Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Event Hubs är en skalbar händelsebearbetningstjänst som matar in och bearbetar stora mängder händelser och data, med låg svarstid och hög tillförlitlighet. En översikt över tjänsten finns i Vad är Event Hubs?.
Den här artikeln bygger på informationen i översiktsartikeln och innehåller teknisk information och implementeringsinformation om Event Hubs-komponenter och -funktioner.
Namnområde
Ett Event Hubs-namnområde är en hanteringscontainer för händelsehubbar (eller ämnen i Kafka-parlance). Den tillhandahåller DNS-integrerade nätverksslutpunkter och en rad funktioner för hantering av åtkomstkontroll och nätverksintegrering, till exempel IP-filtrering, tjänstslutpunkt för virtuellt nätverk och Private Link.

Partitioner
Event Hubs organiserar sekvenser av händelser som skickas till en händelsehubb till en eller flera partitioner. När nyare händelser kommer läggs de till i slutet av den här sekvensen.

En partition kan ses som en commit-logg. Partitioner innehåller händelsedata som innehåller följande information:
- Brödtext för händelsen
- Användardefinierad egenskapslista som beskriver händelsen
- Metadata, till exempel dess förskjutning i partitionen, dess nummer i strömsekvensen
- Tidsstämpel på tjänstsidan där den accepterades

Fördelar med att använda partitioner
Event Hubs är utformat för att hjälpa till med bearbetning av stora mängder händelser, och partitionering hjälper till med detta på två sätt:
- Även om Event Hubs är en PaaS-tjänst finns det en fysisk verklighet under. För att upprätthålla en logg som bevarar händelseordningen måste dessa händelser hållas samman i den underliggande lagringen och dess repliker och det resulterar i ett dataflödestak för en sådan logg. Partitionering gör att flera parallella loggar kan användas för samma händelsehubb och därför multiplicera den tillgängliga I/O-dataflödeskapaciteten (Raw Input-Output).
- Dina egna program måste kunna hantera bearbetningen av mängden händelser som skickas till en händelsehubb. Det kan vara komplext och kräver betydande, utskalad, parallell bearbetningskapacitet. Kapaciteten för en enskild process för att hantera händelser är begränsad, så du behöver flera processer. Partitioner är hur din lösning matar dessa processer och säkerställer ändå att varje händelse har en tydlig bearbetningsägare.
Antal partitioner
Antalet partitioner anges när en händelsehubb skapas. Det måste vara mellan en och det maximala antalet partitioner som tillåts för varje prisnivå. För gränsen för antal partitioner för varje nivå, se den här artikeln.
Vi rekommenderar att du väljer minst så många partitioner som du förväntar dig som krävs under programmets högsta belastning för den specifika händelsehubben. För andra nivåer än premium- och dedikerade nivåer kan du inte ändra antalet partitioner för en händelsehubb när den har skapats. För en händelsehubb på en premium- eller dedikerad nivå kan du öka antalet partitioner när det har skapats, men du kan inte minska dem. Fördelningen av strömmar mellan partitioner ändras när mappningen av partitionsnycklar till partitioner ändras, så du bör försöka undvika sådana ändringar om den relativa händelseordningen är viktig i ditt program.
Det är frestande att ange antalet partitioner till det högsta tillåtna värdet, men kom alltid ihåg att händelseströmmarna måste struktureras så att du verkligen kan dra nytta av flera partitioner. Om du behöver absolut ordningsbevarande för alla händelser eller bara en handfull underströmmar kanske du inte kan dra nytta av många partitioner. Dessutom gör många partitioner bearbetningssidan mer komplex.
Det spelar ingen roll hur många partitioner som finns i en händelsehubb när det gäller priser. Det beror på antalet prisenheter (dataflödesenheter (TUs) för standardnivån, bearbetningsenheter (PUs) för premiumnivån och kapacitetsenheter (CUS) för den dedikerade nivån) för namnområdet eller det dedikerade klustret. Till exempel medför en händelsehubb på standardnivån med 32 partitioner eller med en partition exakt samma kostnad när namnområdet är inställt på en TU-kapacitet. Du kan också skala TUs eller PUs på ditt namnområde eller CUS för ditt dedikerade kluster oberoende av partitionsantalet.
En partition är en mekanism för dataorganisation som möjliggör parallell publicering och förbrukning. Även om den stöder parallell bearbetning och skalning är den totala kapaciteten fortfarande begränsad av namnområdets skalningsallokering. Vi rekommenderar att du balanserar skalningsenheter (dataflödesenheter för standardnivån, bearbetningsenheter för premiumnivån eller kapacitetsenheter för den dedikerade nivån) och partitioner för att uppnå optimal skalning. I allmänhet rekommenderar vi ett maximalt dataflöde på 1 MB/s per partition. Därför skulle en tumregel för att beräkna antalet partitioner vara att dividera det maximala förväntade dataflödet med 1 MB/s. Om ditt användningsfall till exempel kräver 20 MB/s rekommenderar vi att du väljer minst 20 partitioner för att uppnå optimalt dataflöde.
Men om du har en modell där ditt program har en tillhörighet till en viss partition är det inte fördelaktigt att öka antalet partitioner. Mer information finns i tillgänglighet och konsekvens.
Mappning av händelser till partitioner
Du kan organisera data med hjälp av en partitionsnyckel som mappar inkommande händelsedata till specifika partitioner. Partitionsnyckeln är ett värde som avsändaren anger och som skickas till en händelsehubb. Den bearbetas via en statisk hashningsfunktion, vilket skapar partitionstilldelningen. Om du inte anger en partitionsnyckel när du publicerar en händelse, används en round-robin-tilldelning.
Händelseutfärdaren känner bara till sin partitionsnyckel, inte den partition som händelserna publiceras till. Frikopplingen av nyckeln och partitionen gör att avsändaren inte behöver känna till så mycket om bearbetningen nedströms. En identitet per enhet eller en användarunik identitet utgör en bra partitionsnyckel, men andra attribut, till exempel geografi, kan också användas för att gruppera relaterade händelser i en enda partition.
Genom att ange en partitionsnyckel kan relaterade händelser hållas samman i samma partition och i exakt den ordning som de anlände. Partitionsnyckeln är en sträng som härleds från programkontexten och identifierar sambandet mellan händelserna. En sekvens med händelser som identifieras av en partitionsnyckel är en ström. En partition är ett multiplexat loggarkiv för många sådana strömmar.
Anteckning
Du kan skicka händelser direkt till partitioner, men vi rekommenderar det inte, särskilt inte när hög tillgänglighet är viktig för dig. Den nedgraderar tillgängligheten för en händelsehubb till partitionsnivå. Mer information finns i Tillgänglighet och konsekvens.
Eventpublicerare
En entitet som skickar data till en händelsehubb är en händelseutgivare (används synonymt med händelseproducent). Händelseutgivare kan publicera händelser med HTTPS eller AMQP 1.0 eller Kafka-protokollet. Händelseutgivare använder Microsoft Entra ID-baserad auktorisering med OAuth2-utfärdade JWTs eller en Händelsehubbspecifik SAS-token (Signatur för delad åtkomst) för att få publiceringsåtkomst.
Du kan publicera en händelse via AMQP 1.0, Kafka-protokollet eller HTTPS. Event Hubs-tjänsten tillhandahåller REST API - och .NET-, Java-, Python-, JavaScript- och Go-klientbibliotek för publicering av händelser till en händelsehubb. För andra körningar och plattformar kan du använda alla AMQP 1.0-klienter, t.ex. Apache Qpid.
Valet att använda AMQP eller HTTPS är specifikt för användningsscenariot. AMQP kräver en beständig dubbelriktad socket och dessutom säkerhet på transportnivå (TLS) eller SSL/TLS. AMQP har högre nätverkskostnader när sessionen initieras, men HTTPS kräver extra TLS-omkostnader för varje begäran. AMQP har högre prestanda för frekventa utgivare och kan uppnå mycket lägre svarstider när de används med asynkron publiceringskod.
Du kan publicera händelser individuellt eller batchvis. En enskild publikation har en gräns på 1 MB, oavsett om det är en enskild händelse eller en batch. Publicering av händelser som är större än det här tröskelvärdet avvisas.
Event Hubs-dataflödet skalas med hjälp av partitioner och allokeringar för dataflödesenheter. Det är bästa praxis att utgivare inte känner till den specifika partitioneringsmodell som valts för en händelsehubb och att endast ange en partitionsnyckel som används för att konsekvent tilldela relaterade händelser till samma partition.
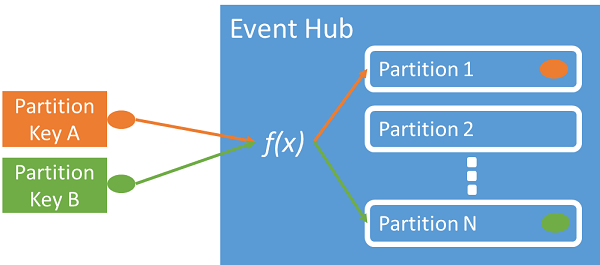
Event Hubs ser till att alla händelser som delar ett partitionsnyckelvärde lagras tillsammans och levereras i ordning efter ankomst. Om partitionsnycklar används med utfärdarprinciper måste utfärdarens identitet och partitionsnyckelns värde matcha varandra. Annars uppstår ett fel.
Kvarhållning av händelser
Publicerade händelser tas bort från en händelsehubb baserat på en konfigurerbar, tidsbaserad kvarhållningsprincip. Här är några viktiga punkter:
- Standardvärdet och den kortaste möjliga kvarhållningsperioden är 1 timme.
- För Event Hubs Standard är den maximala kvarhållningsperioden 7 dagar.
- För Event Hubs Premium och Dedicated är den maximala kvarhållningsperioden 90 dagar.
- Om du ändrar kvarhållningsperioden gäller den för alla händelser, inklusive händelser som redan finns i händelsehubben.
Event Hubs behåller händelser under en konfigurerad kvarhållningstid som gäller för alla partitioner. Händelser tas bort automatiskt när kvarhållningsperioden har uppnåtts. Om du har angett en kvarhållningsperiod på en dag (24 timmar) blir händelsen otillgänglig exakt 24 timmar efter att den har godkänts. Du kan inte uttryckligen ta bort händelser.
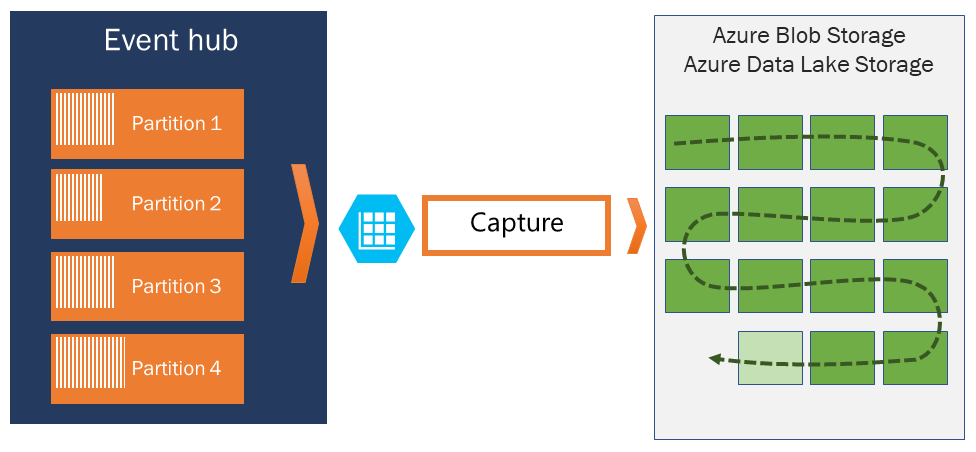
Om du behöver arkivera händelser efter den tillåtna kvarhållningsperioden kan du låta dem lagras automatiskt i Azure Storage eller Azure Data Lake genom att aktivera funktionen Event Hubs Capture. Om du behöver söka efter eller analysera sådana djupa arkiv kan du enkelt importera dem till Azure Synapse eller andra liknande butiker och analysplattformar.
Orsaken till Event Hubs gräns för datakvarhållning baserat på tid är att förhindra att stora mängder historiska kunddata fastnar i ett djupt lager som endast indexeras av en tidsstämpel och endast tillåter sekventiell åtkomst. Arkitekturfilosofin här är att historiska data behöver rikare indexering och mer direkt åtkomst än det realtidshändelsegränssnitt som Event Hubs eller Kafka tillhandahåller. Händelseströmningsmotorer passar inte bra för att spela rollen som datasjöar eller långsiktiga arkiv för händelsekällor.
Anteckning
Event Hubs är en händelseströmmotor i realtid och är inte utformad för att användas i stället för en databas och/eller som ett permanent arkiv för oändligt lagrade händelseströmmar.
Ju djupare historiken för en händelseström blir, desto mer behöver du hjälpindex för att hitta en viss historisk del av en viss ström. Inspektion av händelsenyttolaster och indexering ingår inte i funktionsomfånget för Event Hubs (eller Apache Kafka). Databaser och specialiserade analyslager och motorer som Azure Data Lake Store, Azure Data Lake Analytics och Azure Synapse är därför mycket bättre lämpade för lagring av historiska händelser.
Event Hubs Capture integreras direkt med Azure Blob Storage och Azure Data Lake Storage och möjliggör genom den integreringen även strömmande händelser direkt till Azure Synapse.
Utgivarprincip
Med händelsehubbar får du granulär kontroll över utgivare via utgivarprinciper. Publiceringsprinciper är funktionsfunktioner i realtid, avsedda att underlätta ett stort antal oberoende händelsepublicerare. Med utgivarprinciper använder varje utgivare sin egen unika identifierare vid publicering av händelser på en händelsehubb med hjälp av följande mekanism:
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
Du behöver inte skapa utgivarnamnen i förväg, men de måste matcha SAS-token som används när du publicerar en händelse för att garantera oberoende utgivaridentiteter. När du använder utgivarprinciper måste värdet PartitionKey anges till utgivarens namn. Dessa värden måste matcha för att fungera korrekt.
Fånga
Med Event Hubs Capture kan du automatiskt samla in strömmande data i Event Hubs och spara dem till ditt val av antingen ett Blob Storage-konto eller ett Azure Data Lake Storage-konto. Du kan aktivera avbildning från Azure Portal och ange en minsta storlek och ett tidsfönster för att utföra avbildningen. Med Event Hubs Capture anger du ditt eget Azure Blob Storage-konto och -container, eller Azure Data Lake Storage-konto, varav ett används för att lagra insamlade data. Insamlade data skrivs i Apache Avro-format.
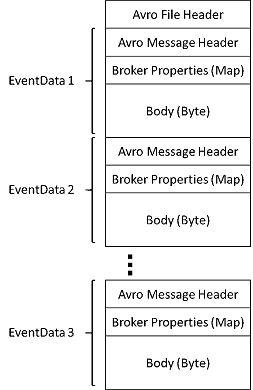
Filerna som skapas av Event Hubs Capture har följande Avro-schema:
Anteckning
När du inte använder någon kodredigerare i Azure Portal kan du samla in strömmande data i Event Hubs i ett Azure Data Lake Storage Gen2-konto i Parquet-format. Mer information finns i Så här samlar du in data från Event Hubs i Parquet-format och Självstudie: samla in Event Hubs-data i Parquet-format och analysera med Azure Synapse Analytics.
SAS-token
Event Hubs använder signaturer för delad åtkomst (SAS, Shared Access Signatures) som är tillgängliga på namnområdes- och händelsehubbnivå. En SAS-token genereras från en SAS-nyckel och är en SHA-hash för en URL som kodats i ett specifikt format. Event Hubs kan återskapa hashen med hjälp av namnet på nyckeln (principen) och token och därmed autentisera avsändaren. SAS-token för händelseutfärdare skapas vanligtvis med enbart behörighet att skicka på en specifik händelsehubb. Den här SAS-token-URL-mekanismen är grunden för publicerareidentifiering som infördes i publicerarpolicyn. Mer information om hur du arbetar med SAS finns i autentisering med signatur för delad åtkomst med Service Bus.
Händelsekonsumenter
En enhet som läser händelsedata från en händelsehubb är en händelsekonsument. Konsumenter eller mottagare använder AMQP eller Apache Kafka för att ta emot händelser från en händelsehubb. Event Hubs stöder endast pull-modellen för konsumenter att ta emot händelser från den. Även när du använder händelsehanterare för att hantera händelser från en händelsehubb använder händelseprocessorn internt pull-modellen för att ta emot händelser från händelsehubben.
Konsumentgrupper
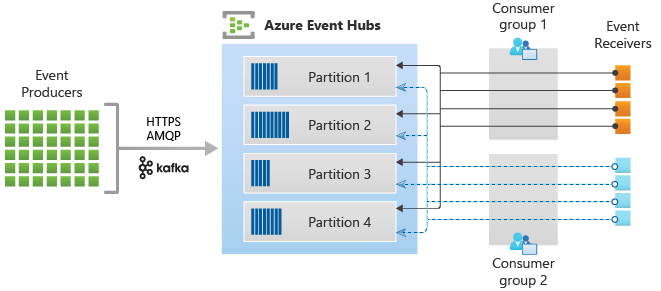
Publicerings-/prenumerationsmekanismen för Event Hubs aktiveras via konsumentgrupper. En konsumentgrupp är en logisk gruppering av konsumenter som läser data från en event hub eller ett Kafka-topic. Det gör det möjligt för flera konsumerande program att läsa samma strömmande data i en händelsehubb oberoende av sinsemellan i sin egen takt med sina offsets. Det gör att du kan parallellisera förbrukningen av meddelanden och distribuera arbetsbelastningen mellan flera konsumenter samtidigt som du behåller ordningen på meddelanden inom varje partition.
Vi rekommenderar att det bara finns en aktiv mottagare på en partition i en konsumentgrupp. I vissa scenarier kan du dock använda upp till fem konsumenter eller mottagare per partition där alla mottagare får alla händelser i partitionen. Om du har flera läsare på samma partition bearbetar du duplicerade händelser. Du måste hantera det i koden, vilket inte är trivialt. Det är dock en giltig metod i vissa scenarier.
Inom en arkitektur för strömbearbetning utgör varje nedströms program en konsumentgrupp. Om du vill skriva händelsedata till långsiktig lagring, då fungerar skrivprogrammet som en konsumentgrupp. Komplex händelsebearbetning kan sedan utföras av en annan, separat konsumentgrupp. Du får bara åtkomst till en partition via en konsumentgrupp. Det finns alltid en standardkonsumentgrupp i en händelsehubb och du kan skapa upp till det maximala antalet konsumentgrupper för motsvarande prisnivå.
Vissa klienter som erbjuds av Azure SDK:er är intelligenta konsumentagenter som automatiskt hanterar information om att säkerställa att varje partition har en enskild läsare och att alla partitioner för en händelsehubb läss från. Det gör att koden kan fokusera på att bearbeta de händelser som läss från händelsehubben så att den kan ignorera många av detaljerna i partitionerna. Mer information finns i Ansluta till en partition.
Följande exempel visar konsumentgruppens URI-konvention:
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
Följande bild visar strömhanteringsarkitekturen för händelsehubbar:
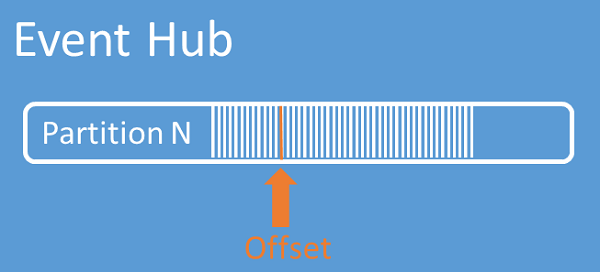
Offsets för strömmar
En offset är en händelses position inom en partition. Föreställ dig en offset som en markör på klientsidan. Offseten är en bytenumrering av händelsen. Den här förskjutningen gör det möjligt för en händelsekonsument (läsare) att ange vid vilken punkt i händelseströmmen de vill börja läsa händelser. Du kan ange offseten som en tidsstämpel eller ett offset-värde. Konsumenterna ansvarar för att lagra sina egna offset-värden utanför Event Hub-tjänsten. Inom en partition innehåller varje händelse en offset.
Kontrollpunkter
Att skapa kontrollpunkter är en process genom vilken läsare markerar eller sparar sin position inom en händelsesekvens i en partition. Kontrollpunktering är konsumentens ansvar och sker för varje partition i en konsumentgrupp. Det här ansvaret innebär att varje läsare i partitionen måste hålla reda på sin nuvarande position i händelseströmmen för varje konsumentgrupp. Läsaren kan sedan informera tjänsten när de anser att dataströmmen är klar.
Om en läsare kopplar från en partition och den sedan återansluts kan han börja läsa vid den kontrollpunkt som tidigare skickades in av den senaste läsaren i den aktuella partitionen inom just den konsumentgruppen. När läsaren ansluter skickas offsetet till händelsehubben för att ange var man ska börja läsa. På så sätt kan du använda kontrollpunkter både till att markera händelser som ”klara” i underordnade program och som skydd i händelse av en redundansväxling mellan läsare som körs på olika datorer. Det går att återgå till äldre data genom att ange en lägre förskjutning från den här kontrollpunktsprocessen. Den här mekanismen möjliggör både återhämtning vid redundansväxlingar och återuppspelning av händelseströmmar.
Viktigt!
Offsets tillhandahålls av Event Hubs-tjänsten. Det är konsumentens ansvar att kontrollera när händelser bearbetas.
Följ dessa rekommendationer när du använder Azure Blob Storage som kontrollpunktslager:
- Använd en separat container för varje konsumentgrupp. Du kan använda samma lagringskonto, men använda en container per grupp.
- Använd inte lagringskontot för något annat.
- Använd inte containern för något annat.
- Skapa lagringskontot i samma region som det distribuerade programmet. Om programmet är lokalt, försök att välja den region som är närmast.
På sidan Lagringskonto i Azure Portal i avsnittet Blob Service kontrollerar du att följande inställningar är inaktiverade.
- Hierarkisk namnrymd
- Mjuk borttagning av blob
- Versionshantering
Loggkomprimering
Azure Event Hubs stöder komprimering av händelseloggen för att behålla de senaste händelserna i en viss händelsenyckel. Med kompakterat event hubs/Kafka-ämne kan du använda nyckelbaserad kvarhållning i stället för att använda den mer grovkorniga tidsbaserade kvarhållningen.
Mer information om loggkomprimering finns i Loggkomprimering.
Vanliga konsumentuppgifter
Alla Event Hubs-konsumenter ansluter via en AMQP 1.0-session, en tillståndsmedveten dubbelriktad kommunikationskanal. Varje partition har en AMQP 1.0-session som gör det lättare att flytta händelser som åtskiljs av partitioner.
Ansluta till en partition
När du ansluter till partitioner är det vanligt att använda en leasingmekanism för att samordna läsaranslutningar till specifika partitioner. På så sätt är det möjligt för varje partition i en konsumentgrupp att bara ha en aktiv läsare. Kontrollpunkter, leasing och hantering av läsare förenklas med hjälp av klienterna i Event Hubs SDK:er, som fungerar som intelligenta konsumentagenter. Dessa är:
- EventProcessorClient för .NET
- EventProcessorClient för Java
- EventHubConsumerClient för Python
- EventHubConsumerClient för JavaScript/TypeScript
Läsa händelser
När en AMQP 1.0-session och -länk har öppnats för en specifik partition, levereras händelser till AMQP 1.0-klienten av händelsehubbtjänsten. Den här leveransmekanismen gör det möjligt med ett högre genomflöde och kortare svarstid än i pull-baserade mekanismer som t.ex. HTTP GET. När händelser skickas till klienten innehåller varje instans av händelsedata viktiga metadata, till exempel offset- och sekvensnumret som används för att göra det lättare att skapa kontrollpunkter i händelsesekvensen.
Evenemangsdata
- Förskjutning
- Sekvensnummer
- Kropp
- Användaregenskaper
- Systemegenskaper
Det är ditt ansvar att hantera förskjutningen.
Applikationsgrupper
En programgrupp är en samling klientprogram som ansluter till ett Event Hubs-namnområde som delar ett unikt identifieringsvillkor, till exempel säkerhetskontexten – principen för delad åtkomst eller Microsoft Entra-program-ID.
Med Azure Event Hubs kan du definiera principer för resursåtkomst, till exempel begränsningsprinciper för en viss programgrupp och styr händelseströmning (publicering eller användning) mellan klientprogram och Event Hubs.
Mer information finns i Resursstyrning för klientprogram med programgrupper.
Stöd för Apache Kafka
Protokollstöd för Apache Kafka-klienterbefintliga Kafka-program att använda Event Hubs. De flesta befintliga Kafka-program kan konfigureras om för att peka mot ett specifikt "s namespace" istället för en Kafka-klusters bootstrap-server.
Ur kostnads-, drifts- och tillförlitlighetsperspektiv är Azure Event Hubs ett bra alternativ till att distribuera och driva egna Kafka- och Zookeeper-kluster och till Kafka-as-a-Service-erbjudanden som inte är inbyggda i Azure.
Förutom att få samma grundläggande funktioner som Apache Kafka-koordinatorn får du även åtkomst till Funktioner i Azure Event Hubs som automatisk batchbearbetning och arkivering via Event Hubs Capture, automatisk skalning och balansering, haveriberedskap, stöd för kostnadsneutral tillgänglighetszon, flexibel och säker nätverksintegrering och stöd för flera protokoll, inklusive det brandväggsvänliga PROTOKOLLET AMQP-over-WebSockets.
Protokoll
Producenter eller avsändare kan använda Advanced Messaging Queuing Protocol (AMQP), Kafka eller HTTPS-protokollen för att skicka händelser till en händelsehubb.
Konsumenter eller mottagare använder AMQP eller Kafka för att ta emot händelser från en händelsehubb. Event Hubs stöder endast pull-modellen för konsumenter att ta emot händelser från den. Även när du använder händelsehanterare för att hantera händelser från en händelsehubb använder händelseprocessorn internt pull-modellen för att ta emot händelser från händelsehubben.
AMQP (Advanced Message Queuing Protocol)
Du kan använda PROTOKOLLET AMQP 1.0 för att skicka händelser till och ta emot händelser från Azure Event Hubs. AMQP tillhandahåller tillförlitlig, högpresterande och säker kommunikation för både sändning och mottagning av händelser. Du kan använda den för strömning med höga prestanda och realtid och stöds av de flesta SDK:er för Azure Event Hubs.
HTTPS/REST API
Du kan bara skicka händelser till Event Hubs med HTTP POST-begäranden. Event Hubs har inte stöd för att ta emot händelser via HTTPS. Den är lämplig för lätta klienter där en direkt TCP-anslutning inte är möjlig.
Apache Kafka
Azure Event Hubs har en inbyggd Kafka-slutpunkt som stöder Kafka-producenter och konsumenter. Program som skapas med Kafka kan använda Kafka-protokollet (version 1.0 eller senare) för att skicka och ta emot händelser från Event Hubs utan några kodändringar.
Azure SDK:er abstraherar de underliggande kommunikationsprotokollen och ger ett förenklat sätt att skicka och ta emot händelser från Event Hubs med hjälp av språk som C#, Java, Python, JavaScript osv.
Nästa steg
Besök följande länkar för mer utförlig information om Event Hubs:
- Kom igång med Event Hubs