Kopiera och transformera data i Azure Synapse Analytics med hjälp av Azure Data Factory eller Synapse-pipelines
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktivitet i Azure Data Factory eller Synapse-pipelines för att kopiera data från och till Azure Synapse Analytics och använda Data Flow för att transformera data i Azure Data Lake Storage Gen2. Mer information om Azure Data Factory finns i introduktionsartikeln.
Funktioner som stöds
Den här Azure Synapse Analytics-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR | Hanterad privat slutpunkt |
|---|---|---|
| Kopieringsaktivitet (källa/mottagare) | (1) (2) | ✓ |
| Mappa dataflöde (källa/mottagare) | (1) | ✓ |
| Sökningsaktivitet | (1) (2) | ✓ |
| GetMetadata-aktivitet | (1) (2) | ✓ |
| Skriptaktivitet | (1) (2) | ✓ |
| Lagrad proceduraktivitet | (1) (2) | ✓ |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
För kopieringsaktivitet stöder den här Azure Synapse Analytics-anslutningsappen följande funktioner:
- Kopiera data med hjälp av SQL-autentisering och Microsoft Entra-programtokenautentisering med tjänstens huvudnamn eller hanterade identiteter för Azure-resurser.
- Som källa hämtar du data med hjälp av en SQL-fråga eller en lagrad procedur. Du kan också välja att kopiera parallellt från en Azure Synapse Analytics-källa. Mer information finns i avsnittet Parallell kopia från Azure Synapse Analytics .
- Som mottagare läser du in data med hjälp av COPY-instruktionen eller PolyBase eller massinfogning. Vi rekommenderar COPY-instruktionen eller PolyBase för bättre kopieringsprestanda. Anslutningsappen har också stöd för att automatiskt skapa måltabellen med DISTRIBUTION = ROUND_ROBIN om den inte finns baserat på källschemat.
Viktigt!
Om du kopierar data med hjälp av en Azure Integration Runtime konfigurerar du en brandväggsregel på servernivå så att Azure-tjänster kan komma åt den logiska SQL-servern. Om du kopierar data med hjälp av en lokalt installerad integrationskörning konfigurerar du brandväggen så att den tillåter lämpligt IP-intervall. Det här intervallet omfattar datorns IP-adress som används för att ansluta till Azure Synapse Analytics.
Kom igång
Dricks
Använd PolyBase- eller COPY-instruktionen för att läsa in data i Azure Synapse Analytics för att uppnå bästa prestanda. Avsnitten Använd PolyBase för att läsa in data i Azure Synapse Analytics och använda COPY-instruktionen för att läsa in data i Azure Synapse Analytics innehåller information. En genomgång med ett användningsfall finns i Läsa in 1 TB i Azure Synapse Analytics under 15 minuter med Azure Data Factory.
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad Azure Synapse Analytics-tjänst med hjälp av användargränssnittet
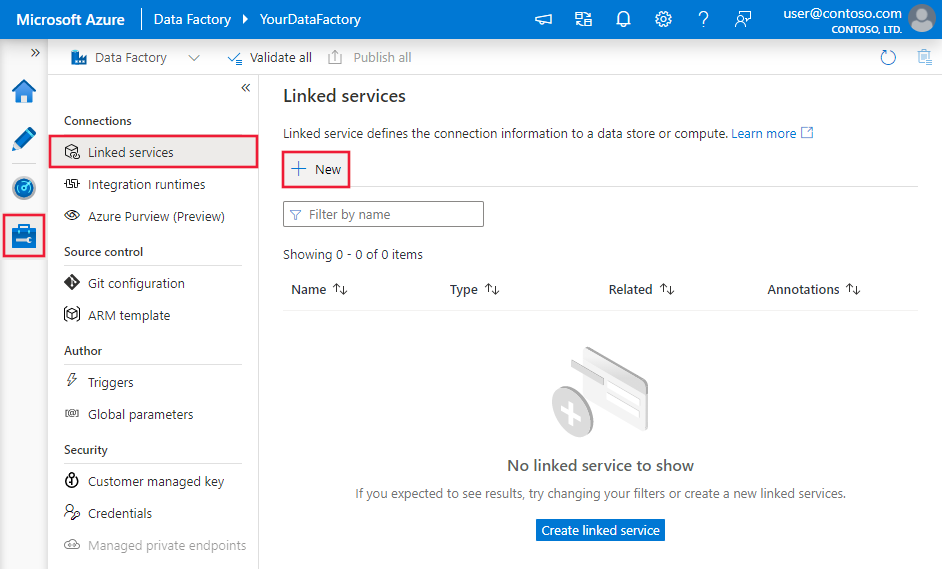
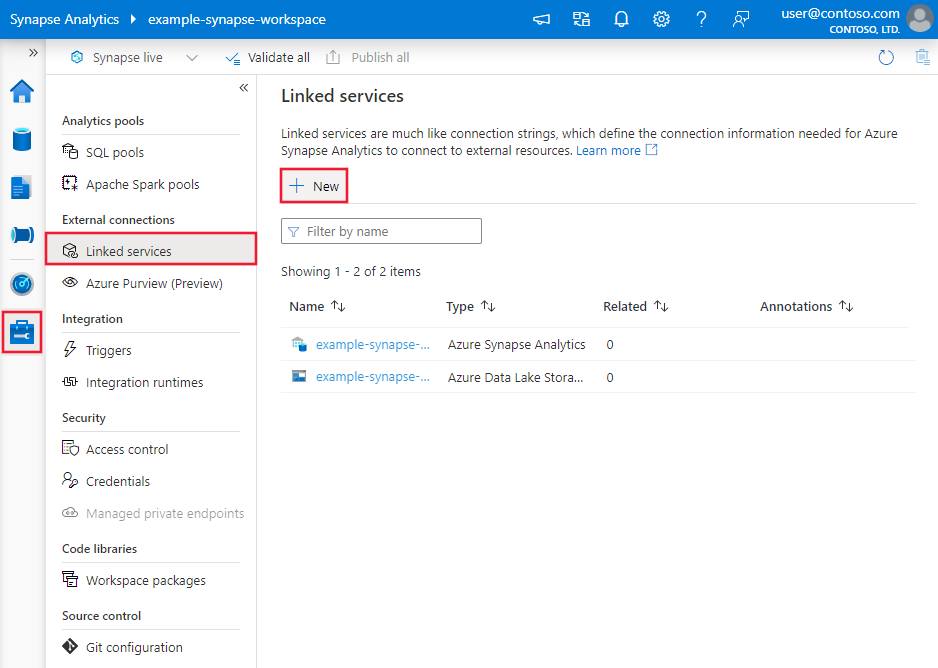
Använd följande steg för att skapa en länkad Azure Synapse Analytics-tjänst i azure-portalens användargränssnitt.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter Synapse och välj Azure Synapse Analytics-anslutningsappen.

Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.

Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som definierar Data Factory- och Synapse-pipelineentiteter som är specifika för en Azure Synapse Analytics-anslutningsapp.
Länkade tjänstegenskaper
Den rekommenderade versionen av Azure Synapse Analytics-anslutningsappen stöder TLS 1.3. Se det här avsnittet om du vill uppgradera din Azure Synapse Analytics-anslutningsversion från Äldre . Information om egenskapen finns i motsvarande avsnitt.
Dricks
När du skapar en länkad tjänst för en serverlös SQL-pool i Azure Synapse från Azure-portalen:
- För Kontovalsmetod väljer du Ange manuellt.
- Klistra in det fullständigt kvalificerade domännamnet för den serverlösa slutpunkten. Du hittar detta på översiktssidan i Azure-portalen för din Synapse-arbetsyta i egenskaperna under Serverlös SQL-slutpunkt. Exempel:
myserver-ondemand.sql-azuresynapse.net - För Databasnamn anger du databasnamnet i den serverlösa SQL-poolen.
Dricks
Om du får fel med felkoden "UserErrorFailedToConnectToSqlServer" och meddelandet "Sessionsgränsen för databasen är XXX och har nåtts.", lägger du till Pooling=false i din niska veze och försöker igen.
