En icke-relationsdatabas är en databas som inte använder tabellschemat för rader och kolumner som finns i de flesta traditionella databassystem. I stället använder icke-relationsdatabaser en lagringsmodell som är optimerad för de specifika kraven för den typ av data som lagras. Data kan till exempel lagras som enkla nyckel/värde-par, som JSON-dokument eller som ett diagram som består av kanter och hörn.
Vad alla dessa datalager har gemensamt är att de inte använder en relationsmodell. Dessutom tenderar de att vara mer specifika för vilken typ av data de stöder och hur data kan efterfrågas. Till exempel är tidsseriedatalager optimerade för frågor över tidsbaserade datasekvenser. Diagramdatalager är dock optimerade för att utforska viktade relationer mellan entiteter. Inget av formaten skulle generalisera väl till uppgiften att hantera transaktionsdata.
Termen NoSQL refererar till datalager som inte använder SQL för frågor. I stället använder datalager andra programmeringsspråk och konstruktioner för att köra frågor mot data. I praktiken betyder "NoSQL" "icke-relationell databas", även om många av dessa databaser stöder SQL-kompatibla frågor. Den underliggande frågekörningsstrategin skiljer sig dock vanligtvis mycket från hur ett traditionellt hanteringssystem för relationsdatabaser (RDBMS) skulle köra samma SQL-fråga.
Det finns variationer i implementeringar och specialiseringar av NoSQL-databaser, som om det finns variationer i funktionerna i relationsdatabaser. Dessa variationer ger varje implementering sina egna primära styrkor och har en egen inlärningskurva och användningsrekommendationer. I följande avsnitt beskrivs de viktigaste kategorierna för icke-relationella databaser eller NoSQL-databaser.
Dokumentdatalager
Ett dokumentdatalager hanterar en uppsättning namngivna strängfält och objektdatavärden i en entitet som kallas för ett dokument. Dessa datalager lagrar vanligtvis data i form av JSON-dokument. Varje fältvärde kan vara ett skalärt objekt, till exempel ett tal eller ett sammansatt element, till exempel en lista eller en överordnad-underordnad samling. Data i fälten i ett dokument kan kodas på olika sätt, till exempel XML, YAML, JSON, binär JSON (BSON) eller till och med lagras som oformaterad text. Fälten i dokumenten exponeras för lagringshanteringssystemet, vilket gör det möjligt för ett program att fråga efter och filtrera data med hjälp av värdena i dessa fält.
Ett dokument innehåller vanligtvis alla data för en entitet. De objekt som utgör en entitet varierar beroende på tillämpningen. En entitet kan till exempel innehålla information om en kund, en order eller en kombination av båda. Ett enskilt dokument kan innehålla information som skulle spridas över flera relationstabeller i ett relationsdatabashanteringssystem (RDBMS). Dokumentarkiv kräver inte att alla dokument har samma struktur. Den här metoden med fri form ger stor flexibilitet. Program kan till exempel lagra olika data i dokument som svar på en ändring av affärskraven.
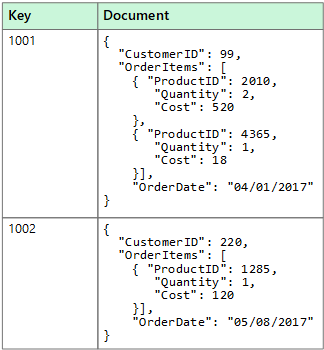
Programmet kan hämta dokument med hjälp av dokumentnyckeln. Nyckeln är en unik identifierare för dokumentet, som ofta hashas, för att distribuera data jämnt. Vissa dokumentdatabaser skapar dokumentnyckeln automatiskt. Andra gör att du kan ange ett attribut för det dokument som ska användas som nyckel. Programmet kan även köra frågor mot dokument baserat på värdet för ett eller flera fält. Vissa dokumentdatabaser stöder indexering för att underlätta snabb sökning efter dokument baserat på ett eller flera indexerade fält.
Många dokumentdatabaser har stöd för uppdateringar på plats, vilket gör det möjligt för ett program att ändra värdena i specifika fält i ett dokument utan att skriva om hela dokumentet. Läs- och skrivåtgärder över flera fält i ett enda dokument är vanligtvis atomiska.
Relevant Azure-tjänst:
Kolumndatalager
Ett kolumn- eller kolumnfamiljedatalager organiserar data i kolumner och rader. I sin enklaste form kan ett kolumnfamiljedatalager se ut ungefär som en relationsdatabas, åtminstone konceptuellt. Den verkliga kraften i en kolumnfamiljedatabas ligger i dess avnormaliserade metod för att strukturera glesa data, som härrör från den kolumnorienterade metoden för att lagra data.
Du kan tänka dig att ett datalager för kolumnfamiljen innehåller tabelldata med rader och kolumner, men kolumnerna är indelade i grupper som kallas kolumnfamiljer. Varje kolumnfamilj innehåller en uppsättning kolumner som är logiskt relaterade och som vanligtvis hämtas eller manipuleras som en enhet. Andra data som kan nås separat kan lagras i separata kolumnserier. I en kolumnserie kan nya kolumner läggas till dynamiskt, och rader kan vara null-optimerade (dvs. en rad behöver inte ha ett värde för varje kolumn).
Följande diagram visar ett exempel med två kolumnserier, Identity och Contact Info. Data för en enskild entitet har samma radnyckel i varje kolumnfamilj. Den här strukturen, där raderna för ett visst objekt i en kolumnfamilj kan variera dynamiskt, är en viktig fördel med kolumnfamiljemetoden, vilket gör att den här typen av datalager är mycket lämplig för att lagra data med olika scheman.

Till skillnad från ett nyckel-/värdelager eller en dokumentdatabas lagrar de flesta kolumnfamiljedatabaser fysiskt data i nyckelordning i stället för genom att beräkna en hash. Radnyckeln anses vara det primära indexet och aktiverar nyckelbaserad åtkomst via en specifik nyckel eller ett nyckelintervall. Med vissa implementeringar kan du skapa sekundära index över specifika kolumner i en kolumnfamilj. Med sekundära index kan du hämta data efter kolumnvärde i stället för radnyckel.
På disk lagras alla kolumner i en kolumnfamilj tillsammans i samma fil, med ett visst antal rader i varje fil. Med stora datamängder skapar den här metoden en prestandafördel genom att minska mängden data som behöver läsas från disk när bara några få kolumner efterfrågas tillsammans i taget.
Läs- och skrivåtgärder för en rad är vanligtvis atomiska inom en enda kolumnfamilj, även om vissa implementeringar ger atomitet över hela raden, som sträcker sig över flera kolumnfamiljer.
Relevant Azure-tjänst:
Nyckel/värde-datalager
Ett nyckel/värde-lager är i grunden en stor hash-tabell. Du kopplar varje datavärde till en unik nyckel och nyckel/värde-lagret använder den här nyckeln för att lagra data med hjälp av en lämplig hash-funktion. Hash-funktionen väljs för att tillhandahålla en jämn fördelning av hash-formaterade nycklar i datalagringen.
De flesta nyckel/värde-lager har endast stöd för enkla fråge-, infognings- och borttagningsåtgärder. För att ändra ett värde (delvis eller helt) måste ett program skriva över befintliga data för hela värdet. I de flesta implementeringar är läsning eller skrivning av ett enskilt värde en atomisk åtgärd. Om värdet är stort kan det ta lite tid att skriva.
Ett program kan lagra valfria data som en värdeuppsättning, även om vissa nyckel/värde-lager har gränser för den högsta storleken på värden. De lagrade värdena är täckande för lagringssystemets programvara. All schemainformation måste anges och tolkas av programmet. Värden är i princip blobar och nyckel/värde-lagret hämtar eller lagrar helt enkelt värdet efter nyckel.
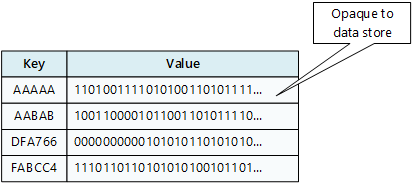
Nyckel-/värdelager är mycket optimerade för program som utför enkla sökningar med hjälp av nyckelns värde eller av ett antal nycklar, men är mindre lämpliga för system som behöver köra frågor mot data i olika tabeller med nycklar/värden, till exempel att koppla data mellan flera tabeller.
