Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Använd Azure Batch för att effektivt köra storskaliga parallella och högpresterande databehandlingsjobb (HPC) i Azure. Azure Batch skapar och hanterar en pool med beräkningsnoder (virtuella datorer), installerar de program som du vill köra och schemalägger jobb som ska köras på noderna. Det finns ingen programvara för kluster eller jobbschemaläggare för att installera, hantera eller skala. I stället använder du Batch-API:er och verktyg, kommandoradsskript eller Azure-portalen för att konfigurera, hantera och övervaka dina jobb.
Utvecklare kan använda Batch som en plattformstjänst för att skapa SaaS-program eller klientprogram där storskalig körning krävs. Du kan till exempel skapa en tjänst med Batch för att köra en Monte Carlo-risksimulering för ett företag för finansiella tjänster eller en tjänst för att bearbeta många avbildningar.
Det kostar inget extra att använda Batch. Du betalar bara för de underliggande resurser som förbrukas, till exempel virtuella datorer, lagring och nätverk.
En jämförelse mellan Batch och andra HPC-lösningsalternativ i Azure finns i HPC (High Performance Computing) på Azure.
Köra parallella arbetsbelastningar
Batch fungerar bra med parallella (även kallade "pinsamt parallella") arbetsbelastningar. Dessa arbetsbelastningar har program som kan köras separat, där varje instans slutför en del av arbetet. När programmen körs kan de komma åt några vanliga data, men de kommunicerar inte med andra instanser av programmet. Parallella arbetsbelastningar kan därför köras i stor skala, vilket bestäms av mängden beräkningsresurser som är tillgängliga för att köra program samtidigt.
Några exempel på parallella arbetsbelastningar som du kan ta med till Batch:
- Modellering av finansiella risker med Monte Carlo-simuleringar
- VFX- och 3D-bildåtergivning
- Bildanalys och bearbetning
- Medietranskodning
- Genetisk sekvensanalys
- Optisk teckenläsning (OCR)
- Datainmatning, bearbetning och ETL-åtgärder
- Körning av programvarutest
Du kan också använda Batch för att köra nära kopplade arbetsbelastningar, där de program som du kör måste kommunicera med varandra i stället för att köras oberoende av varandra. Nära kopplade program använder normalt MPI-API:et (Message Passing Interface). Du kan köra dina tätt kopplade arbetsbelastningar i Batch med Microsoft MPI eller Intel MPI. Förbättra programprestanda med specialiserade HPC- och GPU-optimerade VM-storlekar.
Några exempel på nära kopplade arbetsbelastningar:
- Analys av ändliga element
- Vätskedynamik
- AI-träning med flera noder
Många nära kopplade jobb kan köras parallellt med Batch. Du kan till exempel utföra flera simuleringar av en vätska som flödar genom ett rör med varierande rörbredder.
Ytterligare Batch-funktioner
Batch stöder storskaliga renderingsarbetsbelastningar med renderingsverktyg som Autodesk Maya, 3ds Max, Arnold och V-Ray.
Du kan också köra Batch-jobb som en del av ett större Azure arbetsflöde för att transformera data, som hanteras av verktyg som Azure Data Factory.
Så här fungerar det
Ett vanligt scenario för Batch är att skala ut parallellt arbete, till exempel återgivning av bilder för 3D-scener, i en pool med beräkningsnoder. Den här poolen kan vara din "renderfarm" som ger tiotals, hundratals eller till och med tusentals kärnor till ditt renderingsjobb.
Följande diagram visar steg i ett vanligt Batch-arbetsflöde, med ett klientprogram eller en värdbaserad tjänst som använder Batch för att köra en parallell arbetsbelastning.
