vyberte Azure Synapse Link. Ak sa položka nenachádza na table bočného panela, vyberte položku … Viac a potom vyberte požadovanú položku.
Na paneli príkazov vyberte + Nové prepojenie
Vyberte položku Pripojiť k pracovnému Azure Synapse Analytics priestoru a potom vyberte položky Predplatné, Skupina zdrojov a Názov pracovného priestoru.
Vyberte položku Použiť Spark pool na spracovanie a potom vyberte vopred vytvorené konto Spark pool a Storage.
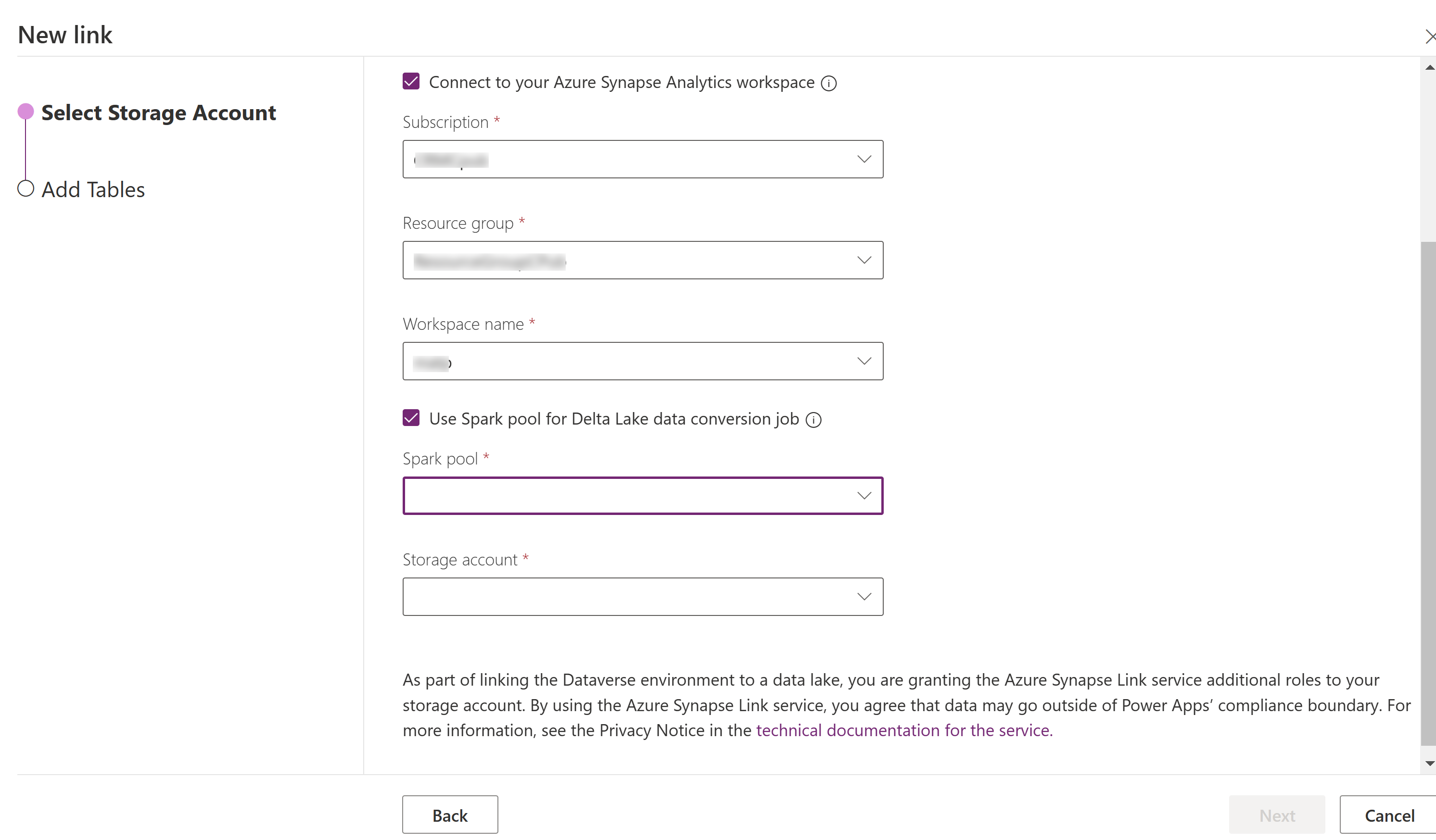
Vyberte Ďalej.
Pridajte tabuľky, ktoré chcete exportovať, a potom vyberte položku Rozšírené.
Voliteľne môžete vybrať možnosť Zobraziť rozšírené nastavenia konfigurácie a v minútach zadať časový interval, v ktorom sa majú zachytávať prírastkové aktualizácie.
Vyberte Uložiť.
Sledujte svoju Azure Synapse Link konverziu dát
- Vyberte požadované tlačidlo Azure Synapse Link a potom na paneli príkazov vyberte položku Prejsť do Azure Synapse Analytics pracovného priestoru .
- Vyberte položku Monitorovať > Apache Spark aplikácie. Ďalšie informácie: Použitie Synapse Studio na monitorovanie aplikácií Apache Spark
Zobrazenie údajov z pracovného priestoru Synapse
- Vyberte požadované tlačidlo Azure Synapse Link a potom na paneli príkazov vyberte položku Prejsť do Azure Synapse Analytics pracovného priestoru .
- Rozbaľte Lake Databases *na ľavej table, vyberte *** dataverse-environmentNameorganizationUniqueName **** a potom rozbaľte Tables . Všetky parketové tabuľky sú uvedené a dostupné na analýzu pomocou konvencie pomenovania DataverseTableName. (Non_partitioned tabuľka).
Poznámka
Nepoužívajte tabuľky s konvenciou pomenovania_partitioned. Keď ako formát vyberiete parkety Delta, tabuľky _partition s konvenciou pomenovania sa použijú ako tabuľky a odstránia sa po ich použití systémom.
Zobrazenie údajov z Azure Data Lake Storage Gen2
- Vyberte požadované a Azure Synapse Link potom na paneli príkazov vyberte položku Prejsť do údajového jazera Azure.
- Vyberte možnosť Kontajnery v časti Úložisko údajov.
- Vyberte *dataverse-environmentName-organizationUniqueName *. Všetky parketové súbory sú uložené v priečinku deltalake .
Na mieste upgrade na Apache Spark 3.3 s Delta Lake 2.2
Požiadavky
- Musíte mať existujúci Azure Synapse Link for Dataverse profil Delta Lake spustený s verziou Synapse Spark 3.1.
- Musíte vytvoriť nový fond Synapse Spark s verziou Spark verzie 3.3 s použitím hardvérovej konfigurácie rovnakých alebo vyšších uzlov v rámci rovnakého pracovného priestoru Synapse. Informácie o tom, ako vytvoriť fond Spark, nájdete v časti Vytvoriť nový Apache Spark pool. Tento bazén Spark by mal byť vytvorený nezávisle od súčasného bazéna 3.1.
Priama inovácia na Spark 3.3:
- Prihláste sa a Power Apps vyberte preferované prostredie.
- Na ľavej navigačnej table vyberte Azure Synapse Link. Ak sa položka nenachádza na ľavej navigačnej table, vyberte ... Viac a potom vyberte požadovanú položku.
- Azure Synapse Link Otvorte profil a potom vyberte položku Upgrade to Apache Spark 3.3 with Delta Lake 2.2.
- Vyberte dostupný fond Spark zo zoznamu a potom vyberte možnosť Aktualizovať.
Poznámka
K inovácii fondu Spark dôjde iba vtedy, keď sa spustí nová úloha Spark konverzie Delta Lake. Po výbere Aktualizovať sa uistite, že máte aspoň jednu zmenu údajov.
Pozrite si tiež
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre