Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics
Dataidentifiering och klassificering är inbyggt i Azure SQL Database, Azure SQL Managed Instance och Azure Synapse Analytics. Den här funktionen ger grundläggande funktioner för identifiering, klassificering, etikettering och rapportering av känsliga data i dina databaser.
Dina känsligaste data kan vara affärsinformation, ekonomi, sjukvård eller personlig information. Den kan fungera som infrastruktur för:
- Hjälper till att uppfylla standarder för datasekretess och krav för regelefterlevnad.
- Olika säkerhetsscenarier, till exempel övervakning (granskning) åtkomst till känsliga data.
- Kontrollera åtkomsten till och förstärka säkerheten för databaser som innehåller mycket känsliga data.
Anmärkning
Information om SQL Server lokalt finns i SQL Data Discovery &Classification .
Tips/Råd
Etikettbaserat åtkomstskydd med microsoft Purview Information Protection-principer är nu i förhandsversion. Mer information finns i Aktivera åtkomstkontroll för känsliga data med hjälp av Microsoft Purview Information Protection-principer (offentlig förhandsversion).
Vad är dataidentifiering och -klassificering?
Dataidentifiering och -klassificering stöder för närvarande följande funktioner:
Identifiering och rekommendationer: Klassificeringsmotorn söker igenom databasen och identifierar kolumner som innehåller potentiellt känsliga data. Det ger dig sedan ett enkelt sätt att granska och tillämpa rekommenderad klassificering via Azure-portalen.
Märkning: Du kan tillämpa känslighetsklassificeringsetiketter beständigt på kolumner med hjälp av nya metadataattribut som har lagts till i SQL Server-databasmotorn. Dessa metadata kan sedan användas för känslighetsbaserade granskningsscenarier.
Frågeresultatuppsättningskänslighet: Känsligheten för en frågeresultatuppsättning beräknas i realtid i granskningssyfte.
Synlighet: Du kan visa databasklassificeringstillståndet i en detaljerad instrumentpanel i Azure-portalen. Du kan också ladda ned en rapport i Excel-format som ska användas för efterlevnads- och granskningsändamål och andra behov.
Identifiera, klassificera och märka känsliga kolumner
I det här avsnittet beskrivs stegen för:
- Identifiera, klassificera och märka kolumner som innehåller känsliga data i databasen.
- Visa databasens aktuella klassificeringstillstånd och exportera rapporter.
Klassificeringen innehåller två metadataattribut:
- Etiketter: De viktigaste klassificeringsattributen som används för att definiera känslighetsnivån för de data som lagras i kolumnen.
- Informationstyper: Attribut som ger mer detaljerad information om vilken typ av data som lagras i kolumnen.
InformationSskyddsprincip
Azure SQL erbjuder både SQL Information Protection-principen och Microsoft Information Protection-principen i dataklassificering, och du kan välja någon av dessa två principer baserat på dina behov.

SQL Information Protection-princip
Data discovery &classification levereras med en inbyggd uppsättning känslighetsetiketter och informationstyper med identifieringslogik som är inbyggd i den logiska SQL-servern. Du kan fortsätta att använda skyddsetiketterna som är tillgängliga i standardprincipfilen, eller så kan du anpassa den här taxonomi. Du kan definiera en uppsättning och rangordning av klassificeringskonstruktioner specifikt för din miljö.
Definiera och anpassa klassificeringstaxonomi
Du definierar och anpassar klassificeringstaxonomi på en central plats för hela Azure-organisationen. Den platsen finns i Microsoft Defender för molnet som en del av din säkerhetsprincip. Endast någon med administrativa rättigheter i organisationens rothanteringsgrupp kan utföra den här uppgiften.
Som en del av principhanteringen kan du definiera anpassade etiketter, rangordna dem och associera dem med en vald uppsättning informationstyper. Du kan också lägga till egna anpassade informationstyper och konfigurera dem med strängmönster. Mönstren läggs till i identifieringslogik för att identifiera den här typen av data i dina databaser.
Mer information finns i Anpassa SQL-informationsskyddsprincipen i Microsoft Defender för molnet (förhandsversion).
När den organisationsomfattande principen har definierats kan du fortsätta att klassificera enskilda databaser med hjälp av din anpassade princip.
Klassificera databasen i principläge för SQL Information Protection
Anmärkning
I exemplet nedan används Azure SQL Database, men du bör välja den produkt som du vill konfigurera dataidentifiering och klassificering.
Gå till Azure-portalen.
Gå till Dataidentifiering och klassificering under rubriken Säkerhet i fönstret Azure SQL Database. Fliken Översikt innehåller en sammanfattning av databasens aktuella klassificeringstillstånd. Sammanfattningen innehåller en detaljerad lista över alla klassificerade kolumner, som du också kan filtrera för att endast visa specifika schemadelar, informationstyper och etiketter. Om du inte har klassificerat några kolumner ännu går du vidare till steg 4.
