Arkitekturmetoder för AI och ML i lösningar för flera klientorganisationer
Ett ständigt ökande antal lösningar för flera klientorganisationer bygger på artificiell intelligens (AI) och maskininlärning (ML). En AI/ML-lösning för flera klienter är en lösning som ger liknande ML-baserade funktioner till valfritt antal klienter. Klientorganisationer kan vanligtvis inte se eller dela data för någon annan klientorganisation, men i vissa situationer kan klientorganisationer använda samma modeller som andra klientorganisationer.
Ai-/ML-arkitekturer med flera klientorganisationer måste beakta kraven för data och modeller, samt de beräkningsresurser som krävs för att träna modeller och utföra slutsatsdragning från modeller. Det är viktigt att tänka på hur AI/ML-modeller med flera klientorganisationer distribueras, distribueras och orkestreras och ser till att din lösning är korrekt, tillförlitlig och skalbar.
Eftersom generativa AI-tekniker, som drivs av både stora och små språkmodeller, blir populärare, är det viktigt att upprätta effektiva operativa metoder och strategier för att hantera dessa modeller i produktionsmiljöer genom införandet av Mašinsko učenje Operations (MLOps) och GenAIOps (kallas ibland LLMOps).
Viktiga överväganden och krav
När du arbetar med AI och ML är det viktigt att du separat överväger dina krav för utbildning och slutsatsdragning. Syftet med träningen är att skapa en förutsägelsemodell som baseras på en uppsättning data. Du utför slutsatsdragning när du använder modellen för att förutsäga något i ditt program. Var och en av dessa processer har olika krav. I en lösning med flera klientorganisationer bör du överväga hur din innehavarmodell påverkar varje process. Med tanke på vart och ett av dessa krav kan du se till att din lösning ger korrekta resultat, presterar bra under belastning, är kostnadseffektiv och kan skala för din framtida tillväxt.
Isolering av klientorganisation
Se till att klientorganisationer inte får obehörig eller oönskad åtkomst till data eller modeller för andra klienter. Behandla modeller med en liknande känslighet som de rådata som har tränat dem. Se till att dina klienter förstår hur deras data används för att träna modeller och hur modeller som tränats på andra klientorganisationers data kan användas i slutsatsdragningssyfte för deras arbetsbelastningar.
Det finns tre vanliga metoder för att arbeta med ML-modeller i lösningar för flera klienter: klientspecifika modeller, delade modeller och anpassade delade modeller.
Klientspecifika modeller
Klientspecifika modeller tränas endast på data för en enda klientorganisation, och sedan tillämpas de på den enskilda klientorganisationen. Klientspecifika modeller är lämpliga när klientorganisationens data är känsliga, eller när det finns lite omfång för att lära sig av de data som tillhandahålls av en klientorganisation, och du tillämpar modellen på en annan klientorganisation. Följande diagram visar hur du kan skapa en lösning med klientspecifika modeller för två klientorganisationer:
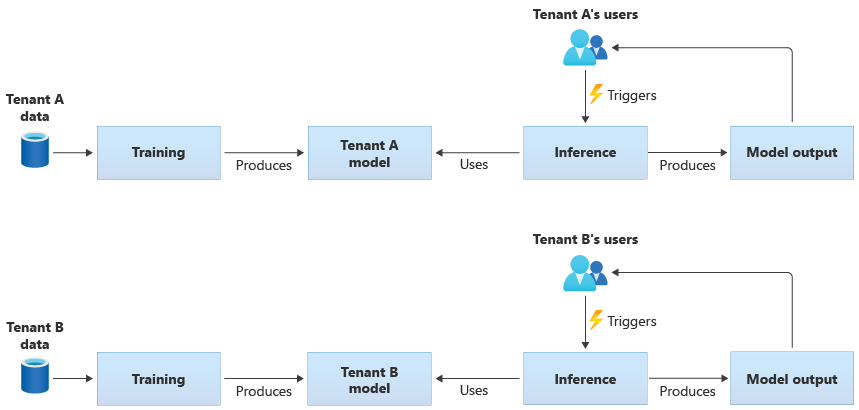
Delade modeller
I lösningar som använder delade modeller utför alla klienter slutsatsdragning baserat på samma delade modell. Delade modeller kan vara förtränad modeller som du skaffar eller hämtar från en community-källa. Följande diagram visar hur en enskild förtränad modell kan användas för slutsatsdragning av alla klienter:
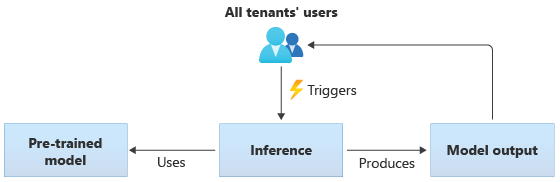
Du kan också skapa egna delade modeller genom att träna dem från de data som tillhandahålls av alla dina klienter. Följande diagram illustrerar en enda delad modell som tränas på data från alla klienter:
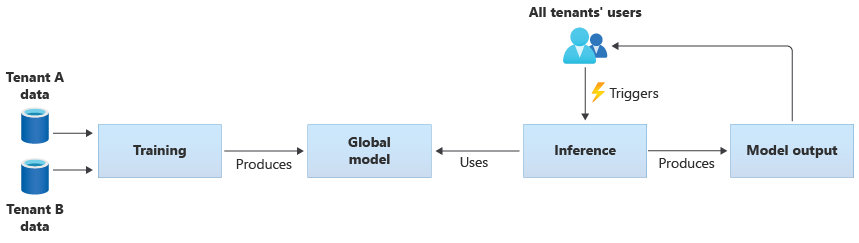
Viktigt!
Om du tränar en delad modell från klientorganisationens data kontrollerar du att dina klienter förstår och godkänner användningen av deras data. Se till att identifierande information tas bort från klientorganisationens data.
Tänk på vad du ska göra om en klientorganisation motsätter sig att deras data används för att träna en modell som ska tillämpas på en annan klientorganisation. Skulle du till exempel kunna exkludera specifika klientorganisationers data från träningsdatauppsättningen?
Anpassade delade modeller
Du kan också välja att skaffa en förtränad basmodell och sedan utföra ytterligare modelljustering för att göra den tillämplig för var och en av dina klienter, baserat på deras egna data. Följande diagram illustrerar den här metoden:
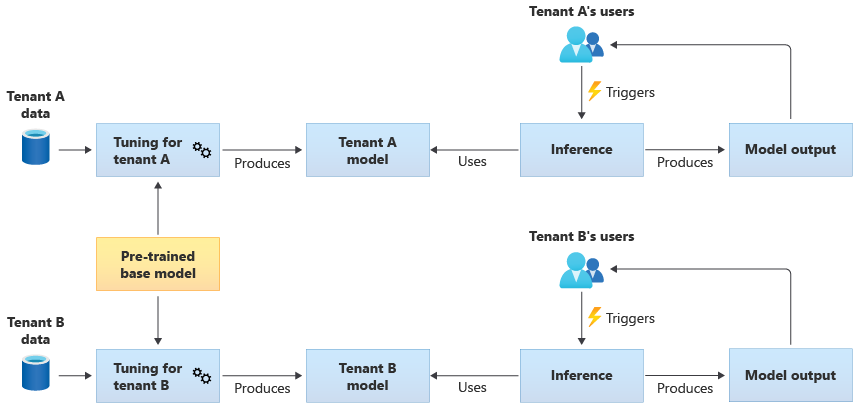
Skalbarhet
Tänk på hur din lösnings tillväxt påverkar din användning av AI- och ML-komponenter. Tillväxt kan referera till en ökning av antalet klienter, mängden data som lagras för varje klientorganisation, antalet användare och mängden begäranden till din lösning.
Utbildning: Det finns flera faktorer som påverkar de resurser som krävs för att träna dina modeller. Dessa faktorer inkluderar antalet modeller som du behöver träna, mängden data som du tränar modellerna med och hur ofta du tränar eller tränar modeller. Om du skapar klientspecifika modeller kommer mängden beräkningsresurser och lagringsutrymme som du behöver att öka när antalet klienter växer. Om du skapar delade modeller och tränar dem baserat på data från alla dina klienter är det mindre troligt att resurserna för träning skalas i samma takt som ökningen av antalet klienter. En ökning av den totala mängden träningsdata påverkar dock de resurser som förbrukas för att träna både de delade och klientspecifika modellerna.
Slutsatsdragning: De resurser som krävs för slutsatsdragning är vanligtvis proportionella mot antalet begäranden som kommer åt modellerna för slutsatsdragning. I takt med att antalet klienter ökar kommer antalet begäranden sannolikt också att öka.
Det är en bra allmän praxis att använda Azure-tjänster som skalar bra. Eftersom AI/ML-arbetsbelastningar tenderar att använda containrar tenderar Azure Kubernetes Service (AKS) och Azure Container Instances (ACI) att vara vanliga val för AI/ML-arbetsbelastningar. AKS är vanligtvis ett bra val för att aktivera hög skala och att dynamiskt skala dina beräkningsresurser baserat på efterfrågan. För små arbetsbelastningar kan ACI vara en enkel beräkningsplattform att konfigurera, även om den inte skalas lika enkelt som AKS.
Prestanda
Överväg prestandakraven för AI/ML-komponenterna i din lösning för både träning och slutsatsdragning. Det är viktigt att klargöra dina svarstider och prestandakrav för varje process, så att du kan mäta och förbättra efter behov.
Utbildning: Träning utförs ofta som en batchprocess, vilket innebär att den kanske inte är lika prestandakänslig som andra delar av din arbetsbelastning. Du måste dock se till att du etablerar tillräckligt med resurser för att utföra modellträningen effektivt, inklusive när du skalar.
Slutsatsdragning: Slutsatsdragning är en svarstidskänslig process som ofta kräver ett snabbt eller till och med realtidssvar. Även om du inte behöver utföra slutsatsdragning i realtid kontrollerar du att du övervakar lösningens prestanda och använder lämpliga tjänster för att optimera din arbetsbelastning.
Överväg att använda Azures högpresterande databehandlingsfunktioner för dina AI- och ML-arbetsbelastningar. Azure tillhandahåller många olika typer av virtuella datorer och andra maskinvaruinstanser. Fundera på om din lösning skulle ha nytta av att använda processorer, GPU:er, FPGA eller andra maskinvaruaccelererade miljöer. Azure tillhandahåller även slutsatsdragning i realtid med NVIDIA-GPU:er, inklusive NVIDIA Triton-slutsatsdragningsservrar. För beräkningskrav med låg prioritet bör du överväga att använda AKS-skalningsnodpooler för oanvänd kapacitet. Mer information om hur du optimerar beräkningstjänster i en lösning med flera klientorganisationer finns i Arkitekturmetoder för beräkning i lösningar för flera klientorganisationer.
Modellträning kräver vanligtvis många interaktioner med dina datalager, så det är också viktigt att tänka på din datastrategi och de prestanda som datanivån ger. Mer information om multitenancy- och datatjänster finns i Arkitekturmetoder för lagring och data i lösningar för flera klientorganisationer.
Överväg att profilera lösningens prestanda. Azure Mašinsko učenje tillhandahåller till exempel profileringsfunktioner som du kan använda när du utvecklar och instrumenterar din lösning.
Implementeringskomplexitet
När du skapar en lösning för att använda AI och ML kan du välja att använda fördefinierade komponenter eller skapa anpassade komponenter. Det finns två viktiga beslut som du måste fatta. Den första är den plattform eller tjänst som du använder för AI och ML. Det andra är om du använder förtränad modeller eller skapar egna anpassade modeller.
Plattformar: Det finns många Azure-tjänster som du kan använda för dina AI- och ML-arbetsbelastningar. Till exempel tillhandahåller Azure AI Services och Azure OpenAI Service API:er för att utföra slutsatsdragning mot fördefinierade modeller och Microsoft hanterar de underliggande resurserna. Med Azure AI Services kan du snabbt distribuera en ny lösning, men det ger dig mindre kontroll över hur träning och slutsatsdragning utförs, och det kanske inte passar alla typer av arbetsbelastningar. Azure Mašinsko učenje är däremot en plattform där du kan skapa, träna och använda dina egna ML-modeller. Azure Mašinsko učenje ger kontroll och flexibilitet, men det ökar komplexiteten i din design och implementering. Granska maskininlärningsprodukter och tekniker från Microsoft för att fatta ett välgrundat beslut när du väljer en metod.
Modeller: Även om du inte använder en fullständig modell som tillhandahålls av en tjänst som Azure AI Services, kan du fortfarande påskynda utvecklingen med hjälp av en förtränad modell. Om en förtränad modell inte exakt passar dina behov kan du överväga att utöka en förtränad modell genom att använda en teknik som kallas överföringsinlärning eller finjustering. Med överföringsinlärning kan du utöka en befintlig modell och tillämpa den på en annan domän. Om du till exempel skapar en tjänst för musikrekommendationstjänsten för flera klientorganisationer kan du överväga att bygga upp en förtränad modell med musikrekommendationer och använda överföringsinlärning för att träna modellen för en specifik användares musikinställningar.
Genom att använda en fördefinierad ML-plattform som Azure AI Services eller Azure OpenAI Service, eller en förtränad modell, kan du avsevärt minska dina initiala kostnader för forskning och utveckling. Användningen av fördefinierade plattformar kan spara många månaders forskning och undvika behovet av att rekrytera högkvalificerade dataforskare för att träna, utforma och optimera modeller.
Kostnadsoptimering
I allmänhet medför AI- och ML-arbetsbelastningar den största andelen av deras kostnader från de beräkningsresurser som krävs för modellträning och slutsatsdragning. Granska arkitekturmetoder för beräkning i lösningar med flera klientorganisationer för att förstå hur du optimerar kostnaden för din beräkningsarbetsbelastning för dina behov.
Tänk på följande krav när du planerar dina AI- och ML-kostnader:
- Fastställa beräknings-SKU:er för träning. Se till exempel vägledning om hur du gör detta med Azure Mašinsko učenje.
- Fastställa beräknings-SKU:er för slutsatsdragning. Ett exempel på en kostnadsuppskattning för slutsatsdragning finns i vägledningen för Azure Mašinsko učenje.
- Övervaka din användning. Genom att observera användningen av dina beräkningsresurser kan du avgöra om du ska minska eller öka deras kapacitet genom att distribuera olika SKU:er eller skala beräkningsresurserna när dina krav ändras. Se Azure Mašinsko učenje Monitor.
- Optimera din beräkningsklustermiljö. När du använder beräkningskluster övervakar du klusteranvändningen eller konfigurerar automatisk skalning för att skala ned beräkningsnoder.
- Dela dina beräkningsresurser. Fundera på om du kan optimera kostnaden för dina beräkningsresurser genom att dela dem mellan flera klienter.
- Tänk på din budget. Förstå om du har en fast budget och övervaka din förbrukning i enlighet med detta. Du kan konfigurera budgetar för att förhindra överförbrukning och allokera kvoter baserat på klientprioritet.
Metoder och mönster att tänka på
Azure tillhandahåller en uppsättning tjänster för att aktivera AI- och ML-arbetsbelastningar. Det finns flera vanliga arkitekturmetoder som används i lösningar med flera klientorganisationer: för att använda fördefinierade AI/ML-lösningar, för att skapa en anpassad AI/ML-arkitektur med hjälp av Azure Mašinsko učenje och för att använda en av Azure-analysplattformarna.
Använda fördefinierade AI/ML-tjänster
Det är en bra idé att försöka använda fördefinierade AI/ML-tjänster, där du kan. Din organisation kanske till exempel börjar titta på AI/ML och vill snabbt integrera med en användbar tjänst. Eller så kan du ha grundläggande krav som inte kräver anpassad ML-modellträning och utveckling. Med fördefinierade ML-tjänster kan du använda slutsatsdragning utan att skapa och träna dina egna modeller.
Azure tillhandahåller flera tjänster som tillhandahåller AI- och ML-teknik i en rad olika domäner, inklusive språktolkning, taligenkänning, kunskap, dokument- och formulärigenkänning samt visuellt innehåll. Azures fördefinierade AI/ML-tjänster omfattar Azure AI Services, Azure OpenAI Service, Azure AI Search och Azure AI Document Intelligence. Varje tjänst tillhandahåller ett enkelt gränssnitt för integrering och en samling förtränad och testade modeller. Som hanterade tjänster tillhandahåller de serviceavtal och kräver lite konfiguration eller löpande hantering. Du behöver inte utveckla eller testa dina egna modeller för att använda dessa tjänster.
Många hanterade ML-tjänster kräver inte modellträning eller data, så det finns vanligtvis inga problem med klientdataisolering. Men när du arbetar med AI Search i en lösning med flera klienter kan du läsa Designmönster för SaaS-program med flera klienter och Azure AI Search.
Överväg skalningskraven för komponenterna i din lösning. Till exempel stöder många av API:erna i Azure AI Services ett maximalt antal begäranden per sekund. Om du distribuerar en enda AI Services-resurs att dela mellan dina klienter kan du behöva skala till flera resurser när antalet klienter ökar.
Kommentar
Vissa hanterade tjänster gör att du kan träna med dina egna data, inklusive Custom Vision-tjänsten, ansikts-API:et, anpassade modeller för dokumentinformation och vissa OpenAI-modeller som stöder anpassning och fin tunning. När du arbetar med dessa tjänster är det viktigt att tänka på isoleringskraven för klientorganisationens data.
Anpassad AI/ML-arkitektur
Om din lösning kräver anpassade modeller eller om du arbetar i en domän som inte omfattas av en hanterad ML-tjänst kan du överväga att skapa en egen AI/ML-arkitektur. Azure Mašinsko učenje tillhandahåller en uppsättning funktioner för att samordna träning och distribution av ML-modeller. Azure Machine Learning stöder många maskininlärningsbibliotek med öppen källkod, bland annat PyTorch, TensorFlow, Scikitoch Keras. Du kan kontinuerligt övervaka modellers prestandamått, identifiera dataavvikelser och utlösa omträning för att förbättra modellens prestanda. Under hela livscykeln för dina ML-modeller möjliggör Azure Mašinsko učenje granskning och styrning med inbyggd spårning och ursprung för alla dina ML-artefakter.
När du arbetar i en lösning med flera klienter är det viktigt att tänka på isoleringskraven för dina klienter under både utbildnings- och inferensstegen. Du måste också bestämma din modelltränings- och distributionsprocess. Azure Mašinsko učenje tillhandahåller en pipeline för att träna modeller och distribuera dem till en miljö som ska användas för slutsatsdragning. I en kontext med flera klienter bör du överväga om modeller ska distribueras till delade beräkningsresurser eller om varje klientorganisation har dedikerade resurser. Utforma dina modelldistributionspipelines baserat på din isoleringsmodell och klientdistributionsprocessen.
När du använder modeller med öppen källkod kan du behöva träna om dessa modeller med hjälp av överföringsinlärning eller justering. Fundera på hur du ska hantera de olika modellerna och träningsdata för varje klientorganisation samt versioner av modellen.
Följande diagram illustrerar en exempelarkitektur som använder Azure Mašinsko učenje. I exemplet används isoleringsmetoden för klientspecifika modeller .
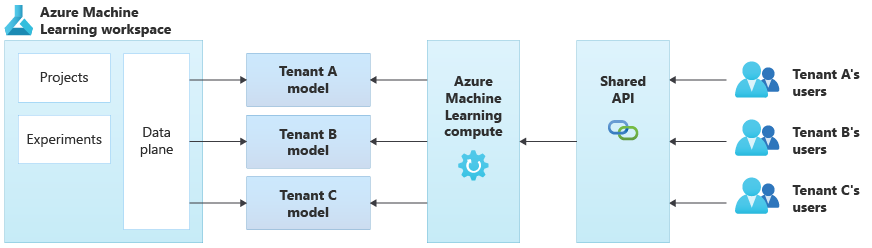
Integrerade AI/ML-lösningar
Azure tillhandahåller flera kraftfulla analysplattformar som kan användas för en rad olika syften. Dessa plattformar inkluderar Azure Synapse Analytics, Databricks och Apache Spark.
Du kan överväga att använda dessa plattformar för AI/ML när du behöver skala dina ML-funktioner till ett mycket stort antal klienter och när du behöver storskalig beräkning och orkestrering. Du kan också överväga att använda dessa plattformar för AI/ML när du behöver en bred analysplattform för andra delar av din lösning, till exempel för dataanalys och integrering med rapportering via Microsoft Power BI. Du kan distribuera en enda plattform som täcker alla dina analys- och AI/ML-behov. När du implementerar dataplattformar i en lösning med flera klientorganisationer kan du läsa Arkitekturmetoder för lagring och data i lösningar med flera klientorganisationer.
ML-driftsmodell
När du använder AI och maskininlärning, inklusive generativa AI-metoder, är det en bra idé att kontinuerligt förbättra och utvärdera organisationens funktioner i hanteringen av dem. Introduktionen av MLOps och GenAIOps ger objektivt ett ramverk för att kontinuerligt utöka funktionerna i dina AI- och ML-metoder i din organisation. Mer vägledning finns i dokumenten MLOps Maturity Model och LLMOps Maturity Model .
Antimönster att undvika
- Det gick inte att överväga isoleringskrav. Det är viktigt att noga överväga hur du isolerar klientorganisationens data och modeller, både för träning och slutsatsdragning. Om du inte gör det kan det strida mot juridiska eller avtalsmässiga krav. Det kan också minska noggrannheten för dina modeller att träna över flera klientorganisationers data, om data skiljer sig avsevärt.
- Bullriga grannar. Fundera på om dina träning- eller slutsatsdragningsprocesser kan omfattas av problemet Med bullriga grannar. Om du till exempel har flera stora klienter och en enda liten klientorganisation kontrollerar du att modellträningen för de stora klienterna inte oavsiktligt förbrukar alla beräkningsresurser och svälter de mindre klientorganisationer. Använd resursstyrning och övervakning för att minska risken för en klients beräkningsarbetsbelastning som påverkas av aktiviteten hos de andra klienterna.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Kevin Ashley | Senior kundtekniker, FastTrack för Azure
Övriga medarbetare:
- Paul Burpo | Huvudkundtekniker, FastTrack för Azure
- John Downs | Huvudprogramtekniker
- Daniel Scott-Raynsford | Partnerteknikstrateg
- Arsen Vladimirskiy | Huvudkundtekniker, FastTrack för Azure
- Vic Perdana | Lösningsarkitekt för ISV-partner
Nästa steg
- Granska arkitekturmetoder för beräkning i lösningar för flera klientorganisationer.
- Mer information om hur du utformar Azure Mašinsko učenje pipelines för att stödja flera klientorganisationer finns i En lösning för ML-pipeline på flera innehavare.