Prestandatips för Azure Cosmos DB Python SDK
GÄLLER FÖR: ![]() NoSQL
NoSQL
Viktigt!
Prestandatipsen i den här artikeln gäller endast För Azure Cosmos DB Python SDK. Mer information finns i Viktig information om Azure Cosmos DB Python SDK Readme, Package (PyPI), Package (Conda) och felsökningsguiden.
Azure Cosmos DB är en snabb och flexibel distribuerad databas som skalas sömlöst med garanterad svarstid och dataflöde. Du behöver inte göra större arkitekturändringar eller skriva komplex kod för att skala databasen med Azure Cosmos DB. Det är lika enkelt att skala upp och ned som att göra ett enda API-anrop eller ett SDK-metodanrop. Men eftersom Azure Cosmos DB nås via nätverksanrop finns det optimeringar på klientsidan som du kan göra för att uppnå högsta prestanda när du använder Azure Cosmos DB Python SDK.
Så om du frågar "Hur kan jag förbättra mina databasprestanda?" bör du överväga följande alternativ:
Nätverk
- Samla klienter i samma Azure-region för prestanda
När det är möjligt placerar du alla program som anropar Azure Cosmos DB i samma region som Azure Cosmos DB-databasen. För en ungefärlig jämförelse slutförs anrop till Azure Cosmos DB inom samma region inom 1–2 ms, men svarstiden mellan USA:s västra och östra kust är >50 ms. Den här svarstiden kan sannolikt variera från begäran till begäran beroende på vilken väg begäran tar när den skickas från klienten till Gränsen för Azure-datacenter. Den lägsta möjliga svarstiden uppnås genom att säkerställa att det anropande programmet finns i samma Azure-region som den etablerade Azure Cosmos DB-slutpunkten. En lista över tillgängliga regioner finns i Azure-regioner.
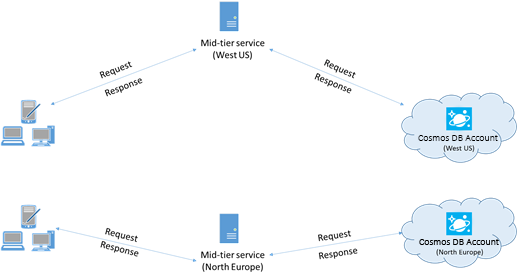
En app som interagerar med ett Azure Cosmos DB-konto i flera regioner måste konfigurera önskade platser för att säkerställa att begäranden går till en samordnad region.
Aktivera accelererat nätverk för att minska svarstiden och CPU-jitter
Vi rekommenderar att du följer anvisningarna för att aktivera accelererat nätverk i windows (välj instruktioner) eller Linux (välj för instruktioner) virtuella Azure-datorer för att maximera prestanda (minska svarstiden och CPU-jitter).
Utan accelererat nätverk kan I/O som överförs mellan din virtuella Azure-dator och andra Azure-resurser i onödan dirigeras via en värd och en virtuell växel mellan den virtuella datorn och dess nätverkskort. Att ha värden och den virtuella växeln infogade i datasökvägen ökar inte bara svarstiden och jitter i kommunikationskanalen, utan stjäl även CPU-cykler från den virtuella datorn. Med accelererat nätverk gränssnittar den virtuella datorn direkt med nätverkskortet utan mellanhänder. All information om nätverksprinciper som hanterades av värden och den virtuella växeln hanteras nu i maskinvaran på nätverkskortet. värden och den virtuella växeln kringgås. Vanligtvis kan du förvänta dig lägre svarstid och högre dataflöde, samt mer konsekvent svarstid och minskad CPU-användning när du aktiverar accelererat nätverk.
Begränsningar: Accelererat nätverk måste stödjas på det virtuella datoroperativsystemet och kan bara aktiveras när den virtuella datorn stoppas och frigörs. Det går inte att distribuera den virtuella datorn med Azure Resource Manager. App Service har inget accelererat nätverk aktiverat.
Mer information finns i Windows- och Linux-instruktionerna.
SDK-användning
- Installera den senaste SDK:en
Azure Cosmos DB SDK:er förbättras ständigt för att ge bästa möjliga prestanda. Se viktig information om Azure Cosmos DB SDK för att fastställa de senaste SDK:erna och granska förbättringar.
- Använda en Singleton Azure Cosmos DB-klient under programmets livslängd
Varje Azure Cosmos DB-klientinstans är trådsäker och utför effektiv anslutningshantering och adresscachelagring. För att möjliggöra effektiv anslutningshantering och bättre prestanda för Azure Cosmos DB-klienten rekommenderar vi att du använder en enda instans av Azure Cosmos DB-klienten under programmets livslängd.
- Justera timeout- och återförsökskonfigurationer
Tidsgränskonfigurationer och återförsöksprinciper kan anpassas baserat på programmets behov. Se dokumentet om tidsgräns och återförsök för att få en fullständig lista över konfigurationer som kan anpassas.
- Använd den lägsta konsekvensnivå som krävs för ditt program
När du skapar en CosmosClient används konsekvens på kontonivå om ingen anges när klienten skapas. Mer information om konsekvensnivåer finns i dokumentet om konsekvensnivåer .
- Skala ut din klientarbetsbelastning
Om du testar på höga dataflödesnivåer kan klientprogrammet bli flaskhalsen på grund av att datorn begränsar processor- eller nätverksanvändningen. Om du når den här punkten kan du fortsätta att push-överföra Azure Cosmos DB-kontot ytterligare genom att skala ut dina klientprogram över flera servrar.
En bra tumregel är att inte överskrida >50 % processoranvändning på en viss server för att hålla svarstiden låg.
- Resursgräns för öppna OS-filer
Vissa Linux-system (till exempel Red Hat) har en övre gräns för antalet öppna filer och därmed det totala antalet anslutningar. Kör följande för att visa de aktuella gränserna:
ulimit -a
Antalet öppna filer (nofile) måste vara tillräckligt stort för att ha tillräckligt med utrymme för din konfigurerade storlek på anslutningspoolen och andra öppna filer i operativsystemet. Den kan ändras för att tillåta en större storlek på anslutningspoolen.
Öppna filen limits.conf:
vim /etc/security/limits.conf
Lägg till/ändra följande rader:
* - nofile 100000
Frågeåtgärder
Information om frågeåtgärder finns i prestandatipsen för frågor.
Indexeringsprincip
- Utesluta sökvägar som inte används från indexering för att få snabbare skrivning
Med Azure Cosmos DB:s indexeringsprincip kan du ange vilka dokumentsökvägar som ska inkluderas eller undantas från indexering genom att använda indexeringssökvägar (setIncludedPaths och setExcludedPaths). Användningen av indexeringssökvägar kan ge bättre skrivprestanda och lägre indexlagring för scenarier där frågemönstren är kända i förväg, eftersom indexeringskostnaderna är direkt korrelerade med antalet indexerade unika sökvägar. Följande kod visar till exempel hur du inkluderar och exkluderar hela delar av dokumenten (kallas även för ett underträd) från indexering med jokertecknet "*".
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Mer information finns i Azure Cosmos DB-indexeringsprinciper.
Genomflöde
- Mät och justera för lägre användning av enheter för begäranden/sekund
Azure Cosmos DB erbjuder en omfattande uppsättning databasåtgärder, inklusive relationsfrågor och hierarkiska frågor med UDF:er, lagrade procedurer och utlösare – som alla körs på dokumenten i en databassamling. Den kostnad som hör till var och en av dessa operationer varierar baserat på vilken CPU, vilka IO-resurser och hur mycket minne som krävs för att slutföra operationen. I stället för att tänka på och hantera maskinvaruresurser kan du betrakta en enhet för begäran (RU) som ett enda mått för de resurser som krävs för att utföra olika databasåtgärder och hantera en programbegäran.
Dataflödet etableras baserat på antalet enheter för begäranden som angetts för varje container. Enhetsförbrukning för begäran utvärderas som en hastighet per sekund. Program som överskrider den etablerade enhetsfrekvensen för begäranden för containern begränsas tills priset sjunker under den etablerade nivån för containern. Om programmet kräver ett högre dataflöde kan du öka dataflödet genom att etablera ytterligare enheter för begäranden.
Komplexiteten i en fråga påverkar hur många enheter för begäran som förbrukas för en åtgärd. Antalet predikat, predikatens natur, antalet UDF:er och storleken på källdatauppsättningen påverkar alla kostnaden för frågeåtgärder.
Om du vill mäta omkostnaderna för en åtgärd (skapa, uppdatera eller ta bort) kontrollerar du rubriken x-ms-request-charge för att mäta antalet enheter för begäranden som förbrukas av dessa åtgärder.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
Den begärandeavgift som returneras i det här huvudet är en bråkdel av ditt etablerade dataflöde. Om du till exempel har etablerat 2 000 RU/s och om föregående fråga returnerar 1 000 1 KB-dokument är kostnaden för åtgärden 1 000. Därför respekterar servern bara två sådana begäranden inom en sekund innan efterföljande begäranden begränsas. Mer information finns i Enheter för begäran och kalkylatorn för begärandeenheten.
- Hantera hastighetsbegränsning/begärandefrekvens för stor
När en klient försöker överskrida det reserverade dataflödet för ett konto sker ingen prestandaförsämring på servern och ingen användning av dataflödeskapacitet utöver den reserverade nivån. Servern avslutar begäran i förebyggande syfte med RequestRateTooLarge (HTTP-statuskod 429) och returnerar rubriken x-ms-retry-after-ms som anger hur lång tid, i millisekunder, som användaren måste vänta innan begäran försöker igen.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK:erna fångar alla implicit det här svaret, respekterar det server-angivna återförsökshuvudet och försöker begära igen. Om inte ditt konto används samtidigt av flera klienter kommer nästa återförsök att lyckas.
Om du har fler än en klient som kumulativt fungerar konsekvent över begärandefrekvensen kanske standardantalet för återförsök som för närvarande är inställt på 9 internt av klienten kanske inte räcker. I det här fallet genererar klienten en CosmosHttpResponseError med statuskod 429 till programmet. Standardantalet för återförsök kan ändras genom att konfigurationen skickas retry_total till klienten. Som standard returneras CosmosHttpResponseError med statuskod 429 efter en kumulativ väntetid på 30 sekunder om begäran fortsätter att fungera över begärandefrekvensen. Detta inträffar även om det aktuella antalet återförsök är mindre än det maximala antalet återförsök, oavsett om det är standardvärdet 9 eller ett användardefinierat värde.
Även om det automatiserade återförsöksbeteendet hjälper till att förbättra återhämtning och användbarhet för de flesta program, kan det komma till odds när prestandamått utförs, särskilt när svarstiden mäts. Den klient observerade svarstiden ökar om experimentet når serverbegränsningen och gör att klient-SDK:t tyst försöker igen. För att undvika svarstidstoppar under prestandaexperiment mäter du den avgift som returneras av varje åtgärd och ser till att begäranden fungerar under den reserverade begärandefrekvensen. Mer information finns i Enheter för begäran.
- Designa för mindre dokument för högre dataflöde
Begärandeavgiften (kostnaden för bearbetning av begäran) för en viss åtgärd är direkt korrelerad till dokumentets storlek. Åtgärder på stora dokument kostar mer än åtgärder för små dokument. Vi rekommenderar att du utformar ditt program och arbetsflöden så att objektstorleken är ~1 KB eller liknande ordning eller storlek. För svarstidskänsliga program bör stora objekt undvikas – dokument med flera MB gör programmet långsammare.
Nästa steg
Mer information om hur du utformar ditt program för skalning och höga prestanda finns i Partitionering och skalning i Azure Cosmos DB.
Försöker du planera kapacitet för en migrering till Azure Cosmos DB? Du kan använda information om ditt befintliga databaskluster för kapacitetsplanering.
- Om allt du vet är antalet virtuella kärnor och servrar i ditt befintliga databaskluster läser du om att uppskatta enheter för begäranden med virtuella kärnor eller virtuella kärnor
- Om du känner till vanliga begärandefrekvenser för din aktuella databasarbetsbelastning kan du läsa om att uppskatta enheter för begäranden med azure Cosmos DB-kapacitetshanteraren