Vytvorenie vizualizácií kľúčových vplyvov
VZŤAHUJE SA NA:![]() služba Power BI aplikácie Power BI Desktop
služba Power BI aplikácie Power BI Desktop ![]()
Vizuál kľúčových vplyvov vám pomôže porozumieť faktorom riadiacim metriku, ktorá vás zaujíma. Analyzuje údaje, radí faktory, ktoré sú dôležité, a zobrazuje ich ako kľúčové vplyvy. Predpokladajme napríklad, že chcete zistiť, čo ovplyvňuje fluktuáciu zamestnancov, ktorá sa označuje aj ako výpovede. Jedným faktorom môže byť doba platnosti pracovnej zmluvy a ďalším faktorom môže byť čas dochádzať.
Kedy použiť kľúčové vplyvy
Vizuál kľúčových vplyvov je skvelou voľbou, ak chcete:
- Pozrite si, ktoré faktory vplývajú na analyzovanú metriku.
- porovnať relatívnu dôležitosť týchto faktorov, Napríklad to, či majú krátkodobé zmluvy vplyv na výpovede viac ako dlhodobé zmluvy?
Funkcie vizuálu kľúčových vplyvov
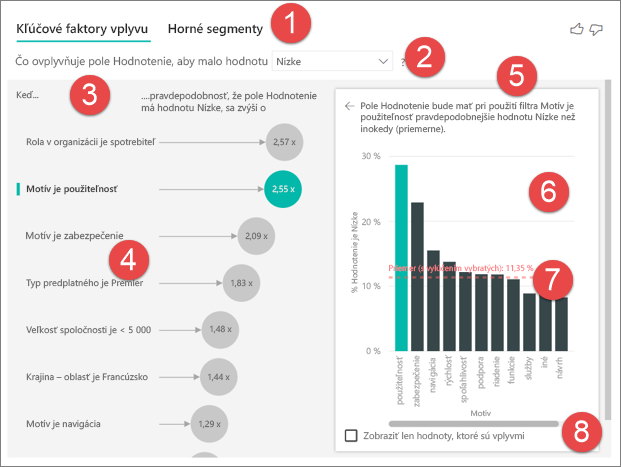
Karty: výberom karty prepnete medzi zobrazeniami. Kľúčové vplyvy zobrazujú, čo najviac prispieva k hodnote vybranej metriky. Horné segmenty zobrazujú horné segmenty, ktoré prispievajú k hodnote vybranej metriky. Segment je tvorené kombináciou hodnôt. Napríklad jeden segment môže predstavovať spotrebiteľov, ktorí sú zákazníkmi po dobu minimálne 20 rokov a žijú v západnej oblasti.
Rozbaľovací zoznam: Hodnota metriky, ktorá sa skúma. V tomto príklade sa pozrieme na metriku Hodnotenie. Vybratá hodnota je Low (Nízke).
Preformulovanie: Pomáha nám interpretovať vizuál na ľavej table.
Ľavá tabla: Ľavá tabla obsahuje jeden vizuál. V tomto prípade ľavá tabla zobrazuje zoznam najvýznamnejších kľúčových vplyvov.
Preformulovanie: Pomáha nám interpretovať vizuál na pravej table.
Pravá tabla: Pravá tabla obsahuje jeden vizuál. V tomto prípade stĺpcový graf zobrazuje všetky hodnoty pre kľúčový vplyv Theme (Motív ), ktorý bol vybratý na ľavej table. Konkrétna hodnota použiteľnosti z ľavej tably sa zobrazí v zelenej farbe. Všetky ostatné hodnoty pre Theme (Motív ) sú zobrazené v čiernej farbe.
Spojnica priemeru: Priemer sa vypočítava pre všetky možné hodnoty pre Theme (Motív ) okrem položky použiteľnosť (ktorá je vybratá ako vplyv). Výpočet sa preto vzťahuje na všetky hodnoty čiernej farby. Informuje o tom, aké percento iných Themes (Motívov ) malo nízke hodnotenie. V tomto prípade 11,35 % malo nízke hodnotenie (zobrazené bodkovanou čiarou).
Začiarkavacie políčko: Filtruje vizuál na pravej table a zobrazí iba hodnoty, ktoré sú vplyvmi pre dané pole. V tomto príklade sa vizuál vyfiltruje tak, aby zobrazoval použiteľnosť, zabezpečenie a navigáciu.
Analýza metriky, ktorá je kategorická
Pozrite si toto video a zistite, ako vytvoriť vizuál kľúčových vplyvov s kategorickou metrikou. Potom ho vytvorte pomocou uvedených krokov.
Poznámka
Toto video môže používať staršie verzie aplikácie Power BI Desktop alebo služba Power BI.
- Váš produktový manažér chce zistiť, ktoré faktory viedli k tomu, že zákazníci zanechali negatívne recenzie vašej cloudovej služby. Ak chcete pokračovať v aplikácii Power BI Desktop, otvorte súbor Customer Feedback PBIX.
Poznámka
Množina údajov Customer Feedback vychádza z nasledujúceho súboru: Moro a kol., 2014 (S. Moro, P. Cortez a P. Rita). "Data-Driven prístup predpovedať úspech bankovej telemarketing." Decision Support Systems, Elsevier, č. 62, s. 22-31, jún 2014.
V časti Vytvoriť vizuál na table Vizualizácie vyberte ikonu Kľúčových vplyvov.
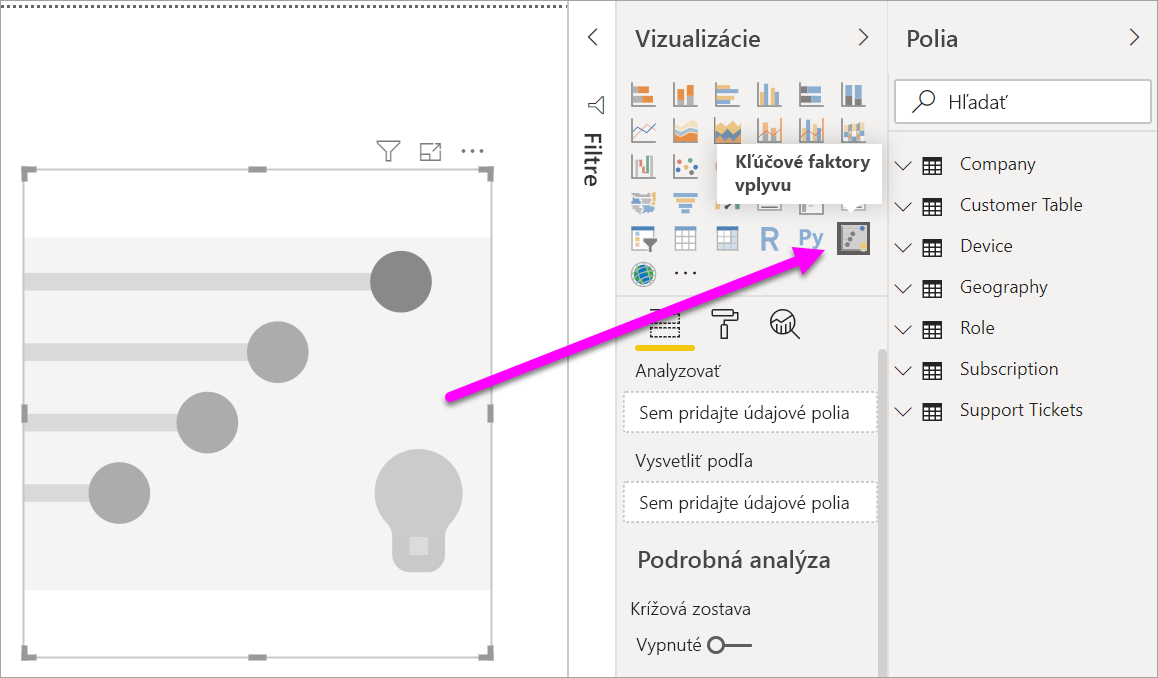
Presuňte metriku, ktorú chcete skúmať, do poľa Analyzovať . Ak chcete zistiť, čo vedie zákazníka k tomu, aby službu hodnotí nízko, vyberte položku Hodnotenie tabuľky>zákazníka.
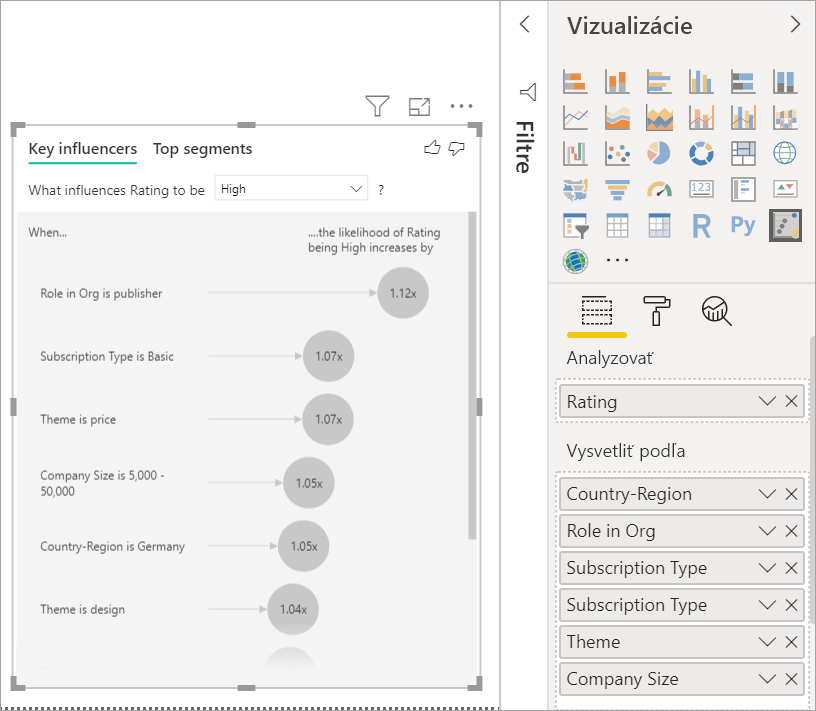
Presuňte polia, ktoré si myslíte, že mohli mať vplyv na pole Hodnotenie , do poľa Vysvetliť podľa . Môžete presunúť ľubovoľný počet polí. V tomto prípade začnite s nasledovnými:
- Country-Region (Krajina – oblasť)
- Role in Org
- Typ predplatného
- Company Size
- Theme
Nechajte pole Spôsob rozbalenia prázdne. Toto pole sa používa iba pri analýze mierky alebo pri súhrnnom poli.
