I den här artikeln beskrivs några strategier för partitionering av data i olika Azure-datalager. Allmän vägledning om när data ska partitioneras och metodtips finns i Datapartitionering.
Partitionera Azure SQL Database
Varje enskild SQL-databas kan innehålla en viss datavolym. Genomströmningen begränsas av arkitekturen och hur många samtidiga anslutningar som stöds.
Elastiska pooler stöder horisontell skalning för en SQL-databas. Med elastiska pooler kan du partitionera dina data i shards som är spridda över flera SQL-databaser. Du kan också lägga till och ta bort fragment när datavolymen växer och krymper. Elastiska pooler kan också bidra till att minska konkurrensen genom att distribuera belastningen mellan databaser.
Varje fragment (eller shard) implementeras som en SQL-databas. En shard kan innehålla mer än en datauppsättning (kallas för en shardlet). Varje databas underhåller metadata som beskriver varje shardlet som den innehåller. En shardlet kan vara ett enskilt dataobjekt eller en grupp med objekt som delar samma shardlet-nyckel. I ett program med flera klienter kan shardlet-nyckeln till exempel vara klientorganisations-ID:t och alla data för en klientorganisation kan lagras i samma shardlet.
Klientprogram ansvarar för att associera en datauppsättning med en shardlet-nyckel. En separat SQL-databas ansvarar för en övergripande fragmentkarta. Den här databasen har en lista över alla shards och shardletar i systemet. Programmet ansluter till shard map manager-databasen för att hämta en kopia av fragmentkartan. Den cachelagrar shardkartan lokalt och använder kartan för att dirigera databegäranden till rätt fragment. Den här funktionen är dold bakom en serie API:er som finns i Elastic Database-klientbiblioteket, som är tillgängligt för Java och .NET.
Mer information om elastiska pooler finns i Skala ut med Azure SQL Database.
För att minska svarstiden och förbättra tillgängligheten kan du replikera den globala shard map manager-databasen. Med prisnivåerna Premium kan du konfigurera aktiv geo-replikering för att kontinuerligt kopiera data till databaser i olika regioner.
Du kan också använda Azure SQL Data Sync eller Azure Data Factory för att replikera shard map manager-databasen mellan regioner. Den här typen av replikering körs regelbundet och är lämpligare om fragmentkartan ändras sällan och inte kräver Premium-nivå.
Elastic Database ger två scheman för att mappa data till shardletar och lagra dem i fragment:
En listshardkarta associerar en enda nyckel till en shardlet. I ett flerklientsystem kan data för varje klient kopplas till en unik nyckel och lagras i en egen shardlet. För att garantera isolering kan varje shardlet hållas inom sin egen shard.

Ladda ned en Visio-fil med det här diagrammet.
En intervallshardkarta associerar en uppsättning sammanhängande nyckelvärden med en shardlet. Du kan till exempel gruppera data för en uppsättning klienter (var och en med sin egen nyckel) i samma shardlet. Det här schemat är billigare än det första eftersom klientorganisationer delar datalagring, men har mindre isolering.

Ladda ned en Visio-fil i det här diagrammet
En enda shard kan innehålla data för flera shardletar. Du kan till exempel använda listshardletar och lagra data för olika, icke sammanhängande klienter i samma fragment. Du kan också blanda intervallshardletar och lista shardletar i samma fragment, även om de kommer att hanteras via olika kartor. Följande diagram visar den här metoden:

Ladda ned en Visio-fil med det här diagrammet.
Elastiska pooler gör det möjligt att lägga till och ta bort fragment när datavolymen krymper och växer. Klientprogram kan skapa och ta bort shards dynamiskt och transparent uppdatera shard map manager. Att ta bort ett fragment är dock en destruktiv åtgärd. Det krävs att du också tar bort alla data i fragmentet.
Om ett program behöver dela upp en shard i två separata shards eller kombinera shards använder du verktyget split-merge. Det här verktyget körs som en Azure-webbtjänst och migrerar data på ett säkert sätt mellan shards.
Partitioneringsschemat kan avsevärt påverka systemets prestanda. Det kan också påverka den hastighet med vilken shards måste läggas till eller tas bort, eller att data måste partitioneras om mellan shards. Tänk också på följande faktorer:
Gruppera data som används tillsammans i samma fragment och undvik åtgärder som kommer åt data från flera shards. En shard är en SQL-databas i sig, och kopplingar mellan databaser måste utföras på klientsidan.
Även om SQL Database inte stöder kopplingar mellan databaser kan du använda Elastic Database-verktygen för att utföra frågor med flera fragment. En fråga med flera fragment skickar enskilda frågor till varje databas och sammanfogar resultatet.
Utforma inte ett system som har beroenden mellan shards. Referensintegritetsbegränsningar, utlösare och lagrade procedurer i en databas kan inte referera till objekt i en annan.
Om du har referensdata som ofta används av frågor bör du överväga att replikera dessa data mellan shards. Den här metoden kan ta bort behovet av att koppla data mellan databaser. Helst bör sådana data vara statiska eller långsamma för att minimera replikeringsarbetet och minska risken för att de blir inaktuella.
Shardletar som tillhör samma fragmentkarta bör ha samma schema. Den här regeln tillämpas inte av SQL Database, men datahantering och frågor blir mycket komplexa om varje shardlet har ett annat schema. Skapa i stället separata fragmentkartor för varje schema. Kom ihåg att data som tillhör olika shardletar kan lagras i samma fragment.
Transaktionsåtgärder stöds endast för data i en shard och inte mellan shards. Transaktioner kan sträcka sig över flera shardletar så länge de ingår i samma fragment. Om din affärslogik behöver utföra transaktioner bör du därför antingen lagra data i samma fragment eller implementera eventuell konsekvens.
Placera shards nära de användare som har åtkomst till data i dessa shards. Den här strategin kan förkorta svarstiden.
Undvik att ha en blandning av mycket aktiva och relativt inaktiva fragment. Försök att sprida belastningen jämnt över fragmenten. Detta kan kräva hashning av partitioneringsnycklarna. Om du geoplacerar fragment ska du se till att de hashade nycklarna pekar på shardletar i fragment som ligger nära de användare som använder dessa data.
Partitionera Azure Table Storage
Azure Table Storage är ett nyckelvärdeslager som är utformat för partitionering. Alla entiteter lagras i en partition och partitioner hanteras internt av Azure Table Storage. Varje entitet som lagras i en tabell måste ange en tvådelad nyckel som innehåller:
Partitionsnyckeln. Det här är ett strängvärde som avgör partitionen där Azure Table Storage ska placera entiteten. Alla entiteter med samma partitionsnyckel lagras i samma partition.
Radnyckeln. Det här är ett strängvärde som identifierar entiteten i partitionen. Alla enheter inom en partition är lexikalt sorterade, i stigande ordning, av den här nyckeln. Kombinationen partitionsnyckel/radnyckel måste vara unik för varje entitet och längden får inte överstiga 1 KB.
Om en entitet läggs till i en tabell med en tidigare oanvänd partitionsnyckel skapar Azure Table Storage en ny partition för den här entiteten. Andra entiteter med samma partitionsnyckel lagras i samma partition.
Den här mekanismen implementerar effektivt en automatisk utskalningsstrategi. Varje partition lagras på samma server i ett Azure-datacenter för att säkerställa att frågor som hämtar data från en enda partition körs snabbt.
Microsoft har publicerat skalbarhetsmål för Azure Storage. Om systemet sannolikt överskrider dessa gränser kan du överväga att dela upp entiteter i flera tabeller. Använd vertikal partitionering och dela upp fälten i grupper efter vilka som mest sannolikt ska användas tillsammans.
Följande diagram visar den logiska strukturen för ett exempel på ett lagringskonto. Lagringskontot innehåller tre tabeller: kundinformation, produktinformation och beställningsinformation.
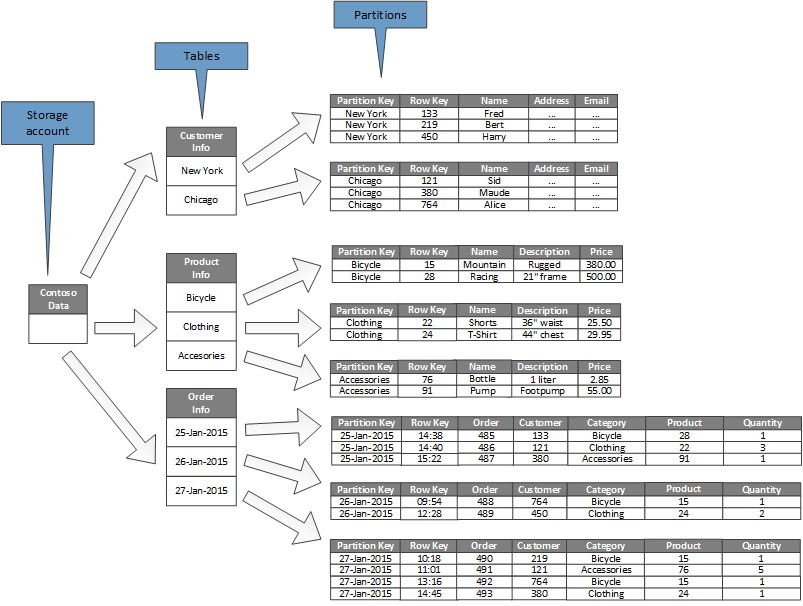
Varje tabell har flera partitioner.
- I tabellen Kundinformation partitioneras data enligt den stad där kunden finns. Radnyckeln innehåller kund-ID:t.
- I tabellen Produktinformation partitioneras produkterna efter produktkategori och radnyckeln innehåller produktnumret.
- I tabellen Orderinformation partitioneras beställningarna efter orderdatum och radnyckeln anger den tid då ordern togs emot. Alla data sorteras efter radnyckeln i varje partition.
Tänk på följande när du utformar entiteter för Azure Table Storage:
Välj en partitionsnyckel och radnyckel efter hur data används. Välj en kombination av partitionsnyckel och radnyckel som stöder de flesta av dina frågor. De mest effektiva frågorna hämtar data genom att ange partitionsnyckeln och radnyckeln. Det går att slutföra frågor som anger en partitionsnyckel och en uppsättning radnycklar genom att skanna en enda partition. Det här går relativt snabbt eftersom data lagras i radnyckelordning. Om frågor inte anger vilken partition som ska genomsökas måste varje partition genomsökas.
Om en entitet har en naturlig nyckel kan du använda den som partitionsnyckel och ange en tom sträng som radnyckel. Om en entitet har en sammansatt nyckel som består av två egenskaper väljer du den långsammaste egenskapen som partitionsnyckel och den andra som radnyckel. Om en entitet har fler än två nyckelegenskaper används en sammansättning av egenskaper för partitions- och radnycklarna.
Om du regelbundet utför frågor som söker efter data med andra fält än partitions- och radnycklarna kan du överväga att implementera indextabellmönstret eller överväga att använda ett annat datalager som stöder indexering, till exempel Azure Cosmos DB.
Om du genererar partitionsnycklar med hjälp av en monoton sekvens (till exempel "0001", "0002", "0003") och varje partition endast innehåller en begränsad mängd data, kan Azure Table Storage fysiskt gruppera dessa partitioner på samma server. Azure Storage förutsätter att programmet troligen utför frågor över ett sammanhängande intervall med partitioner (intervallfrågor) och är optimerat för det här fallet. Den här metoden kan dock leda till hotspots, eftersom alla infogningar av nya entiteter sannolikt kommer att koncentreras i ena änden det sammanhängande intervallet. Den kan också minska skalbarheten. Om du vill sprida belastningen jämnare kan du överväga att hasha partitionsnyckeln.
Azure Table Storage stöder transaktionsåtgärder för entiteter som tillhör samma partition. Ett program kan utföra flera åtgärder för att infoga, uppdatera, ta bort, ersätta eller slå samman som en atomisk enhet, så länge transaktionen inte innehåller fler än 100 entiteter och nyttolasten för begäran inte överstiger 4 MB. Åtgärder som omfattar flera partitioner är inte transaktionella och kan kräva att du implementerar eventuell konsekvens. Mer information om tabelllagring och transaktioner finns i Utföra entitetsgrupptransaktioner.
Tänk på partitionsnyckelns kornighet:
Om du använder samma partitionsnyckel för varje entitet resulterar det i en enda partition som finns på en server. Detta hindrar partitionen från att skala ut och fokuserar belastningen på en enskild server. Därför är den här metoden endast lämplig för lagring av ett litet antal entiteter. Det säkerställer dock att alla entiteter kan delta i entitetsgrupptransaktioner.
Om du använder en unik partitionsnyckel för varje entitet skapar tabelllagringstjänsten en separat partition för varje entitet, vilket kan resultera i ett stort antal små partitioner. Den här metoden är mer skalbar än en enda partitionsnyckel, men entitetsgrupptransaktioner är inte möjliga. Om frågor hämtar från fler än en entitet kan de dessutom behöva läsa från fler än en server. Men om programmet utför intervallfrågor kan det hjälpa att optimera dessa frågor genom att använda en monoton sekvens för partitionsnycklarna.
Genom att dela partitionsnyckeln mellan en delmängd av entiteter kan du gruppera relaterade entiteter i samma partition. Åtgärder som omfattar relaterade entiteter kan utföras med hjälp av entitetsgrupptransaktioner. Förfrågningar som hämtar en uppsättning relaterade entiteter kan uppfyllas via åtkomst till en enda server.
Mer information finns i designguiden för Azure Storage-tabellen och strategin för skalbar partitionering.
Partitionering av Azure Blob Storage
Azure Blob Storage gör det möjligt att lagra stora binära objekt. Använd blockblobar i scenarier när du behöver ladda upp eller ladda ned stora mängder data snabbt. Använda sidblobar för program som kräver slumpmässiga snarare än seriell åtkomst till delar av dina data.
Varje blob (block- eller sidtyp) lagras i en container i ett Azure-lagringskonto. Du kan använda containrar och gruppera relaterade blobar som har samma säkerhetskrav. Den här grupperingen är logisk snarare än fysisk. Varje blob har ett unikt namn i en container.
Partitionsnyckeln för en blob är kontonamnet + containernamnet + blobnamnet. Partitionsnyckeln används för att partitionera data i intervall och dessa intervall är belastningsutjäxlade i hela systemet. Blobar kan distribueras över flera servrar för att skala ut åtkomsten till dem. En enda blob kan dock bara hanteras av en enda server.
Om ditt namngivningsschema använder tidsstämplar eller numeriska identifierare kan det leda till överdriven trafik till en partition, vilket begränsar systemet från effektiv belastningsutjämning. Om du till exempel har dagliga åtgärder som använder ett blobobjekt med en tidsstämpel, till exempel yyyy-mm-dd, skulle all trafik för åtgärden gå till en enda partitionsserver. Överväg i stället att prefixera namnet med en tresiffrig hash. Mer information finns i Namngivningskonvention för partitioner.
Åtgärderna för att skriva ett enda block eller en sida är atomiska, men åtgärder som omfattar block, sidor eller blobar är inte det. Om du behöver säkerställa konsekvens när du utför skrivåtgärder över block, sidor och blobar kan du ta ut ett skrivlås med hjälp av ett bloblån.
Partitionera Azure-lagringsköer
Med Azure-lagringsköer kan du implementera asynkrona meddelanden mellan processer. Alla Azure-lagringskonton kan innehålla valfritt antal köer. Varje kö kan innehålla valfritt antal meddelanden. Den enda begränsningen är det utrymme som finns tillgängligt i lagringskontot. Den maximala storleken för ett enskilt meddelande är 64 KB. Om du behöver meddelanden som är större än det kan du överväga att använda Azure Service Bus-köer i stället.
Varje lagringskö har ett unikt namn inom sitt lagringskonto. Azure partitionerar köer baserat på namnet. Alla meddelanden för samma kö lagras i samma partition, som kontrolleras av en enda server. Olika köer kan hanteras av olika servrar i syfte att jämna ut belastningen. Tilldelningen av köer till servrar är transparent för program och användare.
I ett storskaligt program ska du inte använda samma lagringskö för alla instanser av programmet eftersom den här metoden kan göra att servern som är värd för kön blir en frekvent plats. Använd i stället olika köer för olika funktionsområden i programmet. Azure Storage-köer stöder inte transaktioner, så att dirigera meddelanden till olika köer bör ha liten effekt på meddelandekonsekvensen.
En Azure-lagringskö kan hantera upp till 2 000 meddelanden per sekund. Om du måste bearbeta fler meddelanden kan du överväga att skapa flera köer. I ett globalt program kan du till exempel skapa separata lagringsköer i separata lagringskonton för att hantera programinstanser som körs i varje region.
Partitionera Azure Service Bus
Azure Service Bus använder en meddelandekoordinator för att hantera meddelanden som skickas till en Service Bus-kö eller ett ämne. Standardinställningen är att alla meddelanden som skickas till en kö eller ett ämne hanteras av samma process. Den här arkitekturen begränsa det totala genomflödet i meddelandekön. Du kan dock också partitionera en kö eller ett ämne medan du skapar dem. Du ställer då in beskrivningen EnablePartitioning för kön eller ämnet på true (sant).
En partitionerad kö, eller ett ämne, är indelad i flera fragment. Varje fragment backas upp av ett separat meddelandearkiv och en meddelandekoordinator. Service Bus ansvarar för att skapa och hantera dessa fragment. När ett program skickar ett meddelande till en partitionerad kö eller ett ämne tilldelar Service Bus meddelandet ett fragment för den kön eller det ämnet. När ett program tar emot ett meddelande från en kö eller en prenumeration letar Service Bus efter nästa tillgängliga meddelande i varje fragment och skickar det till programmet för bearbetning.
Den här strukturen hjälper till att fördela belastningen över koordinatorerna och lagren. Det ger ökad skalbarhet och förbättrad tillgänglighet. Om en meddelandekoordinator eller ett arkiv för ett fragment är tillfälligt otillgänglig kan Service Bus hämta meddelanden från ett tillgängligt fragment.
Service Bus tilldelar meddelanden till fragment på följande sätt:
Om meddelandet tillhör en session skickas alla meddelanden med samma värde för egenskapen SessionId till samma fragment.
Om ett meddelande inte tillhör någon session men avsändaren har angett ett värde för egenskapen PartitionKey (partitionsnyckel) så skickas alla meddelanden med samma värde för PartitionKey (partitionsnyckel) till samma fragment.
Kommentar
Om egenskaperna SessionId (sessions-id) och PartitionKey (partitionsnyckel) båda anges måste de ha samma värde. I annat fall avvisas meddelandet.
Om egenskaperna SessionId (sessions-id) och PartitionKey (partitionsnyckel) inte anges för ett meddelande och dubblettidentifiering är aktiverad används egenskapen MessageId (meddelande-id). Alla meddelanden med samma MessageId (meddelande-id) dirigeras till samma fragment.
Om egenskaperna SessionId, PartitionKey (sessions-id, partitionsnyckel) och MessageId (meddelande-id) inte finns för meddelanden så tilldelar Service Bus meddelanden till fragment sekventiellt. Om ett fragment inte är tillgängligt går Service Bus vidare till nästa. Det betyder att ett tillfälligt fel i meddelandeinfrastrukturen inte innebär att åtgärden för att skicka meddelanden stoppas.
Överväg följande när du bestämmer om och hur du ska partitionera en Service Bus-meddelandekö eller ett ämne:
Service Bus-köer och -ämnen skapas inom en Service Bus-namnområde. Service Bus tillåter för närvarande upp till 100 partitionerade köer och ämnen per namnområde.
Varje Service Bus-namnområde inför kvoter på tillgängliga resurser. Det kan vara antalet prenumerationer per ämne, antalet samtidiga begäranden per sekund om att skicka och ta emot och det maximala antalet samtidiga anslutningar som kan upprättas. Dessa kvoter dokumenteras i Service Bus-kvoter. Om du tror att du kan överskrida de här värdena kan du skapa ytterligare namnområden med egna köer och ämnen och sprida arbetet över dessa. I ett globalt program kan du till exempel skapa separata namnområden i varje region. Du kan konfigurera programinstanser så att köer och ämnen används i det närmaste namnområdet.
Meddelanden som skickas som del i en transaktion måste ange en partitionsnyckel. Det kan vara egenskapen SessionId (sessions-id), PartitionKey (partitionsnyckel) eller MessageId (meddelande-id). Alla meddelanden som skickas inom samma transaktion måste ha samma partitionsnyckel, för att hanteras av samma meddelandekoordinatorprocess. Det går inte att skicka meddelanden till olika köer och ämnen inom samma transaktion.
Partitionerade köer och ämnen kan inte konfigureras så att de tas bort automatiskt när de blir inaktiva.
Det går för närvarande inte att använda partitionerade köer och ämnen med AMQP (Advanced Message Queuing Protocol) om du skapar lösningar av typen flera plattformar eller hybrid.
Partitionera Azure Cosmos DB
Azure Cosmos DB for NoSQL är en NoSQL-databas för lagring av JSON-dokument. Ett dokument i en Azure Cosmos DB-databas är en JSON-serialiserad representation av ett objekt eller andra data. Inga fasta scheman tillämpas, förutom att varje dokument måste innehålla ett unikt ID.
Dokument delas upp i samlingar. Du kan gruppera relaterade dokument tillsammans i en samling. I ett system som underhåller blogginlägg kan du till exempel lagra innehållet i varje blogginlägget som ett dokument i en samling. Du kan också skapa samlingar för varje ämnestyp. I ett program med flera klienter, till exempel ett system där olika användare styr och hanterar sina egna blogginlägg, kan du partitionera bloggar efter författare och skapa separata samlingar för var och en. Lagringsutrymmet som tilldelas till samlingar är elastiskt och krympa och växa efter behov.
Azure Cosmos DB stöder automatisk partitionering av data baserat på en programdefinierad partitionsnyckel. En logisk partition är en partition som lagrar alla data för ett partitionsnyckelvärde. Alla dokument som delar samma partitionsnyckelvärde placeras i samma logiska partition. Azure Cosmos DB distribuerar värden enligt hash för partitionsnyckeln. En logisk partition har en maximal storlek på 20 GB. Det är därför viktigt att välja rätt partitionsnyckeln när du skapar den. Välj en egenskap med ett stort antal värden och jämnt åtkomstmönster. Mer information finns i dokumentationen om partitioner och skalanpassning i Azure Cosmos DB.
Kommentar
Varje Azure Cosmos DB-databas har en prestandanivå som avgör hur mycket resurser den får. Prestandanivån är kopplad till en hastighetsbegränsning för en enhet för begäran, även kallad en RU. RU-hastighetsbegränsningen specificerar mängden resurser som reserveras och är tillgängliga för samlingen för exklusiv användning. Kostnaden för en samling beror på vilken prestandanivå som väljs för samlingen. Ju högre prestandanivå (och RU-hastighetsbegränsning), desto högre kostnad. Du kan justera prestandanivån för en samling via Azure-portalen. Mer information finns i Enheter för programbegäran i Azure Cosmos DB.
Om partitioneringsmekanismen som Azure Cosmos DB tillhandahåller inte räcker kan du behöva fragmentera data på programnivå. Dokumentsamlingarna tillhandahåller en naturlig mekanism för att partitionera data i en enskild databas. Det enklaste sättet att implementera horisontell partitionering (sharding) är att skapa en samling för varje fragment. Containrar är logiska resurser och kan sträcka sig över en eller flera servrar. Containrar med fast storlek har en maximal gräns på 20 GB och 10 000 RU/s-dataflöde. Obegränsade containrar har inte en maximal lagringsstorlek, men måste ange en partitionsnyckel. Vid programsharding måste klientprogrammet rikta direkta begäranden till rätt fragment, vanligtvis genom att implementera en egen mappningsmekanism baserad på vissa dataattribut som definierar fragmentnyckeln.
Alla databaser skapas i kontexten för ett Azure Cosmos DB-databaskonto. Ett enda konto kan innehålla flera databaser. Det specificerar inom vilka regioner databaserna skapas. Varje konto har dessutom en egen åtkomstkontroll. Du kan använda Azure Cosmos DB-konton för att geo-hitta shards (samlingar i databaser) nära de användare som behöver komma åt dem och tillämpa begränsningar så att endast dessa användare kan ansluta till dem.
Tänk på följande när du bestämmer hur du partitionerar data med Azure Cosmos DB för NoSQL:
De resurser som är tillgängliga för en Azure Cosmos DB-databas omfattas av kontots kvotbegränsningar. Varje databas kan innehålla ett antal samlingar. Varje samling har en prestandanivå som styr RU-hastighetsbegränsningen för samlingen (det reserverade genomflödet). Läs mer i Azure-prenumeration och tjänstbegränsningar, kvoter och begränsningar.
Varje dokument måste ha ett attribut som kan användas till att unikt identifiera dokumentet i samlingen där det lagras. Attributet skiljer sig från fragmentnyckeln, som definierar vilken samling dokumentet finns i. En samling kan innehålla ett stort antal dokument. I teorin begränsas den bara av den maximala längden för dokument-ID:t. Dokument-ID:t kan innehålla upp till 255 tecken.
Alla åtgärder mot ett dokument utförs inom ramen för en transaktion. Transaktioner är begränsade till den samling där dokumentet finns. Om en åtgärd misslyckas återställs det arbete som har utförts. När ett dokument är föremål för en åtgärd gäller isolering på skuggkopienivå för alla ändringar som görs. Om ett fel uppstår vid en begäran om att exempelvis skapa ett nytt dokument, och en annan användare samtidigt skickar en begäran till databasen, så ser inte den senarenämnda användaren dokumentet som sedan tas bort.
Databasfrågor också är begränsade till samlingsnivå. En enskild fråga kan hämta data från en enda samling. Om du behöver hämta data från flera samlingar måste du skicka förfrågningar till varje samling för sig och sammanfoga resultaten i programkoden.
Azure Cosmos DB stöder programmerbara objekt som alla kan lagras i en samling tillsammans med dokument. De här omfattar lagrade procedurer, användardefinierade funktioner och utlösare (skrivna med JavaScript). De här objekten har åtkomst till alla dokument i samma samling. De här objekten körs antingen inom den omgivande transaktionen (om det finns en utlösare som utlöses av åtgärderna skapa, ta bort eller byt ut för dokumentet) eller genom att du sätter igång en ny transaktion (om det handlar om en lagrad procedur som körs på grund av en uttrycklig klientbegäran). Om koden i ett programmerbart objekt genererar ett undantag återställs transaktionen. Du kan använda lagrade procedurer och utlösare för att upprätthålla integritet och konsekvens mellan dokument, men dokumenten måste ingå i samma samling.
Det bör vara sannolikt att de samlingar du tänker lagra i databaserna håller sig inom genomströmningsgränserna som definieras av kollektionernas prestandanivåer. Mer information finns i Enheter för programbegäran i Azure Cosmos DB. Om du förutser att gränserna kommer att överskridas bör du överväga att dela samlingarna på databaser i olika konton, för att minska belastningen per samling.
Partitionering av Azure Search
I många webbprogram är möjligheten att söka efter data den primära metoden för att navigera och utforska. Användarna kan snabbt söka efter resurser (till exempel produkter i ett e-handelsprogram) baserat på kombinationer av sökvillkor. I Azure Search-tjänsten finns funktioner för fulltextsökning i webbinnehåll. Det finns dessutom funktioner som ifyllning, föreslagna förfrågningar baserade på närliggande matchningar och fasetterad navigering. Mer information finns i Vad är Azure Search?.
I Azure Search lagrar du sökbart innehåll som JSON-dokument i en databas. Du kan definiera index som anger de sökbara fälten i de här dokumenten och ger definitionerna till Azure Search. När en användare skickar en sökbegäran använder Azure Search rätt index för att hitta matchande objekt.
För att minska konkurrensen kan den lagring som används av Azure Search delas in i 1, 2, 3, 4, 6 eller 12 partitioner. Varje partition kan replikeras upp till 6 gånger. Produkten av antalet partitioner multiplicerad med antalet repliker kallas sökenheten (SU). En instans av Azure Search kan innehålla upp till 36 SU:er (en databas med 12 partitioner stöder högst 3 repliker).
Du debiteras för varje SU som allokeras till din tjänst. När volymen sökbart innehåll ökar eller antalet sökbegäranden växer kan du lägga till SU:er i en befintlig instans av Azure Search för att hantera den extra belastningen. Azure Search distribuerar dokumenten jämnt över partitionerna. För närvarande finns inte stöd för några manuella partitioneringsstrategier.
Varje partition kan innehålla högst 15 miljoner dokument eller uppta 300 GB lagringsutrymme (beroende på vilket som är mindre). Du kan skapa upp till 50 index. Tjänstens prestanda varierar och beror på dokumentkomplexiteten, tillgängliga index och nätverkslatensen. I genomsnitt ska en enskild replik (1 SU) kunna hantera 15 frågor per sekund (QPS). Vi rekommenderar dock att du utför prestandamätningar med egna data att få ett mer exakta mått på dataflödet. Mer information finns i Tjänstbegränsningar i Azure Search.
Kommentar
Du kan lagra en begränsad uppsättning datatyper i sökbara dokument, bland annat strängar, booleska värden, numeriska data, datetime-data och vissa geografiska data. Mer information finns på sidan Datatyper som stöds (Azure Search) på Microsofts webbplats.
Du har begränsad kontroll över hur Azure Search partitionerar data för varje instans av tjänsten. I en global miljö kan du eventuellt förbättra prestanda och minska svarstider och konkurrens ytterligare genom att partitionera själva tjänsten med någon av följande strategier:
Skapa en instans av Azure Search i varje geografisk region och se till att klientprogram dirigeras mot närmaste tillgängliga instans. Den här strategin kräver att alla uppdateringar av sökbart innehåll replikeras inom rimlig tid i alla instanser av tjänsten.
Skapa två nivåer för Azure Search:
- En lokal tjänst i varje region. Den ska innehålla de data som oftast används av användarna i regionen. Användare kan dirigera begäranden hit för snabba men begränsade resultat.
- En global tjänst som omfattar alla data. Användare kan dirigera begäranden hit för långsammare men mer heltäckande resultat.
Den här metoden är bäst lämpad när det finns betydande regional variation i de data som genomsöks.
Partitionering av Azure Cache for Redis
Azure Cache for Redis tillhandahåller en delad cachelagringstjänst i molnet som baseras på Redis nyckelvärdesdatalager. Som namnet antyder är Azure Cache for Redis avsett som en cachelagringslösning. Här ska du endast lagra tillfälliga data. Den är inte ett permanent datalager. Program som använder Azure Cache for Redis bör kunna fortsätta att fungera om cacheminnet inte är tillgängligt. Azure Cache for Redis stöder primär/sekundär replikering för att ge hög tillgänglighet, men begränsar för närvarande den maximala cachestorleken till 53 GB. Om du behöver mer utrymme än så måste du skapa ytterligare cacheminnen. Mer information finns i Azure Cache for Redis.
Partitionering av Redis-datalager omfattar att dela data mellan instanser av Redis-tjänsten. Varje instans utgör en partition. Azure Cache for Redis abstraherar Redis-tjänsterna bakom en fasad och exponerar dem inte direkt. Det enklaste sättet att implementera partitionering är att skapa flera Azure Cache for Redis-instanser och sprida data över dem.
Du kan koppla varje dataobjekt till en identifierare (en partitionsnyckel) som anger vilket cacheminne som lagrar dataobjektet. Klientprogramlogiken kan sedan använda identifieraren och omdirigera begäranden till rätt partition. Det här schemat är mycket enkelt, men om partitioneringsschemat ändras (till exempel om ytterligare Azure Cache for Redis-instanser skapas) kan klientprogram behöva konfigureras om.
Native Redis (inte Azure Cache for Redis) stöder partitionering på serversidan baserat på Redis-klustring. Med den här metoden kan du dela upp data jämnt över servrar med en hashningsmekanism. Varje Redis-server lagrar metadata som beskriver det intervall hashnycklar som partitionen innehåller, och som även innehåller information om vilka hashnycklar som finns i partitionerna på andra servrar.
Klientprogram skickar helt enkelt begäranden till någon av Redis-servrarna (ofta den som finns närmast). Redis-servern undersöker klientbegäran. Om det går att lösa lokalt utförs den begärda åtgärden. Annars vidarebefordras begäran till rätt server.
Den här modellen implementeras med Redis-klustring och beskrivs närmare i Redis-kursen om kluster på Redis webbplats. Redis-klustring är transparent för klientprogram. Ytterligare Redis-servrar kan läggas till i klustret (och data kan partitioneras om) utan att du behöver konfigurera om klienterna.
Viktigt!
Azure Cache for Redis stöder för närvarande endast Redis-klustring på premiumnivå.
Sidan om partitionering och om att dela data mellan flera Redis-instanser på Redis webbplats innehåller ytterligare information om hur du implementerar partitionering med Redis. I det här avsnittet förutsätter vi att du implementerar partitionering på klientsidan eller proxystödd partitionering.
Tänk på följande när du bestämmer hur du partitionerar data med Azure Cache for Redis:
Azure Cache for Redis är inte avsett att fungera som ett permanent datalager, så oavsett vilket partitioneringsschema du implementerar måste programkoden kunna hämta data från en plats som inte är cacheminnet.
Data som ofta används tillsammans ska lagras i samma partition. Redis är en kraftfull nyckelvärdeslagring med flera mycket optimerade mekanismer för att strukturera data. Mekanismerna kan vara någon av följande:
- enkla strängar (binära data med längd upp till 512 MB)
- aggregeringstyper som listor (som kan fungera som kö och stack)
- uppsättningar (sorterade och osorterade)
- hashar (som kan gruppera relaterade fält tillsammans, till exempel enheter som representerar fälten i ett objekt).
Med aggregeringstyper kan du associera många relaterade värden med samma nyckel. En Redis-nyckel identifierar en lista, uppsättning eller hash snarare än de dataobjekt som den innehåller. Dessa typer är alla tillgängliga med Azure Cache for Redis och beskrivs av sidan Datatyper på Redis webbplats. Ta till exempel ett e-handelssystem som spårar beställningar som läggs av kunder. Information om varje kund kan lagras i en Redis-hash som ställs in med hjälp av kund-ID. Varje hash kan innehålla en uppsättning beställningsnummer för kunden. En separat Redis-uppsättning kan innehålla beställningarna, strukturerade som hashar, och ställas in med beställnings-ID. Bild 8 visar den här strukturen. Observera att Redis inte implementerar någon form av referensintegritet. Det är utvecklarens ansvar att underhålla relationerna mellan kunder och beställningar.
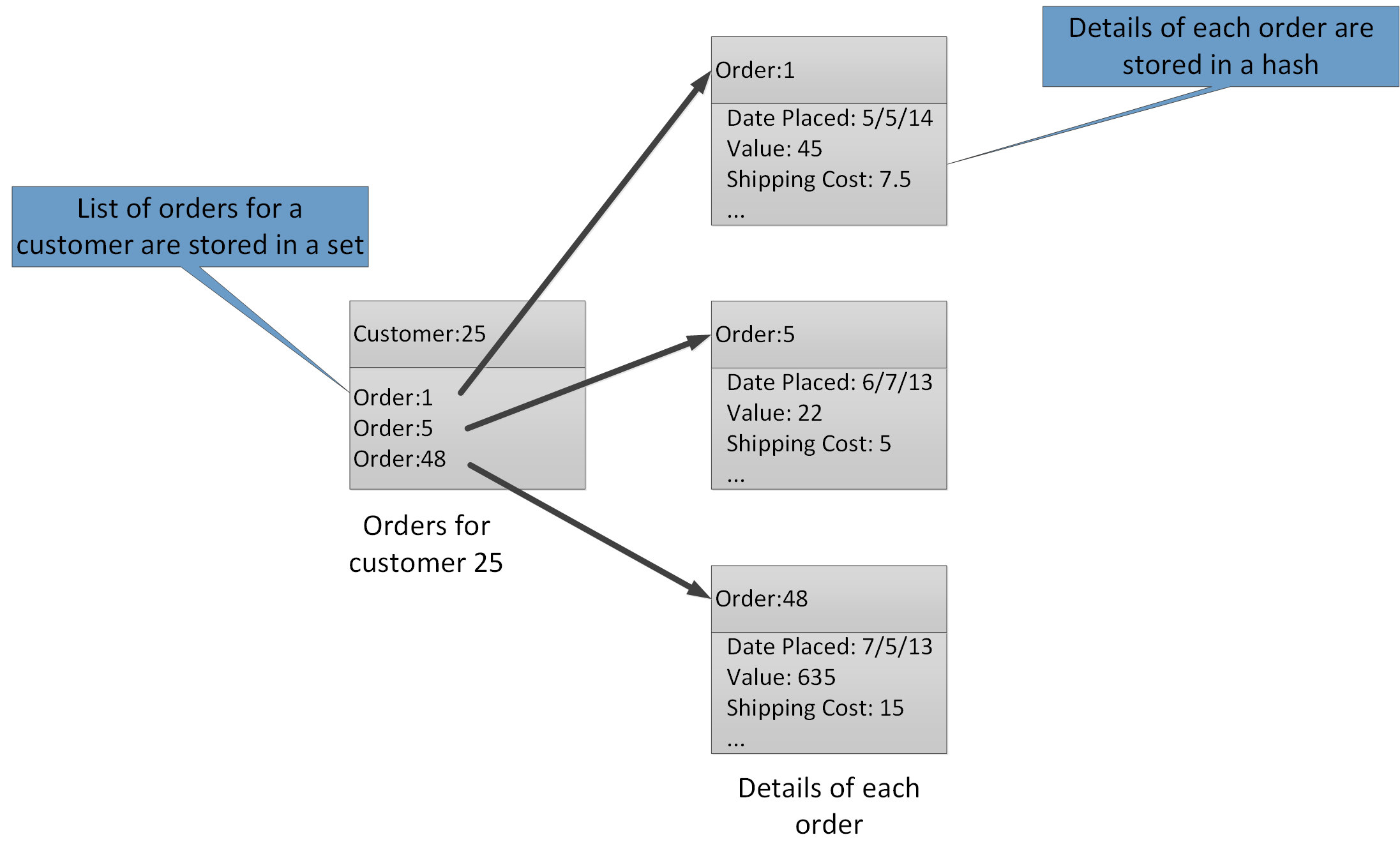
Figur 8. Föreslagen struktur i Redis-lagring för registrering av kundbeställningar och deras information.
Kommentar
I Redis är alla nycklar binära datavärden (som Redis-strängar) och kan innehålla upp till 512 MB data. En nyckel kan i teorin innehålla nästan vilken information som helst. Vi rekommenderar dock att du namnger nycklar på ett konsekvent sätt. Namnet ska beskriva datatypen och identifiera enheten men inte vara för långt. En vanlig metod är att använda nycklar i formatet entity_type:ID (enhetstyp:ID). Du kan till exempel använda formatet customer:99 (kund:99) för en kund med ID-numret 99.
Du kan implementera vertikal partitionering genom att lagra relaterad information i olika sammansättningar i samma databas. I ett e-handelsprogram kan du till exempel lagra produktinformation som används ofta i en Redis-hash och sådan som används mer sällan i en annan. Båda hashar kan ha samma produkt-ID i nyckeln. Du kan till exempel använda "product: nn" (där nn är produkt-ID) för produktinformationen och "product_details: nn" för detaljerade data. Den här strategin kan minska mängden data som de flesta frågor hämtar.
Det går att partitionera om Redis-datalager, men tänk på att det är komplicerat och tidskrävande. Redis-klustring kan partitionera om data automatiskt, men den här funktionen är inte tillgänglig med Azure Cache for Redis. När du utformar partitioneringsschemat ska du därför försöka lämna tillräckligt med ledigt utrymme i varje partition för den förväntade datatillväxten över tid. Kom dock ihåg att Azure Cache for Redis är avsett att cachelagrar data tillfälligt, och att data som lagras i cacheminnet kan ha en begränsad livslängd angiven som ett TTL-värde (time-to-live). TTL-värdet kan vara kort för relativt föränderliga data. Om data är statiska kan TTL-värdet vara mycket längre. Undvik att lagra stora mängder långlivade data i cacheminnet om det är troligt att du därmed fyller cacheminnet. Du kan ange en borttagningsprincip som gör att Azure Cache for Redis tar bort data om utrymmet är på premium.
Kommentar
När du använder Azure Cache for Redis anger du den maximala storleken på cachen (från 250 MB till 53 GB) genom att välja lämplig prisnivå. Men när en Azure Cache for Redis har skapats kan du inte öka (eller minska) dess storlek.
Redis-batchar och transaktioner kan inte sträcka sig över flera anslutningar, så alla data som påverkas av en batch eller en transaktion bör behållas i samma databas (fragment).
Kommentar
En åtgärdssekvens i en Redis-transaktion är inte nödvändigtvis atomisk. De kommandon som utgör en transaktion verifieras och läggs i kö innan de körs. Om ett fel inträffar under den här fasen tas hela kön bort. När transaktionen väl har skickats körs kommandokön i ordningsföljd. Om ett fel uppstår med ett kommando stoppas endast det kommandot. Alla föregående och efterföljande kommandon i kön utförs. Mer information finns på sidan om transaktioner på Redis webbplats.
I Redis finns funktioner för ett begränsat antal atomiska åtgärder. De enda åtgärderna av den här typen med stöd för flera nycklar och värden är MGET- och MSET-åtgärder. MGET-åtgärder returnerar en samling värden för en angiven nyckellista. MSET-åtgärder lagrar en samling värden för en angiven nyckellista. Om du behöver använda de här åtgärderna måste de nyckelvärdepar som kommandona MSET och MGET refererar till finnas i samma databas.
Partitionering av Azure Service Fabric
Azure Service Fabric är en plattform för mikrotjänster. Den tillhandahåller körning (runtime) för distribuerade program i molnet. Service Fabric stöder körbara .NET-gästprogram, tillståndskänsliga och tillståndslösa tjänster och containrar. Tillståndskänsliga tjänster ger en tillförlitlig samling för att beständigt lagra data i en nyckelvärdesamling i Service Fabric-klustret. Mer information om strategier för partitionering av nycklar i en tillförlitlig samling finns i riktlinjer och rekommendationer för tillförlitliga samlingar i Azure Service Fabric.
Nästa steg
Översikt över Azure Service Fabric är en introduktion till Azure Service Fabric.
I Partitionera tillförlitliga Service Fabric-tjänster finns mer information om tillförlitliga tjänster i Azure Service Fabric.
Partitionering av Azure Event Hubs
Azure Event Hubs är utformat för att strömma data i mycket stor skala. Partitionering är inbyggd i tjänsten för att möjliggöra horisontell skalning. Varje konsument läser endast en specifik partition av meddelandeströmmen.
Händelseutfärdaren känner bara till sin partitionsnyckel, inte den partition som händelserna publiceras till. Frikopplingen av nyckeln och partitionen gör att avsändaren inte behöver känna till så mycket om bearbetningen nedströms. (Det går också att skicka händelser direkt till en viss partition, men det rekommenderas vanligtvis inte.)
Fundera över skalningen på sikt när du väljer partitionsantal. När en händelsehubb har skapats går det inte att ändra antalet partitioner.
Nästa steg
Mer information om hur du använder partitioner i Event Hubs finns i Vad är Event Hubs?.
Du kan läsa mer om avvägningar mellan tillgänglighet och konsekvens i Tillgänglighet och konsekvens i Event Hubs.