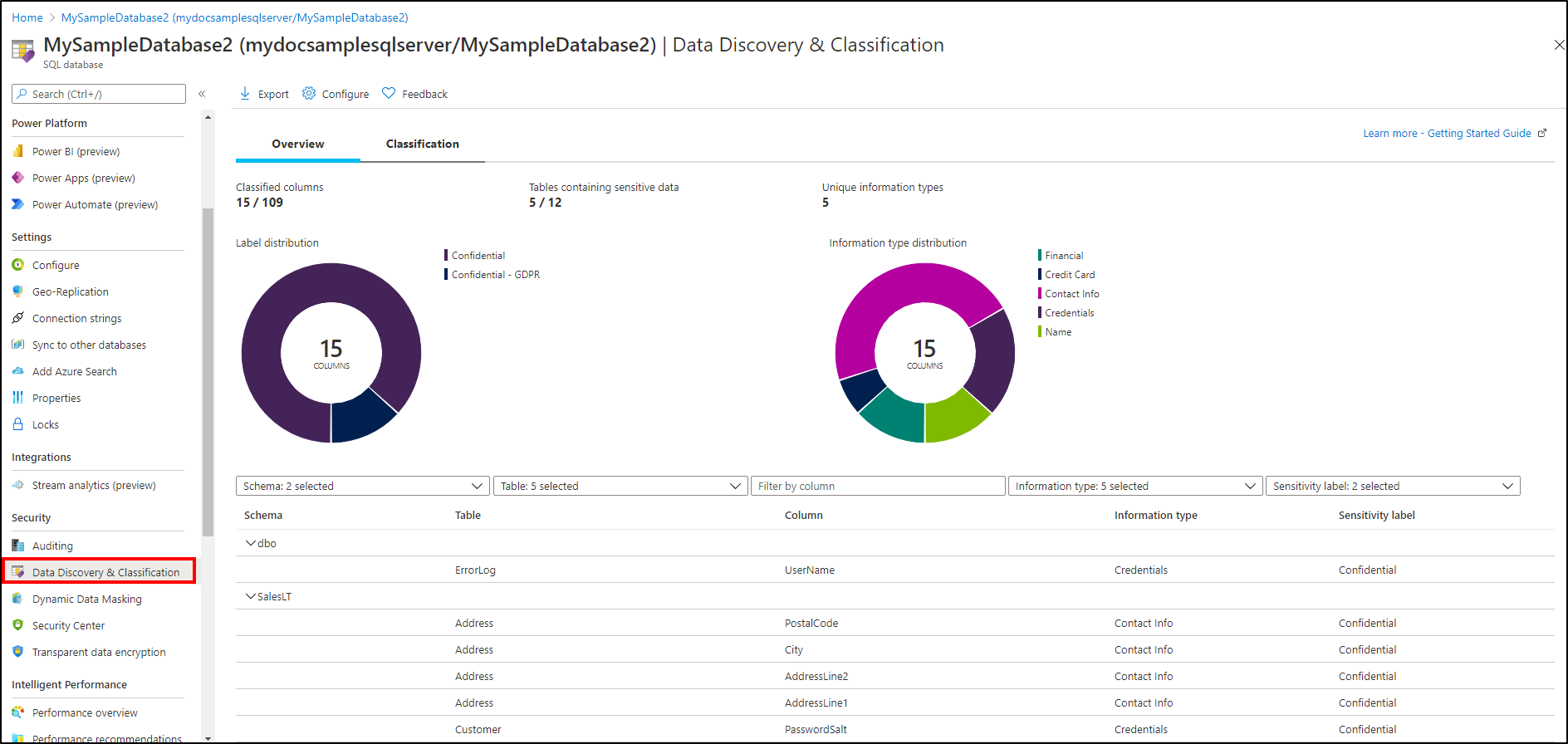
Om du vill ladda ned en rapport i Excel-format väljer du Exportera på den översta menyn i fönstret.
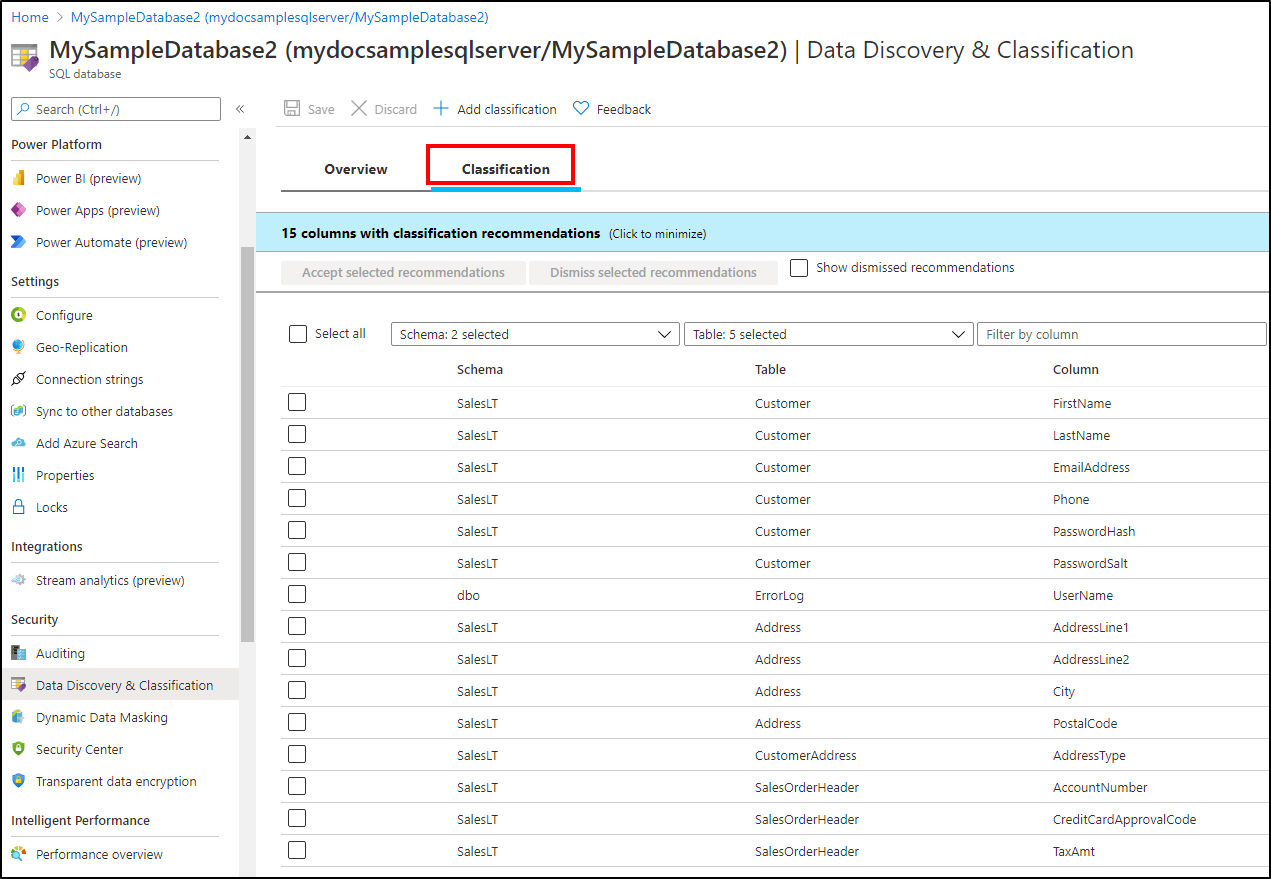
Börja klassificera dina data genom att välja fliken Klassificering på sidan Dataidentifiering och klassificering .
Klassificeringsmotorn söker igenom databasen efter kolumner som innehåller potentiellt känsliga data och innehåller en lista över rekommenderade kolumnklassificeringar.
Visa och tillämpa klassificeringsrekommendationer:
Om du vill visa listan över rekommenderade kolumnklassificeringar väljer du panelen rekommendationer längst ned i fönstret.
Om du vill acceptera en rekommendation för en specifik kolumn markerar du kryssrutan i den vänstra kolumnen på den relevanta raden. Markera alla rekommendationer som godkända genom att markera kryssrutan längst till vänster i tabellrubriken för rekommendationerna.
Om du vill tillämpa de valda rekommendationerna väljer du Acceptera valda rekommendationer.
Anmärkning
Rekommendationsmotorn, som gör automatisk dataidentifiering och ger rekommendationer för känsliga kolumner, inaktiveras när Principläget för Microsoft Purview Information Protection används.
Du kan också klassificera kolumner manuellt, som ett alternativ eller utöver den rekommendationsbaserade klassificeringen:
Välj Lägg till klassificering på den översta menyn i fönstret.
I kontextfönstret som öppnas väljer du det schema, den tabell och kolumn som du vill klassificera samt informationstypen och känslighetsetiketten.
Välj Lägg till klassificering längst ned i kontextfönstret.
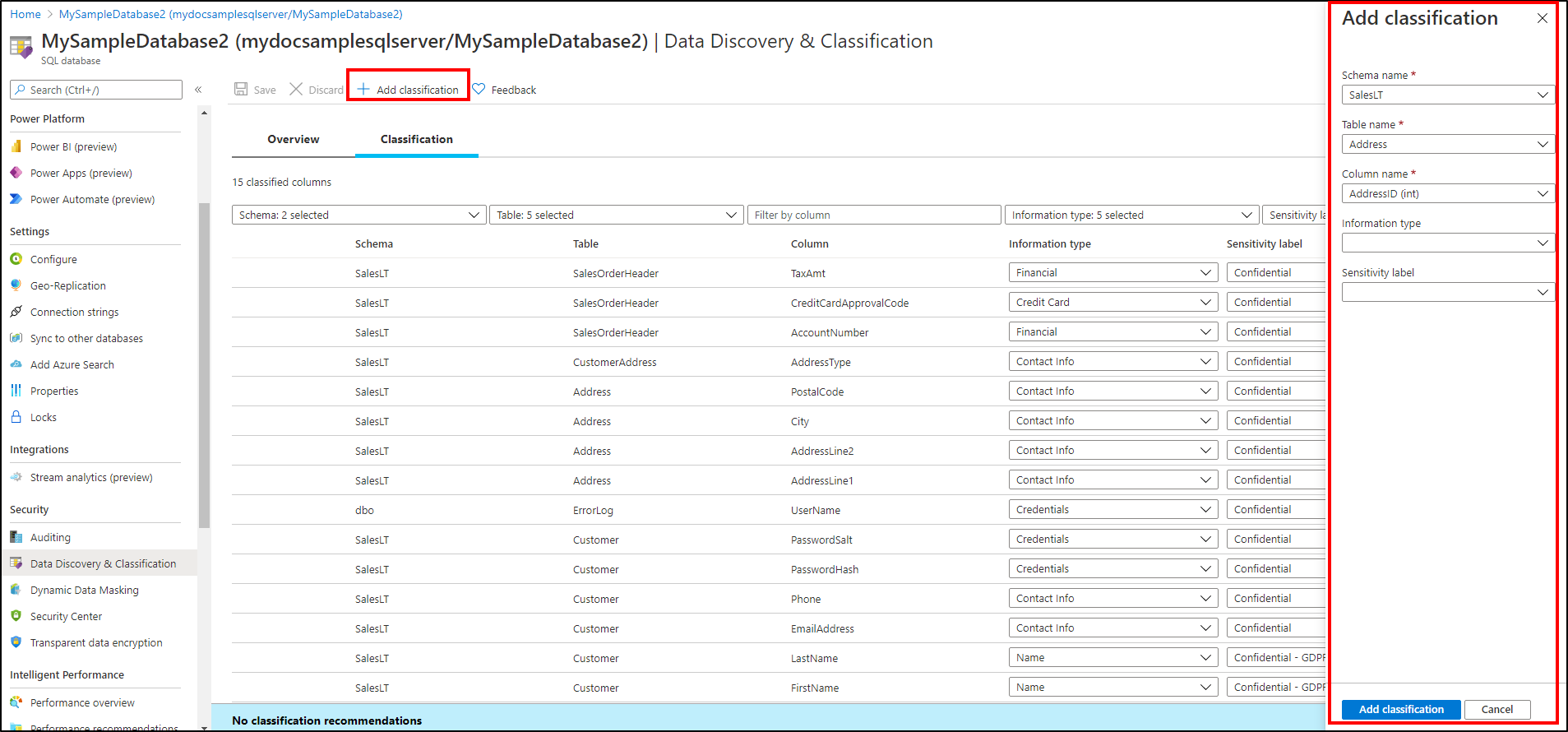
Om du vill slutföra din klassificering och beständigt märka (tagga) databaskolumnerna med de nya klassificeringsmetadata väljer du Spara på sidan Klassificering .
Microsoft Purview Information Protection-policy
Anmärkning
Microsoft Information Protection (MIP) har bytt namn till Microsoft Purview Information Protection. Både "MIP" och "Microsoft Purview Information Protection" används omväxlande i det här dokumentet, men refererar till samma koncept.
Microsoft Purview Information Protection-etiketter är ett enkelt och enhetligt sätt för användare att klassificera känsliga data på ett enhetligt sätt i olika Microsoft-program. MIP-känslighetsetiketter skapas och hanteras i Microsoft Purview-efterlevnadsportalen. Information om hur du skapar och publicerar känsliga MIP-etiketter i Microsoft Purview-efterlevnadsportalen finns i Skapa och publicera känslighetsetiketter.
Krav för att växla till Microsoft Purview Information Protection-princip
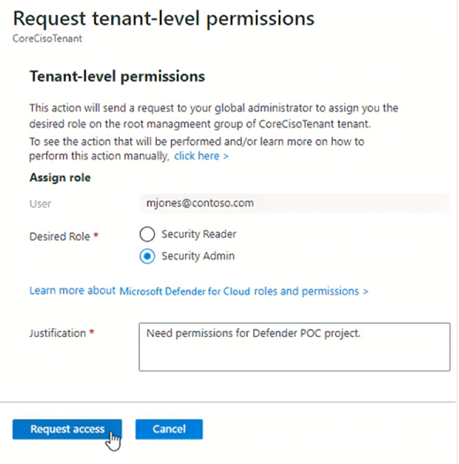
- Inställning/ändring av informationsskyddsprincip i Azure SQL Database anger respektive informationsskyddsprincip för alla databaser under klientorganisationen. Användaren eller personan måste ha behörighet som säkerhetsadministratör för hela klientorganisationen för att kunna ändra informationsskyddsprincipen från SQL Information Protection-principen till MIP-principen, eller tvärtom.
- Den användare eller persona som har behörighet som säkerhetsadministratör för klientorganisationen kan tillämpa principen på klientorganisationens rothanteringsgruppsnivå. För mer information, se Bevilja klientomfattande behörigheter till dig själv.
- Din klientorganisation har en aktiv Microsoft 365-prenumeration och du har etiketter publicerade för den aktuella användaren. Mer information finns i Skapa och konfigurera känslighetsetiketter och dessas policyer.
Klassificera databasen i Principläge för Microsoft Purview Information Protection
Gå till Azure-portalen.
Navigera till databasen i Azure SQL Database
Gå till Dataidentifiering och klassificering under rubriken Säkerhet i databasfönstret.
Välj Microsoft Information Protection-princip genom att välja fliken Översikt och sedan Konfigurera.
Välj Microsoft Information Protection-princip i alternativen för informationsskyddsprinciper och välj Spara.
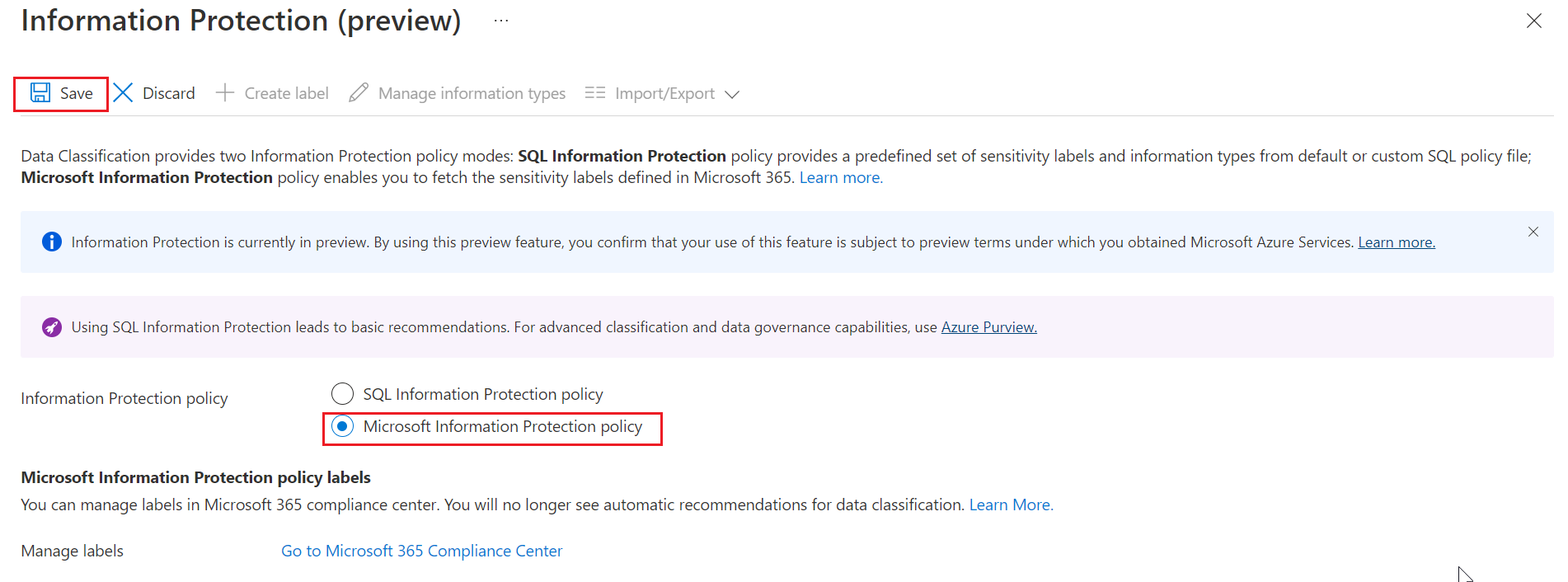
Om du går till fliken Klassificering eller väljer Lägg till klassificering visas nu Microsoft 365-känslighetsetiketter i listrutan Känslighetsetiketter .

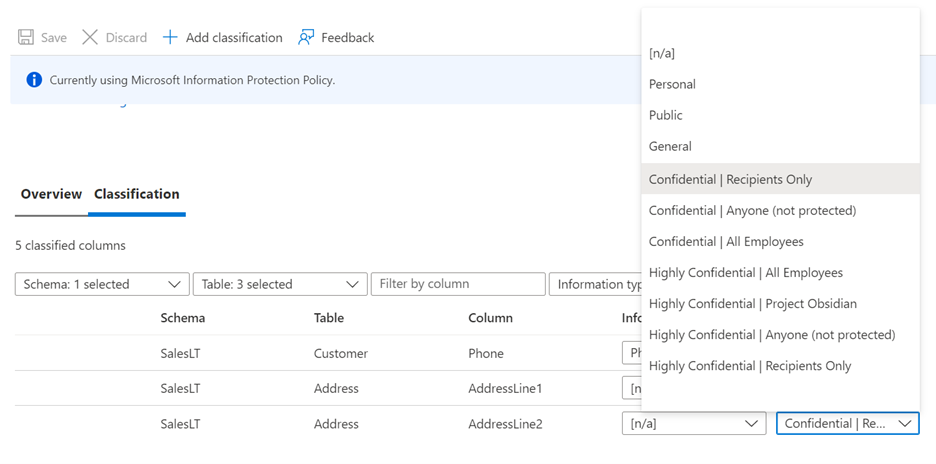


Informationstypen är
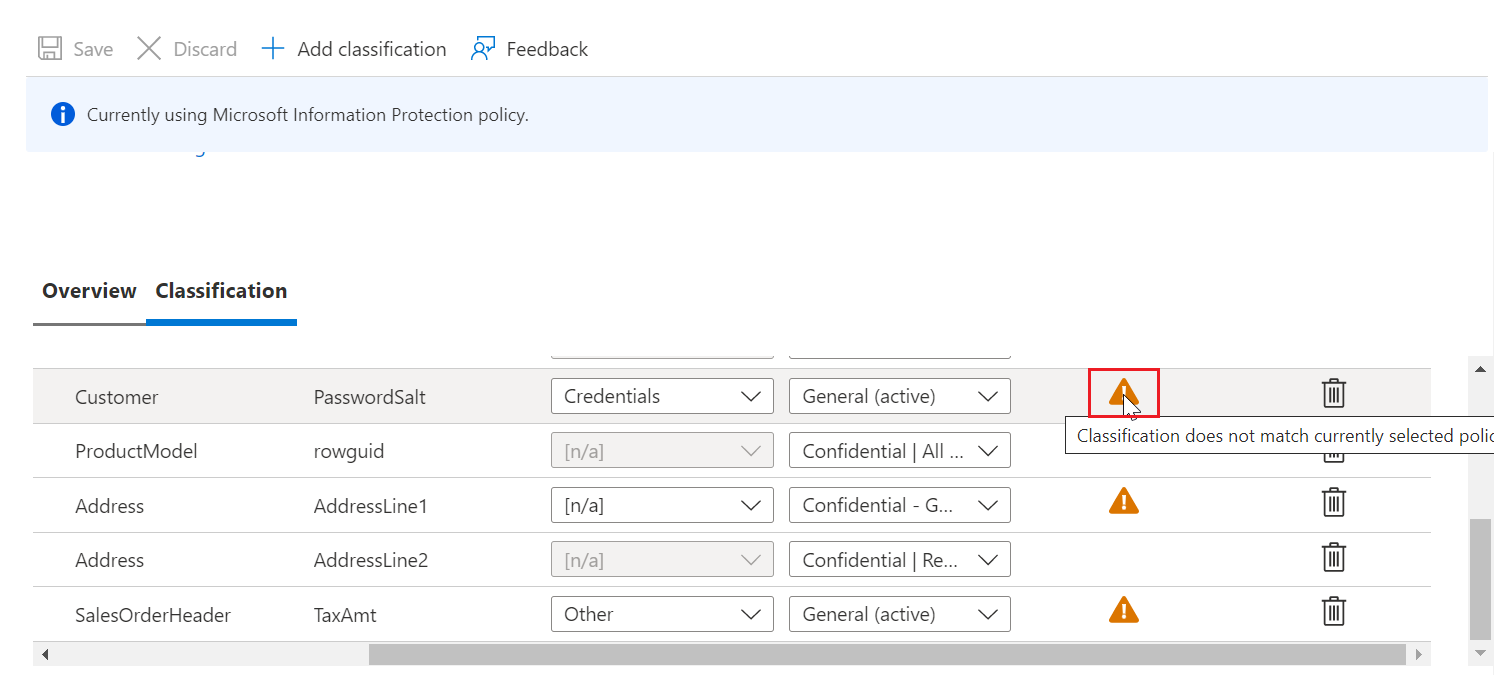
[n/a]när du är i MIP-principläge och automatiska dataidentifiering och rekommendationer förblir inaktiverade.En varningsikon kan visas mot en redan klassificerad kolumn om kolumnen klassificerades med en annan informationsskyddsprincip än den aktuella aktiva principen. Om kolumnen till exempel klassificerades med en etikett under SQL Information Protection-policy tidigare och nu är i Microsoft Information Protection-policyläge. du ser en varningsikon mot den specifika kolumnen. Den här varningsikonen anger inget problem, men används endast i informationssyfte.

Aktivera åtkomstkontroll för känsliga data med hjälp av Microsoft Purview Information Protection-principer (offentlig förhandsversion)
Azure SQL Database har stöd för möjligheten att framtvinga åtkomstkontroll för kolumner med känsliga data som har märkts med känslighetsetiketter för Microsoft Purview Information Protection (MIP) med hjälp av Microsoft Purview Information Protection-åtkomstprinciper.
Åtkomstprinciper i Purview gör det möjligt för organisationer att skydda känsliga data i sina datakällor. De gör det möjligt för personer som företagssäkerhets-/efterlevnadsadministratörer att konfigurera och tillämpa åtkomstkontrollåtgärder på känsliga data i sina databaser, vilket säkerställer att känsliga data inte kan nås av obehöriga användare för en viss känslighetsetikett. Purview-åtkomstprinciper tillämpas på kolumnnivåskornighet för Azure SQL Database, vilket skyddar känsliga data utan att blockera åtkomst till icke-känsliga datakolumner i databastabellerna.
För att konfigurera och tillämpa Purview-åtkomstprinciper måste användaren ha en giltig Microsoft 365-licens och databasen måste registreras i Purview-datakartan och genomsökas, så att MIP-känslighetsetiketter tilldelas av Purview till databaskolumnerna som innehåller känsliga data. När känslighetsetiketter har tilldelats kan användaren konfigurera Purview-åtkomstprinciper för att framtvinga neka-åtgärder på databaskolumner med en specifik känslighetsetikett, vilket begränsar åtkomsten till känsliga data i dessa kolumner till endast en tillåten användare eller grupp av användare.
Konfigurera och aktivera åtkomstprincip i Purview för Azure SQL-databas
Följ listan med steg nedan för att konfigurera och använda Purview-åtkomstprinciper för Azure SQL Database:
- Kontrollera att du har nödvändiga licenskrav för Microsoft 365 och Purview.
- Konfigurera roller och behörigheter för dina användare.
- Skapa eller utöka känslighetsetiketter i Purview till Azure SQL Database. Se också till att du publicerar känslighetsetiketterna till de användare som krävs i din organisation.
- Registrera och skanna din Azure SQL-databas för att tillämpa känslighetsetiketter automatiskt.
- Skapa och konfigurera åtkomstkontrollprincip i Purview för Azure SQL Database.
När åtkomstprincipen har konfigurerats och publicerats i Purview misslyckas alla försök av en obehörig användare att köra en T-SQL-fråga för att komma åt kolumner i en SQL-databas med känslighetsetiketter som är begränsade till principen. Om samma fråga inte innehåller känsliga kolumner lyckas frågan.
Begränsningar
När du skapar en databas geo-replik eller kopia flödar inte känslighetsetiketter som tilldelats kolumner i den primära databasen automatiskt till den nya/sekundära databasen, och Purview-åtkomstkontrollprinciper tillämpas inte automatiskt på den nya/sekundära databasen. Om du vill aktivera åtkomstkontroll på den nya/sekundära databasen registrerar du och söker igenom den separat i Purview. Konfigurera sedan alla åtkomstprinciper så att de även innehåller den nya/sekundära databasen.
Granska åtkomst till känsliga data
En viktig aspekt av klassificeringen är möjligheten att övervaka åtkomsten till känsliga data.
Azure SQL-granskning har förbättrats för att inkludera ett nytt fält i granskningsloggen med namnet data_sensitivity_information. Det här fältet loggar känslighetsklassificeringar (etiketter) för de data som returnerades av en fråga. Här är ett exempel:

Det här är de aktiviteter som faktiskt kan granskas med känslighetsinformation:
- ALTER TABLE ... SLÄPP KOLUMN
- BULKINFÖRSEL
- VÄLJ
- TA BORT
- INSERT
- SAMMANFÖRA
- UPPDATERING
- UPPDATERA TEXT
- SKRIVTEXT
- TA BORT TABELL
- BACKUP
- DBCC CloneDatabase
- VÄLJ I
- INFOGA I EXEC
- TRUNKERA TABELL
- DBCC-SHOW_STATISTICS
- sys.dm_db_stats_histogram
Använd sys.fn_get_audit_file för att returnera information från en granskningsfil som lagras på ett Azure Storage-konto.
Behörigheter
Dessa inbyggda roller kan läsa dataklassificeringen för en databas:
- Ägare
- Läsare
- Bidragsgivare
- SQL Säkerhetschef
- Administratör för användaråtkomst
Det här är de åtgärder som krävs för att läsa dataklassificeringen för en databas:
- Microsoft.Sql/servers/databases/currentSensitivityLabels/*
- Microsoft.Sql/servers/databases/recommendedSensitivityLabels/*
- Microsoft.Sql/servers/databases/schemas/tables/columns/sensitivityLabels/*
Dessa inbyggda roller kan ändra dataklassificeringen för en databas:
- Ägare
- Bidragsgivare
- SQL Säkerhetschef
Det här är den nödvändiga åtgärden för att ändra dataklassificeringen för en databas:
- Microsoft.Sql/servers/databases/schemas/tables/columns/sensitivityLabels/*
Läs mer om rollbaserade behörigheter i Azure RBAC.
Anmärkning
De inbyggda Azure SQL-rollerna i det här avsnittet gäller för en dedikerad SQL-pool (tidigare SQL DW) men är inte tillgängliga för dedikerade SQL-pooler och andra SQL-resurser i Azure Synapse-arbetsytor. För SQL-resurser i Azure Synapse-arbetsytor använder du tillgängliga åtgärder för dataklassificering för att skapa anpassade Azure-roller efter behov för märkning. Mer information om provideråtgärder finns i Microsoft.Synapse/workspaces/sqlPoolsMicrosoft.Synapse.
Hantera klassificeringar
Du kan använda T-SQL, ett REST-API eller PowerShell för att hantera klassificeringar.
Använda T-SQL
Du kan använda T-SQL för att lägga till eller ta bort kolumnklassificeringar och hämta alla klassificeringar för hela databasen.
Anmärkning
När du använder T-SQL för att hantera etiketter finns det ingen verifiering av att etiketter som du lägger till i en kolumn finns i organisationens informationsskyddsprincip (den uppsättning etiketter som visas i portalrekommendationerna). Så det är upp till dig att verifiera detta.
Information om hur du använder T-SQL för klassificeringar finns i följande referenser:
- Så här lägger du till eller uppdaterar klassificeringen av en eller flera kolumner: LÄGG TILL KÄNSLIGHETSKLASSIFICERING
- Ta bort klassificeringen från en eller flera kolumner: SLÄPP KÄNSLIGHETSKLASSIFICERING
- Så här visar du alla klassificeringar i databasen: sys.sensitivity_classifications
Använda PowerShell-cmdletar
Hantera klassificeringar och rekommendationer för Azure SQL Database och Azure SQL Managed Instance med hjälp av PowerShell.
PowerShell-cmdletar för Azure SQL Database
- Hämta-AzSqlDatabasKänslighetsklassificering
- Set-AzSqlDatabaseSensitivityClassification
- Remove-AzSqlDatabaseSensitivityClassification (ta bort känslighetsklassificering för SQL-databasen)
- Get-AzSqlDatabaseSensitivityRecommendation
- Aktivera-AzSqlDatabaseSensitivitetsRekommendation
- Disable-AzSqlDatabaseSensitivityRecommendation
PowerShell-cmdletar för Azure SQL Managed Instance
- Get-AzSqlInstanceDatabaseSensitivityClassification
- Set-AzSqlInstanceDatabaseSensitivityClassification
- Remove-AzSqlInstanceDatabaseSensitivityClassification
- Get-AzSqlInstanceDatabaseSensitivityRecommendation
- Enable-AzSqlInstanceDatabaseSensitivityRecommendation
- Disable-AzSqlInstanceDatabaseSensitivityRecommendation
Använda REST-API:et
Du kan använda REST-API:et för att programmatiskt hantera klassificeringar och rekommendationer. Det publicerade REST-API:et stöder följande åtgärder:
- Skapa eller uppdatera: Skapar eller uppdaterar känslighetsetiketten för den angivna kolumnen.
- Ta bort: Tar bort känslighetsetiketten för den angivna kolumnen.
- Inaktivera rekommendation: Inaktiverar känslighetsrekommendationer för den angivna kolumnen.
- Aktivera rekommendation: Aktiverar känslighetsrekommendationer för den angivna kolumnen. (Rekommendationer är aktiverade som standard för alla kolumner.)
- Hämta: Hämtar känslighetsetiketten för den angivna kolumnen.
- Lista aktuell efter databas: Hämtar aktuella känslighetsetiketter för den angivna databasen.
- Lista som rekommenderas av databasen: Hämtar de rekommenderade känslighetsetiketterna för den angivna databasen.
Hämta metadata för klassificeringar med SQL-drivrutiner
Du kan använda följande SQL-drivrutiner för att hämta klassificeringsmetadata:
- Microsoft.Data.SqlClient
- ODBC-drivrutin
- OLE DB-drivrutin
- JDBC-drivrutin
- Microsoft-drivrutiner för PHP för SQL Server
Vanliga frågor och svar – Avancerade klassificeringsfunktioner
Fråga: Kommer Microsoft Purview att ersätta SQL Data Discovery & Classification eller kommer SQL Data Discovery &Classification snart att dras tillbaka? Svar: Vi fortsätter att stödja SQL Data Discovery &Classification och uppmuntrar dig att använda Microsoft Purview som har bättre funktioner för att driva avancerade klassificeringsfunktioner och datastyrning. Om vi bestämmer oss för att dra tillbaka någon tjänst, funktion, API eller SKU får du ett meddelande i förväg, inklusive en migrerings- eller övergångssökväg. Mer information finns i Microsofts livscykelprinciper.
Nästa steg
- Överväg att konfigurera Azure SQL-granskning för övervakning och granskning av åtkomst till dina klassificerade känsliga data.
- En presentation som innehåller dataidentifiering och klassificering finns i Identifiera, klassificera, märka och skydda SQL-data | Exponerade data.
- Information om hur du klassificerar dina Azure SQL-databaser och Azure Synapse Analytics med Microsoft Purview-etiketter med hjälp av T-SQL-kommandon finns i Klassificera dina Azure SQL-data med hjälp av Microsoft Purview-etiketter.