Ak sa chcete zamerať na negatívne hodnotenia, vyberte možnosť Low (Nízke ) v rozbaľovacom poli Čo ovplyvňuje pole Hodnotenie, aby malo hodnotu .
Analýza sa spustí na úrovni tabuľky analyzovaného poľa. V tomto prípade je metrika Rating (Hodnotenie ). Táto metrika je definovaná na úrovni zákazníka. Každý zákazník zadal vysoké skóre alebo nízke skóre. Na to, aby ich vizuál využil, musia byť všetky vysvetľujúce faktory definované na úrovni zákazníka.
V predchádzajúcom príklade majú všetky vysvetľujúce faktory s metrikou buď vzťah "one-to-one" alebo "many-to-one". V tomto prípade každý zákazník priradil k hodnoteniu jeden motív. Podobne zákazníci pochádzajúci z jednej krajiny alebo oblasti, majú jeden typ členstva a majú jednu rolu v organizácii. Vysvetľujúce faktory sú už atribútmi zákazníkov a nie sú potrebné žiadne transformácie. Vizuál ich dokáže okamžite použiť.
Neskôr sa v tomto kurze pozrieme na komplexnejšie príklady, ktoré majú vzťah "one-to-many". V týchto prípadoch je pred spustením analýzy najskôr potrebné stĺpce agregovať na úroveň zákazníka.
Mierky a agregáty používané ako vysvetľujúce faktory sa takisto hodnotia na úrovni tabuľky metriky Analyzovať . Niektoré príklady sú uvedené ďalej v tomto článku.
Interpretácia kľúčových vplyvov kategórií
Pozrime sa na kľúčové vplyvy nízkych hodnotení.
Najvýznamnejší samostatný faktor vplývajúceho na pravdepodobnosť nízkeho hodnotenia
Zákazník v tomto príklade môže mať tri roly: spotrebiteľ, správca a vydavateľ. Najvýznamnejším faktorom, ktorý prispieva k nízkemu hodnoteniu, je byť spotrebiteľom.
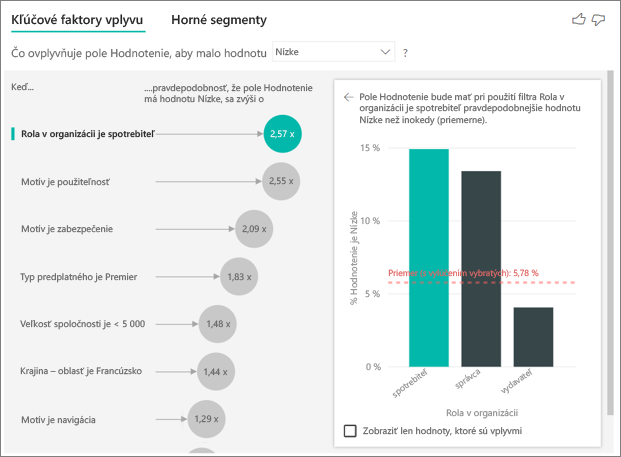
Presnejšie povedané, spotrebitelia majú 2,57-násobne väčšiu pravdepodobnosť, že udelia vašej službe negatívne skóre. Graf kľúčových vplyvov uvádza Role in Org is consumer (Rola v organizácii je spotrebiteľ ) ako prvú hodnotu zoznamu vľavo. Výberom položky Role in Org is consumer (Rola v organizácii je spotrebiteľ) zobrazí Power BI ďalšie podrobnosti na pravej table. Zobrazený je porovnávací vplyv každej roly na pravdepodobnosť nízkeho hodnotenia.
- 14,93 % spotrebiteľov udelí nízke skóre,
- Všetky ostatné roly v priemere udelia nízke skóre v 5,78 % okamihu.
- Spotrebitelia majú 2,57-násobne väčšiu pravdepodobnosť, že udelia nízke skóre v porovnaní so všetkými ostatnými rolami. Toto skóre môžete určiť tak, že vydelíte zelený pruh červenou bodkovanou čiarou.
Druhý samostatný faktor vplývaci na pravdepodobnosť nízkeho hodnotenia
Vizuál kľúčových vplyvov porovná a vyraďuje faktory mnohých rôznych premenných. Druhý vplyv vôbec nesúvisí s položkou Role in Org (Rola v organizácii). Vyberte druhý vplyv zo zoznamu, ktorým je Theme is usability (Motív je používanie).
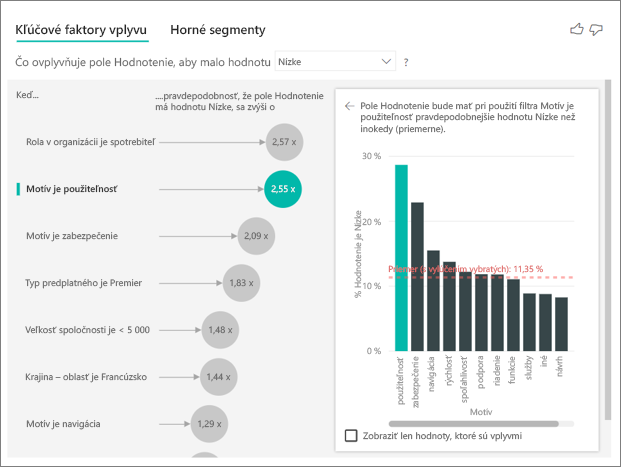
Druhý najdôležitejší faktor súvisí s motívom zákazníckych recenzií. Zákazníci, ktorí komentovali použiteľnosť produktu mali 2,55-násobne vyššiu pravdepodobnosť udeliť nízke skóre v porovnaní so zákazníkmi, ktorí komentovali iné motívy, ako napríklad spoľahlivosť, dizajn alebo rýchlosť.
Na vizuáloch sa priemer, ktorý je zobrazený ako červená bodkovaná čiara, zmenil z 5,78 % na 11,35 %. Priemer je dynamický, pretože vychádza z priemeru všetkých ostatných hodnôt. Pri prvom vplyve bola v priemere vynechaná rola zákazníka. Pri druhom vplyve bol vynechaný motív použiteľnosti.
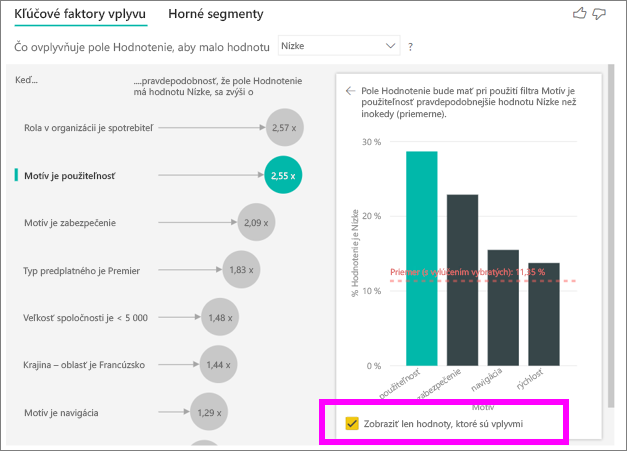
Začiarknutím políčka Zobraziť iba hodnoty, ktoré sú vplyvmi vykonajte filtrovanie iba pomocou vplyvných hodnôt. V tomto prípade sú to roly, ktoré spôsobujú nízke skóre. 12 motívov sa zredukuje na štyri, ktoré služba Power BI identifikovala ako motívy, ktoré spôsobujú nízke hodnotenie.
Interakcia s inými vizuálmi
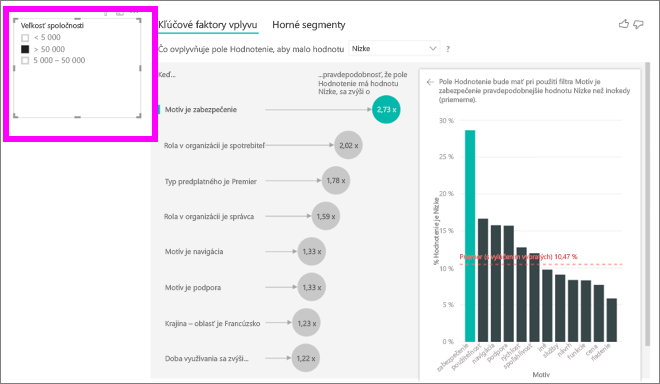
Vždy, keď vyberiete rýchly filter, filter alebo iný vizuál na plátne, vizuál kľúčových vplyvov vráti analýzu novej časti údajov. Môžete napríklad presunúť položku Company Size (Veľkosť spoločnosti) do zostavy a použiť ju ako rýchly filter. Použite ho na to, aby ste zistili, či sú kľúčové vplyvy vašich podnikových zákazníkov odlišné v porovnaní s bežnou populáciou. Spoločnosť, ktorá nazýva podnik (enterprise) má viac ako 50 000 zamestnancov.
Výberom položky >50 000 opätovne spustite analýzu a môžete vidieť, že vplyvy sa zmenili. V prípade zákazníkov veľkých podnikov je najväčším vplyvom nízkeho hodnotenia motív súvisiaci so zabezpečením. Môžete to skúmať viac do hĺbky, aby ste zistili, či sú nejaké konkrétne funkcie zabezpečenia, s ktorými sú veľkí zákazníci nespokojní.
Interpretácia spojitých kľúčových vplyvov
Doposiaľ ste videli, ako sa dá vizuál používať na skúmanie toho, ako polia kategórií ovplyvňujú nízke hodnotenia. V poli Vysvetliť podľa je tiež možné mať spojité faktory, ako je vek, výška a cena. Pozrime sa, čo sa stane, keď presunieme hodnotu Tenure (Doba využívania) z tabuľky zákazníkov do kontajnera Vysvetliť podľa. Tenure (Doba využívania) zobrazuje, ako dlho zákazník službu používa.
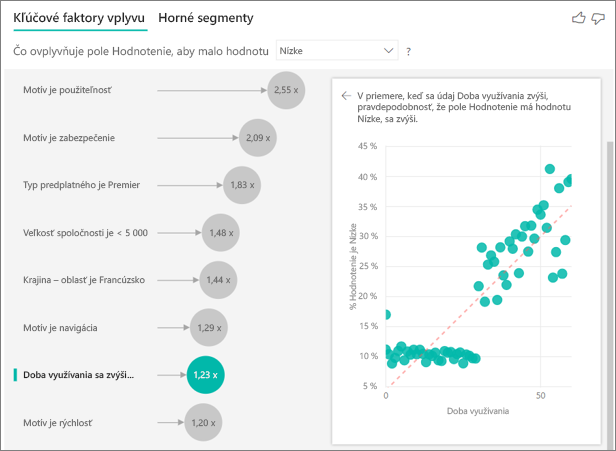
Keď sa doba využívania zvyšuje, pravdepodobnosť nízkeho hodnotenia sa tiež zvyšuje. Tento trend naznačuje, že dlhodobí zákazníci dávajú negatívne skóre s väčšou pravdepodobnosťou. Tento prehľad je zaujímavý a možno ho budete chcieť sledovať aj neskôr.
Vizualizácia ukazuje, že vždy, keď doba využívania stúpa o 13,44 mesiaca, pravdepodobnosť nízkeho hodnotenia stúpa v priemere 1,23-krát. V tomto prípade 13,44 mesiaca vyjadruje smerodajnú odchýlku doba využívania. Takže prehľad, ktorý získate, zobrazuje, ako doba využívania zvýšená o štandardnú hodnotu, ktorou je smerodajná odchýlka doba využívania, ovplyvňuje pravdepodobnosť získania nízkeho hodnotenia.
Bodový graf na pravej table vykreslí priemernú percentuálnu hodnotu nízkych hodnotení pre každú hodnotu doba využívania. Zvýrazní sklon s čiarou trendu.
Rozdelenie spojitých kľúčových vplyvov
V niektorých prípadoch možno zistíte, že vaše spojité faktory sa automaticky zmenili na kategorické. Ak vzťah medzi premennými nie je lineárny, nemôžeme popísať vzťah tak, že sa jednoducho zväčšuje alebo zmenšuje (napríklad v príklade uvedenom vyššie).
Na určenie linearity vplyvu vzhľadom na cieľ sa spustia korelačné testy. Ak je cieľ spojitý, spustí sa Pearsonova korelácia, a ak je cieľ kategorický, spustí sa test korelácie bodu Biserial. Ak zistíme, že vzťah nie je dostatočne lineárny, vykoná sa pod dohľadom rozdelenie a vygeneruje sa maximálne päť priehradiek. Priehradky, ktoré majú najväčší zmysel, vyberieme metódu kontrolovaného rozdelenie, ktorá sa zameriava na vzťah medzi vysvetľujúcim faktorom a analyzovaným cieľom.
Interpretácia mier a agregátov ako kľúčových vplyvov
Vo svojich analýzach môžete ako vysvetľujúce faktory používať mierky a agregáty. Môžete napríklad chcieť zobraziť, aký vplyv má počet žiadostí o podporu zo spoločnosti Customer alebo priemerná doba trvania otvorenej žiadosti na zobrazené skóre.
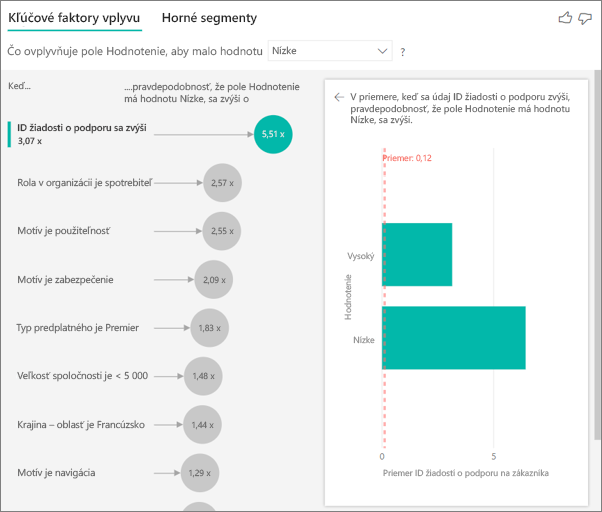
V tomto prípade budete chcieť zobraziť, či počet žiadostí o podporu zo 6. Teraz prinesieme Support Ticket ID (ID žiadosti o podporu) z tabuľky žiadostí o podporu. Keďže zákazník môže mať viacero žiadostí o podporu, vykonáme agregáciu ID na úroveň zákazníka. Agregácia je dôležitá, pretože analýza sa vykoná na úrovni zákazníka, takže všetky spúšťače musia byť definované na úrovni granularity.
Poďme sa pozrieť na počet ID. V každom riadku zákazníka je počet žiadostí o podporu, ktoré s ním súvisia. V tomto prípade, keď počet žiadostí o podporu stúpa, pravdepodobnosť nízkeho hodnotenia stúpa 4,08-krát. Vizuál na pravej strane zobrazuje priemerný počet žiadostí o podporu podľa rôznych hodnôt hodnotenia vyhodnocovaných na úrovni zákazníka.
Interpretácia výsledkov: Horné segmenty
Pomocou karty Kľúčové vplyvy môžete vyhodnotiť každý faktor jednotlivo. Môžete tiež použiť kartu Horné segmenty , kde môžete vidieť, ako kombinácia faktorov ovplyvňuje metriku, ktorú analyzujete.
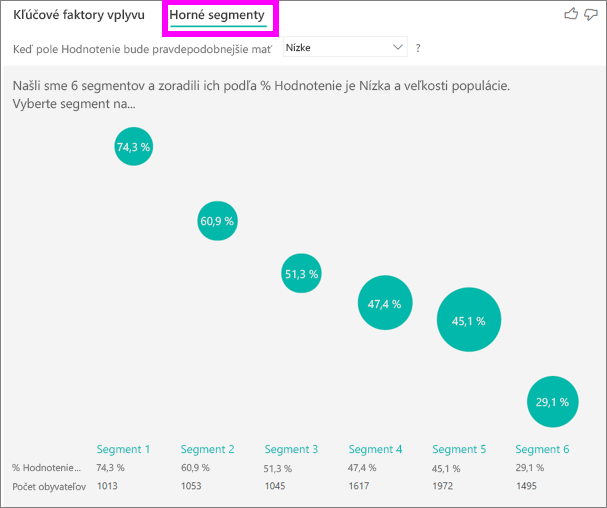
Horné segmenty pôvodne zobrazujú prehľad všetkých segmentov, ktoré služba Power BI zistila. Nasledujúci príklad zobrazuje, že sa našlo šesť segmentov. Tieto segmenty sú hodnotené podľa percenta nízkych hodnotení v rámci segmentu. Napríklad Segment 1 má 74,3 % hodnotení zákazníkov, ktoré sú nízke. Čím vyššie je bublina, tým väčší je podiel nízkych hodnotení. Veľkosť bubliny predstavuje počet zákazníkov v rámci segmentu.
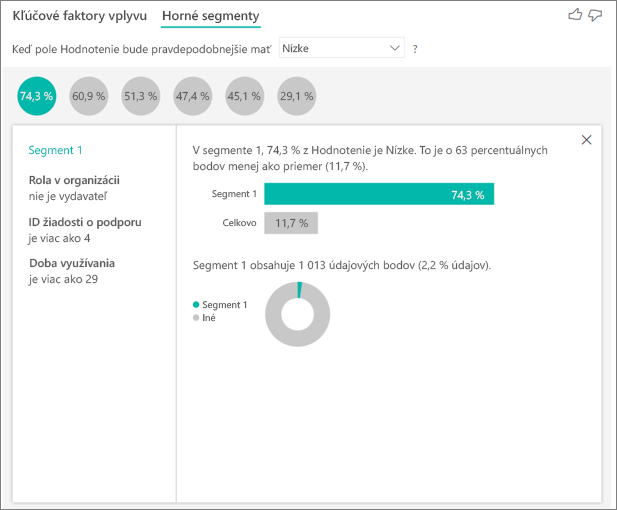
Výberom bubliny sa zobrazia podrobnosti o danom segmente. Ak napríklad vyberiete Segment 1, zistíte, že sa skladá z relatívne zabehaných zákazníkov. Zákazníkmi sú už viac ako 29 mesiacov a majú viac ako štyri žiadosti o podporu. Nie sú vydavateľmi, čiže sú buď spotrebiteľmi alebo správcami.
V tejto skupine udelilo 74,3 % zákazníkov nízke hodnotenie. Priemerný zákazník udelil nízke hodnotenie v 11,7 %ách, čiže tento segment má väčší podiel nízkych hodnotení. Je to o 63 percentuálnych bodov vyššie. Segment 1 tiež obsahuje približne 2,2 % údajov, čiže predstavuje osloviteľnú časť populácie.
Pridávanie počtov
Niekedy môže mať vplyv významný účinok, ale predstavuje len málo údajov. Napríklad Theme (Motív ) je použiteľnosť a je tretím najväčším vplyvom pre nízke hodnotenia. Možno však existovala len hŕstka zákazníkov, ktorá sa sťažovala na použiteľnosť. Počty vám môžu pomôcť určiť, na ktoré vplyvy sa chcete zamerať.
Počty môžete zapnúť prostredníctvom karty Analýza na table formátovanie.
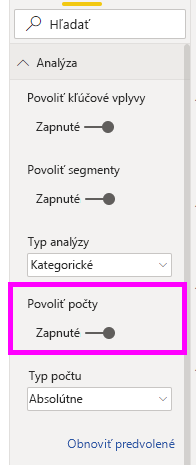
Po povolení počtov sa zobrazí kruh okolo bubliny vplyvu, ktorá predstavuje približné percento údajov, ktoré vplyv obsahuje. Čím viac sa bubliny kruh obkolkol, tým viac údajov, ktoré obsahuje. Môžeme vidieť, že Theme (Motív ) je použiteľnosť a obsahuje malú časť údajov.
