Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
AKS-övervakning kräver flera nivåer av observerbarhet mellan plattformsmått, Prometheus-mått, aktivitetsloggar, resursloggar och containerinsikter. AKS tillhandahåller inbyggda övervakningsfunktioner och integreras med Azure Monitor, Container Insights, hanterad tjänst för Prometheus och Azure Managed Grafana för omfattande klusterhälsa och prestandaövervakning.
Tips/Råd
Du kan använda Azure Copilot för att konfigurera övervakning på dina AKS-kluster i Azure-portalen. Mer information finns i Arbeta med AKS-kluster effektivt med Hjälp av Azure Copilot.
Insikter
Vissa tjänster i Azure har en inbyggd instrumentpanel för övervakning i Azure-portalen som är en startpunkt för övervakning av din tjänst. Dessa instrumentpaneler kallas insikter och du hittar dem i Insights Hub i Azure Monitor i Azure-portalen.
AKS-övervakningsdata: mått, loggar, integreringar
AKS genererar samma typer av övervakningsdata som andra Azure-resurser enligt beskrivningen i Övervaka data från Azure-resurser. Detaljerad information om mått och loggar som skapats av AKS finns i referensen för AKS-övervakningsdata.
Andra Azure-tjänster och funktioner samlar in andra data och aktiverar andra analysalternativ enligt följande diagram och tabell.

| Källa | Beskrivning |
|---|---|
| Plattformsstatistik | Plattformsmått samlas automatiskt in för AKS-kluster utan kostnad. Du kan analysera dessa mått med hjälp av metrics Explorer eller använda dem för att skapa måttaviseringar. |
| Prometheus mätvärden | När du aktiverar metriksamling för klustret samlar den hanterade tjänsten för Prometheus i Azure Monitor in Prometheus-mått och lagrar dem i en Azure Monitor-arbetsyta. Analysera dessa mått med hjälp av fördefinierade instrumentpaneler i Azure Managed Grafana och med Prometheus-aviseringar. |
| Aktivitetsloggar | Azure Monitor-aktivitetsloggen samlar automatiskt in vissa data för AKS-kluster utan kostnad. Dessa loggfiler spårar information som när ett kluster skapas eller ändringar görs i en klusterkonfiguration. Om du vill analysera aktivitetsloggdata med dina andra loggdata skickar du aktivitetsloggdata till en Log Analytics-arbetsyta. |
| Resursloggar | Kontrollplansloggar för AKS implementeras som resursloggar. Skapa en diagnostikinställning för att skicka loggarna till en Log Analytics-arbetsyta. På arbetsytan kan du analysera loggarna med hjälp av frågor och konfigurera aviseringar baserat på logginformation. |
| Containerinsikter | Containerinsikter samlar in olika loggar och prestandadata från ett kluster och lagrar dem på en Log Analytics-arbetsyta och i Azure Monitor-mått. Analysera data som stdout och stderr strömmar med hjälp av vyer och arbetsböcker i Container insights eller Log Analytics och metrics Explorer. |
| Programinsikter | Application Insights, en funktion i Azure Monitor, samlar in loggar, mått och distribuerade spårningar. Telemetrin lagras på en Log Analytics-arbetsyta för analys i Azure-portalen. Information om hur du aktiverar Application Insights med kodändringar finns i Aktivera Azure Monitor OpenTelemetry. Information om hur du aktiverar Application Insights utan kodändringar finns i Automatisk instrumentering av AKS. Mer information om instrumentation finns i grunderna för datainsamling. |
Resurstyper
Azure använder begreppet resurstyper och ID:t för att identifiera allt i en prenumeration. Resurstyper ingår också i resurs-ID:t för varje resurs som körs i Azure. En resurstyp för en virtuell dator är till exempel Microsoft.Compute/virtualMachines. En lista över tjänster och deras associerade resurstyper finns i Resursprovidrar.
Azure Monitor organiserar på liknande sätt kärnövervakningsdata i mått och loggar baserat på resurstyper, även kallade namnområden. Olika mått och loggar är tillgängliga för olika resurstyper. Tjänsten kan vara associerad med mer än en resurstyp.
Mer information om resurstyper i AKS finns i referensen för AKS-övervakningsdata.
Datalagring
För Azure Monitor:
- Måttdata lagras i Azure Monitor-måttdatabasen.
- Loggdata lagras i Azure Monitor-loggarkivet. Log Analytics är ett verktyg i Azure-portalen som kan ställa frågor till det här lagret.
- Azure-aktivitetsloggen är ett separat arkiv med ett eget gränssnitt i Azure-portalen.
Du kan också dirigera mått- och aktivitetsloggdata till Azure Monitor-loggarkivet. Du kan sedan använda Log Analytics för att fråga efter data och korrelera dem med andra loggdata.
Många tjänster kan använda diagnostikinställningar för att skicka mått- och loggdata till andra lagringsplatser utanför Azure Monitor. Exempel inkluderar Azure Storage, värdbaserade partnersystem och icke-Azure-partnersystem, som alla använder Event Hubs.
Detaljerad information om hur Azure Monitor lagrar data finns i Azure Monitor-dataplattformen.
Azure Monitor-plattformsmätvärden
Azure Monitor tillhandahåller plattformsmått för de flesta tjänster. Dessa mått är:
- Individuellt definierad för varje namnområde.
- Lagras i azure monitor-databasen för tidsseriemått.
- Lättviktig och kan stödja aviseringar i nästan realtid.
- Används för att spåra prestanda för en resurs över tid.
Samling: Azure Monitor samlar in plattformsmått automatiskt. Ingen konfiguration krävs.
Routning: Du kan också dirigera vissa plattformsmått till Azure Monitor-loggar/Log Analytics så att du kan köra frågor mot dem med andra loggdata. Kontrollera DS-exportinställningen för varje mått för att se om du kan använda en diagnostikinställning för att dirigera måttet till Azure Monitor-loggar/Log Analytics.
- För mer information, se diagnostikinställningen för mätvärden.
- Information om hur du konfigurerar diagnostikinställningar för en tjänst finns i Skapa diagnostikinställningar i Azure Monitor.
En lista över alla mått som du kan samla in för alla resurser i Azure Monitor finns i Mått som stöds i Azure Monitor.
En lista över mått som du kan samla in för AKS finns i referensen för AKS-övervakningsdata.
Mått spelar en viktig roll för att övervaka kluster, identifiera problem och optimera prestanda i AKS-kluster. Plattformsmått samlas in med hjälp av den förinstallerade måttservern som installerats i kube-system-namnområdet, vilken periodiskt hämtar mått från alla AKS-noder som hanteras av kubelet. Du bör också aktivera hanterad tjänst för Prometheus-mått för att samla in containermått och Kubernetes-objektmått, inklusive objektdistributionstillstånd.
Du kan visa listan över standardhanterade tjänster för Prometheus-mått.
För mer information, se Samla in hanterade tjänstemetiker för Prometheus från ett AKS-kluster.
Icke-Azure Monitor-baserade mått
Den här tjänsten tillhandahåller andra mått som inte ingår i Azure Monitor-måttdatabasen.
Du kan använda följande Azure-tjänster och Azure Monitor-funktioner för att övervaka dina AKS-kluster. Du aktiverar dessa funktioner när du skapar ett AKS-kluster.
