Prestandatips för Azure Cosmos DB Sync Java SDK v2
GÄLLER FÖR: ![]() NoSQL
NoSQL
Viktigt!
Det här är inte den senaste Java SDK:t för Azure Cosmos DB! Du bör uppgradera projektet till Azure Cosmos DB Java SDK v4 och sedan läsa prestandatipsguiden för Azure Cosmos DB Java SDK v4. Följ anvisningarna i guiden Migrera till Azure Cosmos DB Java SDK v4 och Guiden Reactor vs RxJava för uppgradering.
De här prestandatipsen gäller endast För Azure Cosmos DB Sync Java SDK v2. Mer information finns i Maven-lagringsplatsen .
Viktigt!
Den 29 februari 2024 dras Azure Cosmos DB Sync Java SDK v2.x tillbaka. SDK och alla program som använder SDK fortsätter att fungera. Azure Cosmos DB upphör helt enkelt att tillhandahålla ytterligare underhåll och support för denna SDK. Vi rekommenderar att du följer anvisningarna ovan för att migrera till Azure Cosmos DB Java SDK v4.
Azure Cosmos DB är en snabb och flexibel distribuerad databas som skalas sömlöst med garanterad svarstid och dataflöde. Du behöver inte göra större arkitekturändringar eller skriva komplex kod för att skala databasen med Azure Cosmos DB. Det är lika enkelt att skala upp och ned som att göra ett enda API-anrop. Mer information finns i hur du etablerar containerdataflöde eller hur du etablerar databasdataflöde. Men eftersom Azure Cosmos DB nås via nätverksanrop finns det optimeringar på klientsidan som du kan göra för att uppnå högsta prestanda när du använder Azure Cosmos DB Sync Java SDK v2.
Så om du frågar "Hur kan jag förbättra mina databasprestanda?" bör du överväga följande alternativ:
Nätverk
Anslutningsläge: Använd DirectHttps
Hur en klient ansluter till Azure Cosmos DB har stor inverkan på prestandan, särskilt de svarstider som uppstår på klientsidan. Det finns en nyckelkonfigurationsinställning för att konfigurera klienten ConnectionPolicy – ConnectionMode. De två tillgängliga ConnectionModes är:
-
Gatewayläge stöds på alla SDK-plattformar och är den konfigurerade standardinställningen. Om ditt program körs i ett företagsnätverk med strikta brandväggsbegränsningar är Gateway det bästa valet eftersom det använder https-standardporten och en enda slutpunkt. Prestandaavvägningen är dock att gatewayläget innebär ytterligare ett nätverkshopp varje gång data läse eller skrivs till Azure Cosmos DB. På grund av detta erbjuder DirectHttps-läget bättre prestanda på grund av färre nätverkshopp.
Azure Cosmos DB Sync Java SDK v2 använder HTTPS som ett transportprotokoll. HTTPS använder TLS för inledande autentisering och kryptering av trafik. När du använder Azure Cosmos DB Sync Java SDK v2 behöver endast HTTPS-port 443 vara öppen.
ConnectionMode konfigureras under konstruktionen av DocumentClient-instansen med parametern ConnectionPolicy.
Synkronisera Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
public ConnectionPolicy getConnectionPolicy() { ConnectionPolicy policy = new ConnectionPolicy(); policy.setConnectionMode(ConnectionMode.DirectHttps); policy.setMaxPoolSize(1000); return policy; } ConnectionPolicy connectionPolicy = new ConnectionPolicy(); DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);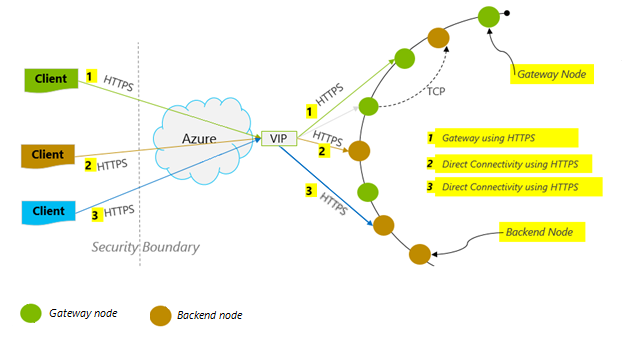
Samla klienter i samma Azure-region för prestanda
När det är möjligt placerar du alla program som anropar Azure Cosmos DB i samma region som Azure Cosmos DB-databasen. För en ungefärlig jämförelse slutförs anrop till Azure Cosmos DB inom samma region inom 1–2 ms, men svarstiden mellan USA:s västra och östra kust är >50 ms. Den här svarstiden kan sannolikt variera från begäran till begäran beroende på vilken väg begäran tar när den skickas från klienten till Gränsen för Azure-datacenter. Den lägsta möjliga svarstiden uppnås genom att säkerställa att det anropande programmet finns i samma Azure-region som den etablerade Azure Cosmos DB-slutpunkten. En lista över tillgängliga regioner finns i Azure-regioner.
SDK-användning
Installera den senaste SDK:en
Azure Cosmos DB SDK:er förbättras ständigt för att ge bästa möjliga prestanda. Information om de senaste SDK-förbättringarna finns i Azure Cosmos DB SDK.
Använda en Singleton Azure Cosmos DB-klient under programmets livslängd
Varje DocumentClient-instans är trådsäker och utför effektiv anslutningshantering och adresscachelagring vid drift i direktläge. För att möjliggöra effektiv anslutningshantering och bättre prestanda av DocumentClient rekommenderar vi att du använder en enda instans av DocumentClient per AppDomain under programmets livslängd.
Öka MaxPoolSize per värd när du använder gatewayläge
Azure Cosmos DB-begäranden görs via HTTPS/REST när gatewayläget används och omfattas av standardanslutningsgränsen per värdnamn eller IP-adress. Du kan behöva ange MaxPoolSize till ett högre värde (200–1 000) så att klientbiblioteket kan använda flera samtidiga anslutningar till Azure Cosmos DB. I Azure Cosmos DB Sync Java SDK v2 är standardvärdet för ConnectionPolicy.getMaxPoolSize 100. Använd setMaxPoolSize för att ändra värdet.
Justera parallella frågor för partitionerade samlingar
Azure Cosmos DB Sync Java SDK version 1.9.0 och senare stöder parallella frågor, vilket gör att du kan köra frågor mot en partitionerad samling parallellt. Mer information finns i kodexempel som rör arbete med SDK:erna. Parallella frågor är utformade för att förbättra frågesvarstiden och dataflödet över deras seriella motsvarighet.
(a) JusteringsuppsättningMaxDegreeOfParallelism: Parallella frågor fungerar genom att köra frågor mot flera partitioner parallellt. Data från en enskild partitionerad samling hämtas dock seriellt med avseende på frågan. Använd därför setMaxDegreeOfParallelism för att ange antalet partitioner som har maximal chans att uppnå den mest högpresterande frågan, förutsatt att alla andra systemvillkor förblir desamma. Om du inte känner till antalet partitioner kan du använda setMaxDegreeOfParallelism för att ange ett högt tal, och systemet väljer minimum (antal partitioner, användarindata) som maximal grad av parallellitet.
Det är viktigt att observera att parallella frågor ger de bästa fördelarna om data fördelas jämnt över alla partitioner med avseende på frågan. Om den partitionerade samlingen partitioneras på ett sådant sätt att alla eller de flesta data som returneras av en fråga är koncentrerade till några partitioner (en partition i värsta fall), skulle frågans prestanda flaskhalsas av dessa partitioner.
(b) JusteringsuppsättningMaxBufferedItemCount: Parallell fråga är utformad för att förbearbeta resultat medan den aktuella batchen med resultat bearbetas av klienten. Prefetching hjälper till med övergripande svarstidsförbättringar för en fråga. setMaxBufferedItemCount begränsar antalet fördefinierade resultat. Genom att ange setMaxBufferedItemCount till det förväntade antalet returnerade resultat (eller ett högre tal) kan frågan få maximal nytta av prefetching.
Prefetching fungerar på samma sätt oavsett MaxDegreeOfParallelism, och det finns en enda buffert för data från alla partitioner.
Implementera backoff vid getRetryAfterInMilliseconds-intervall
Under prestandatestningen bör du öka belastningen tills en liten mängd begäranden begränsas. Om begränsningen är begränsad bör klientprogrammet backa på begränsningen för det serverspecifika återförsöksintervallet. Om du respekterar backoffen ser du till att du ägnar minimal tid åt att vänta mellan återförsöken. Stöd för återförsöksprinciper ingår i version 1.8.0 och senare av Azure Cosmos DB Sync Java SDK. Mer information finns i getRetryAfterInMilliseconds.
Skala ut din klientarbetsbelastning
Om du testar på höga dataflödesnivåer (>50 000 RU/s) kan klientprogrammet bli flaskhalsen på grund av att datorn begränsar processor- eller nätverksanvändningen. Om du når den här punkten kan du fortsätta att push-överföra Azure Cosmos DB-kontot ytterligare genom att skala ut dina klientprogram över flera servrar.
Använda namnbaserad adressering
Använd namnbaserad adressering, där länkar har formatet
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId, i stället för SelfLinks (_self), som har formatetdbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>för att undvika att hämta ResourceIds för alla resurser som används för att skapa länken. Eftersom dessa resurser återskapas (eventuellt med samma namn) kanske cachelagringen inte hjälper.Justera sidstorleken för frågor/läsfeeds för bättre prestanda
När du utför en massläsning av dokument med hjälp av läsflödesfunktioner (till exempel readDocuments) eller när du utfärdar en SQL-fråga returneras resultatet på ett segmenterat sätt om resultatuppsättningen är för stor. Som standard returneras resultaten i segment på 100 objekt eller 1 MB, beroende på vilken gräns som uppnås först.
Om du vill minska antalet nätverksresor som krävs för att hämta alla tillämpliga resultat kan du öka sidstorleken med begäranderubriken x-ms-max-item-count till upp till 1 000. Om du bara behöver visa några få resultat, till exempel om ditt användargränssnitt eller program-API bara returnerar 10 resultat per tid, kan du också minska sidstorleken till 10 för att minska dataflödet som förbrukas för läsningar och frågor.
Du kan också ange sidstorleken med metoden setPageSize.
Indexeringsprincip
Utesluta sökvägar som inte används från indexering för att få snabbare skrivning
Med Azure Cosmos DB:s indexeringsprincip kan du ange vilka dokumentsökvägar som ska inkluderas eller undantas från indexering med hjälp av Indexeringssökvägar (setIncludedPaths och setExcludedPaths). Användningen av indexeringssökvägar kan ge bättre skrivprestanda och lägre indexlagring för scenarier där frågemönstren är kända i förväg, eftersom indexeringskostnaderna är direkt korrelerade med antalet indexerade unika sökvägar. Följande kod visar till exempel hur du exkluderar ett helt avsnitt (underträd) av dokumenten från indexering med jokertecknet "*".
Synkronisera Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Mer information finns i Azure Cosmos DB-indexeringsprinciper.
Genomflöde
Mät och justera för lägre användning av enheter för begäranden/sekund
Azure Cosmos DB erbjuder en omfattande uppsättning databasåtgärder, inklusive relationsfrågor och hierarkiska frågor med UDF:er, lagrade procedurer och utlösare – som alla körs på dokumenten i en databassamling. Den kostnad som hör till var och en av dessa operationer varierar baserat på vilken CPU, vilka IO-resurser och hur mycket minne som krävs för att slutföra operationen. I stället för att tänka på och hantera maskinvaruresurser kan du betrakta en enhet för begäran (RU) som ett enda mått för de resurser som krävs för att utföra olika databasåtgärder och hantera en programbegäran.
Dataflödet etableras baserat på antalet enheter för begäranden som angetts för varje container. Enhetsförbrukning för begäran utvärderas som en hastighet per sekund. Program som överskrider den etablerade enhetsfrekvensen för begäranden för containern begränsas tills priset sjunker under den etablerade nivån för containern. Om programmet kräver ett högre dataflöde kan du öka dataflödet genom att etablera ytterligare enheter för begäranden.
Komplexiteten i en fråga påverkar hur många enheter för begäran som förbrukas för en åtgärd. Antalet predikat, predikatens natur, antalet UDF:er och storleken på källdatauppsättningen påverkar alla kostnaden för frågeåtgärder.
Om du vill mäta omkostnaderna för en åtgärd (skapa, uppdatera eller ta bort) kontrollerar du rubriken x-ms-request-charge (eller motsvarande RequestCharge-egenskap i ResourceResponse<T> eller FeedResponse<T> för att mäta antalet enheter för begäranden som förbrukas av dessa åtgärder.
Synkronisera Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
ResourceResponse<Document> response = client.createDocument(collectionLink, documentDefinition, null, false); response.getRequestCharge();Den begärandeavgift som returneras i det här huvudet är en bråkdel av ditt etablerade dataflöde. Om du till exempel har etablerat 2 000 RU/s och om föregående fråga returnerar 1 000 1 KB-dokument är kostnaden för åtgärden 1 000. Därför respekterar servern bara två sådana begäranden inom en sekund innan efterföljande begäranden begränsas. Mer information finns i Enheter för begäran och kalkylatorn för begärandeenheten.
Hantera hastighetsbegränsning/begärandefrekvens för stor
När en klient försöker överskrida det reserverade dataflödet för ett konto sker ingen prestandaförsämring på servern och ingen användning av dataflödeskapacitet utöver den reserverade nivån. Servern avslutar begäran i förebyggande syfte med RequestRateTooLarge (HTTP-statuskod 429) och returnerar rubriken x-ms-retry-after-ms som anger hur lång tid, i millisekunder, som användaren måste vänta innan begäran försöker igen.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100SDK:erna fångar alla implicit det här svaret, respekterar det server-angivna återförsökshuvudet och försöker begära igen. Om inte ditt konto används samtidigt av flera klienter kommer nästa återförsök att lyckas.
Om du har fler än en klient som kumulativt fungerar konsekvent över begärandefrekvensen kanske standardantalet för återförsök som för närvarande är inställt på 9 internt av klienten inte räcker. I det här fallet genererar klienten en DocumentClientException med statuskod 429 till programmet. Standardantalet för återförsök kan ändras med setRetryOptions på ConnectionPolicy-instansen. Som standard returneras DocumentClientException med statuskod 429 efter en kumulativ väntetid på 30 sekunder om begäran fortsätter att fungera över begärandefrekvensen. Detta inträffar även om det aktuella antalet återförsök är mindre än det maximala antalet återförsök, oavsett om det är standardvärdet 9 eller ett användardefinierat värde.
Även om det automatiserade återförsöksbeteendet hjälper till att förbättra återhämtning och användbarhet för de flesta program, kan det komma till odds när prestandamått utförs, särskilt när svarstiden mäts. Den klient observerade svarstiden ökar om experimentet når serverbegränsningen och gör att klient-SDK:t tyst försöker igen. För att undvika svarstidstoppar under prestandaexperiment mäter du den avgift som returneras av varje åtgärd och ser till att begäranden fungerar under den reserverade begärandefrekvensen. Mer information finns i Enheter för begäran.
Designa för mindre dokument för högre dataflöde
Begärandeavgiften (kostnaden för bearbetning av begäran) för en viss åtgärd är direkt korrelerad till dokumentets storlek. Åtgärder på stora dokument kostar mer än åtgärder för små dokument.
Nästa steg
Mer information om hur du utformar ditt program för skalning och höga prestanda finns i Partitionering och skalning i Azure Cosmos DB.