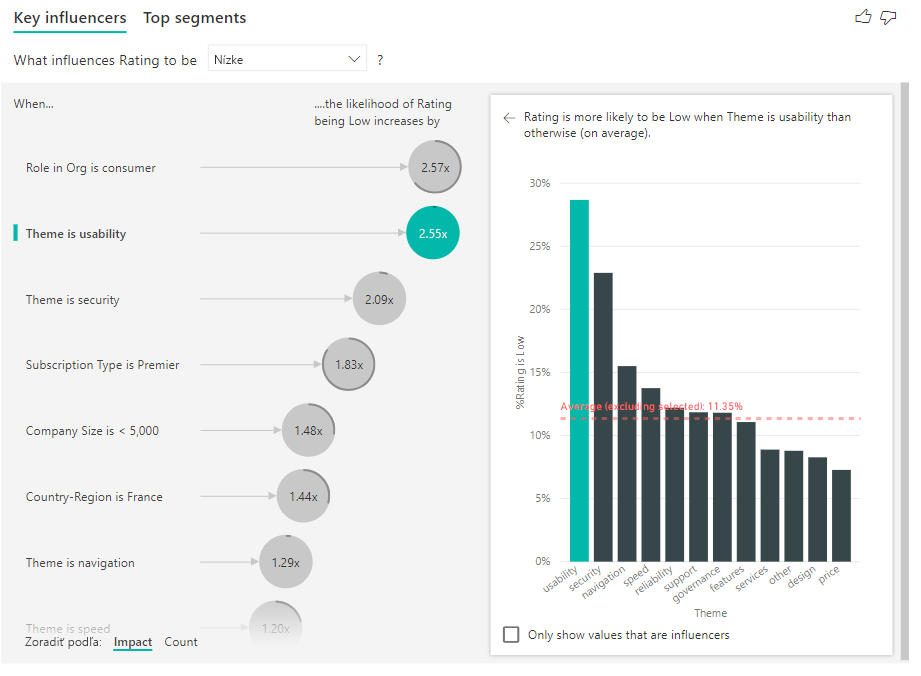
Môžete tiež použiť prepínač Zoradiť podľa v ľavom dolnom rohu vizuálu, aby sa bubliny zoradli najskôr podľa počtu namiesto dopadu. Typ predplatného je Premier a je najlepším vplyvom na základe počtu.
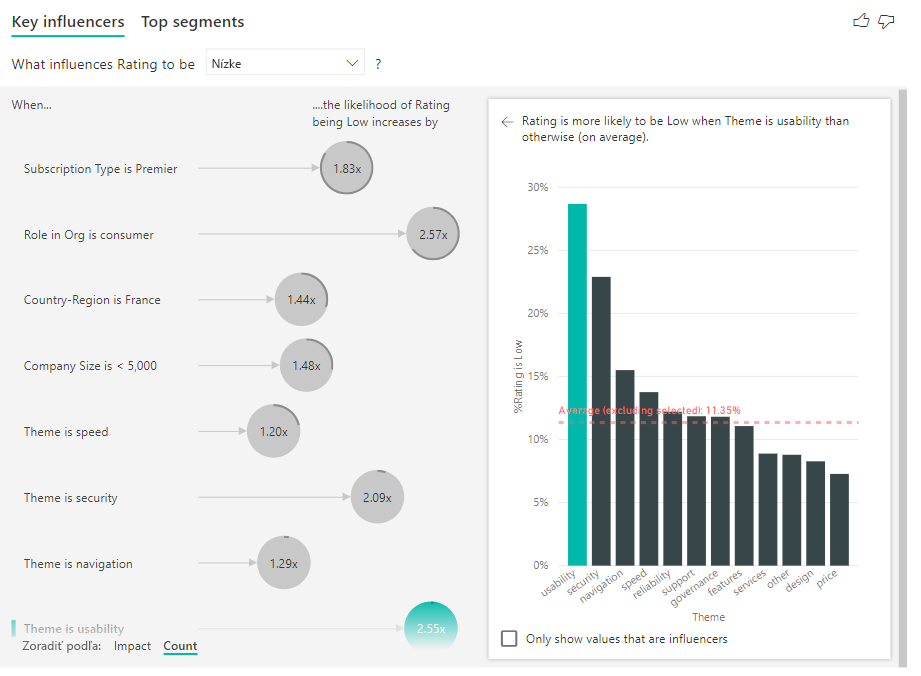
Úplný krúžok okolo kruhu znamená, že vplyv obsahuje 100 % údajov. Typ počtu môžete zmeniť od relatívneho k maximálnemu vplyvu pomocou rozbaľovacieho zoznamu Typ počtu na karte Analýza na table formátovania. Teraz bude vplyv s najväčším množstvom údajov zastúpený celým krúžkom a všetky ostatné počty budú voči nemu relatívne.
Analýza metriky, ktorá je numerická
Ak presunietehrnné číselné pole do poľa Analyzovať , máte na výber, ako tento scenár spracujete. Správanie vizuálu môžete zmeniť tak, že prejdete do tably Formátovanie a budete prepínať medzi možnosťami Typ kategorickej analýzy a Typ spojitej analýzy.
Typ kategorickej analýzy sa správa tak, ako je to popísané vyššie. Ak ste sa napríklad pozerali na skóre prieskumu v rozmedzí od 1 do 10, môžete sa spýtať "Čo ovplyvňuje, že skóre prieskumu je 1?"
Typ spojitej analýzy zmení otázku na spojitú. Vo vyššie uvedenom príklade by naša nová otázka bola "Čo ovplyvňuje zvýšenie/zníženie skóre prieskumu?"
Tento rozdiel je užitočný, ak máte v poli, ktoré analyzujete, veľa jedinečných hodnôt. V nižšie uvedenom príklade sa pozrieme na ceny domov. Nie je zmysluplné pýtať sa "Čo ovplyvňuje, aby cena domu bola 156 214?" pretože je to veľmi špecifické a pravdepodobne nebudeme mať dostatok údajov na odvodzovanie vzoru.
Namiesto toho sa môžeme opýtať "Čo ovplyvňuje rast ceny domov?", čo nám umožňuje brať ceny domov ako rozsah a nie ako jedinečné hodnoty.
Interpretácia výsledkov: Kľúčové faktory vplyvu
Poznámka
V príkladoch v tejto časti sa používajú údaje o cenách domov vo verejnej doméne. Ak si to chcete vyskúšať, môžete si vzorové množiny údajov stiahnuť.
V tomto scenári sa pozrieme na tému Čo ovplyvňuje rast ceny domov. Množstvo vysvetľujúcich faktorov môže ovplyvniť cenu domu, ako je napríklad Year Built (rok, keď bol dom postavený), KitchenQual (kvalita kuchyne) a YearRemodAdd (rok, v rámci ktorého bol dom rekonštruovaný).
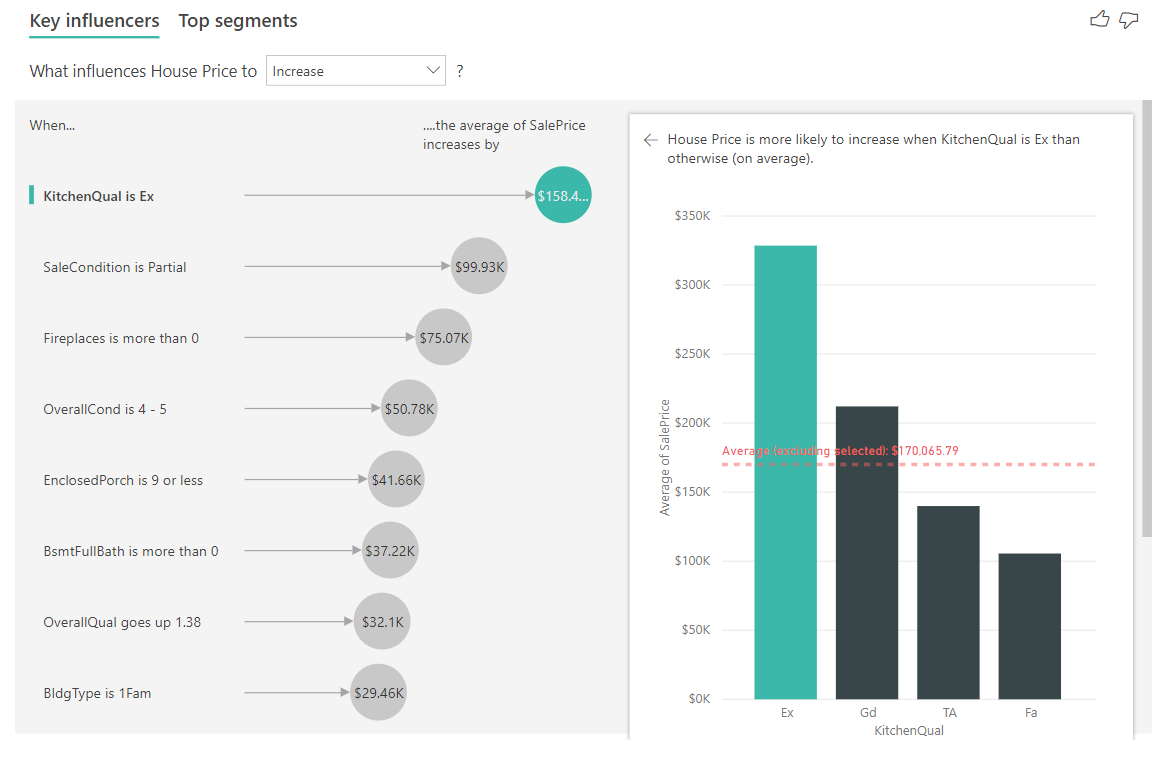
V príklade uvedenom nižšie sa pozrieme na najdôležitejší vplyv, ktorým je kvalita kuchyne na úrovni Excellent (Vynikajúca). Výsledky sú podobné ako tie, ktoré sme videli, keď sme analyzovali kategorické metriky s niekoľkými dôležitými rozdielmi:
- Stĺpcový graf na pravej strane sa pozerá na priemery a nie na percentá. Preto nám ukazuje, aká je priemerná cena domu s vynikajúcou kuchyňou (zelený pruh) v porovnaní s priemernou cenou domu bez vynikajúcej kuchyne (bodkovaná čiara)
- Číslo v bubline stále predstavuje rozdiel medzi červenou bodkovanou čiarou a zeleným pruhom, ale je vyjadrené ako číslo (158 490 USD) a nie ako pravdepodobnosť (1,93-násobok). Takže v priemere domy s vynikajúcimi kuchyňami sú takmer o 160 000 USD drahšie ako domy bez vynikajúcich kuchýň.
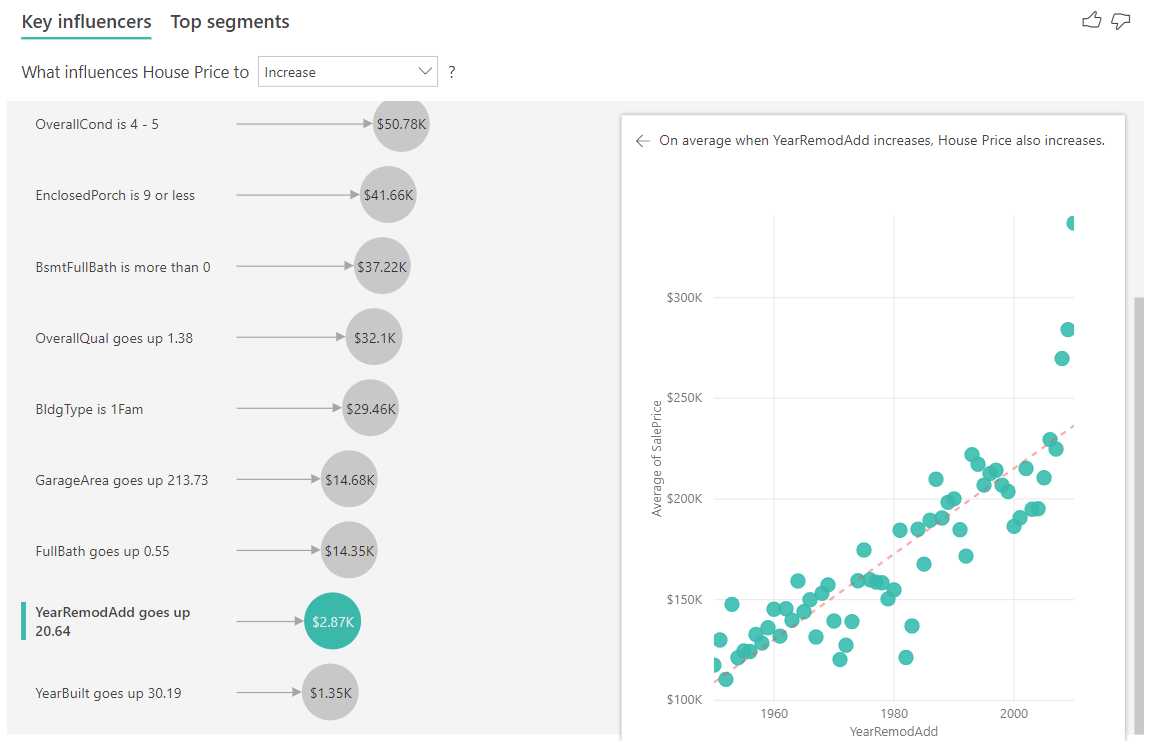
V príklade uvedenom nižšie sa pozrieme na vplyv, ktorý má spojitý faktor (rok, keď bol dom rekonštruovaný) na cenu domu. Rozdiely v porovnaní s tým, ako analyzujeme spojité faktory vplyvu pre kategorické metriky, sú nasledovné:
- Bodový graf na pravej table vykreslí priemernú cenu domu pre každú jedinečnú hodnotu roku rekonštrukcie.
- Hodnota v bubline zobrazuje, o koľko sa zvýši priemerná cena domu (v tomto prípade 2 870 USD), keď sa rok, v rámci ktorého bol dom rekonštruovaný, zvýši o svoju štandardnú odchýlku (v tomto prípade je to 20 rokov)
Nakoniec, v prípade mier sa pozeráme na priemerný rok, keď bol dom postavený. Analýza je nasledovná:
- Bodový graf na pravej table vykreslí priemernú cenu domu pre každú jedinečnú hodnotu v tabuľke
- Hodnota v bubline zobrazuje, o koľko sa zvýši priemerná cena domu (v tomto prípade 1 350 USD), keď sa priemerný rok zvýši o svoju štandardnú odchýlku (v tomto prípade je to 30 rokov)
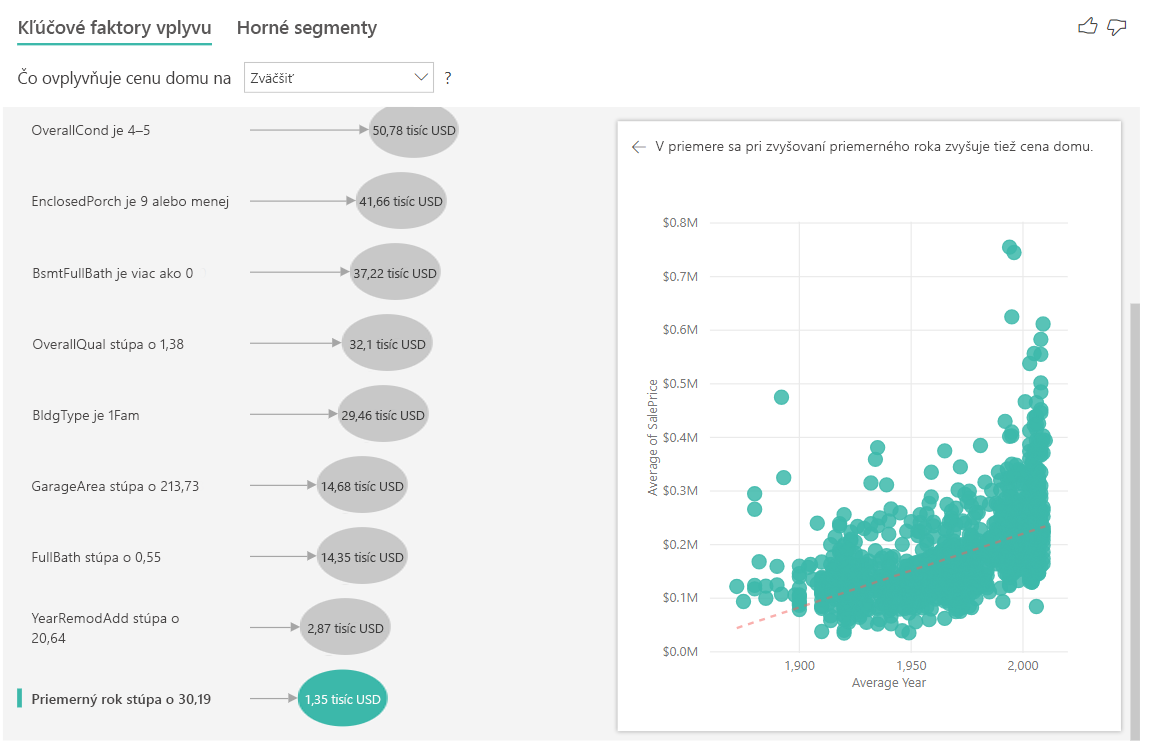
Interpretácia výsledkov: Horné segmenty
Horné segmenty pre číselné ciele zobrazujú skupiny, kde sú ceny domov v priemere vyššie ako v celkovej množine údajov. Nižšie môžeme napríklad vidieť, že Segment 1 sa skladá z domov, kde položka GarageCars (počet automobilov, ktoré sa zmestia do garáže) je väčšia ako 2 a položka RoofStyle (Štýl strechy) je Hip. Domy s týmito vlastnosťami majú priemernú cenu 355 000 USD v porovnaní s celkovým priemerom v údajoch, ktorý je 180 000 USD.
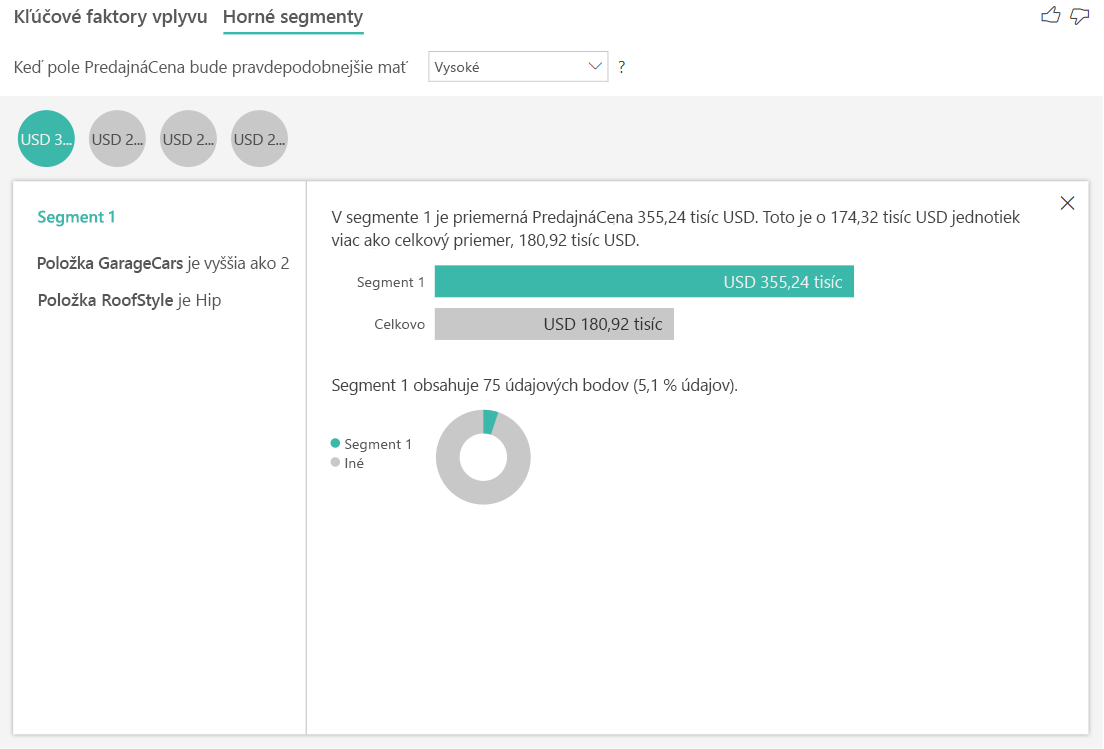
Analýza metriky, ktorá je mierou alebo súhrnným stĺpcom
V prípade mierky alebo súhrnného stĺpca sa analýza predvolene nastaví na typ spojitej analýzy popísanývyššie. Nedá sa zmeniť. Najväčším rozdielom medzi analýzou mierky/súhrnného stĺpca a súhrnným číselným stĺpcom je úroveň, pri ktorej sa analýza spúšťa.
V prípade súhrnných stĺpcov sa analýza vždy spustí na úrovni tabuľky. V príklade ceny domu sme analyzovali metriku Cena domu, aby sme zistili, čo ovplyvňuje rast/zníženie ceny domu. Analýza sa automaticky spustí na úrovni tabuľky. Naša tabuľka má jedinečné ID pre každý dom, takže analýza sa spustí na úrovni domu.
V prípade mierok a súhrnných stĺpcov nebudeme okamžite vedieť, na akej úrovni sa majú analyzovať. Ak cena domu bola zhrnutá ako priemer, musíme uvažovať o tom, akú úroveň by sme chceli vypočítať v priemere za cenu domu. Je priemerná cena domu na úrovni okolia? Alebo snáď na regionálnej úrovni?
Mierky a súhrnné stĺpce sa automaticky analyzujú na úrovni použitých polí Vysvetliť podľa . Predstavte si, že máme tri polia v zdroji polí Vysvetliť podľa, o ktoré sa zaujímame: Kvalita kuchyne, Typ stavby a Klimatizácia. Priemerná cena domu by sa vypočítala pre každú jedinečnú kombináciu týchto troch polí. Často je užitočné prepnúť sa do zobrazenia tabuľky a pozrieť sa, ako vyzerajú vyhodnotené údaje.
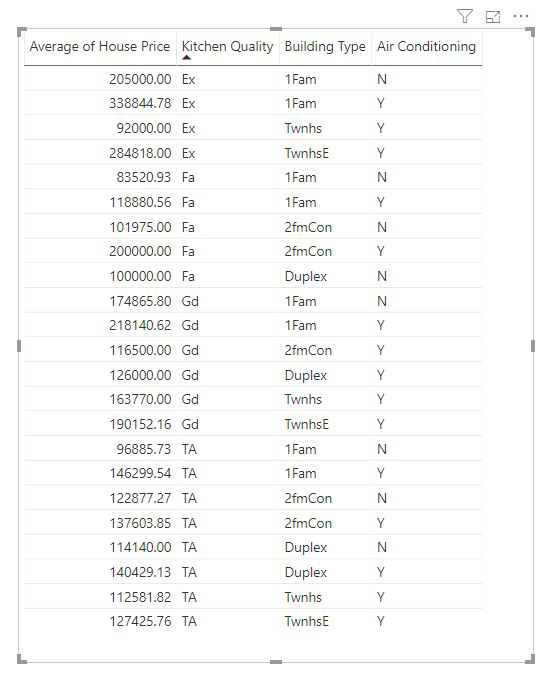
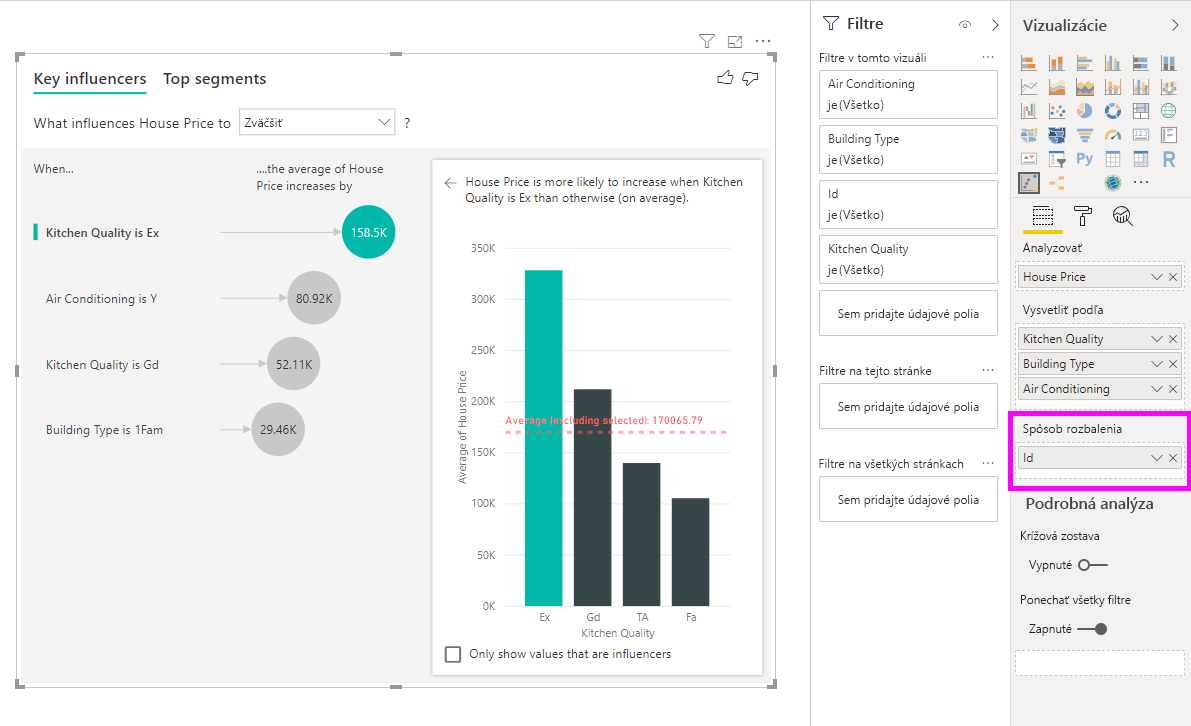
Táto analýza je veľmi zhrnutá a preto bude pre model regresie ťažké nájsť vzory v údajoch, z akých sa môže učiť. Analýzu by sme mali spustiť na podrobnejšej úrovni, aby sme získali lepšie výsledky. Ak by sme chceli analyzovať cenu domu na úrovni domu, museli by sme do analýzy výslovne pridať pole ID . My však nechceme, aby sa ID domu považovalo za vplyv. Informácie, že cena domu sa zvyšuje podľa toho, ako sa zvyšuje JEHO ID, nie je užitočná. Možnosť zdroja polí Spôsob rozbalenia sa sem hodí. Funkciu Spôsob rozbalenia môžete použiť na pridanie polí, ktoré chcete použiť na nastavenie úrovne analýzy, bez toho, aby ste hľadali nové vplyvy.
Pozrite sa, ako vyzerá vizualizácia po pridaní ID do možnosti Rozbaliť podľa. Po definovaní úrovne, pri ktorej sa má vyhodnocovať vaša mierka, je interpretácia vplyvov rovnaká ako v prípade súhrnných číselných stĺpcov.
Ak sa chcete dozvedieť viac o tom, ako môžete analyzovať mierky s vizualizáciou kľúčových vplyvov, pozrite si nasledujúce video. Informácie o tom, ako služba Power BI používa ML.NET na získanie prehľadov z údajov prirodzeným spôsobom, nájdete v téme Identifikácia kľúčových vplyvov v službe Power BI pomocou ML.NET.
Poznámka
Toto video môže používať staršie verzie aplikácie Power BI Desktop alebo služba Power BI.
Dôležité informácie a riešenie problémov
Aké sú obmedzenia vizuálu?
Vizuál kľúčových vplyvov má určité obmedzenia:
- Nepodporuje sa priamy dotaz
- Dynamické Pripojenie služby Azure Analysis Services a SQL Server Analysis Services nie sú podporované
- Publikovanie na webe nie je podporované
- Vyžaduje sa .NET Framework 4,6 alebo novšia verzia
- Vkladanie v SharePointe Online nie je podporované
Zobrazuje sa mi chyba, že sa nenašli žiadne vplyvy ani segmenty. Prečo k tomu prislúcha?
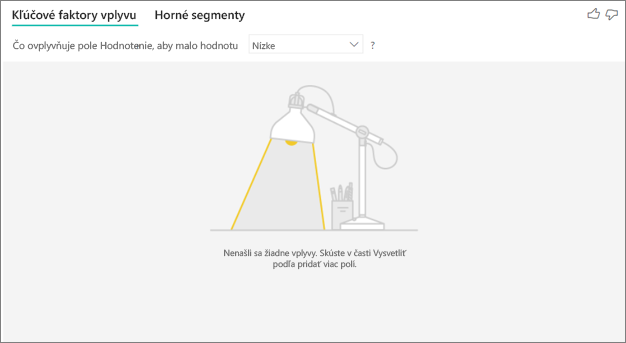
Táto chyba sa vyskytne, keď ste do kontajnera Vysvetliť podľa zahrnuli polia, no nenašli sa žiadne vplyvy.
- Zahrnuli ste metriku, ktorú ste analyzovali, do kontajnera Analyzovať aj kontajnera Vysvetliť podľa. Odstráňte ju z kontajnera Vysvetliť podľa.
- Vaše vysvetľujúce polia majú priveľa kategórií s málo pozorovaniami. Táto situácia sťažuje, aby vizualizácia určila, ktoré faktory predstavujú vplyvy. Je ťažké zovšeobecňovať len na základe niekoľkých pozorovaní. Ak analyzujete číselné pole, možno sa budete chcieť prepnúť z možnosti Kategorická analýza na možnosť Spojitá analýza na table Formátovanie na karte Analýza .