Rekommenderad version
Dessa allmänna egenskaper stöds för en länkad Azure Synapse Analytics-tjänst när du använder rekommenderad version:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till AzureSqlDW. | Ja |
| server | Namnet eller nätverksadressen för den SQL Server-instans som du vill ansluta till. | Ja |
| database | Namnet på databasen. | Ja |
| authenticationType | Den typ som används för autentisering. Tillåtna värden är SQL (standard), ServicePrincipal, SystemAssignedManagedIdentity, UserAssignedManagedIdentity. Gå till relevant autentiseringsavsnitt om specifika egenskaper och förutsättningar. | Ja |
| kryptera | Ange om TLS-kryptering krävs för alla data som skickas mellan klienten och servern. Alternativ: obligatoriskt (för sant, standard)/valfritt (för falskt)/strikt. | Nej |
| trustServerCertificate | Ange om kanalen ska krypteras när certifikatkedjan kringgås för att verifiera förtroende. | Nej |
| hostNameInCertificate | Det värdnamn som ska användas när du verifierar servercertifikatet för anslutningen. När det inte anges används servernamnet för certifikatverifiering. | Nej |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller en lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
Ytterligare anslutningsegenskaper finns i tabellen nedan:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| applicationIntent | Programmets arbetsbelastningstyp när du ansluter till en server. Tillåtna värden är ReadOnly och ReadWrite. |
Nej |
| connectTimeout | Hur lång tid (i sekunder) det tar att vänta på en anslutning till servern innan försöket avslutas och ett fel genereras. | Nej |
| connectRetryCount | Antalet återanslutningsförsök efter identifiering av ett inaktivt anslutningsfel. Värdet ska vara ett heltal mellan 0 och 255. | Nej |
| connectRetryInterval | Hur lång tid (i sekunder) mellan varje återanslutningsförsök efter att ett inaktivt anslutningsfel har identifierats. Värdet ska vara ett heltal mellan 1 och 60. | Nej |
| loadBalanceTimeout | Den minsta tiden (i sekunder) för anslutningen att finnas i anslutningspoolen innan anslutningen förstörs. | Nej |
| commandTimeout | Standardväntetiden (i sekunder) innan du avslutar försöket att köra ett kommando och generera ett fel. | Nej |
| integratedSecurity | De tillåtna värdena är true eller false. När du falseanger anger du om userName och lösenord har angetts i anslutningen. När du trueanger anger anger du om de aktuella autentiseringsuppgifterna för Windows-kontot används för autentisering. |
Nej |
| failoverPartner | Namnet eller adressen på partnerservern som ska anslutas till om den primära servern är nere. | Nej |
| maxPoolSize | Det maximala antalet anslutningar som tillåts i anslutningspoolen för den specifika anslutningen. | Nej |
| minPoolSize | Det minsta antalet anslutningar som tillåts i anslutningspoolen för den specifika anslutningen. | Nej |
| multipleActiveResultSets | De tillåtna värdena är true eller false. När du anger truekan ett program underhålla flera aktiva resultatuppsättningar (MARS). När du anger falsemåste ett program bearbeta eller avbryta alla resultatuppsättningar från en batch innan det kan köra andra batchar på den anslutningen. |
Nej |
| multiSubnetFailover | De tillåtna värdena är true eller false. Om ditt program ansluter till en AlwaysOn-tillgänglighetsgrupp (AG) i olika undernät kan du ange att true den här egenskapen ska ge snabbare identifiering av och anslutning till den aktiva servern. |
Nej |
| packetSize | Storleken i byte för de nätverkspaket som används för att kommunicera med en serverinstans. | Nej |
| poolning | De tillåtna värdena är true eller false. När du anger truekommer anslutningen att poolas. När du anger falseöppnas anslutningen explicit varje gång anslutningen begärs. |
Nej |
SQL-autentisering
Om du vill använda SQL-autentisering anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| userName | Användarnamnet som används för att ansluta till servern. | Ja |
| password | Lösenordet för användarnamnet. Markera det här fältet som SecureString för att lagra det på ett säkert sätt. Eller så kan du referera till en hemlighet som lagras i Azure Key Vault. | Ja |
Exempel: använda SQL-autentisering
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: lösenord i Azure Key Vault
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Tjänstens huvudautentisering
Om du vill använda autentisering med tjänstens huvudnamn anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| servicePrincipalId | Ange programmets klient-ID. | Ja |
| servicePrincipalCredential | Autentiseringsuppgifterna för tjänstens huvudnamn. Ange programmets nyckel. Markera det här fältet som SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. | Ja |
| klientorganisation | Ange klientinformationen (domännamn eller klient-ID) som programmet finns under. Du kan hämta den genom att hovra musen i det övre högra hörnet i Azure-portalen. | Ja |
| azureCloudType | För autentisering med tjänstens huvudnamn anger du vilken typ av Azure-molnmiljö som ditt Microsoft Entra-program är registrerat i. Tillåtna värden är AzurePublic, AzureChina, AzureUsGovernmentoch AzureGermany. Som standard används datafabriken eller Synapse-pipelinens molnmiljö. |
Nej |
Du måste också följa stegen nedan:
Skapa ett Microsoft Entra-program från Azure-portalen. Anteckna programnamnet och följande värden som definierar den länkade tjänsten:
- Program-ID:t
- Programnyckel
- Klientorganisations-ID
Etablera en Microsoft Entra-administratör för servern i Azure-portalen om du inte redan har gjort det. Microsoft Entra-administratören kan vara en Microsoft Entra-användare eller Microsoft Entra-grupp. Om du ger gruppen med hanterad identitet en administratörsroll hoppar du över steg 3 och 4. Administratören har fullständig åtkomst till databasen.
Skapa oberoende databasanvändare för tjänstens huvudnamn. Anslut till informationslagret från eller till vilket du vill kopiera data med hjälp av verktyg som SSMS, med en Microsoft Entra-identitet som har minst ALTER ANY USER-behörighet. Kör följande T-SQL:
CREATE USER [your_application_name] FROM EXTERNAL PROVIDER;Ge tjänstens huvudnamn nödvändiga behörigheter som du normalt gör för SQL-användare eller andra. Kör följande kod eller se fler alternativ här. Om du vill använda PolyBase för att läsa in data lär du dig vilken databasbehörighet som krävs.
EXEC sp_addrolemember db_owner, [your application name];Konfigurera en länkad Azure Synapse Analytics-tjänst på en Azure Data Factory- eller Synapse-arbetsyta.
Exempel på länkad tjänst som använder autentisering med tjänstens huvudnamn
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Systemtilldelade hanterade identiteter för Azure-resursautentisering
En datafabrik eller Synapse-arbetsyta kan associeras med en systemtilldelad hanterad identitet för Azure-resurser som representerar resursen. Du kan använda den här hanterade identiteten för Azure Synapse Analytics-autentisering. Den avsedda resursen kan komma åt och kopiera data från eller till ditt informationslager med hjälp av den här identiteten.
Om du vill använda systemtilldelad hanterad identitetsautentisering anger du de allmänna egenskaper som beskrivs i föregående avsnitt och följer dessa steg.
Etablera en Microsoft Entra-administratör för servern på Azure-portalen om du inte redan har gjort det. Microsoft Entra-administratören kan vara en Microsoft Entra-användare eller Microsoft Entra-grupp. Om du ger gruppen med systemtilldelad hanterad identitet en administratörsroll hoppar du över steg 3 och 4. Administratören har fullständig åtkomst till databasen.
Skapa oberoende databasanvändare för den systemtilldelade hanterade identiteten. Anslut till informationslagret från eller till vilket du vill kopiera data med hjälp av verktyg som SSMS, med en Microsoft Entra-identitet som har minst ALTER ANY USER-behörighet. Kör följande T-SQL.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Ge den systemtilldelade hanterade identiteten nödvändiga behörigheter som du normalt gör för SQL-användare och andra. Kör följande kod eller se fler alternativ här. Om du vill använda PolyBase för att läsa in data lär du dig vilken databasbehörighet som krävs.
EXEC sp_addrolemember db_owner, [your_resource_name];Konfigurera en länkad Azure Synapse Analytics-tjänst.
Exempel:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Användartilldelad hanterad identitetsautentisering
En datafabrik eller Synapse-arbetsyta kan associeras med en användartilldelad hanterad identitet som representerar resursen. Du kan använda den här hanterade identiteten för Azure Synapse Analytics-autentisering. Den avsedda resursen kan komma åt och kopiera data från eller till ditt informationslager med hjälp av den här identiteten.
Om du vill använda användartilldelad hanterad identitetsautentisering anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| autentiseringsuppgifter | Ange den användartilldelade hanterade identiteten som autentiseringsobjekt. | Ja |
Du måste också följa stegen nedan:
Etablera en Microsoft Entra-administratör för servern på Azure-portalen om du inte redan har gjort det. Microsoft Entra-administratören kan vara en Microsoft Entra-användare eller Microsoft Entra-grupp. Om du beviljar gruppen med användartilldelad hanterad identitet en administratörsroll hoppar du över steg 3. Administratören har fullständig åtkomst till databasen.
Skapa inneslutna databasanvändare för den användartilldelade hanterade identiteten. Anslut till informationslagret från eller till vilket du vill kopiera data med hjälp av verktyg som SSMS, med en Microsoft Entra-identitet som har minst ALTER ANY USER-behörighet. Kör följande T-SQL.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Skapa en eller flera användartilldelade hanterade identiteter och ge den användartilldelade hanterade identiteten nödvändiga behörigheter som du normalt gör för SQL-användare och andra. Kör följande kod eller se fler alternativ här. Om du vill använda PolyBase för att läsa in data lär du dig vilken databasbehörighet som krävs.
EXEC sp_addrolemember db_owner, [your_resource_name];Tilldela en eller flera användartilldelade hanterade identiteter till din datafabrik och skapa autentiseringsuppgifter för varje användartilldelad hanterad identitet.
Konfigurera en länkad Azure Synapse Analytics-tjänst.
Exempel
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Äldre version
Dessa allmänna egenskaper stöds för en länkad Azure Synapse Analytics-tjänst när du använder äldre version:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till AzureSqlDW. | Ja |
| connectionString | Ange den information som behövs för att ansluta till Azure Synapse Analytics-instansen för egenskapen connectionString . Markera det här fältet som en SecureString för att lagra det på ett säkert sätt. Du kan också placera lösenords-/tjänstens huvudnyckel i Azure Key Vault och om det är SQL-autentisering hämtar du konfigurationen password från niska veze. Mer information finns i artikeln Lagra autentiseringsuppgifter i Azure Key Vault . |
Ja |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller en lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
För olika autentiseringstyper, se följande avsnitt om specifika egenskaper respektive förutsättningar:
- SQL-autentisering för den äldre versionen
- Autentisering med tjänstens huvudnamn för den äldre versionen
- Systemtilldelad hanterad identitetsautentisering för den äldre versionen
- Användartilldelad hanterad identitetsautentisering för den äldre versionen
SQL-autentisering för den äldre versionen
Om du vill använda SQL-autentisering anger du de allmänna egenskaper som beskrivs i föregående avsnitt.
Autentisering med tjänstens huvudnamn för den äldre versionen
Om du vill använda autentisering med tjänstens huvudnamn anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| servicePrincipalId | Ange programmets klient-ID. | Ja |
| servicePrincipalKey | Ange programmets nyckel. Markera det här fältet som en SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. | Ja |
| klientorganisation | Ange klientinformationen, till exempel domännamnet eller klient-ID:t, under vilket ditt program finns. Hämta den genom att hovra musen i det övre högra hörnet i Azure-portalen. | Ja |
| azureCloudType | För autentisering med tjänstens huvudnamn anger du vilken typ av Azure-molnmiljö som ditt Microsoft Entra-program är registrerat i. Tillåtna värden är AzurePublic, AzureChina, AzureUsGovernment och AzureGermany. Som standard används datafabriken eller Synapse-pipelinens molnmiljö. |
Nej |
Du måste också följa stegen i autentisering med tjänstens huvudnamn för att bevilja motsvarande behörighet.
Systemtilldelad hanterad identitetsautentisering för den äldre versionen
Om du vill använda systemtilldelad hanterad identitetsautentisering följer du samma steg för den rekommenderade versionen i Systemtilldelad hanterad identitetsautentisering.
Användartilldelad hanterad identitetsautentisering för äldre version
Om du vill använda användartilldelad hanterad identitetsautentisering följer du samma steg för den rekommenderade versionen i Användartilldelad hanterad identitetsautentisering.
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln Datauppsättningar .
Följande egenskaper stöds för Azure Synapse Analytics-datauppsättning:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till AzureSqlDWTable. | Ja |
| schema | Namnet på schemat. | Nej för källa, Ja för mottagare |
| table | Namnet på tabellen/vyn. | Nej för källa, Ja för mottagare |
| tableName | Namnet på tabellen/vyn med schemat. Den här egenskapen stöds för bakåtkompatibilitet. För ny arbetsbelastning använder du schema och table. |
Nej för källa, Ja för mottagare |
Exempel på datauppsättningsegenskaper
{
"name": "AzureSQLDWDataset",
"properties":
{
"type": "AzureSqlDWTable",
"linkedServiceName": {
"referenceName": "<Azure Synapse Analytics linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Egenskaper för kopieringsaktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Azure Synapse Analytics-källan och mottagaren.
Azure Synapse Analytics som källa
Dricks
Om du vill läsa in data från Azure Synapse Analytics effektivt med hjälp av datapartitionering kan du läsa mer från Parallell kopiering från Azure Synapse Analytics.
Om du vill kopiera data från Azure Synapse Analytics anger du typegenskapen i kopieringsaktivitetskällan till SqlDWSource. Följande egenskaper stöds i avsnittet Kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till SqlDWSource. | Ja |
| sqlReaderQuery | Använd den anpassade SQL-frågan för att läsa data. Exempel: select * from MyTable. |
Nej |
| sqlReaderStoredProcedureName | Namnet på den lagrade proceduren som läser data från källtabellen. Den sista SQL-instruktionen måste vara en SELECT-instruktion i den lagrade proceduren. | Nej |
| storedProcedureParameters | Parametrar för den lagrade proceduren. Tillåtna värden är namn- eller värdepar. Namn och hölje för parametrar måste matcha namnen och höljet för de lagrade procedureparametrarna. |
Nej |
| isolationLevel | Anger transaktionslåsningsbeteendet för SQL-källan. De tillåtna värdena är: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Om den inte anges används databasens standardisoleringsnivå. Mer information finns i system.data.isolationlevel. | Nej |
| partitionOptions | Anger de datapartitioneringsalternativ som används för att läsa in data från Azure Synapse Analytics. Tillåtna värden är: Ingen (standard), PhysicalPartitionsOfTable och DynamicRange. När ett partitionsalternativ är aktiverat (dvs. inte None) styrs graden av parallellitet för samtidig inläsning av data från en Azure Synapse Analytics av parallelCopies inställningen för kopieringsaktiviteten. |
Nej |
| partitionSettings | Ange gruppen med inställningarna för datapartitionering. Använd när partitionsalternativet inte Noneär . |
Nej |
Under partitionSettings: |
||
| partitionColumnName | Ange namnet på källkolumnen i heltal eller datum/datetime-typ (int, , bigintsmallint, date, smalldatetime, datetime, datetime2eller datetimeoffset) som ska användas av intervallpartitionering för parallell kopiering. Om det inte anges identifieras indexet eller den primära nyckeln i tabellen automatiskt och används som partitionskolumn.Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata kopplar ?DfDynamicRangePartitionCondition du in WHERE-satsen. Ett exempel finns i avsnittet Parallellkopiering från SQL-databas . |
Nej |
| partitionUpperBound | Det maximala värdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. Använd när partitionsalternativet är DynamicRange. Ett exempel finns i avsnittet Parallellkopiering från SQL-databas . |
Nej |
| partitionLowerBound | Minimivärdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. Använd när partitionsalternativet är DynamicRange. Ett exempel finns i avsnittet Parallellkopiering från SQL-databas . |
Nej |
Observera följande:
- När du använder lagrad procedur i källan för att hämta data bör du tänka på att om den lagrade proceduren är utformad som att returnera ett annat schema när ett annat parametervärde skickas in, kan det uppstå ett fel eller ett oväntat resultat när du importerar schemat från användargränssnittet eller när du kopierar data till SQL Database med automatisk tabellskapande.
Exempel: använda SQL-fråga
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exempel: använda lagrad procedur
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exempel på lagrad procedur:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Azure Synapse Analytics som mottagare
Azure Data Factory- och Synapse-pipelines stöder tre sätt att läsa in data i Azure Synapse Analytics.
- Använda COPY-instruktion
- Använda PolyBase
- Använda massinfogning
Det snabbaste och mest skalbara sättet att läsa in data är genom COPY-instruktionen eller PolyBase.
Om du vill kopiera data till Azure Synapse Analytics anger du mottagartypen i Kopieringsaktivitet till SqlDWSink. Följande egenskaper stöds i avsnittet Kopieringsaktivitetsmottagare:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetsmottagaren måste anges till SqlDWSink. | Ja |
| allowPolyBase | Anger om du vill använda PolyBase för att läsa in data i Azure Synapse Analytics. allowCopyCommand och allowPolyBase kan inte vara båda sanna. Mer information finns i Använda PolyBase för att läsa in data i Azure Synapse Analytics . Tillåtna värden är True och False (standard). |
Nej. Använd när du använder PolyBase. |
| polyBaseSettings | En grupp med egenskaper som kan anges när egenskapen är inställd på allowPolybase true. |
Nej. Använd när du använder PolyBase. |
| allowCopyCommand | Anger om du vill använda COPY-instruktionen för att läsa in data i Azure Synapse Analytics. allowCopyCommand och allowPolyBase kan inte vara båda sanna. Mer information finns i Använda COPY-instruktion för att läsa in data i Azure Synapse Analytics . Tillåtna värden är True och False (standard). |
Nej. Använd när du använder COPY. |
| copyCommandSettings | En grupp med egenskaper som kan anges när allowCopyCommand egenskapen är inställd på TRUE. |
Nej. Använd när du använder COPY. |
| writeBatchSize | Antal rader som ska infogas i SQL-tabellen per batch. Det tillåtna värdet är heltal (antal rader). Som standard avgör tjänsten dynamiskt lämplig batchstorlek baserat på radstorleken. |
Nej. Använd när du använder massinfogning. |
| writeBatchTimeout | Väntetiden för att åtgärden infoga, upsert och lagrad procedur ska slutföras innan tidsgränsen uppnås. Tillåtna värden är för tidsintervallet. Ett exempel är "00:30:00" i 30 minuter. Om inget värde anges är tidsgränsen som standard "00:30:00". |
Nej. Använd när du använder massinfogning. |
| preCopyScript | Ange en SQL-fråga för kopieringsaktivitet som ska köras innan du skriver data till Azure Synapse Analytics i varje körning. Använd den här egenskapen för att rensa inlästa data. | Nej |
| tableOption | Anger om mottagartabellen ska skapas automatiskt, om den inte finns, baserat på källschemat. Tillåtna värden är: none (standard), autoCreate. |
Nej |
| disableMetricsCollection | Tjänsten samlar in mått, till exempel Azure Synapse Analytics-DWU:er för kopieringsprestandaoptimering och rekommendationer, vilket ger ytterligare åtkomst till huvuddatabasen. Om du är intresserad av det här beteendet anger du true för att inaktivera det. |
Nej (standard är false) |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
| WriteBehavior | Ange skrivbeteendet för kopieringsaktiviteten för att läsa in data i Azure Synapse Analytics. Det tillåtna värdet är Insert och Upsert. Som standard använder tjänsten insert för att läsa in data. |
Nej |
| upsertSettings | Ange gruppen med inställningarna för skrivbeteende. Använd när alternativet WriteBehavior är Upsert. |
Nej |
Under upsertSettings: |
||
| keys | Ange kolumnnamnen för unik radidentifiering. Antingen kan en enskild nyckel eller en serie nycklar användas. Om den inte anges används primärnyckeln. | Nej |
| interimSchemaName | Ange interimschemat för att skapa interimtabellen. Obs! Användaren måste ha behörighet att skapa och ta bort tabellen. Som standard delar interimtabellen samma schema som mottagartabellen. | Nej |
Exempel 1: Azure Synapse Analytics-mottagare
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true,
"polyBaseSettings":
{
"rejectType": "percentage",
"rejectValue": 10.0,
"rejectSampleValue": 100,
"useTypeDefault": true
}
}
Exempel 2: Upsert-data
"sink": {
"type": "SqlDWSink",
"writeBehavior": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
],
"interimSchemaName": "<interim schema name>"
},
}
Parallell kopiering från Azure Synapse Analytics
Azure Synapse Analytics-anslutningsappen i kopieringsaktivitet ger inbyggd datapartitionering för att kopiera data parallellt. Du hittar alternativ för datapartitionering på fliken Källa i kopieringsaktiviteten.
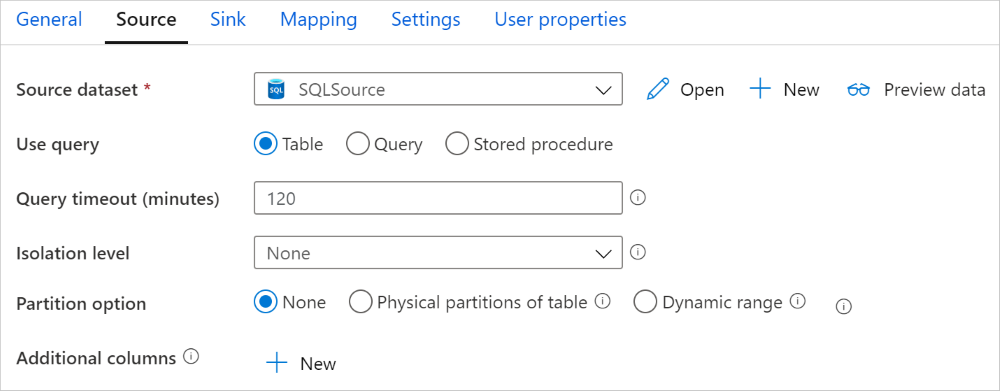
När du aktiverar partitionerad kopiering kör kopieringsaktiviteten parallella frågor mot din Azure Synapse Analytics-källa för att läsa in data efter partitioner. Den parallella graden styrs av parallelCopies inställningen för kopieringsaktiviteten. Om du till exempel anger parallelCopies till fyra genererar och kör tjänsten samtidigt fyra frågor baserat på ditt angivna partitionsalternativ och inställningar, och varje fråga hämtar en del data från Azure Synapse Analytics.
Du rekommenderas att aktivera parallell kopiering med datapartitionering, särskilt när du läser in stora mängder data från Azure Synapse Analytics. Följande är föreslagna konfigurationer för olika scenarier. När du kopierar data till filbaserat datalager rekommenderar vi att du skriver till en mapp som flera filer (anger endast mappnamn), i vilket fall prestandan är bättre än att skriva till en enda fil.
| Scenario | Föreslagna inställningar |
|---|---|
| Full belastning från en stor tabell med fysiska partitioner. | Partitionsalternativ: Fysiska partitioner i tabellen. Under körningen identifierar tjänsten automatiskt de fysiska partitionerna och kopierar data efter partitioner. Om du vill kontrollera om tabellen har fysisk partition eller inte kan du läsa den här frågan. |
| Fullständig belastning från en stor tabell, utan fysiska partitioner, med ett heltal eller en datetime-kolumn för datapartitionering. | Partitionsalternativ: Partition med dynamiskt intervall. Partitionskolumn (valfritt): Ange den kolumn som används för att partitionera data. Om det inte anges används index- eller primärnyckelkolumnen. Partitionens övre gräns och partitionens nedre gräns (valfritt): Ange om du vill fastställa partitionssteget. Detta är inte för att filtrera raderna i tabellen, alla rader i tabellen partitioneras och kopieras. Om det inte anges identifierar kopieringsaktiviteten värdena automatiskt. Om partitionskolumnen "ID" till exempel har värden mellan 1 och 100 och du anger den nedre gränsen som 20 och den övre gränsen som 80, med parallell kopia som 4, hämtar tjänsten data med 4 partitioner – ID:n i intervallet <=20, [21, 50], [51, 80] >respektive =81. |
| Läs in en stor mängd data med hjälp av en anpassad fråga, utan fysiska partitioner, med ett heltal eller en date/datetime-kolumn för datapartitionering. | Partitionsalternativ: Partition med dynamiskt intervall. Fråga: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitionskolumn: Ange den kolumn som används för att partitionera data. Partitionens övre gräns och partitionens nedre gräns (valfritt): Ange om du vill fastställa partitionssteget. Detta är inte för att filtrera raderna i tabellen, alla rader i frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. Om partitionskolumnen "ID" till exempel har värden mellan 1 och 100 och du anger den nedre gränsen som 20 och den övre gränsen som 80, med parallell kopia som 4, hämtar tjänsten data med 4 partitioner – ID:n i intervallet <=20, [21, 50], [51, 80] >respektive =81. Här är fler exempelfrågor för olika scenarier: 1. Fråga hela tabellen: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Fråga från en tabell med kolumnval och ytterligare where-clause-filter: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Fråga med underfrågor: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Fråga med partition i underfrågor: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Metodtips för att läsa in data med partitionsalternativet:
- Välj distinkt kolumn som partitionskolumn (till exempel primärnyckel eller unik nyckel) för att undvika datasnedvridning.
- Om tabellen har inbyggd partition använder du partitionsalternativet "Fysiska partitioner av tabellen" för att få bättre prestanda.
- Om du använder Azure Integration Runtime för att kopiera data kan du ange större "Data Integration Units (DIU)" (>4) för att använda mer databehandlingsresurser. Kontrollera tillämpliga scenarier där.
- "Grad av kopieringsparallellitet" styr partitionsnumren, anger det här talet för stort ibland skadar prestandan, rekommenderar att du anger det här talet som (DIU eller antalet lokalt installerade IR-noder) * (2 till 4).
- Observera att Azure Synapse Analytics kan köra högst 32 frågor i taget, och om du anger "Grad av kopieringsparallellitet" för stor kan det orsaka problem med Synapse-begränsning.
Exempel: fullständig belastning från en stor tabell med fysiska partitioner
"source": {
"type": "SqlDWSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exempel: fråga med partition för dynamiskt intervall
"source": {
"type": "SqlDWSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Exempelfråga för att kontrollera fysisk partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Om tabellen har en fysisk partition ser du "HasPartition" som "ja".
Använda COPY-instruktion för att läsa in data i Azure Synapse Analytics
Att använda COPY-instruktionen är ett enkelt och flexibelt sätt att läsa in data i Azure Synapse Analytics med högt dataflöde. Mer information finns i Massinläsningsdata med copy-instruktionen
- Om dina källdata finns i Azure Blob eller Azure Data Lake Storage Gen2 och formatet är COPY-instruktionskompatibelt kan du använda kopieringsaktivitet för att direkt anropa COPY-instruktionen så att Azure Synapse Analytics kan hämta data från källan. Mer information finns i Direct copy by using COPY statement (Direktkopiering med copy-instruktion).
- Om källdatalagret och formatet inte ursprungligen stöds av COPY-instruktionen använder du funktionen Mellanlagrad kopia med hjälp av copy-instruktionsfunktionen i stället. Den mellanlagrade kopieringsfunktionen ger dig också bättre dataflöde. Den konverterar automatiskt data till copy-instruktionskompatibelt format, lagrar data i Azure Blob Storage och anropar sedan COPY-instruktionen för att läsa in data till Azure Synapse Analytics.
Dricks
När du använder COPY-instruktionen med Azure Integration Runtime är effektiva dataintegreringsenheter (DIU) alltid 2. Justering av DIU påverkar inte prestanda eftersom inläsning av data från lagring drivs av Azure Synapse-motorn.
Direktkopiering med copy-instruktion
Azure Synapse Analytics COPY-instruktionen har direkt stöd för Azure Blob och Azure Data Lake Storage Gen2. Om dina källdata uppfyller kriterierna som beskrivs i det här avsnittet använder du COPY-instruktionen för att kopiera direkt från källdatalagret till Azure Synapse Analytics. Annars använder du stegvis kopiering med hjälp av COPY-instruktionen. Tjänsten kontrollerar inställningarna och misslyckas med kopieringsaktiviteten om villkoret inte uppfylls.
Den länkade källtjänsten och formatet är med följande typer och autentiseringsmetoder:
Typ av källdatalager som stöds Format som stöds Typ av källautentisering som stöds Azure Blob Avgränsad text Kontonyckelautentisering, signaturautentisering med delad åtkomst, autentisering med tjänstens huvudnamn (med ServicePrincipalKey), systemtilldelad hanterad identitetsautentisering Parkettgolv Kontonyckelautentisering, signaturautentisering för delad åtkomst ORCH Kontonyckelautentisering, signaturautentisering för delad åtkomst Azure Data Lake Storage Gen2 Avgränsad text
Parkettgolv
ORCHKontonyckelautentisering, autentisering med tjänstens huvudnamn (med ServicePrincipalKey), signaturautentisering för delad åtkomst, systemtilldelad hanterad identitetsautentisering Viktigt!
- När du använder hanterad identitetsautentisering för den länkade lagringstjänsten får du lära dig de konfigurationer som behövs för Azure Blob respektive Azure Data Lake Storage Gen2 .
- Om Azure Storage har konfigurerats med VNet-tjänstslutpunkten måste du använda hanterad identitetsautentisering med "tillåt betrodd Microsoft-tjänst" aktiverad på lagringskontot, se Påverkan av att använda VNet-tjänstslutpunkter med Azure Storage.
Formatinställningarna är med följande:
- För Parquet:
compressionkan inte vara någon komprimering, Snappy ellerGZip. - För ORC:
compressionkan inte vara någon komprimering,zlibeller snappy. - För avgränsad text:
rowDelimiteranges uttryckligen som ett enskilt tecken eller "\r\n" stöds inte standardvärdet.nullValueär kvar som standard eller inställd på tom sträng ("").encodingNameär kvar som standard eller inställd på utf-8 eller utf-16.escapeCharmåste vara samma somquoteCharoch är inte tom.skipLineCountlämnas som standard eller anges till 0.compressionkan inte vara någon komprimering ellerGZip.
- För Parquet:
Om källan är en mapp
recursivemåste kopieringsaktiviteten vara inställd på true ochwildcardFilenamemåste vara*eller*.*.wildcardFolderPath,wildcardFilename(annat än*eller*.*),modifiedDateTimeStart,modifiedDateTimeEnd, ,enablePartitionDiscoveryprefixochadditionalColumnshar inte angetts.
Följande COPY-instruktionsinställningar stöds under allowCopyCommand i kopieringsaktiviteten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| defaultValues | Anger standardvärdena för varje målkolumn i Azure Synapse Analytics. Standardvärdena i egenskapen skriver över standardvillkorsuppsättningen i informationslagret och identitetskolumnen kan inte ha ett standardvärde. | Nej |
| additionalOptions | Ytterligare alternativ som skickas till en Azure Synapse Analytics COPY-instruktion direkt i "With"-satsen i COPY-instruktionen. Ange värdet efter behov för att justera kraven för COPY-instruktionen. | Nej |
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Mellanlagrad kopia med copy-instruktion
När dina källdata inte är internt kompatibla med COPY-instruktionen aktiverar du datakopiering via en mellanlagring av Azure Blob eller Azure Data Lake Storage Gen2 (det kan inte vara Azure Premium Storage). I det här fallet konverterar tjänsten automatiskt data för att uppfylla dataformatkraven för COPY-instruktionen. Sedan anropas COPY-instruktionen för att läsa in data i Azure Synapse Analytics. Slutligen rensas dina tillfälliga data från lagringen. Mer information om hur du kopierar data via en mellanlagring finns i Mellanlagrad kopia .
Om du vill använda den här funktionen skapar du en länkad Azure Blob Storage-tjänst eller en länkad Azure Data Lake Storage Gen2-tjänst med kontonyckel eller systemhanterad identitetsautentisering som refererar till Azure Storage-kontot som tillfällig lagring.
Viktigt!
- När du använder hanterad identitetsautentisering för din länkade mellanlagringstjänst får du lära dig de konfigurationer som behövs för Azure Blob respektive Azure Data Lake Storage Gen2 . Du måste också bevilja behörigheter till din hanterade identitet för Azure Synapse Analytics-arbetsytan i ditt mellanlagringskonto för Azure Blob Storage eller Azure Data Lake Storage Gen2. Information om hur du beviljar den här behörigheten finns i Bevilja behörigheter till arbetsytans hanterade identitet.
- Om din mellanlagring av Azure Storage har konfigurerats med VNet-tjänstslutpunkten måste du använda hanterad identitetsautentisering med "tillåt betrodd Microsoft-tjänst" aktiverad på lagringskontot. Se Effekten av att använda VNet-tjänstslutpunkter med Azure Storage.
Viktigt!
Om din mellanlagring av Azure Storage har konfigurerats med en hanterad privat slutpunkt och lagringsbrandväggen är aktiverad måste du använda hanterad identitetsautentisering och ge Storage Blob Data Reader behörighet till Synapse SQL Server för att säkerställa att den kan komma åt mellanlagrade filer under kopieringssatsens inläsning.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Använda PolyBase för att läsa in data i Azure Synapse Analytics
Att använda PolyBase är ett effektivt sätt att läsa in en stor mängd data i Azure Synapse Analytics med högt dataflöde. Du ser en stor vinst i dataflödet med hjälp av PolyBase i stället för standardmekanismen BULKINSERT.
- Om dina källdata finns i Azure Blob eller Azure Data Lake Storage Gen2 och formatet är PolyBase-kompatibelt kan du använda kopieringsaktivitet för att direkt anropa PolyBase för att låta Azure Synapse Analytics hämta data från källan. Mer information finns i Direktkopiering med hjälp av PolyBase.
- Om ditt källdatalager och format inte ursprungligen stöds av PolyBase använder du den mellanlagrade kopian med hjälp av PolyBase-funktionen i stället. Den mellanlagrade kopieringsfunktionen ger dig också bättre dataflöde. Den konverterar automatiskt data till PolyBase-kompatibelt format, lagrar data i Azure Blob Storage och anropar sedan PolyBase för att läsa in data till Azure Synapse Analytics.
Dricks
Läs mer om metodtips för att använda PolyBase. När du använder PolyBase med Azure Integration Runtime är effektiva dataintegreringsenheter (DIU) för direkt eller mellanlagrad lagring till Synapse alltid 2. Justering av DIU påverkar inte prestanda eftersom inläsning av data från lagring drivs av Synapse-motorn.
Följande PolyBase-inställningar stöds under polyBaseSettings i kopieringsaktiviteten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| rejectValue | Anger antalet eller procentandelen rader som kan avvisas innan frågan misslyckas. Läs mer om Alternativen för att avvisa PolyBase i avsnittet Argument i CREATE EXTERNAL TABLE (Transact-SQL). Tillåtna värden är 0 (standard), 1, 2 osv. |
Nej |
| rejectType | Anger om alternativet rejectValue är ett literalvärde eller en procentandel. Tillåtna värden är Värde (standard) och Procent. |
Nej |
| rejectSampleValue | Avgör hur många rader som ska hämtas innan PolyBase beräknar om procentandelen avvisade rader. Tillåtna värden är 1, 2 osv. |
Ja, om rejectType är procent. |
| useTypeDefault | Anger hur du hanterar saknade värden i avgränsade textfiler när PolyBase hämtar data från textfilen. Läs mer om den här egenskapen i avsnittet Argument i CREATE EXTERNAL FILE FORMAT (Transact-SQL). Tillåtna värden är True och False (standard). |
Nej |
Direktkopiering med hjälp av PolyBase
Azure Synapse Analytics PolyBase har direkt stöd för Azure Blob och Azure Data Lake Storage Gen2. Om dina källdata uppfyller de kriterier som beskrivs i det här avsnittet använder du PolyBase för att kopiera direkt från källdatalagret till Azure Synapse Analytics. Annars kan du använda mellanlagrad kopia med hjälp av PolyBase.
Dricks
Om du vill kopiera data effektivt till Azure Synapse Analytics kan du lära dig mer från Azure Data Factory, vilket gör det ännu enklare och enklare att upptäcka insikter från data när du använder Data Lake Store med Azure Synapse Analytics.
Om kraven inte uppfylls kontrollerar tjänsten inställningarna och återgår automatiskt till BULKINSERT-mekanismen för dataflytten.
Den länkade källtjänsten har följande typer och autentiseringsmetoder:
Typ av källdatalager som stöds Typ av källautentisering som stöds Azure Blob Kontonyckelautentisering, systemtilldelad hanterad identitetsautentisering Azure Data Lake Storage Gen2 Kontonyckelautentisering, systemtilldelad hanterad identitetsautentisering Viktigt!
- När du använder hanterad identitetsautentisering för den länkade lagringstjänsten får du lära dig de konfigurationer som behövs för Azure Blob respektive Azure Data Lake Storage Gen2 .
- Om Azure Storage har konfigurerats med VNet-tjänstslutpunkten måste du använda hanterad identitetsautentisering med "tillåt betrodd Microsoft-tjänst" aktiverad på lagringskontot, se Påverkan av att använda VNet-tjänstslutpunkter med Azure Storage.
Källdataformatet är parquet, ORC eller avgränsad text med följande konfigurationer:
- Mappsökvägen innehåller inte jokerteckenfilter.
- Filnamnet är tomt eller pekar på en enda fil. Om du anger jokerteckenfilnamn i kopieringsaktiviteten kan det bara vara
*eller*.*. rowDelimiterär standard, \n, \r\n eller \r.nullValueär kvar som standard eller inställd på tom sträng (""), ochtreatEmptyAsNulllämnas som standard eller inställd på true.encodingNameär kvar som standard eller inställd på utf-8.quoteChar,escapeCharochskipLineCounthar inte angetts. PolyBase stöder hoppa över rubrikraden, som kan konfigureras somfirstRowAsHeader.compressionkan inte vara någon komprimering,GZip, eller Deflate.
Om källan är en mapp
recursivemåste kopieringsaktiviteten vara inställd på true.wildcardFolderPath,wildcardFilename,modifiedDateTimeStart,modifiedDateTimeEnd,prefix, ochenablePartitionDiscoveryadditionalColumnshar inte angetts.
Kommentar
Om källan är en mapp noterar du att PolyBase hämtar filer från mappen och alla dess undermappar, och den hämtar inte data från filer där filnamnet börjar med en understrykning (_) eller en punkt (.), enligt beskrivningen här – LOCATION-argumentet.
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
}
}
]
Mellanlagrad kopia med hjälp av PolyBase
När dina källdata inte är internt kompatibla med PolyBase aktiverar du datakopiering via en mellanlagring av Azure Blob eller Azure Data Lake Storage Gen2 (det kan inte vara Azure Premium Storage). I det här fallet konverterar tjänsten automatiskt data för att uppfylla dataformatkraven för PolyBase. Sedan anropas PolyBase för att läsa in data i Azure Synapse Analytics. Slutligen rensas dina tillfälliga data från lagringen. Mer information om hur du kopierar data via en mellanlagring finns i Mellanlagrad kopia .
Om du vill använda den här funktionen skapar du en länkad Azure Blob Storage-tjänst eller en länkad Azure Data Lake Storage Gen2-tjänst med kontonyckel eller hanterad identitetsautentisering som refererar till Azure Storage-kontot som tillfällig lagring.
Viktigt!
- När du använder hanterad identitetsautentisering för din länkade mellanlagringstjänst får du lära dig de konfigurationer som behövs för Azure Blob respektive Azure Data Lake Storage Gen2 . Du måste också bevilja behörigheter till din hanterade identitet för Azure Synapse Analytics-arbetsytan i ditt mellanlagringskonto för Azure Blob Storage eller Azure Data Lake Storage Gen2. Information om hur du beviljar den här behörigheten finns i Bevilja behörigheter till arbetsytans hanterade identitet.
- Om din mellanlagring av Azure Storage har konfigurerats med VNet-tjänstslutpunkten måste du använda hanterad identitetsautentisering med "tillåt betrodd Microsoft-tjänst" aktiverad på lagringskontot. Se Effekten av att använda VNet-tjänstslutpunkter med Azure Storage.
Viktigt!
Om din mellanlagring av Azure Storage har konfigurerats med hanterad privat slutpunkt och har lagringsbrandväggen aktiverad måste du använda hanterad identitetsautentisering och ge Storage Blob Data Reader behörigheter till Synapse SQL Server för att säkerställa att den kan komma åt mellanlagrade filer under PolyBase-belastningen.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Metodtips för att använda PolyBase
Följande avsnitt innehåller metodtips utöver de metoder som nämns i Metodtips för Azure Synapse Analytics.
Nödvändig databasbehörighet
Om du vill använda PolyBase måste den användare som läser in data i Azure Synapse Analytics ha behörigheten "CONTROL" på måldatabasen. Ett sätt att uppnå detta är att lägga till användaren som medlem i db_owner roll. Lär dig hur du gör det i översikten över Azure Synapse Analytics.
Radstorlek och datatypsgränser
PolyBase-inläsningar är begränsade till rader som är mindre än 1 MB. Den kan inte användas för att läsa in till VARCHR(MAX), NVARCHAR(MAX) eller VARBINARY(MAX). Mer information finns i Kapacitetsbegränsningar för Azure Synapse Analytics-tjänsten.
När källdata har rader som är större än 1 MB kanske du vill dela upp källtabellerna lodrätt i flera små. Kontrollera att den största storleken på varje rad inte överskrider gränsen. De mindre tabellerna kan sedan läsas in med hjälp av PolyBase och sammanfogas i Azure Synapse Analytics.
För data med så breda kolumner kan du också använda icke-PolyBase för att läsa in data genom att inaktivera inställningen "tillåt PolyBase".
Resursklass för Azure Synapse Analytics
För att uppnå bästa möjliga dataflöde tilldelar du en större resursklass till användaren som läser in data i Azure Synapse Analytics via PolyBase.
PolyBase-felsökning
Läser in till decimalkolumn
Om dina källdata är i textformat eller andra icke-PolyBase-kompatibla butiker (med mellanlagrad kopiering och PolyBase) och den innehåller ett tomt värde som ska läsas in i kolumnen Decimal i Azure Synapse Analytics kan du få följande fel:
ErrorCode=FailedDbOperation, ......HadoopSqlException: Error converting data type VARCHAR to DECIMAL.....Detailed Message=Empty string can't be converted to DECIMAL.....
Lösningen är att avmarkera alternativet "Använd typstandard" (som falskt) i kopieringsaktivitetsmottagaren –> PolyBase-inställningar. "USE_TYPE_DEFAULT" är en inbyggd PolyBase-konfiguration som anger hur du hanterar saknade värden i avgränsade textfiler när PolyBase hämtar data från textfilen.
Kontrollera egenskapen tableName i Azure Synapse Analytics
Följande tabell innehåller exempel på hur du anger egenskapen tableName i JSON-datauppsättningen. Den visar flera kombinationer av schema- och tabellnamn.
| DB-schema | Tabellnamn | tableName JSON-egenskap |
|---|---|---|
| dbo | MyTable | MyTable eller dbo. MyTable eller [dbo]. [MyTable] |
| dbo1 | MyTable | dbo1. MyTable eller [dbo1]. [MyTable] |
| dbo | My.Table | [My.Table] eller [dbo]. [My.Table] |
| dbo1 | My.Table | [dbo1]. [My.Table] |
Om du ser följande fel kan problemet vara det värde som du angav för egenskapen tableName . Se tabellen ovan för rätt sätt att ange värden för egenskapen tableName JSON.
Type=System.Data.SqlClient.SqlException,Message=Invalid object name 'stg.Account_test'.,Source=.Net SqlClient Data Provider
Kolumner med standardvärden
För närvarande accepterar PolyBase-funktionen endast samma antal kolumner som i måltabellen. Ett exempel är en tabell med fyra kolumner där en av dem definieras med ett standardvärde. Indata måste fortfarande ha fyra kolumner. En datauppsättning med tre kolumner ger ett fel som liknar följande meddelande:
All columns of the table must be specified in the INSERT BULK statement.
NULL-värdet är en särskild form av standardvärdet. Om kolumnen är null kan indata i bloben för kolumnen vara tomma. Men den kan inte saknas i indatauppsättningen. PolyBase infogar NULL för saknade värden i Azure Synapse Analytics.
Extern filåtkomst misslyckades
Om du får följande fel kontrollerar du att du använder hanterad identitetsautentisering och har beviljat Storage Blob Data Reader-behörigheter till Azure Synapse-arbetsytans hanterade identitet.
Job failed due to reason: at Sink '[SinkName]': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist
Mer information finns i Bevilja behörigheter till hanterad identitet när arbetsytan har skapats.
Mappa dataflödesegenskaper
När du transformerar data i dataflödet för mappning kan du läsa och skriva till tabeller från Azure Synapse Analytics. Mer information finns i källtransformering och mottagartransformation i mappning av dataflöden.
Källtransformering
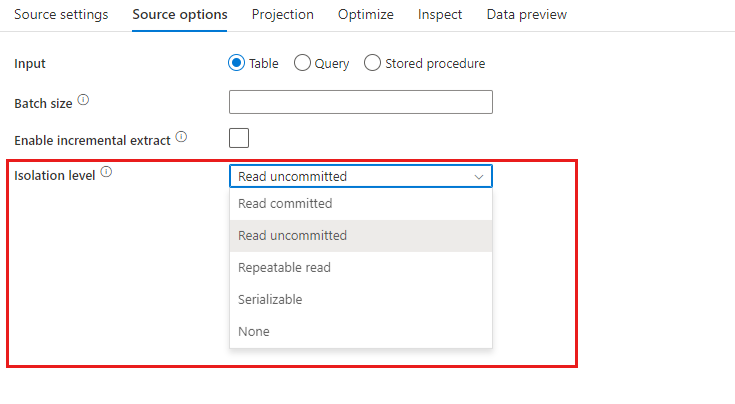
Inställningar som är specifika för Azure Synapse Analytics är tillgängliga på fliken Källalternativ i källtransformeringen.
Indata Välj om du pekar källan i en tabell (motsvarande Select * from <table-name>) eller anger en anpassad SQL-fråga.
Aktivera mellanlagring Det rekommenderas starkt att du använder det här alternativet i produktionsarbetsbelastningar med Azure Synapse Analytics-källor. När du kör en dataflödesaktivitet med Azure Synapse Analytics-källor från en pipeline uppmanas du att ange ett lagringskonto för mellanlagringsplats och använda det för mellanlagrad datainläsning. Det är den snabbaste mekanismen för att läsa in data från Azure Synapse Analytics.
- När du använder hanterad identitetsautentisering för den länkade lagringstjänsten får du lära dig de konfigurationer som behövs för Azure Blob respektive Azure Data Lake Storage Gen2 .
- Om Azure Storage har konfigurerats med VNet-tjänstslutpunkten måste du använda hanterad identitetsautentisering med "tillåt betrodd Microsoft-tjänst" aktiverad på lagringskontot, se Påverkan av att använda VNet-tjänstslutpunkter med Azure Storage.
- När du använder Azure Synapse-serverlös SQL-pool som källa stöds inte aktivering av mellanlagring.
Fråga: Om du väljer Fråga i indatafältet anger du en SQL-fråga för källan. Den här inställningen åsidosätter alla tabeller som du har valt i datauppsättningen. Order By-satser stöds inte här, men du kan ange en fullständig SELECT FROM-instruktion. Du kan också använda användardefinierade tabellfunktioner. select * from udfGetData() är en UDF i SQL som returnerar en tabell. Den här frågan skapar en källtabell som du kan använda i ditt dataflöde. Att använda frågor är också ett bra sätt att minska antalet rader för testning eller sökning.
SQL-exempel: Select * from MyTable where customerId > 1000 and customerId < 2000
Batchstorlek: Ange en batchstorlek för att segmentera stora data i läsningar. I dataflöden används den här inställningen för att ange Cachelagring av Spark-kolumner. Det här är ett alternativfält som använder Spark-standardvärden om det lämnas tomt.
Isoleringsnivå: Standardvärdet för SQL-källor i mappning av dataflöde är skrivskyddat. Du kan ändra isoleringsnivån här till något av följande värden:
- Läs bekräftad
- Läs som inte har genererats
- Repeterbar läsning
- Serialiserbar
- Ingen (ignorera isoleringsnivå)
Transformering av mottagare
Inställningar som är specifika för Azure Synapse Analytics är tillgängliga på fliken Inställningar i mottagartransformeringen.
Uppdateringsmetod: Avgör vilka åtgärder som tillåts på databasmålet. Standardvärdet är att endast tillåta infogningar. För att uppdatera, uppdatera eller ta bort rader krävs en ändringsradstransformering för att tagga rader för dessa åtgärder. För uppdateringar, upserts och borttagningar måste en nyckelkolumn eller kolumner anges för att avgöra vilken rad som ska ändras.
Tabellåtgärd: Avgör om du vill återskapa eller ta bort alla rader från måltabellen innan du skriver.