Nyckel-/värdelager är inte heller optimerade för scenarier där frågor eller filtrering efter icke-nyckelvärden är viktigt, i stället för att utföra sökningar baserat på nycklar. Med en relationsdatabas kan du till exempel hitta en post med hjälp av en WHERE-sats för att filtrera icke-nyckelkolumnerna, men nyckel-/värdelager har vanligtvis inte den här typen av uppslagsfunktion för värden, eller om de gör det krävs en långsam genomsökning av alla värden.
Ett enda nyckel/värde-lager kan vara extremt skalbart, eftersom datalagret enkelt kan distribuera data över flera noder på separata datorer.
Relevanta Azure-tjänster:
Diagramdatalager
Ett diagramdatalager hanterar två typer av information, noder och kanter. Noder representerar entiteter och kanter anger relationerna mellan dessa entiteter. Både noder och kanter kan ha egenskaper som ger information om den noden eller kanten, vilket liknar kolumner i en tabell. Kanter kan också ha en riktning som visar relationens typ.
Syftet med ett diagramdatalager är att göra det möjligt för ett program att effektivt utföra frågor som passerar nätverket med noder och kanter och analysera relationerna mellan entiteter. Följande diagram visar en organisations personaldata strukturerade som ett diagram. Entiteterna är medarbetare och avdelningar, och kanterna visar rapportförhållanden samt den avdelning där medarbetarna arbetar. I den här grafen visar pilarna vid kanterna riktningen för relationerna.
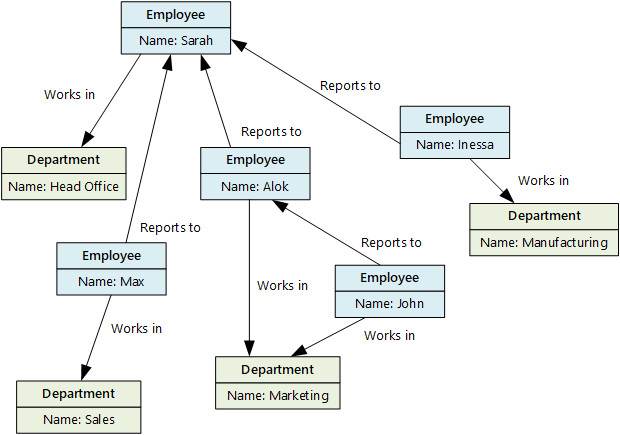
Den här strukturen gör det enkelt att köra frågor som "Hitta alla anställda som rapporterar direkt eller indirekt till Sarah" eller "Vem arbetar på samma avdelning som John?" För stora grafer med många entiteter och relationer kan du utföra komplexa analyser snabbt. Många grafdatabaser ger ett frågespråk som du kan använda för att gå igenom ett nätverk med relationer på ett effektivt sätt.
Relevant Azure-tjänst:
Tidsseriedatalager
Tidsseriedata är en uppsättning värden ordnade efter tid och ett tidsseriedatalager är optimerat för den här typen av data. Tidsseriedatalager måste ha stöd för ett mycket stort antal skrivningar, eftersom de vanligtvis samlar in stora mängder data i realtid från ett stort antal källor. Tidsseriedatalager är optimerade för lagring av telemetridata. Scenarierna omfattar IoT-sensorer eller program-/systemräknare. Uppdateringar sker sällan och borttagningar utförs ofta som massåtgärder.
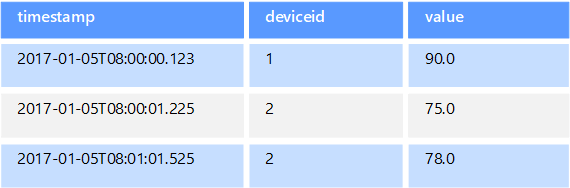
Även om de poster som skrivs till en tidsseriedatabas normalt är små finns det ofta ett stort antal poster, och den totala datamängden kan växa snabbt. Tidsseriedatalager hanterar också oordnade och försenade data, automatisk indexering av datapunkter och optimeringar för frågor som beskrivs i termer av tidsfönster. Den här sista funktionen gör det möjligt för frågor att köras över miljontals datapunkter och flera dataströmmar snabbt, för att stödja tidsserievisualiseringar, vilket är ett vanligt sätt att använda tidsseriedata.
Relevanta Azure-tjänster:
Objektdatalager
Objektdatalager är optimerade för lagring och hämtning av stora binära objekt eller blobbar som bilder, textfiler, video- och ljudströmmar, stora programdataobjekt och dokument samt diskbilder för virtuella datorer. Ett objekt består av lagrade data, vissa metadata och ett unikt ID för åtkomst till objektet. Objektlager är utformade för att stödja filer som är individuellt mycket stora och ger stora mängder total lagring för att hantera alla filer.
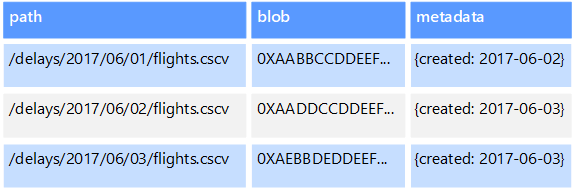
Vissa objektdatalager replikerar en viss blob över flera servernoder, vilket möjliggör snabba parallella läsningar. Den här processen möjliggör i sin tur utskalningsfråga för data som finns i stora filer, eftersom flera processer, som vanligtvis körs på olika servrar, kan köra frågor mot den stora datafilen samtidigt.
Ett specialfall för objektdatalager är nätverksfilresursen. Med hjälp av filresurser kan filer nås i ett nätverk med hjälp av standardnätverksprotokoll som SMB (Server Message Block). Med lämpliga mekanismer för säkerhet och samtidig åtkomstkontroll kan delning av data på det här sättet göra det möjligt för distribuerade tjänster att ge mycket skalbar dataåtkomst för grundläggande åtgärder på låg nivå, till exempel enkla läs- och skrivbegäranden.
Relevanta Azure-tjänster:
Externa indexdatalager
Externa indexdatalager ger möjlighet att söka efter information som finns i andra datalager och tjänster. Ett externt index fungerar som ett sekundärt index för alla datalager och kan användas för att indexering av stora mängder data och ge nästan realtidsåtkomst till dessa index.
Du kan till exempel ha textfiler lagrade i ett filsystem. Det går snabbt att hitta en fil efter dess filsökväg, men sökning baserat på innehållet i filen kräver en genomsökning av alla filer, vilket är långsamt. Med ett externt index kan du skapa sekundära sökindex och sedan snabbt hitta sökvägen till de filer som matchar dina villkor. Ett annat exempel på ett externt index är med nyckel-/värdelager som endast indexeras av nyckeln. Du kan skapa ett sekundärt index baserat på värdena i data och snabbt leta upp nyckeln som unikt identifierar varje matchat objekt.
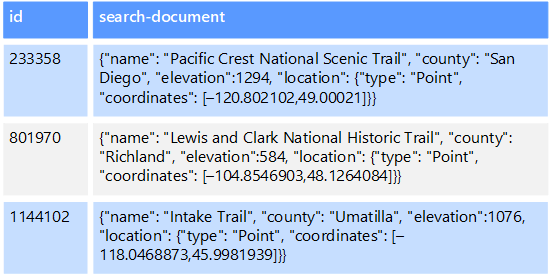
Indexen skapas genom att en indexeringsprocess körs. Detta kan utföras med hjälp av en pull-modell, som utlöses av datalagret eller med hjälp av en push-modell som initieras av programkoden. Index kan vara flerdimensionella och kan ha stöd för fritextsökningar över stora mängder textdata.
Externa indexdatalager används ofta för att stödja fulltext och webbaserad sökning. I dessa fall kan sökningen vara exakt eller suddig. En fuzzy-sökning söker efter dokument som matchar en uppsättning villkor och beräknar hur väl de matchar. Vissa externa index stöder också språklig analys som kan returnera matchningar baserat på synonymer, genreexpansioner (till exempel matchning av "hundar" till "husdjur") och härstamning (till exempel att söka efter "körning" matchar även "ran" och "running").
Relevant Azure-tjänst:
Vanliga krav
Icke-relationsdatalager använder ofta en annan lagringsarkitektur än den som används av relationsdatabaser. Mer specifikt tenderar de att inte ha något fast schema. Dessutom tenderar de att inte stödja transaktioner, eller begränsa transaktionsomfånget, och de inkluderar vanligtvis inte sekundära index av skalbarhetsskäl.
Jämfört med många traditionella relationsdatabaser erbjuder NoSQL-databaser ofta en önskvärd nivå av schemaflexitet och plattformsskalbarhet, men ibland kommer dessa fördelar på bekostnad av svagare konsekvens. Även om du kan lagra dina data flexibelt måste du fortfarande identifiera och analysera dina dataåtkomstmönster och sedan utforma ett lämpligt dataschema, annars kan NoSQL-databasen drabbas av tung arbetsbelastning eller oväntade användningsmönster.
Följande jämför kraven för vart och ett av de icke-relationella datalager:
| Krav | Dokumentdata | Kolumnfamiljedata | Nyckel/värde-data | Diagramdata |
|---|---|---|---|---|
| Normalisering | Avnormaliserad | Avnormaliserad | Avnormaliserad | Normaliserade |
| Schema | Schema vid läsning | Kolumnfamiljer som definierats vid skrivning, kolumnschema vid läsning | Schema vid läsning | Schema vid läsning |
| Konsekvens (mellan samtidiga transaktioner) | Justerbar konsekvens, garantier på dokumentnivå | Garantier på kolumnfamiljenivå | Garantier på nyckelnivå | Garantier på grafnivå |
| Atomicitet (transaktionsomfång) | Samling | Register | Register | Diagram |
| Låsningsstrategi | Optimistisk (låsfritt) | Pessimistisk (radlås) | Optimistisk (entitetstagg (ETag)) | |
| Åtkomstmönster | Slumpmässig åtkomst | Aggregerar på långa/breda data | Slumpmässig åtkomst | Slumpmässig åtkomst |
| Indexering | Primära och sekundära index | Primära och sekundära index | Endast primärt index | Primära och sekundära index |
| Dataform | Dokument | Tabell med kolumnfamiljer som innehåller kolumner | Nyckel och värde | Diagram som innehåller kanter och hörn |
| Utspridda | Ja | Ja | Ja | Nej |
| Bred (många kolumner/attribut) | Ja | Ja | Nej | Nej |
| Datumstorlek | Små (KBs) till medel (låga MBs) | Medel (MBs) till Stor (låg GBs) | Små (KBS) | Små (KBS) |
| Total maximal skala | Mycket stor (PBs) | Mycket stor (PBs) | Mycket stor (PBs) | Stor (TB) |
| Krav | Tidsseriedata | Objektdata | Externa indexdata |
|---|---|---|---|
| Normalisering | Normaliserade | Avnormaliserad | Avnormaliserad |
| Schema | Schema vid läsning | Schema vid läsning | Schema vid skrivning |
| Konsekvens (mellan samtidiga transaktioner) | Saknas | Saknas | Saknas |
| Atomicitet (transaktionsomfång) | Ej tillämpligt | Objekt | Ej tillämpligt |
| Låsningsstrategi | Ej tillämpligt | Pessimistisk (bloblås) | Ej tillämpligt |
| Åtkomstmönster | Slumpmässig åtkomst och aggregering | Sekventiell åtkomst | Slumpmässig åtkomst |
| Indexering | Primära och sekundära index | Endast primärt index | Ej tillämpligt |
| Dataform | Tabell | Blob och metadata | Dokument |
| Utspridda | Nej | Ej tillämpligt | Nej |
| Bred (många kolumner/attribut) | Nej | Ja | Ja |
| Datumstorlek | Små (KBS) | Stora (GBs) till mycket stora (TBs) | Små (KBS) |
| Total maximal skala | Stor (låg TB) | Mycket stor (PBs) | Stor (låg TB) |
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Zoiner Tejada | VD och arkitekt
Nästa steg
- Relationsdata jämfört med NoSQL-data
- Förstå distribuerade NoSQL-databaser
- Grunderna i Microsoft Azure-data: Utforska icke-relationella data i Azure
- Implementera en datamodell som inte är relationell