- Vaše vysvetľujúce faktory majú dostatočný počet pozorovaní na zovšeobecnenie, no vizualizácia nenašla zmysluplné korelácie, ktoré by sa mohli zobraziť v zostave.
Zobrazuje sa mi chyba oznamujúca, že metrika, ktorú analyzujem, nemá dostatok údajov na to, aby sa vykonala analýza. Prečo k tomu prislúcha?
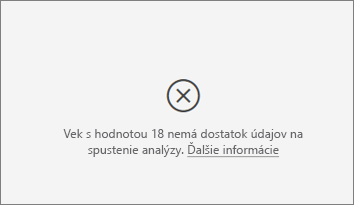
Vizualizácia funguje tak, že hľadá vzory v údajoch pre jednu skupinu v porovnaní s inými skupinami. Vyhľadáva napríklad zákazníkov, ktorí dali nízke hodnotenie, v porovnaní so zákazníkmi, ktorí dali vysoké hodnotenie. Ak majú údaje vo vašom modeli len málo pozorovaní, vzory sa hľadajú ťažko. Ak vizualizácia nemá dostatok údajov na nájdenie zmysluplných vplyvov, uvedie, že na vykonanie analýzy potrebuje viac údajov.
Odporúčame, aby ste pre vybratý stav mali minimálne 100 pozorovaní. V tomto prípade stav predstavuje zákazníkov, ktorí vypovedali zmluvu. Taktiež je potrebných aspoň 10 pozorovaní pre stavy, ktoré používate na porovnanie. V tomto prípade sú stavom na porovnanie zákazníci, ktorí nevy vypovedali zmluvu.
Ak analyzujete číselné pole, možno sa budete chcieť prepnúť z možnosti Kategorická analýza na možnosť Spojitá analýza na table Formátovanie na karte Analýza .
Ak analýza nie je zhrnutá, zobrazí sa chyba. Analýza sa vždy spustí na úrovni riadkov nadradenej tabuľky. Zmena tejto úrovne nie je povolená cez polia Spôsob rozbalenia. Prečo k tomu prislúcha?
Pri analýze číselného alebo kategorického stĺpca sa analýza vždy spustí na úrovni tabuľky. Ak napríklad analyzujete ceny domu a tabuľka obsahuje stĺpec s ID, analýza sa automaticky spustí na úrovni ID domu.
Keď analyzujete mierku alebo súhrnný stĺpec, musíte výslovne uviesť, na akej úrovni by ste chceli vykonať analýzu. Ak chcete zmeniť úroveň analýzy pre mierky a súhrnné stĺpce bez pridania nových vplyvov, môžete použiť funkciu Spôsob rozbalenia . Ak bola cena domu definovaná ako mierka, môžete pridať stĺpec ID domu a spôsob rozbalenia tak, aby sa zmenila úroveň analýzy.
Zobrazuje sa mi chyba oznamujúca, že pole v kontajneri Vysvetliť podľa nemá jedinečnú vzťah s tabuľkou obsahujúcou metriku, ktorú analyzujem. Prečo k tomu prislúcha?
Analýza sa spustí na úrovni tabuľky analyzovaného poľa. Ak napríklad analyzujete pripomienky zákazníkov k vašej službe, môžete mať tabuľku znázorňujúc, či zákazník udelil vysoké alebo nízke hodnotenie. V tomto prípade sa analýza vykonáva na úrovni tabuľky zákazníkov.
Ak máte súvisiacu tabuľku, ktorá je definovaná na granulárnejšej úrovni ako tabuľka obsahujúca vašu metriku, zobrazí sa táto chyba. Príklad:
- Analyzujete, čo privádza zákazníkov k tomu, aby službe dali nízke hodnotenie.
- Chcete zistiť, či zariadenie, pomocou ktorého zákazník službu používa, vplýva na hodnotenia, ktoré nám udeľujú.
- Zákazník môže službu využívať rozličnými spôsobmi.
- V nasledujúcom príklade zákazník 10000000 na prácu so službou využíva prehliadač aj tablet.
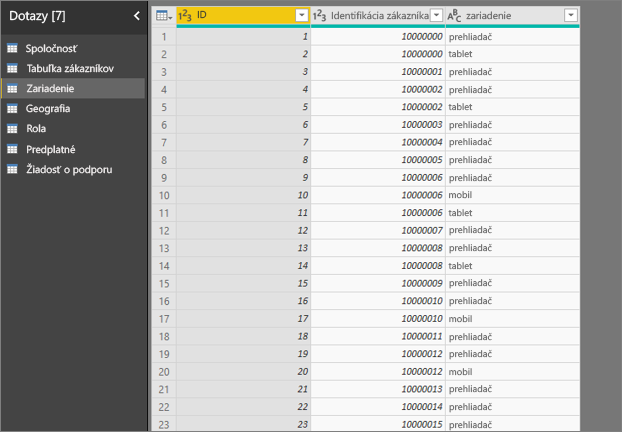
Ak sa pokúsite použiť stĺpec zariadení ako vysvetľujúci faktor, zobrazí sa nasledujúca chyba:

Táto chyba sa zobrazí, pretože zariadenie nie je definované na úrovni zákazníka. Jeden zákazník môže službu využívať na viacerých zariadeniach. Na to, aby vizualizácia mohla nájsť vzory, musí byť zariadenie atribútom zákazníka. Existuje niekoľko riešení, ktoré závisia od vašich predstáv o podnikaní:
- Súhrn zariadení môžete zmeniť na počet. Počet použite napríklad vtedy, ak počet zariadení môže mať vplyv na skóre, ktoré zákazník udelí.
- Môžete vykonať kontingenčnú funkciu v rámci stĺpca zariadení a zistiť, či využívanie služby na konkrétnom zariadení vplýva na hodnotenie zákazníka.
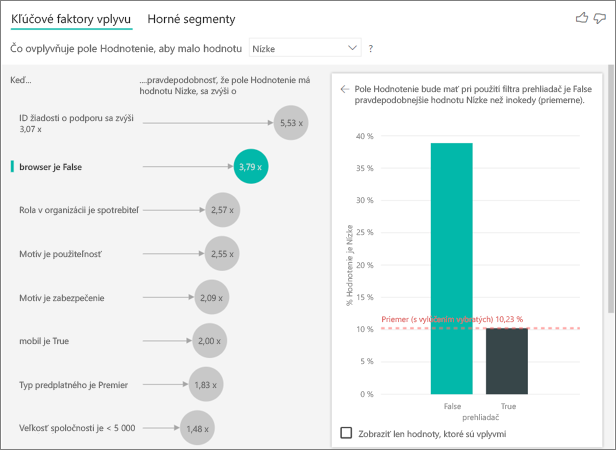
V tomto príklade sa tvorili nové stĺpce pre prehliadač, mobilné zariadenia a tablety (nezabudnite odstrániť a znova vytvoriť vzťahy v zobrazení modelovania po kontingenčnej množine údajov). Teraz môžete tieto špecifické zariadenia používať v kontajneri Vysvetliť podľa. Ukázalo sa, že všetky zariadenia sú vplyvmi a prehliadač má na skóre zákazníka najväčší vplyv.
Presnejšie povedané, zákazníci, ktorí na využívanie služby nepoužívajú prehliadač, majú 3,79-násobne väčšiu pravdepodobnosť udeliť nízke skóre, ako zákazníci, ktorí ho používajú. Nižšie v zozname pre mobilné zariadenia je pravdivá opačná hodnota. Zákazníci, ktorí používajú mobilnú aplikáciu, s väčšou pravdepodobnosťou udelia nízke skóre, ako zákazníci, ktorí ho nepoužívajú.
Zobrazuje sa mi upozornenie, že do mojej analýzy neboli zahrnuté mierky. Prečo k tomu prislúcha?
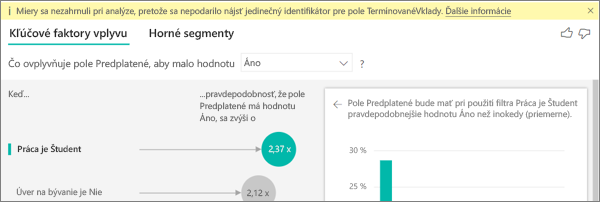
Analýza sa spustí na úrovni tabuľky analyzovaného poľa. Ak analyzujete vypovedaní zmluvy zákazníkmi, môžete mať tabuľku, ktorá uvádza, či zákazník zmluvu vypovedal alebo nie. V tomto prípade sa analýza spustí na úrovni tabuľky zákazníkov.
Mierky a agregáty sa predvolene analyzujú na úrovni tabuľky. Ak by sme mali mierku pre priemernú mesačnú výdavky, bola by analyzovaná na úrovni tabuľky zákazníkov.
Ak tabuľka zákazníkov nemá jedinečný identifikátor, nedokážeme mieru vyhodnotiť a analýza ju ignoruje. Ak sa chcete takejto situácii vyhnúť, uistite sa, že tabuľka s vašou metrikou má jedinečný identifikátor. V tomto prípade je to tabuľka zákazníkov a jedinečným identifikátorom je ID zákazníka. Takisto je jednoduché pridať stĺpec indexu pomocou doplnku Power Query.
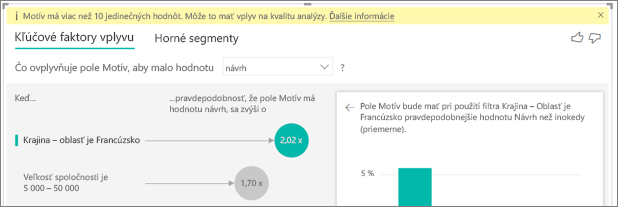
Zobrazuje sa mi upozornenie, že metrika, ktorú analyzujem, má viac ako 10 jedinečných hodnôt a že toto množstvo môže ovplyvniť kvalitu mojej analýzy. Prečo k tomu prislúcha?