I Azure-portalen använder du fliken Integreringar eller använder Azure CLI, Terraform eller Azure Policy. I vissa fall kan du registrera klustret till en övervakningstjänst eller funktion när du har skapat klustret. Varje tjänst eller funktion kan medföra kostnader, så se prisinformationen för varje komponent innan du aktiverar den.
| Tjänst eller funktion | Beskrivning |
|---|---|
| Containerinsikter | Använder en containerbaserad version av Azure Monitor-agenten för att samla in stdout och stderr loggar och Kubernetes-händelser från varje nod i klustret. Funktionen stöder en mängd olika övervakningsscenarier för AKS-kluster. Du kan aktivera övervakning för ett AKS-kluster när det skapas med hjälp av Azure CLI, Azure Policy, Azure Portal eller Terraform. Om du inte aktiverar containerinsikter när du skapar klustret kan du läsa Aktivera containerinsikter för AKS-kluster för andra alternativ för att aktivera det.Container insights lagrar de flesta av sina data på en Log Analytics-arbetsyta. Du använder vanligtvis samma Log Analytics-arbetsyta som resursloggarna för klustret. Information om hur många arbetsytor du bör använda och var du hittar dem finns i Designa en Log Analytics-arbetsytearkitektur. |
| Hanterad tjänst för Prometheus i Azure Monitor |
Prometheus är en molnbaserad måttlösning från Cloud Native Computing Foundation. Det är det vanligaste verktyget att använda för att samla in och analysera måttdata från Kubernetes-kluster. Den hanterade tjänsten för Prometheus i Azure Monitor är en fullständigt hanterad Prometheus-kompatibel övervakningslösning. Om du inte aktiverar den hanterade tjänsten för Prometheus när du skapar klustret kan du läsa Samla in Prometheus-mått från ett AKS-kluster för andra alternativ för att aktivera det. Den hanterade tjänsten för Prometheus i Azure Monitor lagrar sina data på en Azure Monitor-arbetsyta som är länkad till en Grafana-arbetsyta. Du kan använda Azure Managed Grafana för att analysera data. |
| Azure Managed Grafana | En fullständigt hanterad implementering av Grafana. Grafana är en plattform för datavisualisering med öppen källkod som ofta används för att presentera Prometheus-data. Flera fördefinierade Grafana-instrumentpaneler är tillgängliga för övervakning av Kubernetes och fullständig stack-felsökning. Om du inte aktiverar Azure Managed Grafana när du skapar klustret läser du Länka en Grafana-arbetsyta. Du kan länka den till din Azure Monitor-arbetsyta så att den kan komma åt Prometheus-mått från klustret. |
Övervakning av AKS-kontrollplansmått (förhandsversion)
Krav och omfång: Den här förhandsgranskningsfunktionen är tillgänglig för AKS-kluster som kör Kubernetes 1.27 eller senare och kräver att den hanterade tjänsten för Prometheus aktiveras i klustret. Funktionen stöder för närvarande Linux- och Windows-nodpooler men är inte kompatibel med VMAS (Virtual Machine Availability Sets).
AKS exponerar även mått från kritiska kontrollplanskomponenter som API-servern osv. och schemaläggaren via den hanterade tjänsten för Prometheus i Azure Monitor. För närvarande är den här funktionen i förhandsversion. Mer information finns i Övervaka AKS-kontrollplansmått. En delmängd kontrollplansmått för API-servern och etcd är tillgängliga kostnadsfritt via Azure Monitor-plattformsmått. Dessa mått samlas in som standard. Du kan använda måtten för att skapa aviseringar.
Azure Monitor-resursloggar
Resursloggar ger insikter om åtgärder som har utförts av en Azure-resurs. Loggar genereras automatiskt, men du måste dirigera dem till Azure Monitor-loggar för att spara eller köra frågor mot dem. Loggar ordnas i kategorier. Ett givet namnområde kan ha flera resursloggkategorier.
Samling: Resursloggar samlas inte in och lagras förrän du skapar en diagnostikinställning och dirigerar loggarna till en eller flera platser. När du skapar en diagnostikinställning anger du vilka kategorier av loggar som ska samlas in. Det finns flera sätt att skapa och underhålla diagnostikinställningar, inklusive Azure-portalen, programmatiskt och via Azure Policy.
Routning: Det föreslagna standardvärdet är att dirigera resursloggar till Azure Monitor-loggar så att du kan köra frågor mot dem med andra loggdata. Andra platser som Azure Storage, Azure Event Hubs och vissa Microsoft-övervakningspartner är också tillgängliga. Mer information finns i Azure-resursloggar och Resursloggmål.
Detaljerad information om hur du samlar in, lagrar och dirigerar resursloggar finns i Diagnostikinställningar i Azure Monitor.
En lista över alla tillgängliga resursloggkategorier i Azure Monitor finns i Resursloggar som stöds i Azure Monitor.
Alla resursloggar i Azure Monitor har samma rubrikfält följt av tjänstspecifika fält. Det vanliga schemat beskrivs i Azure Monitor-resursloggschemat.
De tillgängliga resursloggkategorierna, deras associerade Log Analytics-tabeller och loggscheman för AKS finns i referensen för AKS-övervakningsdata.
Resursloggar för AKS-kontrollplan
Krav: Kräver en Log Analytics-arbetsyta i samma prenumeration som ditt AKS-kluster. Resursloggar medför inmatnings- och kvarhållningskostnader i destinationsarbetsytan. För kostnadsoptimering använder du resursspecifikt läge och konfigurerar nivån Grundläggande loggar för granskningstabeller.
Kontrollplansloggar för AKS-kluster implementeras som resursloggar i Azure Monitor. Resursloggar samlas inte in och lagras förrän du skapar en diagnostikinställning för att dirigera dem till minst en plats. Du skickar vanligtvis resursloggar till en Log Analytics-arbetsyta, där de flesta data för Container Insights lagras.
Information om hur du skapar en diagnostikinställning med hjälp av Azure-portalen, Azure CLI eller Azure PowerShell finns i Skapa diagnostikinställningar. När du skapar en diagnostikinställning anger du vilka kategorier av loggar som ska samlas in. Kategorierna för AKS visas i aks-övervakningsdatareferensen.
Varning
Du kan få stora kostnader när du samlar in resursloggar för AKS, särskilt för kube-audit-loggar. Överväg följande rekommendationer för att minska mängden data som samlas in:
- Inaktivera
kube-auditloggning när det inte behövs. - Aktivera samling från
kube-audit-admin, vilket exkluderar granskningshändelsernagetochlist. - Aktivera resursspecifika loggar enligt beskrivningen i den här artikeln och konfigurera AKSAudit-tabellen som Grundläggande loggar.
Fler övervakningsrekommendationer finns i Övervaka AKS-kluster med hjälp av Azure-tjänster och molnbaserade verktyg. Strategier för att minska dina övervakningskostnader finns i Kostnadsoptimering och Azure Monitor.
AKS stöder antingen Azure-diagnostikläge eller resursspecifikt läge för resursloggar. Azure-diagnostikläget skickar alla data till AzureDiagnostics-tabellen. Resursspecifikt läge anger tabellerna på Log Analytics-arbetsytan där data skickas. Den skickar också data till AKSAudit, AKSAuditAdminoch AKSControlPlane som visas i tabellen i Resursloggar.
Vi rekommenderar att du använder resursspecifikt läge för AKS av följande skäl:
- Data är lättare att fråga eftersom de finns i enskilda tabeller som är dedikerade till AKS.
- Resursspecifikt läge stöder konfiguration som Grundläggande loggar för betydande kostnadsbesparingar.
Mer information om skillnaden mellan samlingslägen, inklusive hur du ändrar en befintlig inställning, finns i Välj samlingsläge.
Anmärkning
Du kan konfigurera diagnostikinställningar med hjälp av Azure CLI. Den här metoden är inte garanterad att lyckas eftersom den inte söker efter klustrets etableringstillstånd. När du har ändrat diagnostikinställningarna kontrollerar du att klustret återspeglar inställningens ändringar.
az monitor diagnostic-settings create --name AKS-Diagnostics --resource /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/myresourcegroup/providers/Microsoft.ContainerService/managedClusters/my-cluster --logs '[{"category": "kube-audit","enabled": true}, {"category": "kube-audit-admin", "enabled": true}, {"category": "kube-apiserver", "enabled": true}, {"category": "kube-controller-manager", "enabled": true}, {"category": "kube-scheduler", "enabled": true}, {"category": "cluster-autoscaler", "enabled": true}, {"category": "cloud-controller-manager", "enabled": true}, {"category": "guard", "enabled": true}, {"category": "csi-azuredisk-controller", "enabled": true}, {"category": "csi-azurefile-controller", "enabled": true}, {"category": "csi-snapshot-controller", "enabled": true}]' --workspace /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/myresourcegroup/providers/microsoft.operationalinsights/workspaces/myworkspace --export-to-resource-specific true
Förfrågningar och exempel för AKS-resursloggar
Krav på frågeomfång: När du väljer Loggar på en AKS-klustermeny öppnas Log Analytics med frågeomfånget inställt på det aktuella klustret. Loggfrågor inkluderar endast data från den resursen. Om du vill köra frågor som innehåller data från andra kluster eller Azure-tjänster väljer du Loggar på Azure Monitor-menyn .
Om diagnostikinställningarna för klustret använder Azure-diagnostikläge lagras resursloggarna för AKS i tabellen AzureDiagnostics . Identifiera loggar via kolumnen Kategori . En beskrivning av varje kategori finns i AKS-referensresursloggar.
| Beskrivning | Mode | Loggfråga |
|---|---|---|
| Antal loggar för varje kategori | Azure-diagnostikläge | AzureDiagnostics| where ResourceType == "MANAGEDCLUSTERS"| summarize count() by Category |
| Alla API-serverloggar | Azure-diagnostikläge | AzureDiagnostics| where Category == "kube-apiserver" |
| Alla kube-audit-loggar inom ett tidsintervall | Azure-diagnostikläge | let starttime = datetime("2023-02-23");let endtime = datetime("2023-02-24");AzureDiagnostics| where TimeGenerated between(starttime..endtime)| where Category == "kube-audit"| extend event = parse_json(log_s)| extend HttpMethod = tostring(event.verb)| extend User = tostring(event.user.username)| extend Apiserver = pod_s| extend SourceIP = tostring(event.sourceIPs[0])| project TimeGenerated, Category, HttpMethod, User, Apiserver, SourceIP, OperationName, event |
| Alla granskningsloggar | Resursspecifikt läge | AKSAudit |
Alla granskningsloggar exklusive get och list granskningshändelser |
Resursspecifikt läge | AKSAuditAdmin |
| Alla API-serverloggar | Resursspecifikt läge | AKSControlPlane| where Category == "kube-apiserver" |
Om du vill komma åt en uppsättning fördefinierade frågor på Log Analytics-arbetsytan läser du log analytics-frågegränssnittet och väljer resurstypen Kubernetes Services . En lista över vanliga frågor för Container Insights finns i Container Insights-frågor.
AKS-granskningsprincip
AKS använder en Kubernetes-granskningsprincip för att styra vilka händelser som loggas och vilka data de innehåller. Principen definierar regler som fastställer granskningsnivån för olika typer av API-begäranden baserat på användare, resurser, namnområden och verb. Följande granskningsnivåer används:
- Ingen: Händelser som matchar den här regeln loggas inte.
- Metadata: Metadata för loggbegäran (begär användare, tidsstämpel, resurs, verb) men inte begärande- eller svarstext.
- Begäran: Logga händelsemetadata och begärandetext men inte svarstext.
- RequestResponse: Logga händelsemetadata, begärande- och svarsorgan.
I följande tabell sammanfattas de viktiga granskningsprincipregler som tillämpas i AKS:
| Granskningsnivå | Beskrivning | Exempelhändelser |
|---|---|---|
| Ingen | Läsåtgärder med hög volym och låg risk |
aksServiceanvändaråtgärderget/list, kube-proxy övervaka slutpunkter/tjänster, kubelet get på noder/nodstatus, hälsokontroll-URL:er (/healthz*, /version, /swagger*) |
| Metadata | Systemhändelser, händelseresurser (förutom skapar/uppdaterar i default/kube-system), hemligheter, konfigurationskartor, tjänstkonton, tokengranskningar |
Tokengranskningar, åtkomst till hemlighet/konfigurationsmapp, stora CRD:ar som installations.operator.tigera.io |
| Förfrågan | Nod- och poddstatusuppdateringar från kubelets/noder, ta bort insamlingsåtgärder, CRD-uppdateringar för volymögonblicksbilder, läsåtgärder (get/list/watch) i kärn-API-grupper, VPA-ändringar |
Kubelet-statusuppdateringar, namnområdesborttagningar, uppdateringar av VPA-kontrollpunkter |
| RequestResponse | CoreDNS anpassade konfigurationsmappsuppdateringar, Fleet API-åtgärder, Karpenter-resursändringar, alla andra skrivåtgärder i kärn-API-grupper | CoreDNS-konfigurationsändringar, klusteråtgärder för medlemmar i flottan, ändringar i Karpenter-nodpoolen |
Den fullständiga granskningsprincipen som används i AKS är tillgänglig för granskning i följande komprimerbara avsnitt.
Visa den fullständiga AKS-granskningsprincipen
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
# audit level 'None' for high volume and low risk events
- level: None
users: ["aksService"]
verbs: ["get", "list"]
# audit level 'None' for low-risk requests
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: ""
resources: ["endpoints", "services", "services/status"]
# audit level 'None' for low-risk requests
- level: None
users: ["kubelet"] # legacy kubelet identity
verbs: ["get"]
resources:
- group: ""
resources: ["nodes", "nodes/status"]
# audit level 'None' for low-risk requests
- level: None
userGroups: ["system:nodes"]
verbs: ["get"]
resources:
- group: ""
resources: ["nodes", "nodes/status"]
# audit level 'None' for low-risk requests
- level: None
users:
- aksService # the default user/cert used by aks in master node
- system:serviceaccount:kube-system:endpoint-controller
verbs: ["get", "update"]
namespaces: ["kube-system"]
resources:
- group: ""
resources: ["endpoints"]
# audit level 'None' for low-risk requests
- level: None
users: ["system:apiserver"]
verbs: ["get"]
resources:
- group: ""
resources: ["namespaces", "namespaces/status", "namespaces/finalize"]
# audit level 'None' for low-risk requests
- level: None
users:
- aksService # the default user/cert used by aks in master node
verbs: ["get", "list"]
resources:
- group: "metrics.k8s.io"
# Don't log these read-only URLs.
- level: None
nonResourceURLs:
- /healthz*
- /version
- /swagger*
# monitor metadata for system events which are being logged by eventlogger component
- level: Metadata
verbs: ["create", "update", "patch"]
resources:
- group: ""
resources: ["events"]
- group: "events.k8s.io"
resources: ["events"]
namespaces: ["default", "kube-system"]
# Monitoring of actions to detect security/performance relevant activities.
- level: Metadata
verbs: ["delete", "list"]
resources:
- group: ""
resources: ["events"]
- group: "events.k8s.io"
resources: ["events"]
# Don't log other events requests.
- level: None
resources:
- group: ""
resources: ["events"]
- group: "events.k8s.io"
resources: ["events"]
# node and pod status calls from nodes are high-volume and can be large, don't log responses for expected updates from nodes
- level: Request
users: ["client", "kubelet", "system:node-problem-detector", "system:serviceaccount:kube-system:node-problem-detector", "system:serviceaccount:kube-system:aci-connector-linux"]
verbs: ["update","patch"]
resources:
- group: ""
resources: ["nodes/status", "pods/status"]
omitStages:
- "RequestReceived"
# node and pod status calls from nodes are high-volume and can be large, don't log responses for expected updates from nodes
- level: Request
userGroups: ["system:nodes"]
verbs: ["update","patch"]
resources:
- group: ""
resources: ["nodes/status", "pods/status"]
omitStages:
- "RequestReceived"
# deletecollection calls can be large, don't log responses for expected namespace deletions
- level: Request
users: ["system:serviceaccount:kube-system:namespace-controller"]
verbs: ["deletecollection"]
omitStages:
- "RequestReceived"
# ignore response object that has big size
- level: Request
verbs: ["update","patch"]
resources:
- group: "apiextensions.k8s.io"
resources: ["customresourcedefinitions"]
resourceNames: ["volumesnapshotcontents.snapshot.storage.k8s.io", "volumesnapshots.snapshot.storage.k8s.io"]
omitStages:
- "RequestReceived"
# ignore request and response objects for large CRDs that will be filtered down anyway
- level: Metadata
resources:
- group: "apiextensions.k8s.io"
resources: ["customresourcedefinitions"]
resourceNames: ["installations.operator.tigera.io"]
omitStages:
- "RequestReceived"
# overriding the default behavior of coredns might have security threats for Kubernetes DNS in security perspective, set the level as RequestResponse
- level: RequestResponse
verbs: ["update","patch"]
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["coredns-custom"]
namespaces: ["kube-system"]
omitStages:
- "RequestReceived"
# Secrets, ConfigMaps, ServiceAccounts, TokenRequest and TokenReviews can contain sensitive & binary data,
# so only log at the Metadata level.
- level: Metadata
resources:
- group: ""
resources: ["secrets", "configmaps", "serviceaccounts", "serviceaccounts/token"]
- group: authentication.k8s.io
resources: ["tokenreviews"]
omitStages:
- "RequestReceived"
# Capture state of vertical pod autoscalers
- level: Request
verbs: ["create", "update", "patch", "delete"]
resources:
- group: "autoscaling.k8s.io"
resources: ["verticalpodautoscalers", "verticalpodautoscalercheckpoints"]
omitStages:
- "RequestReceived"
# Capture create and delete of internal fleet resources
- level: RequestResponse
verbs: ["create", "delete"]
resources:
- group: "cluster.kubernetes-fleet.io"
resources: ["memberclusters", "internalmemberclusters"]
- group: "placement.kubernetes-fleet.io"
resources: ["works"]
- group: "networking.fleet.azure.com"
resources: ["internalserviceexports", "internalserviceimports"]
omitStages:
- "RequestReceived"
# Capture CUD of user facing Fleet API
- level: RequestResponse
verbs: ["create", "update", "patch", "delete"]
resources:
- group: "placement.kubernetes-fleet.io"
resources: ["clusterstagedupdateruns", "clusterresourceplacements", "clusterresourceplacementevictions", "clusterresourceplacementdisruptionbudgets", "clusterstagedupdatestrategies", "clusterapprovalrequests", "clusterresourceoverrides", "resourceoverrides"]
- group: "networking.fleet.azure.com"
resources: ["serviceexports", "multiclusterservices", "trafficmanagerprofiles", "trafficmanagerbackends"]
omitStages:
- "RequestReceived"
# Capture CUD of user facing Karpenter resources
- level: RequestResponse
verbs: ["create", "update", "patch", "delete"]
resources:
- group: "karpenter.azure.com"
resources: ["aksnodeclasses", "aksnodeclasses/status"]
- group: "karpenter.sh"
resources: ["nodepools", "nodepools/status", "nodeclaims", "nodeclaims/status"]
omitStages:
- "RequestReceived"
# Get responses can be large; don't log response
- level: Request
verbs: ["get", "list", "watch"]
resources:
- group: ""
- group: "admissionregistration.k8s.io"
- group: "apiextensions.k8s.io"
- group: "apiregistration.k8s.io"
- group: "apps"
- group: "authentication.k8s.io"
- group: "authorization.k8s.io"
- group: "autoscaling"
- group: "batch"
- group: "certificates.k8s.io"
- group: "extensions"
- group: "metrics.k8s.io"
- group: "networking.k8s.io"
- group: "policy"
- group: "rbac.authorization.k8s.io"
- group: "scheduling.k8s.io"
- group: "settings.k8s.io"
- group: "storage.k8s.io"
omitStages:
- "RequestReceived"
# Default level for known APIs
- level: RequestResponse
resources:
- group: ""
- group: "admissionregistration.k8s.io"
- group: "apiextensions.k8s.io"
- group: "apiregistration.k8s.io"
- group: "apps"
- group: "authentication.k8s.io"
- group: "authorization.k8s.io"
- group: "autoscaling"
- group: "batch"
- group: "certificates.k8s.io"
- group: "extensions"
- group: "metrics.k8s.io"
- group: "networking.k8s.io"
- group: "policy"
- group: "rbac.authorization.k8s.io"
- group: "scheduling.k8s.io"
- group: "settings.k8s.io"
- group: "storage.k8s.io"
omitStages:
- "RequestReceived"
# Default level for all other requests.
- level: Metadata
omitStages:
- "RequestReceived"
Anmärkning
Granskningsprincipen hanteras av AKS och kan inte anpassas. Principen är utformad för att balansera säkerhetsobservabilitet med prestanda- och kostnadsoptimering genom att minska loggvolymen för högfrekventa åtgärder med låg risk.
AKS dataplan loggar för Container insights
Krav och konfigurationskrav: Containerinsikter kräver en Log Analytics-arbetsyta för logglagring och stöder både hanterade identiteter och äldre autentiseringsmetoder. För nya kluster rekommenderas hanterad identitetsautentisering. Datainsamling kan anpassas med hjälp av Azure Monitor Data Collection Rules (DCR) för att kontrollera kostnader och minska inmatningsvolymen.
Containerinsikter samlar in olika typer av telemetridata från containrar och AKS-kluster som hjälper dig att övervaka, felsöka och få insikter om dina containerbaserade program som körs i dina AKS-kluster. En lista över tabeller och deras detaljerade beskrivningar som används av Container Insights finns i tabellreferensen för Azure Monitor. Alla tabeller är tillgängliga för loggfrågor.
Använd inställningarna för kostnadsoptimering för att anpassa och kontrollera de måttdata som samlas in via Container Insights-agenten. Den här funktionen stöder datainsamlingsinställningarna för enskilda tabellval, datainsamlingsintervall och namnområden för att undanta datainsamlingen via Azure Monitor Data Collection Rules (DCR). De här inställningarna styr inmatningsvolymen och minskar övervakningskostnaderna för Container Insights. Du kan anpassa data som samlas in av Container insights i Azure-portalen med hjälp av följande alternativ. Om du väljer andra alternativ än Alla (standard) blir containerinsikterna otillgängliga.
| Gruppering | Tabeller | Noteringar |
|---|---|---|
| Alla (standardinställning) | Alla standardtabeller för Container Insights | Krävs för att aktivera standardvisualiseringar för Container Insights. |
| Performance | Perf, InsightsMetrics | N/A |
| Loggar och händelser | ContainerLog eller ContainerLogV2, KubeEvents, KubePodInventory | Rekommenderas om du har aktiverat hanterad tjänst för Prometheus-mått. |
| Arbetsbelastningar, distributioner och HPA:er | InsiktsMetrik, KubePodInventering, KubeHändelser, ContainerInventering, ContainerNodInventering, KubeNodInventering, KubeTjänster | N/A |
| Beständiga volymer | InsightsMetrics, KubePVInventory | N/A |
Gruppering av loggar och händelser samlar in loggarna från tabellerna ContainerLog eller ContainerLogV2, KubeEvents och KubePodInventory , men inte måtten. Den rekommenderade sökvägen för att samla in mått är att aktivera den hanterade tjänsten för Prometheus från ditt AKS-kluster och använda Azure Managed Grafana för datavisualisering. Mer information finns i Övervaka en Azure Monitor-arbetsyta.
ContainerLogV2-schema
Kompatibilitets- och konfigurationskrav: ContainerLogV2-schema rekommenderas för nya Container Insights-distributioner med hjälp av hanterad identitetsautentisering via ARM-mallar (Azure Resource Manager), Bicep, Terraform, Azure Policy eller Azure-portalen. Schemat är kompatibelt med Basic-loggnivån för kostnadsbesparingar och påverkar inte analys- eller aviseringsfunktioner. Mer information om hur du aktiverar ContainerLogV2 via antingen klustrets DCR eller konfigurationskarta finns i Aktivera ContainerLogV2-schemat.
Containerinsikter i Azure Monitor innehåller ett rekommenderat schema för containerloggar, ContainerLogV2. Formatet innehåller följande fält för vanliga frågor för att visa data relaterade till AKS- och Azure Arc-aktiverade Kubernetes-kluster:
- ContainerName
- PodName
- PodNamespace
Azure-aktivitetslogg
Aktivitetsloggen innehåller händelser på prenumerationsnivå som spårar åtgärder för varje Azure-resurs som visas utanför resursen. till exempel att skapa en ny resurs eller starta en virtuell dator.
Samling: Aktivitetslogghändelser genereras automatiskt och samlas in i ett separat arkiv för visning i Azure Portal.
Routning: Du kan skicka aktivitetsloggdata till Azure Monitor-loggar så att du kan analysera dem tillsammans med andra loggdata. Andra platser som Azure Storage, Azure Event Hubs och vissa Microsoft-övervakningspartner är också tillgängliga. Mer information om hur du dirigerar aktivitetsloggen finns i Översikt över Azure-aktivitetsloggen.
Visa AKS-containerloggar, händelser och poddmått i realtid
Krav och konfigurationskrav: Live-datafunktionen kräver att Containerinsikter aktiveras i klustret och använder direkt Åtkomst till Kubernetes API. För privata kluster kräver åtkomst en dator i samma privata nätverk som klustret. Autentisering följer Kubernetes RBAC-modellen och kräver lämpliga klusterbehörigheter.
Du kan visa AKS-containerloggar, händelser och poddmått med hjälp av livedatafunktionen i Container Insights och felsöka problem i realtid med direkt åtkomst till kubectl logs -c, kubectl get händelser och kubectl top pods.
Anmärkning
AKS använder loggningsarkitekturer på Kubernetes-klusternivå. Containerloggarna finns på /var/log/containers noden. Information om hur du kommer åt en nod finns i Ansluta till AKS-klusternoder.
Information om hur du konfigurerar den här funktionen finns i Konfigurera livedata i Container Insights. Funktionen har direkt åtkomst till Kubernetes-API:et. Mer information om autentiseringsmodellen finns i Kubernetes API.
Visa AKTIVA AKS-resursloggar
Krav för privata klusternätverk: Om du vill komma åt loggar från ett privat kluster måste du använda en dator som finns i samma privata nätverk som klustret.
I Azure-portalen går du till ditt AKS-kluster.
Under Kubernetes-resurser väljer du Arbetsbelastningar.
För Distribution, Podd, Replikuppsättning, Tillståndskänslig uppsättning, Jobb eller Cron-jobb väljer du ett värde och väljer sedan Live-loggar.
Välj en resurslogg att visa.
I följande exempel visas loggarna för en poddresurs:
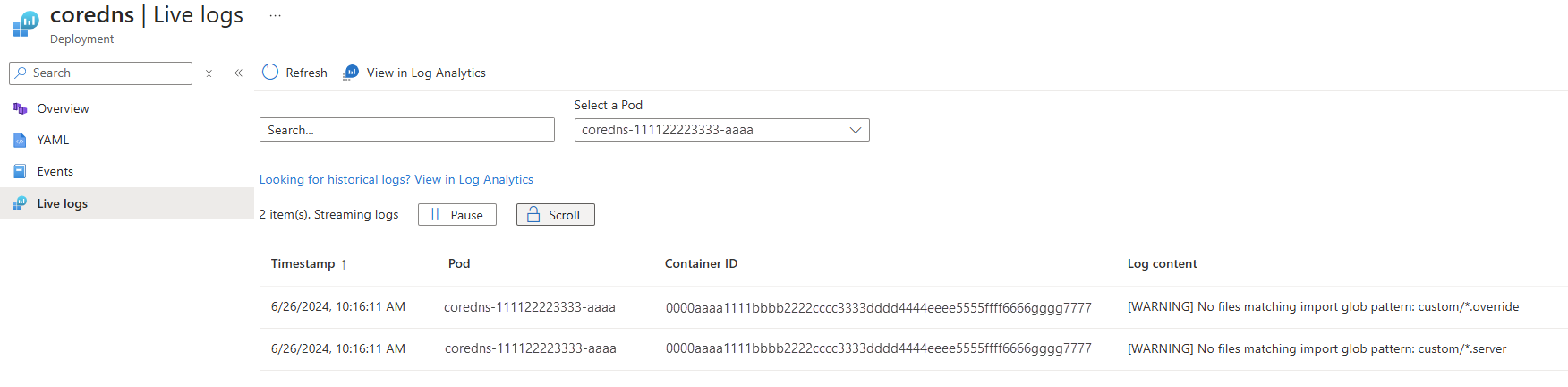

Visa liveloggar för containrar med containerinsikter
Autentisering och dataströmning: Om data kan hämtas efter lyckad autentisering börjar de strömmas till fliken Liveloggar . Loggdata visas i en kontinuerlig ström. Alternativ loggåtkomst är tillgänglig via Visa loggar i Log Analytics för historisk analys.
Du kan visa loggdata i realtid när containermotorn genererar dem på fliken Kluster, Noder, Styrenheter eller Containrar .
I Azure-portalen går du till ditt AKS-kluster.
Under Övervakning väljer du Insikter.
På fliken Kluster, Noder, Kontrollanter eller Containrar väljer du ett värde.
I fönstret Översikt för resursen väljer du LiveLoggar.
Följande bild visar loggarna för en containerresurs:
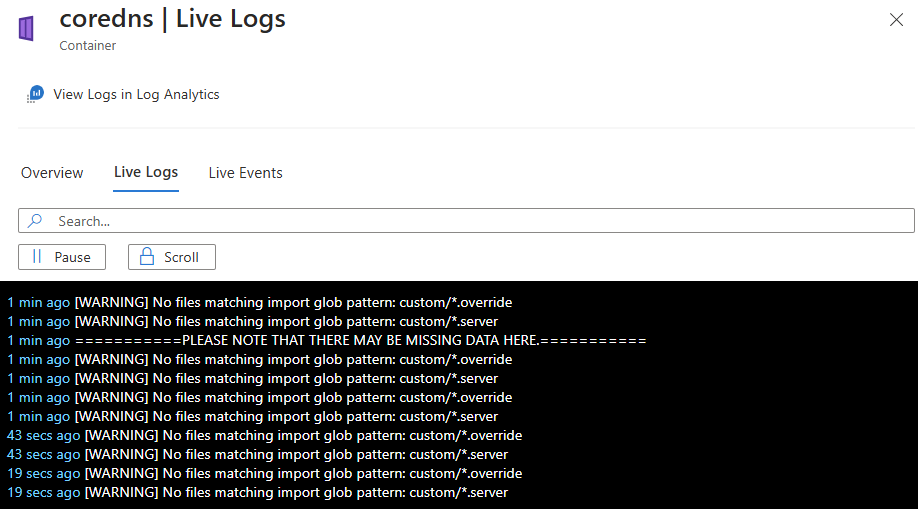

Visa container-livehändelser med containerinsikter
Händelseströmning och åtkomst: Händelsedataströmmar i realtid när containermotorn genererar den. Händelser omfattar skapande av poddar, borttagning, skalningsåtgärder och felmeddelanden. Historiska händelsedata är tillgängliga via Visa händelser i Log Analytics.
Du kan visa händelsedata i realtid när containermotorn genererar dem på fliken Kluster, Noder, Styrenheter eller Containrar .
I Azure-portalen går du till ditt AKS-kluster.
Under Övervakning väljer du Insikter.
Välj fliken Kluster, Noder, Kontrollanter eller Containrar och välj sedan ett objekt.
I fönstret Resursöversikt väljer du Livehändelser.
Om data kan hämtas efter lyckad autentisering börjar de strömmas till fliken Livehändelser . Följande bild visar händelserna för en containerresurs:
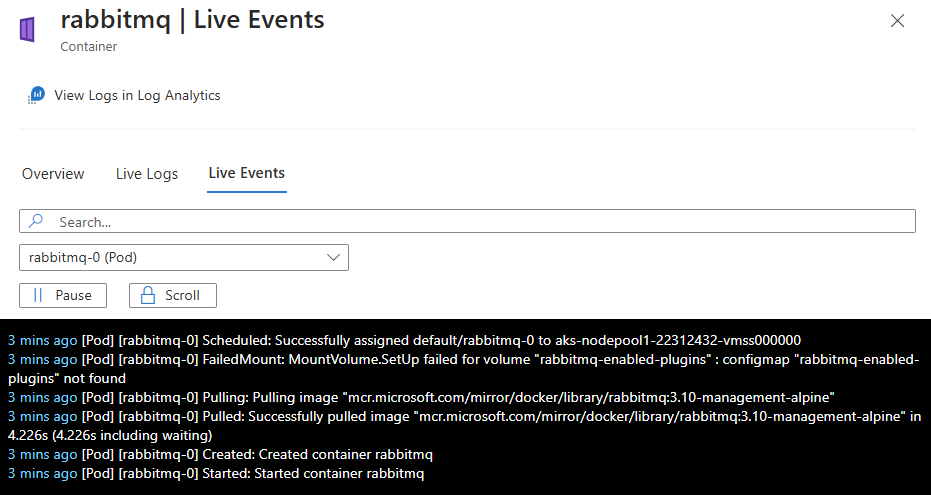

Visa live-mätvärden för pods med Container Insights
Måttomfång och tillgänglighet: Live-mått är tillgängliga för poddresurser på flikarna Noder eller Kontrollanter . Måtten omfattar CPU-användning, minnesförbrukning, nätverks-I/O och filsystemstatistik. Historiska mått är tillgängliga via Visa händelser i Log Analytics.
Du kan visa måttdata i realtid när containermotorn genererar dem på fliken Noder eller Kontrollanter genom att välja en poddresurs.
I Azure-portalen går du till ditt AKS-kluster.
Under Övervakning väljer du Insikter.
Välj fliken Noder eller kontrollanter och välj sedan ett poddobjekt.
I panelen Resursöversikt väljer du Live-mätvärden.
Om data kan hämtas efter lyckad autentisering börjar de strömmas till fliken Live Metrics . Följande bild visar måtten för en poddresurs:
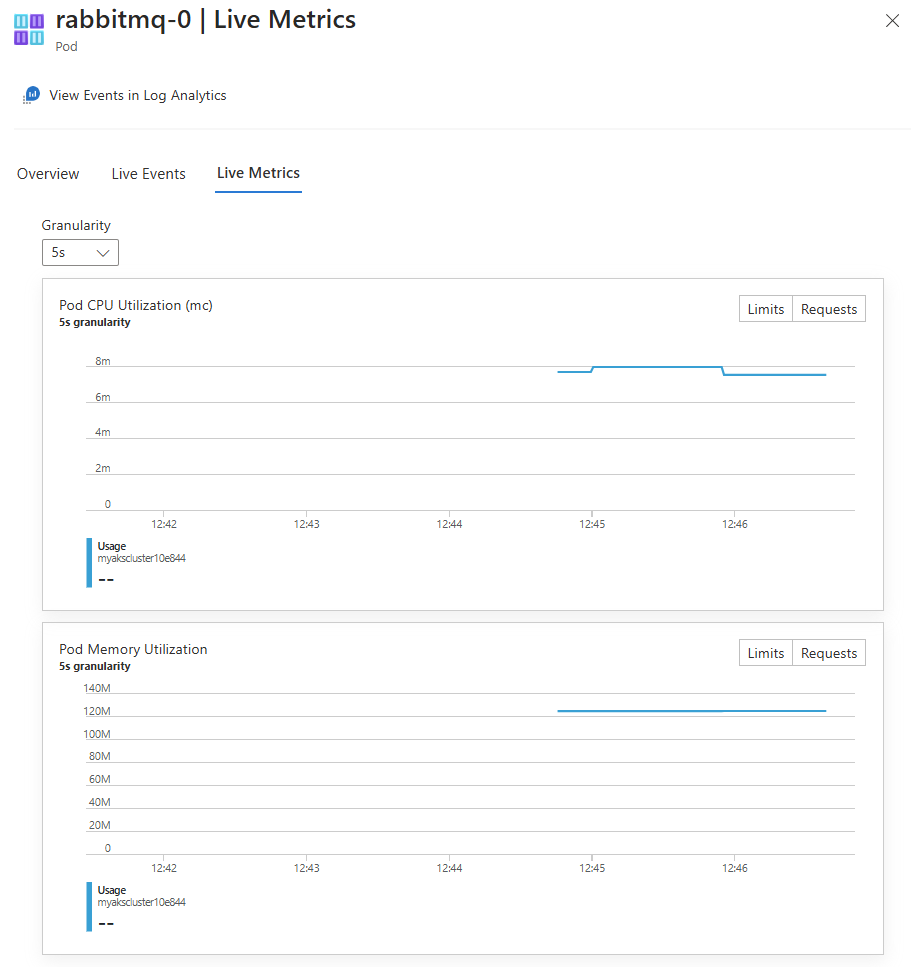
Analysera övervakningsdata
Det finns många verktyg för att analysera övervakningsdata.
Azure Monitor-verktyg
Azure Monitor har stöd för följande grundläggande verktyg:
Metrics Explorer, ett verktyg i Azure Portal som gör att du kan visa och analysera mått för Azure-resurser. Mer information finns i Analysera mått med Azure Monitor Metrics Explorer.
Log Analytics, ett verktyg i Azure-portalen som gör att du kan köra frågor mot och analysera loggdata med hjälp av KQL (Kusto Query Language). Mer information finns i Kom igång med loggfrågor i Azure Monitor.
Aktivitetsloggen, som har ett användargränssnitt i Azure Portal för visning och grundläggande sökningar. Om du vill göra mer djupgående analys måste du dirigera data till Azure Monitor-loggar och köra mer komplexa frågor i Log Analytics.
Verktyg som möjliggör mer komplex visualisering är:
- Instrumentpaneler som gör att du kan kombinera olika typer av data i ett enda fönster i Azure-portalen.
- Arbetsböcker, anpassningsbara rapporter som du kan skapa i Azure-portalen. Arbetsböcker kan innehålla text-, mått- och loggfrågor.
- Grafana, ett öppet plattformsverktyg som utmärker sig i operativa instrumentpaneler. Du kan använda Grafana för att skapa instrumentpaneler som innehåller data från flera andra källor än Azure Monitor.
- Power BI, en tjänst för affärsanalys som tillhandahåller interaktiva visualiseringar mellan olika datakällor. Du kan konfigurera Power BI för att automatiskt importera loggdata från Azure Monitor för att dra nytta av dessa visualiseringar.
Exportverktyg för Azure Monitor
Du kan hämta data från Azure Monitor till andra verktyg med hjälp av följande metoder:
Mått: Använd REST-API:et för mätdata för att extrahera mätdata från måttdatabasen i Azure Monitor. API:et stöder filteruttryck för att förfina de data som hämtas. Mer information finns i Azure Monitor REST API-referens.
Loggar: Använd REST-API:et eller de associerade klientbiblioteken.
Ett annat alternativ är exporten av arbetsytedata.
Information om hur du kommer igång med REST-API:et för Azure Monitor finns i Genomgång av REST API för Azure-övervakning.

Övervaka AKS-kluster i Azure-portalen
Fliken Övervakning i fönstret Översikt för aks-klusterresursen är ett snabbt sätt att börja visa övervakningsdata i Azure-portalen. Den här fliken innehåller diagram med vanliga mått för klustret avgränsat med nodpool. Du kan välja någon av dessa diagram för att ytterligare analysera data i måttutforskaren.
Fliken Övervakning innehåller även länkar till den Azure-hanterade tjänsten för Prometheus och Container insights för klustret. Du kan aktivera dessa verktyg på fliken Övervakning . Du kan också se en banderoll överst i fönstret som rekommenderar andra funktioner för att förbättra övervakningen för klustret.
Tips/Råd
Om du vill komma åt övervakningsfunktioner för alla AKS-kluster i din prenumeration går du till startsidan för Azure-portalen och väljer Azure Monitor.
Kusto-frågor
Du kan analysera övervakningsdata i Azure Monitor-loggar/Log Analytics-arkivet med hjälp av Kusto-frågespråket (KQL).
Viktigt!
När du väljer Loggar på tjänstens meny i portalen öppnas Log Analytics med frågeomfånget inställt på den aktuella tjänsten. Det här omfånget innebär att loggfrågor endast innehåller data från den typen av resurs. Om du vill köra en fråga som innehåller data från andra Azure-tjänster väljer du Loggar på Azure Monitor-menyn . Mer information finns i Log query scope and time range in Azure Monitor Log Analytics (Loggfrågeomfång och tidsintervall i Azure Monitor Log Analytics ).
En lista över vanliga frågor för alla tjänster finns i Log Analytics-frågegränssnittet.
Aviseringar
Azure Monitor-aviseringar meddelar dig proaktivt när specifika villkor finns i dina övervakningsdata. Med aviseringar kan du identifiera och åtgärda problem i systemet innan kunderna märker dem. Mer information finns i Azure Monitor-aviseringar.
Det finns många källor till vanliga aviseringar för Azure-resurser. Exempel på vanliga aviseringar för Azure-resurser finns i Exempelloggaviseringsfrågor. Webbplatsen Azure Monitor Baseline Alerts (AMBA) innehåller en halvautomatiserad metod för att implementera viktiga plattformsmåttaviseringar, instrumentpaneler och riktlinjer. Webbplatsen gäller för en kontinuerligt expanderande delmängd av Azure-tjänster, inklusive alla tjänster som ingår i Azure Landing Zone (ALZ).
Det gemensamma aviseringsschemat standardiserar förbrukningen av Azure Monitor-aviseringsmeddelanden. Mer information finns i Vanliga aviseringsscheman.
Typer av aviseringar
Du kan avisera om valfritt mått eller loggdatakälla på Azure Monitor-dataplattformen. Det finns många olika typer av aviseringar beroende på vilka tjänster du övervakar och de övervakningsdata som du samlar in. Olika typer av aviseringar har olika fördelar och nackdelar. Mer information finns i Välj rätt övervakningsaviseringstyp.
I följande lista beskrivs de typer av Azure Monitor-aviseringar som du kan skapa:
- Måttaviseringar utvärderar resursmått med jämna mellanrum. Mått kan vara plattformsmått, anpassade mått, loggar från Azure Monitor som konverterats till mått eller Application Insights-mått. Måttaviseringar kan också tillämpa flera villkor och dynamiska tröskelvärden.
- Med loggaviseringar kan användare använda en Log Analytics-fråga för att utvärdera resursloggar med en fördefinierad frekvens.
- Aktivitetsloggaviseringar utlöses när en ny aktivitetslogghändelse inträffar som matchar definierade villkor. Resource Health-aviseringar och Service Health-aviseringar är aktivitetsloggaviseringar som rapporterar om tjänstens och resurshälsan.
Vissa Azure-tjänster stöder även aviseringar om smart identifiering, Prometheus-aviseringar eller rekommenderade aviseringsregler.
För vissa tjänster kan du övervaka i stor skala genom att tillämpa samma måttaviseringsregel på flera resurser av samma typ som finns i samma Azure-region. Enskilda meddelanden skickas för varje övervakad resurs. Information om Azure-tjänster och moln som stöds finns i Övervaka flera resurser med en aviseringsregel.
Rekommenderade varningsregler
För vissa Azure-tjänster kan du aktivera rekommenderade färdiga aviseringsregler.
Systemet kompilerar en lista över rekommenderade aviseringsregler baserat på:
- Resursproviderns kunskaper om viktiga signaler och tröskelvärden för övervakning av resursen.
- Data som talar om vad kunder ofta aviserar om för den här resursen.
Anmärkning
Rekommenderade aviseringsregler är tillgängliga för:
- Virtuella datorer
- Azure Kubernetes Service-resurser (AKS)
- Log Analytics-arbetsytorna
Konfigurera Prometheus-måttbaserade aviseringar
Krav för nedladdning och konfiguration: Aviseringsregler är tillgängliga som nedladdningsbara ARM-mallar eller Bicep-filer. Innan du konfigurerar aviseringar kontrollerar du att den hanterade tjänsten för Prometheus är aktiverad i klustret och att en Azure Monitor-arbetsyta är korrekt länkad till ditt AKS-kluster.
När du aktiverar insamling av den hanterade tjänsten för Prometheus-mått för ditt kluster kan du ladda ned en samling rekommenderade regler för Prometheus-aviseringar för den hanterade tjänsten.
Nedladdningen innehåller följande regler:
| Nivå | Aviseringar |
|---|---|
| Klusternivå | KubeCPUQuotaOvercommitKubeMemoryQuotaOvercommitKubeContainerOOMKilledCountKubeClientErrorsKubePersistentVolumeFillingUpKubePersistentVolumeInodesFillingUpKubePersistentVolumeErrorsKubeContainerWaitingKubeDaemonSetNotScheduledKubeDaemonSetMisScheduledKubeQuotaAlmostFull |
| Nodnivå | KubeNodeUnreachableKubeNodeReadinessFlapping |
| Poddnivå | KubePVUsageHighKubeDeploymentReplicasMismatchKubeStatefulSetReplicasMismatchKubeHpaReplicasMismatchKubeHpaMaxedOutKubePodCrashLoopingKubeJobStaleKubePodContainerRestartKubePodReadyStateLowKubePodFailedStateKubePodNotReadyByControllerKubeStatefulSetGenerationMismatchKubeJobFailedKubeContainerAverageCPUHighKubeContainerAverageMemoryHighKubeletPodStartUpLatencyHigh |
Mer information finns i Skapa loggaviseringar från Container Insights och Frågeloggar från Container Insights.
Loggaviseringar kan mäta två typer av information som hjälper dig att övervaka olika scenarier:
- Resultatantal: Räknar antalet rader som returneras av frågan. Använd den här informationen för att arbeta med händelser som Windows-händelseloggar, syslog-händelser och programfel.
- Beräkning av ett värde: Gör en beräkning baserad på en numerisk kolumn. Använd den här informationen om du vill inkludera olika resurser. Ett exempel är CPU-procent.
De flesta loggfrågor jämför ett DateTime värde med den aktuella tiden med operatorn now och går tillbaka en timme. Information om hur du skapar loggbaserade aviseringar finns i Skapa loggaviseringar från Container Insights.
AKS-aviseringsregler
I följande tabell visas några föreslagna aviseringsregler för AKS. Dessa aviseringar är bara exempel. Du kan ange aviseringar för alla mått, loggposter eller aktivitetsloggposter som anges i aks-övervakningsdatareferensen.
| Tillstånd | Beskrivning |
|---|---|
| Cpu-användningsprocent>95 | Aviseringar när den genomsnittliga CPU-användningen för alla noder överskrider tröskelvärdet. |
| Procent för> minnesarbetsuppsättning100 | Aviseringar när den genomsnittliga arbetsuppsättningen för alla noder överskrider tröskelvärdet. |
Advisor-rekommendationer
För vissa tjänster, om kritiska villkor eller överhängande ändringar inträffar under resursåtgärder, visas en avisering på sidan Tjänstöversikt i portalen. Du hittar mer information och rekommenderade korrigeringar för aviseringen i Advisor-rekommendationer under Övervakning i den vänstra menyn. Under normal drift visas inga advisor-rekommendationer.
Mer information om Azure Advisor finns i Översikt över Azure Advisor.
Anmärkning
Om du skapar eller kör ett program som körs på din tjänst kan Azure Monitor-programinsikter erbjuda fler typer av aviseringar.
Övervakning av nätverksmått för AKS-noder
Krav för version och aktivering: I Kubernetes version 1.29 och senare aktiveras nätverksmått för noder som standard för alla kluster som har Azure Monitor aktiverat. För tidigare Kubernetes-versioner måste du aktivera nätverksövervakning manuellt via klusterkonfiguration. Den här funktionen kräver att Azure Monitor eller Container Insights konfigureras i klustret.
Nodnätverksmått är avgörande för att upprätthålla ett felfritt och högpresterande Kubernetes-kluster. Genom att samla in och analysera data om nätverkstrafik kan du få värdefulla insikter om klustrets åtgärd och identifiera potentiella problem innan de leder till avbrott eller prestandaförlust.
Följande nodnätverksmått är aktiverade som standard och aggregeras per nod. Alla mått inkluderar etiketterna kluster och instans (nodnamn). Du kan enkelt visa dessa mått med hjälp av instrumentpanelen Hanterad Grafana under Azure Managed Prometheus>Kubernetes>Nätverk>Kluster
Nätverksmått för AKS-noder efter dataplanstyp
Alla mått innehåller följande etiketter:
cluster-
instance(nodnamn)
Stöd och begränsningar för operativsystemet: För scenarier med Cilium-dataplan tillhandahåller containernätverksobservabilitetsfunktionen endast mått för Linux-nodpooler. Windows stöds för närvarande inte för mått för containernätverksobservabilitet. Se till att klustret har Linux-nodpooler för fullständig Cilium-måtttillgänglighet.
För scenarier med Cilium-dataplan tillhandahåller funktionen Observerbarhet för containernätverk endast mått för Linux. Windows stöds för närvarande inte för mått för containernätverksobservabilitet.
Cilium exponerar flera mått som Container Network Observability använder:
| Metriknamn | Beskrivning | Extra etiketter | Linux | Windows |
|---|---|---|---|---|
cilium_forward_count_total |
Totalt antal vidarebefordrade paket | direction |
Stödd ✅ | Ej stöds ❌ |
cilium_forward_bytes_total |
Totalt antal vidarebefordrade byte | direction |
Stödd ✅ | Ej stöds ❌ |
cilium_drop_count_total |
Totalt antal borttagna paket |
direction, reason |
Stödd ✅ | Ej stöds ❌ |
cilium_drop_bytes_total |
Totalt antal borttagna byte |
direction, reason |
Stödd ✅ | Ej stöds ❌ |
Inaktivera AKS-nodnätverksmåttsamling
Du kan inaktivera insamling av nätverksmått på specifika noder genom att lägga till etiketten networking.azure.com/node-network-metrics=disabled i dessa noder.
Anmärkning
Näthinnan har en operator: "Exists"effect: NoSchedule tolerans, så den kringgår NoSchedule taints. Därför används etiketter i stället för taints för att styra schemaläggningen.
Om klustret är autoprovisioning/autoscaling noder måste du aktivera flaggan manuellt på varje nod.
Viktigt!
Den här funktionen gäller inte om ACNS (Advanced Container Networking Services) är aktiverat i klustret.
Så här inaktiverar du insamling av mått på en nod:
kubectl label node <node-name> networking.azure.com/node-network-metrics=disabled
Detaljerade mått på poddnivå och DNS finns i Advanced Container Networking Services.
Relaterat innehåll
- En referens till mått, loggar och andra viktiga värden som skapats för AKS finns i referensen för AKS-övervakningsdata.
- Allmän information om övervakning av Azure-resurser finns i Övervaka Azure-resurser med Hjälp av Azure Monitor.
- Detaljerad övervakning av den fullständiga Kubernetes-stacken finns i Övervaka Kubernetes-kluster med hjälp av Azure-tjänster och molnbaserade verktyg.
- Information om hur du samlar in måttdata från Kubernetes-kluster finns i Hanterad tjänst för Prometheus i Azure Monitor.
- Information om hur du samlar in loggar i Kubernetes-kluster finns i Azure Monitor-funktioner för Kubernetes-övervakning.
- Information om datavisualisering finns i Azure-arbetsböcker och Övervaka dina Azure-tjänster i Grafana.