- Ingen: Ingen åtgärd utförs i tabellen.
- Återskapa: Tabellen tas bort och återskapas. Krävs om du skapar en ny tabell dynamiskt.
- Trunkera: Alla rader från måltabellen tas bort.
Aktivera mellanlagring: Detta möjliggör inläsning i Azure Synapse Analytics SQL-pooler med hjälp av kopieringskommandot och rekommenderas för de flesta Synapse-mottagare. Mellanlagringen konfigureras i Aktiviteten Kör dataflöde.
- När du använder hanterad identitetsautentisering för den länkade lagringstjänsten får du lära dig de konfigurationer som behövs för Azure Blob respektive Azure Data Lake Storage Gen2 .
- Om Azure Storage har konfigurerats med VNet-tjänstslutpunkten måste du använda hanterad identitetsautentisering med "tillåt betrodd Microsoft-tjänst" aktiverad på lagringskontot, se Påverkan av att använda VNet-tjänstslutpunkter med Azure Storage.
Batchstorlek: Styr hur många rader som skrivs i varje bucket. Större batchstorlekar förbättrar komprimering och minnesoptimering, men riskerar att få slut på minnesfel vid cachelagring av data.
Använd mottagarschema: Som standard skapas en tillfällig tabell under mottagarschemat som mellanlagring. Du kan också avmarkera alternativet Använd mottagarschema och i stället i Välj user DB-schema anger du ett schemanamn under vilket Data Factory skapar en mellanlagringstabell för att läsa in överordnade data och automatiskt rensa dem när de är klara. Kontrollera att du har behörigheten skapa tabell i databasen och ändra behörigheten för schemat.

För- och efter SQL-skript: Ange SQL-skript med flera rader som ska köras före (förbearbetning) och efter att (efterbearbetning) data har skrivits till din mottagardatabas

Dricks
- Vi rekommenderar att du bryter enskilda batchskript med flera kommandon i flera batchar.
- Det går endast att köra instruktioner av typen Data Definition Language (DDL) och Data Manipulation Language (DML), som returnerar ett enda uppdateringsvärde, som del av en batch. Läs mer om att utföra batchåtgärder
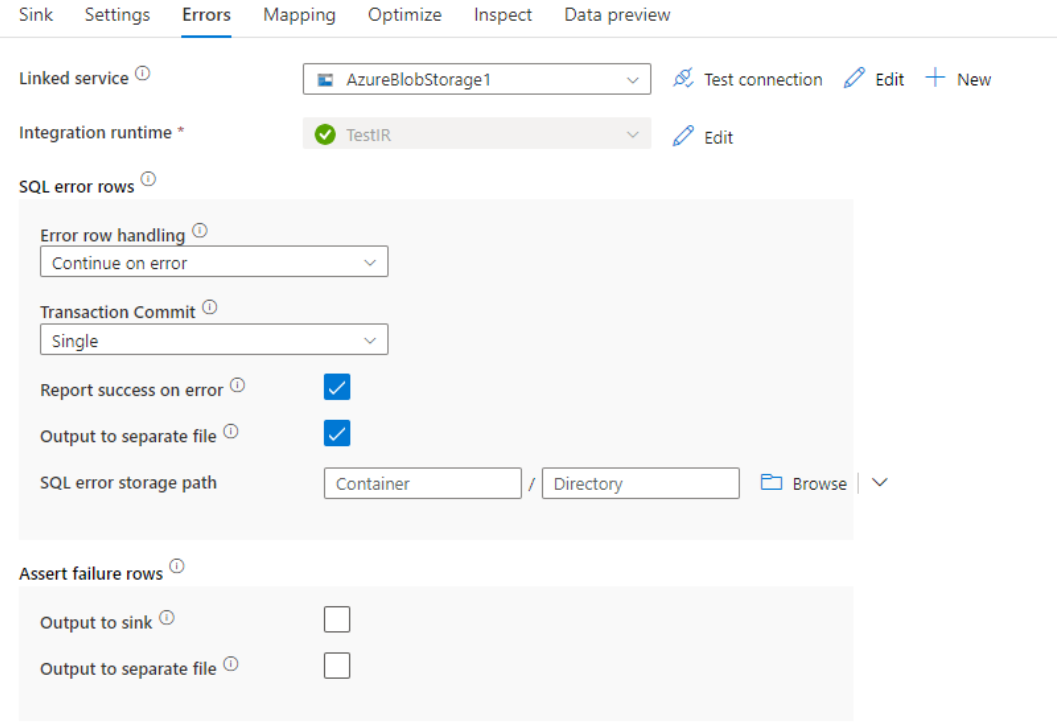
Felhantering av poster
När du skriver till Azure Synapse Analytics kan vissa datarader misslyckas på grund av begränsningar som anges av målet. Några vanliga fel är:
- Strängdata eller binära data trunkeras i tabellen
- Det går inte att infoga värdet NULL i kolumnen
- Konverteringen misslyckades när värdet konverteras till datatyp
Som standard misslyckas en dataflödeskörning på det första felet som den får. Du kan välja Att fortsätta vid fel som gör att dataflödet kan slutföras även om enskilda rader har fel. Tjänsten innehåller olika alternativ för att hantera dessa felrader.
Transaktionsincheckning: Välj om dina data ska skrivas i en enda transaktion eller i batchar. En enskild transaktion ger bättre prestanda och inga skrivna data visas för andra förrän transaktionen har slutförts. Batch-transaktioner har sämre prestanda men kan fungera för stora datamängder.
Utdata avvisade data: Om aktiverad kan du mata ut felraderna till en csv-fil i Azure Blob Storage eller ett Azure Data Lake Storage Gen2-konto som du väljer. Då skrivs felraderna med tre ytterligare kolumner: SQL-åtgärden som INSERT eller UPDATE, dataflödesfelkoden och felmeddelandet på raden.
Rapportera lyckat fel: Om det är aktiverat markeras dataflödet som ett lyckat resultat även om felrader hittas.
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Egenskaper för GetMetadata-aktivitet
Mer information om egenskaperna finns i GetMetadata-aktivitet
Datatypsmappning för Azure Synapse Analytics
När du kopierar data från eller till Azure Synapse Analytics används följande mappningar från Azure Synapse Analytics-datatyper till mellanliggande datatyper i Azure Data Factory. Dessa mappningar används också vid kopiering av data från eller till Azure Synapse Analytics med hjälp av Synapse-pipelines, eftersom pipelines även implementerar Azure Data Factory i Azure Synapse. Se schema- och datatypmappningar för att lära dig hur Kopieringsaktivitet mappar källschemat och datatypen till mottagaren.
Dricks
Se artikeln Tabelldatatyper i Azure Synapse Analytics om datatyper som stöds av Azure Synapse Analytics och lösningarna för datatyper som inte stöds.
| Azure Synapse Analytics-datatyp | Data Factory interim datatyp |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Booleskt |
| char | Sträng, tecken[] |
| datum | Datum/tid |
| Datetime | Datum/tid |
| datetime2 | Datum/tid |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM-attribut (varbinary(max)) | Byte[] |
| Flyttal | Dubbel |
| bild | Byte[] |
| heltal | Int32 |
| money | Decimal |
| nchar | Sträng, tecken[] |
| numeric | Decimal |
| nvarchar | Sträng, tecken[] |
| real | Enstaka |
| rowversion | Byte[] |
| smalldatetime | Datum/tid |
| smallint | Int16 |
| smallmoney | Decimal |
| time | TimeSpan |
| tinyint | Byte |
| uniqueidentifier | GUID |
| varbinary | Byte[] |
| varchar | Sträng, tecken[] |
Uppgradera Azure Synapse Analytics-versionen
Om du vill uppgradera Azure Synapse Analytics-versionen går du till sidan Redigera länkad tjänst och väljer Rekommenderas under Version och konfigurerar den länkade tjänsten genom att referera till länkade tjänstegenskaper för den rekommenderade versionen.
Skillnader mellan den rekommenderade och den äldre versionen
Tabellen nedan visar skillnaderna mellan Azure Synapse Analytics med hjälp av den rekommenderade och äldre versionen.
| Rekommenderad version | Äldre version |
|---|---|
Stöd för TLS 1.3 via encrypt som strict. |
TLS 1.3 stöds inte. |
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare efter kopieringsaktivitet finns i datalager och format som stöds.