Vizualizácia umelej inteligencie môže analyzovať kategorické polia a číselné polia. V prípade kategorických polí môže ako príklad patriť churn (Vypovedať zmluvy) s hodnotami Áno alebo Nie a Customer Satisfaction (Spokojnosť zákazníka) s hodnotami Vysoká, Stredná alebo Nízka. Väčší počet kategórií na analýzu znamená, že na každú kategóriu bude menej pozorovaní. Táto situácia sťažuje vizualizácii nájsť vzory v údajoch.
Pri analýze číselných polí máte na výber medzi dvomi možnosťami. S číselnými poliami budete pracovať ako s textom. V takom prípade spustíte rovnakú analýzu ako v prípade kategorických údajov (Kategorická analýza). Ak máte množstvo jedinečných hodnôt, odporúčame prepnúť analýzu na Spojitú analýzu , čo znamená, že môžeme odvodzovať vzory, keď sa čísla zväčšujú alebo zmenšujú a nebudú sa s nimi pracovať ako s jedinečnými hodnotami. Môžete sa prepnúť z možnosti Kategorická analýza na možnosť Spojitá analýza , ktoré sa nachádzajú na table Formátovanie na karte Analýza .
Ak chcete nájsť silnejšie vplyvy, odporúčame zoskupiť podobné hodnoty do jedného celku. Ak máte napríklad metriku pre cenu, je pravdepodobné, že lepšie výsledky získate zoskupením podobných cien do kategórií "Vysoká", "Stredná", "Nízka", ako pri používaní jednotlivých cenových bodov.
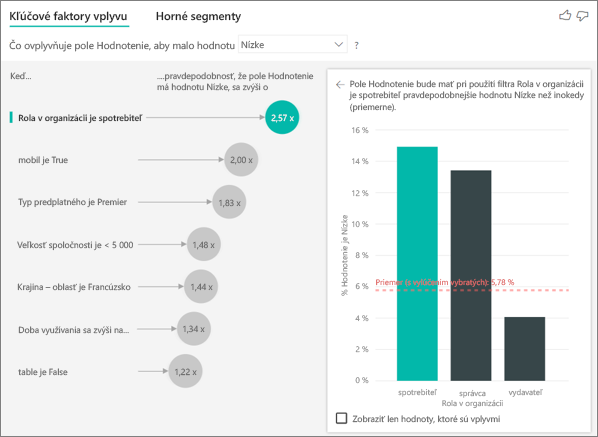
V mojich údajoch sú faktory, ktoré vyzerajú, že by mali byť kľúčovými vplyvmi, no nie sú k dispozícii. Ako k tomuto môže dôjsť?
V nasledujúcom príklade zákazníci, ktorí sú spotrebiteľmi, kladú nízke hodnotenia a predstavujú 14,93 % nízkych hodnotení. Rola správcu má tiež vysoký podiel nízkych hodnotení (13,42 %, no nepovažuje sa za vplyv).
Dôvodom pre toto určenie je, že vizualizácia pri vyhľadaní vplyvu berie do úvahy aj počet údajových bodov. V nasledujúcom príklade je viac ako 29 000 spotrebiteľov a správcov je 10-krát menej, čiže približne 2 900. Iba 390 z nich udelilo nízke hodnotenie. Vizuál nemá dostatok údajov na to, aby určil, či našiel vzor pri hodnoteniach správcov, alebo či ide len o náhodu.
Aké sú limity údajových bodov pre kľúčové vplyvy? Analýzu sme spustili na vzorke 10 000 údajových bodov. Bubliny na jednej strane zobrazujú všetky nájdené vplyvy. Stĺpcové grafy a bodové grafy na druhej strane sa riadia podľa stratégií vzorkovania pre tieto základné vizuály.
Ako sa vypočítavajú kľúčové vplyvy pre kategorickú analýzu?
Vizualizácia umelej inteligencie na pozadí spustí pomocou ML.NET logistickú regresiu, aby sa vypočítali kľúčové vplyvy. Logistická regresia je štatistickým modelom, ktorý navzájom porovnáva rozličné skupiny.
Ak chcete zobraziť, čo vedie k nízkemu hodnoteniu, logistická regresia sa pozrie na to, ako sa zákazníci, ktorí udelili nízke skóre, líšia od zákazníkov, ktorí udelili vysoké skóre. Ak máte viacero kategórií, ako napríklad vysoké, neutrálne a nízke skóre, môžete sa pozrieť na to, ako sa zákazníci, ktorí dali nízke hodnotenie, líšia od zákazníkov, ktorí nedali nízke hodnotenie. Ako sa v tomto prípade zákazníci, ktorí udelili nízke skóre, líšia od zákazníkov, ktorí dali vysoké hodnotenie alebo neutrálne hodnotenie?
Logistická regresia hľadá vzory v údajoch a hľadá to, ako sa zákazníci, ktorí dali nízke hodnotenie, môžu líšiť od zákazníkov, ktorí dali vysoké hodnotenie. Môže napríklad zistiť, že zákazníci, ktorí majú viac žiadostí o podporu, udeľujú väčšie percento nízkych hodnotení ako zákazníci, ktorí majú málo žiadostí o podporu alebo nemajú žiadne.
Logistická regresia tiež berie do úvahy, koľko údajových bodov je prítomných. Ak napríklad zákazníci, ktorí majú rolu správcu, udeľujú proporcionálne viac negatívnych skóre, no správcov je len niekoľko, nebude sa tento faktor považovať za vplyvný. Takýto postup sa rozhodne, pretože nie je k dispozícii dosť údajových bodov na odvodzovanie vzoru. Na určenie toho, či sa faktor považuje za vplyv, sa používa štatistický test známy ako Waldov test. Vizuál používa p-hodnotu 0,05 na určenie prahovej hodnoty.
Ako sa vypočítavajú kľúčové vplyvy pre číselnú analýzu?
Vizualizácia umelej inteligencie na pozadí spustí ML.NET na spustenie lineárnej regresie, aby sa vypočítali kľúčové vplyvy. Lineárna regresia je štatistický model, ktorý zobrazuje ako sa výsledok poľa, ktoré analyzujete, mení na základe vysvetľujúcich faktorov.
Ak napríklad analyzujeme ceny domov, lineárna regresia sa pozrie na to, aký vplyv bude mať vynikajúca kuchyňa na cenu domu. Majú domy s vynikajúcimi kuchyňami vo všeobecnosti nižšie alebo vyššie ceny v porovnaní s domami bez vynikajúcej kuchyne?
Lineárna regresia tiež berie do úvahy počet údajových bodov. Napríklad, ak domy s tenisovými kurtmi majú vyššie ceny, ale máme k dispozícii niekoľko domov s tenisovým kurtom, tento faktor nebude považovaný za vplyvný. Takýto postup sa rozhodne, pretože nie je k dispozícii dosť údajových bodov na odvodzovanie vzoru. Na určenie toho, či sa faktor považuje za vplyv, sa používa štatistický test známy ako Waldov test. Vizuál používa p-hodnotu 0,05 na určenie prahovej hodnoty.
Ako sa vypočítavajú segmenty?
Vizualizácia umelej inteligencie na pozadí vytvorí pomocou ML.NET rozhodovací strom, aby zistila zaujímavé podskupiny. Cieľom rozhodovacieho stromu je skončiť s podskupinou údajových bodov, ktorá obsahuje relatívne veľa metrík, ktoré vás zaujímajú. Mohli by to byť zákazníci s nízkymi hodnoteniami alebo domy s vysokými cenami.
Rozhodovací strom vezme jednotlivé vysvetľujúce faktory a pokúsi sa zistiť, ktorý faktor poskytne najlepšie rozdelenie. Ak napríklad filtrujete údaje, ktoré majú zahŕňať len veľkopodnikových zákazníkov, oddelia sa zákazníci, ktorí udelili vysoké skóre a nízke hodnotenie? Alebo bude lepšie filtrovať údaje tak, aby zahŕňali len zákazníkov, ktorí komentovali zabezpečenie?
Keď rozhodovací strom vytvorí rozdelenie, vezme podskupinu údajov a určí ďalšie najlepšie rozdelenie pre tieto údaje. V tomto prípade sú podskupinou zákazníci, ktorí komentovali zabezpečenie. Po každom rozdelení rozhodovací strom tiež berie do úvahy, či má dostatok údajových bodov na to, aby bola táto skupina dostatočne reprezentatívnou na odvodenie vzoru, alebo či ide o anomáliu v údajoch a nie o skutočný segment. Ďalší štatistický test sa vykonáva na kontrolu štatistickej významnosti podmienky rozdelenia s p-hodnotou 0,05.
Po ukončení spustenia rozhodovacieho stromu sa v ňom zoberú všetky rozdelenia, ako napríklad komentáre o zabezpečení, veľké podniky, a vytvoria sa filtre služby Power BI. Táto kombinácia filtrov sa zbalí do segmentu vo vizuáli.
Prečo niektoré faktory sú vplyvmi alebo prestanú byť vplyvmi, keď presuniem viac polí do poľa Vysvetliť podľa ?
Vizualizácia vyhodnotí všetky vysvetľujúce faktory dokopy. Faktor môže byť vplyvom sám o sebe, ale keď sa zvažuje s inými faktormi, nemusí. Predpokladajme, že analyzujeme parametre, na základe čoho bude cena domu vysoká, pričom spálne a veľkosť domu budú vysvetľujúce faktory:
- Samostatne by viac spální mohlo zvyšovať ceny domov.
- Zahrnutie veľkosti domu do analýzy znamená, že sa pozeráme na to, čo sa stane so spálňami, keď veľkosť domu zostane rovnaká.
- Ak je veľkosť domu stanovená na 140 štvorcových metrov, je nepravdepodobné, že postupný nárast počtu spální výrazne zvýši cenu domu.
- Spálne nemusia byť až tak dôležitým faktorom, ako boli pred zohľadnením veľkosti domu.
Ak chcete zdieľať zostavu s kolegom v službe Power BI, je potrebné, aby ste obaja mali individuálne licencie na Power BI Pro alebo aby bola zostava uložená v kapacite Premium. Pozrite si zdieľanie zostáv.
Súvisiaci obsah
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre