Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Cosmos DB
Händelsehubbar för Azure
Azure Monitor
Azure Stream Analytics
Den här referensarkitekturen visar en dataströmbearbetningspipeline från slutpunkt till slutpunkt. Pipelinen matar in data från två källor, korrelerar poster i de två strömmarna och beräknar ett rullande medelvärde över ett tidsfönster. Resultaten lagras för ytterligare analys.
Arkitektur

Ladda ned en Visio-fil med den här arkitekturen.
Arbetsflöde
Arkitekturen består av följande komponenter:
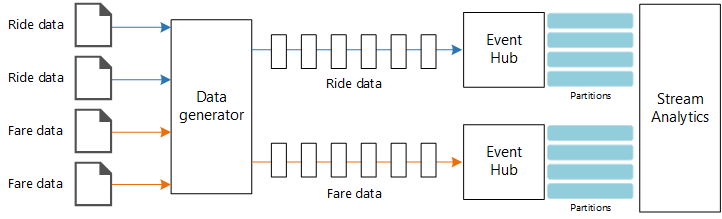
Datakällor. I den här arkitekturen finns det två datakällor som genererar dataströmmar i realtid. Den första strömmen innehåller färdinformation och den andra innehåller information om priser. Referensarkitekturen innehåller en simulerad datagenerator som läser från en uppsättning statiska filer och skickar data till Event Hubs. I ett verkligt program skulle datakällorna vara enheter installerade i taxibilarna.
Azure Event Hubs. Event Hubs är en händelseinmatningstjänst . Den här arkitekturen använder två händelsehubbinstanser, en för varje datakälla. Varje datakälla skickar en dataström till den associerade händelsehubben.
Azure Stream Analytics. Stream Analytics är en motor för händelsebearbetning. Ett Stream Analytics-jobb läser dataströmmarna från de två händelsehubbarna och utför dataströmbearbetning.
Azure Cosmos DB. Utdata från Stream Analytics-jobbet är en serie poster som skrivs som JSON-dokument till en Azure Cosmos DB-dokumentdatabas.
Microsoft Power BI. Power BI är en uppsättning affärsanalysverktyg för att analysera data för affärsinsikter. I den här arkitekturen läser den in data från Azure Cosmos DB. På så sätt kan användarna analysera den fullständiga uppsättningen historiska data som har samlats in. Du kan också strömma resultatet direkt från Stream Analytics till Power BI för en realtidsvy av data. Mer information finns i Realtidsströmning i Power BI.
Azure Monitor. Azure Monitor samlar in prestandamått om de Azure-tjänster som distribueras i lösningen. Genom att visualisera dessa på en instrumentpanel kan du få insikter om lösningens hälsotillstånd.
Information om scenario
Scenario: Ett taxiföretag samlar in data om varje taxiresa. I det här scenariot antar vi att det finns två separata enheter som skickar data. Taxin har en mätare som skickar information om varje resa – varaktighet, avstånd och upphämtnings- och avlämningsplatser. En separat enhet accepterar betalningar från kunder och skickar data om priser. Taxibolaget vill beräkna den genomsnittliga dricksen per körd mil i realtid för att upptäcka trender.
Potentiella användningsfall
Den här lösningen är optimerad för detaljhandelsscenariot.
Datainsamling
För att simulera en datakälla använder den här referensarkitekturen datauppsättningen New York City Taxi Data[1]. Den här datamängden innehåller data om taxiresor i New York City under en fyraårsperiod (2010–2013). Den innehåller två typer av poster: kördata och prisdata. Ride-data inkluderar resans varaktighet, reseavstånd och upphämtnings- och avlämningsplats. Prisdata inkluderar belopp för biljettpriser, skatter och tips. Vanliga fält i båda posttyperna är medaljongnummer, hacklicens och leverantörs-ID. Tillsammans identifierar dessa tre fält unikt en taxi plus en förare. Data lagras i CSV-format.
[1] Donovan, Brian; Arbete, Dan (2016): Data om taxiresor i New York City (2010-2013). University of Illinois vid Urbana-Champaign. https://doi.org/10.13012/J8PN93H8
Datageneratorn är ett .NET Core-program som läser posterna och skickar dem till Azure Event Hubs. Generatorn skickar kördata i JSON-format och prisdata i CSV-format.
Event Hubs använder partitioner för att segmentera data. Med partitioner kan en konsument läsa varje partition parallellt. När du skickar data till Event Hubs kan du uttryckligen ange partitionsnyckeln. I annat fall tilldelas poster till partitioner i resursallokering.
I det här scenariot bör kördata och prisdata få samma partitions-ID för en viss taxi. Detta gör det möjligt för Stream Analytics att tillämpa en grad av parallellitet när det korrelerar de två strömmarna. En post i partition n av kördata matchar en post i partition n av prisdata.
I datageneratorn har den gemensamma datamodellen för båda posttyperna en PartitionKey egenskap som är sammanlänkningen av Medallion, HackLicenseoch VendorId.
public abstract class TaxiData
{
public TaxiData()
{
}
[JsonProperty]
public long Medallion { get; set; }
[JsonProperty]
public long HackLicense { get; set; }
[JsonProperty]
public string VendorId { get; set; }
[JsonProperty]
public DateTimeOffset PickupTime { get; set; }
[JsonIgnore]
public string PartitionKey
{
get => $"{Medallion}_{HackLicense}_{VendorId}";
}
Den här egenskapen används för att tillhandahålla en explicit partitionsnyckel när du skickar till Event Hubs:
using (var client = pool.GetObject())
{
return client.Value.SendAsync(new EventData(Encoding.UTF8.GetBytes(
t.GetData(dataFormat))), t.PartitionKey);
}
Dataströmbearbetning
Dataströmbearbetningsjobbet definieras med hjälp av en SQL-fråga med flera olika steg. De första två stegen väljer poster från de två indataströmmarna.
WITH
Step1 AS (
SELECT PartitionId,
TRY_CAST(Medallion AS nvarchar(max)) AS Medallion,
TRY_CAST(HackLicense AS nvarchar(max)) AS HackLicense,
VendorId,
TRY_CAST(PickupTime AS datetime) AS PickupTime,
TripDistanceInMiles
FROM [TaxiRide] PARTITION BY PartitionId
),
Step2 AS (
SELECT PartitionId,
medallion AS Medallion,
hack_license AS HackLicense,
vendor_id AS VendorId,
TRY_CAST(pickup_datetime AS datetime) AS PickupTime,
tip_amount AS TipAmount
FROM [TaxiFare] PARTITION BY PartitionId
),
I nästa steg kopplas de två indataströmmarna till att välja matchande poster från varje ström.
Step3 AS (
SELECT tr.TripDistanceInMiles,
tf.TipAmount
FROM [Step1] tr
PARTITION BY PartitionId
JOIN [Step2] tf PARTITION BY PartitionId
ON tr.PartitionId = tf.PartitionId
AND tr.PickupTime = tf.PickupTime
AND DATEDIFF(minute, tr, tf) BETWEEN 0 AND 15
)
Den här frågan kopplar poster till en uppsättning fält som unikt identifierar matchande poster (PartitionId och PickupTime).
Kommentar
Vi vill att strömmarna TaxiRide och TaxiFare ska kopplas av den unika kombinationen av Medallion, HackLicenseVendorId och PickupTime. I det här fallet PartitionId omfattar fälten Medallion, HackLicense och VendorId , men detta bör inte tas som vanligt.
I Stream Analytics är kopplingarna tidsmässiga, vilket innebär att poster kopplas inom en viss tidsperiod. Annars kan jobbet behöva vänta på obestämd tid för en matchning. Funktionen DATEDIFF anger hur långt två matchande poster kan avgränsas i tid för en matchning.
Det sista steget i jobbet beräknar det genomsnittliga tipset per mil, grupperat efter ett hoppfönster på 5 minuter.
SELECT System.Timestamp AS WindowTime,
SUM(tr.TipAmount) / SUM(tr.TripDistanceInMiles) AS AverageTipPerMile
INTO [TaxiDrain]
FROM [Step3] tr
GROUP BY HoppingWindow(Duration(minute, 5), Hop(minute, 1))
Stream Analytics innehåller flera fönsterfunktioner. Ett hoppfönster flyttas framåt i tiden med en fast period, i det här fallet 1 minut per hopp. Resultatet är att beräkna ett glidande medelvärde under de senaste 5 minuterna.
I arkitekturen som visas här sparas bara resultatet av Stream Analytics-jobbet i Azure Cosmos DB. För ett stordatascenario bör du även överväga att använda Event Hubs Capture för att spara rådata i Azure Blob Storage. Om du behåller rådata kan du köra batchfrågor över dina historiska data vid senare tillfälle för att härleda nya insikter från data.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som kan användas för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Kostnadsoptimering
Kostnadsoptimering handlar om att titta på sätt att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i checklistan Designgranskning för kostnadsoptimering.
Normalt beräknar du kostnader med hjälp av priskalkylatorn för Azure. Här följer några överväganden för tjänster som används i den här referensarkitekturen.
Azure Stream Analytics
Azure Stream Analytics prissätts med det antal strömningsenheter (0,11 USD/timme) som krävs för att bearbeta data till tjänsten.
Stream Analytics kan vara dyrt om du inte bearbetar data i realtid eller små mängder data. För dessa användningsfall bör du överväga att använda Azure Functions eller Logic Apps för att flytta data från Azure Event Hubs till ett datalager.
Azure Event Hubs och Azure Cosmos DB
Information om kostnadsöverväganden för Azure Event Hubs och Azure Cosmos DB finns i referensarkitekturen Stream-bearbetning med Azure Databricks .
Operativ skicklighet
Operational Excellence omfattar de driftsprocesser som distribuerar ett program och håller det igång i produktion. Mer information finns i checklistan för Designgranskning för Operational Excellence.
Övervakning
Med alla dataströmbearbetningslösningar är det viktigt att övervaka systemets prestanda och hälsa. Azure Monitor samlar in mått och diagnostikloggar för De Azure-tjänster som används i arkitekturen. Azure Monitor är inbyggt i Azure-plattformen och kräver ingen ytterligare kod i ditt program.
Någon av följande varningssignaler indikerar att du bör skala ut relevant Azure-resurs:
- Event Hubs begränsar begäranden eller ligger nära den dagliga meddelandekvoten.
- Stream Analytics-jobbet använder konsekvent mer än 80 % av allokerade streamingenheter (SU).
- Azure Cosmos DB börjar begränsa begäranden.
Referensarkitekturen innehåller en anpassad instrumentpanel som distribueras till Azure Portal. När du har distribuerat arkitekturen kan du visa instrumentpanelen genom att öppna Azure Portal och välja TaxiRidesDashboard från listan över instrumentpaneler. Mer information om hur du skapar och distribuerar anpassade instrumentpaneler i Azure Portal finns i Skapa Azure-instrumentpaneler programmatiskt.
Följande bild visar instrumentpanelen efter att Stream Analytics-jobbet kördes i ungefär en timme.
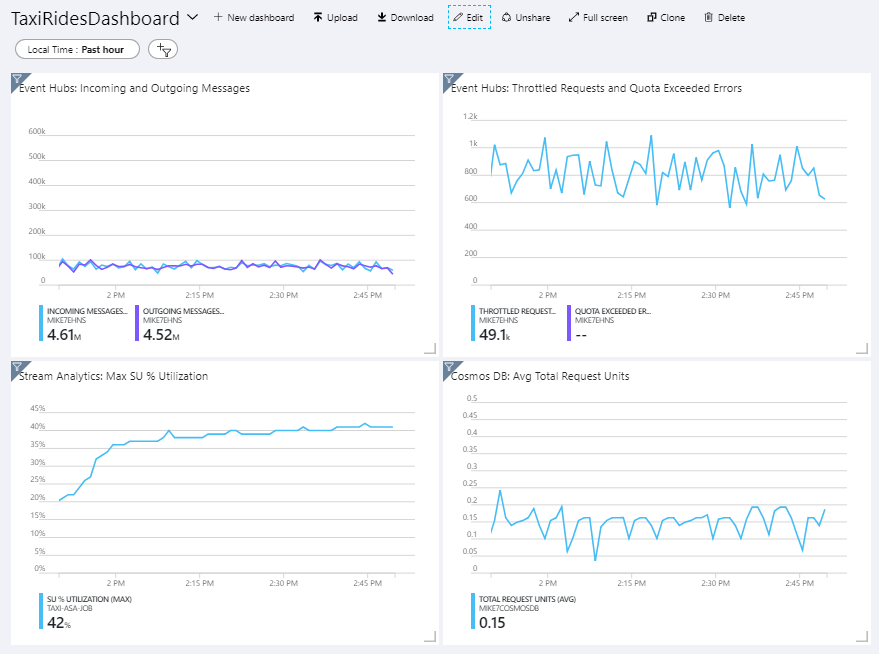
Panelen längst ned till vänster visar att SU-förbrukningen för Stream Analytics-jobbet ökar under de första 15 minuterna och sedan planar ut. Det här är ett typiskt mönster när jobbet når ett stabilt tillstånd.
Observera att Event Hubs begränsar begäranden, som visas i den övre högra panelen. En tillfällig strypningsbegäran är inte ett problem eftersom SDK:t för Event Hubs-klienten automatiskt försöker igen när den får ett strypningsfel. Men om du ser konsekventa begränsningsfel innebär det att händelsehubben behöver fler dataflödesenheter. I följande diagram visas en testkörning med funktionen För automatisk blåsning av Event Hubs, som automatiskt skalar ut dataflödesenheterna efter behov.
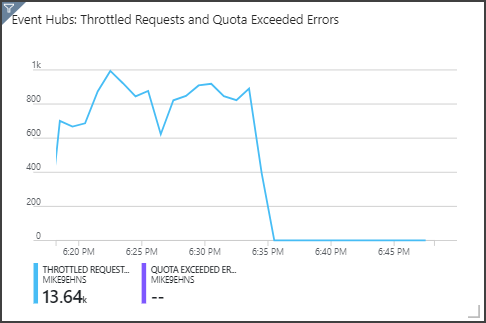
Automatisk blåsning aktiverades vid ungefär 06:35-märket. Du kan se p-minskningen av begränsade begäranden, eftersom Event Hubs automatiskt skalade upp till 3 dataflödesenheter.
Intressant nog hade detta sidoeffekten att öka SU-användningen i Stream Analytics-jobbet. Genom att begränsa minskade Event Hubs artificiellt inmatningshastigheten för Stream Analytics-jobbet. Det är faktiskt vanligt att lösa en prestandaflaskhals avslöjar en annan. I det här fallet löste allokeringen av ytterligare SU för Stream Analytics-jobbet problemet.
DevOps
Skapa separata resursgrupper för produktions-, utvecklings- och testmiljöer. Med separata resursgrupper blir det enklare att hantera distributioner, ta bort testdistributioner och tilldela åtkomsträttigheter.
Använd Azure Resource Manager-mallen för att distribuera Azure-resurserna efter IaC-processen (infrastruktur som kod). Med mallar är det enklare att automatisera distributioner med Hjälp av Azure DevOps Services eller andra CI/CD-lösningar.
Placera varje arbetsbelastning i en separat distributionsmall och lagra resurserna i källkontrollsystemen. Du kan distribuera mallarna tillsammans eller individuellt som en del av en CI/CD-process, vilket gör automatiseringsprocessen enklare.
I den här arkitekturen identifieras Azure Event Hubs, Log Analytics och Azure Cosmos DB som en enda arbetsbelastning. Dessa resurser ingår i en enda ARM-mall.
Överväg att mellanlagring av dina arbetsbelastningar. Distribuera till olika faser och kör valideringskontroller i varje steg innan du fortsätter till nästa steg. På så sätt kan du push-överföra uppdateringar till dina produktionsmiljöer på ett mycket kontrollerat sätt och minimera oväntade distributionsproblem.
Överväg att använda Azure Monitor för att analysera prestanda för din pipeline för dataströmbearbetning.
Mer information finns i grundpelare för driftskvalitet i Microsoft Azure Well-Architected Framework.
Prestandaeffektivitet
Prestandaeffektivitet är arbetsbelastningens förmåga att skala för att uppfylla användarnas krav på ett effektivt sätt. Mer information finns i checklistan för Designgranskning för prestandaeffektivitet.
Event Hubs
Dataflödeskapaciteten för Event Hubs mäts i dataflödesenheter. Du kan autoskala en händelsehubb genom att aktivera automatisk blåsning, vilket automatiskt skalar dataflödesenheterna baserat på trafik, upp till ett konfigurerat maxvärde.
Stream Analytics
För Stream Analytics mäts de databehandlingsresurser som allokerats till ett jobb i strömningsenheter. Stream Analytics-jobb skalas bäst om jobbet kan parallelliseras. På så sätt kan Stream Analytics distribuera jobbet över flera beräkningsnoder.
För Event Hubs-indata använder du nyckelordet PARTITION BY för att partitionering av Stream Analytics-jobbet. Data delas in i delmängder baserat på Event Hubs-partitionerna.
Fönsterfunktioner och tidsmässiga kopplingar kräver ytterligare SU. Använd när det är möjligt PARTITION BY så att varje partition bearbetas separat. Mer information finns i Förstå och justera strömningsenheter.
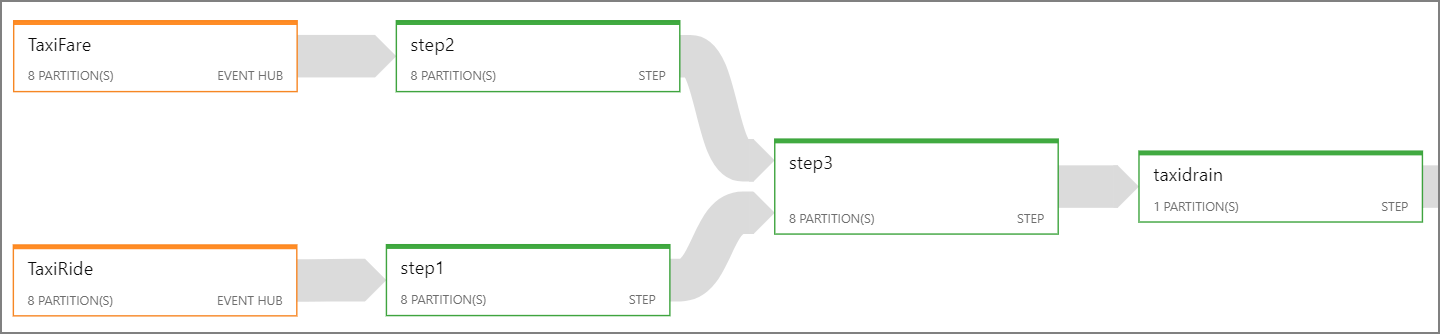
Om det inte går att parallellisera hela Stream Analytics-jobbet kan du försöka dela upp jobbet i flera steg, med början i ett eller flera parallella steg. På så sätt kan de första stegen köras parallellt. I den här referensarkitekturen kan du till exempel:
- Steg 1 och 2 är
SELECTinstruktioner som väljer poster inom en enda partition. - Steg 3 utför en partitionerad koppling mellan två indataströmmar. Det här steget utnyttjar det faktum att matchande poster delar samma partitionsnyckel och därför garanteras att ha samma partitions-ID i varje indataström.
- Steg 4 aggregeras över alla partitioner. Det här steget kan inte parallelliseras.
Använd Stream Analytics-jobbdiagrammet för att se hur många partitioner som tilldelas till varje steg i jobbet. Följande diagram visar jobbdiagrammet för den här referensarkitekturen:
Azure Cosmos DB
Dataflödeskapaciteten för Azure Cosmos DB mäts i enheter för programbegäran (RU:er). För att kunna skala en Azure Cosmos DB-container efter 10 000 RU måste du ange en partitionsnyckel när du skapar containern och inkludera partitionsnyckeln i varje dokument.
I den här referensarkitekturen skapas nya dokument bara en gång per minut (det hoppande fönstrets intervall), så dataflödeskraven är ganska låga. Därför behöver du inte tilldela en partitionsnyckel i det här scenariot.