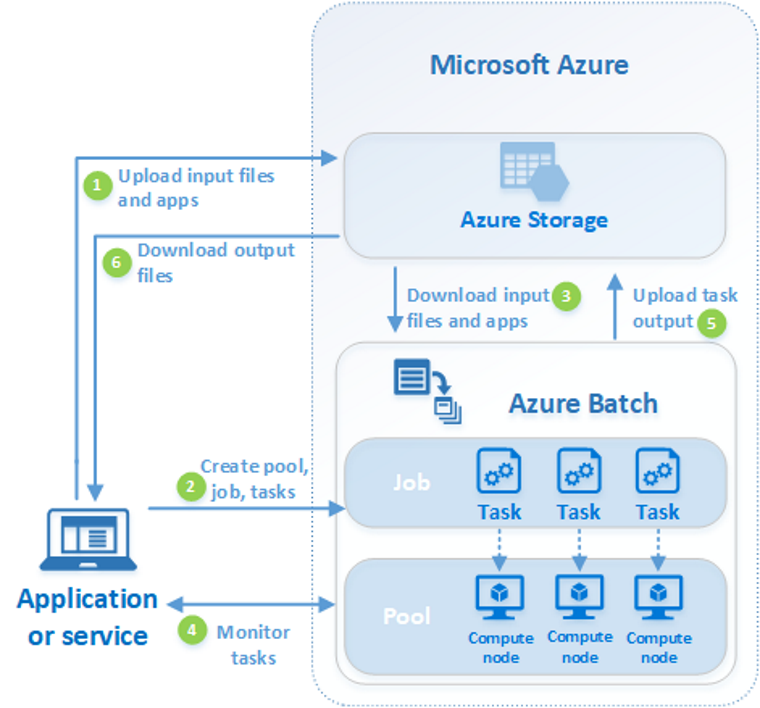
| Steg | Beskrivning |
|---|---|
| 1. Ladda upp indatafiler och program för att bearbeta dessa filer till ditt Azure Storage konto. | Indatafilerna kan vara alla data som ditt program bearbetar, till exempel finansiella modelleringsdata eller videofiler som ska omkodas. Programfilerna kan innehålla skript eller program som bearbetar data, till exempel en medietranskodare. |
| 2. Skapa en Batch-pool med beräkningsnoder i ditt Batch-konto, ett jobb för att köra arbetsbelastningen i poolen och uppgifter i jobbet. |
Beräkningsnoder är de virtuella datorer som kör dina uppgifter. Ange egenskaper för din pool, till exempel antalet och storleken på noderna, en Windows- eller Linux VM-avbildning och ett program som ska installeras när noderna ansluter till poolen. Hantera kostnaden och storleken på poolen med hjälp av Azure virtuella datorer med oanvänd kapacitet eller genom att automatiskt skala antalet noder när arbetsbelastningen ändras. När du lägger till uppgifter i ett jobb, schemalägger Batch-tjänsten automatiskt uppgifterna för att köras på beräkningsnoderna i poolen. Varje uppgift använder programmet som du laddade upp för att bearbeta indatafilerna. |
| 3. Ladda ned indatafiler och program till Batch | Innan varje aktivitet körs kan den ladda ned indata som den bearbetar till den tilldelade noden. Om programmet inte redan är installerat på poolnoderna kan det laddas ned här i stället. När nedladdningarna från Azure Storage slutförs körs uppgiften på den tilldelade noden. |
| 4. Övervaka körning av uppgifter | När uppgifterna körs använder du Batch för att övervaka jobbets och uppgifternas förlopp. Klientprogrammet eller tjänsten kommunicerar med Batch-tjänsten via HTTPS. Eftersom du kanske övervakar tusentals aktiviteter som körs på tusentals beräkningsnoder bör du se till att fråga Batch-tjänsten på ett effektivt sätt. |
| 5. Ladda upp aktivitetsutdata | När uppgifterna har slutförts kan de ladda upp sina resultatdata till Azure Storage. Du kan också hämta filer direkt från filsystemet på en beräkningsnod. |
| 6. Ladda ned utdatafiler | När övervakningen upptäcker att uppgifterna i jobbet har slutförts kan klientprogrammet eller tjänsten ladda ned utdata för vidare bearbetning. |
Tänk på att föregående arbetsflöde bara är ett sätt att använda Batch, och det finns många andra funktioner och alternativ. Du kan till exempel köra flera uppgifter parallellt på varje beräkningsnod. Eller så kan du använda jobbförberedelse- och slutförandeaktiviteter för att förbereda noderna för dina jobb och sedan rensa efteråt.
Se Batch-tjänstens arbetsflöde och resurser för en översikt över funktioner som pooler, noder, jobb och uppgifter. Se även de senaste uppdateringarna av Batch-tjänsten.
Dataresidens inom regionen
Azure Batch flyttar eller lagrar inte kunddata utanför den region där den distribueras.
Nästa steg
Kom igång med Azure Batch med någon av följande snabbstarter:
- Kör ditt första Batch-jobb med Azure CLI
- Kör ditt första Batch-jobb med Azure-portalen
- Kör ditt första Batch-jobb med hjälp av .NET-API:et
- Kör ditt första Batch-jobb med Python-API:et
- Skapa ett Batch-konto med ARM-mallar
För att fortsätta, se dessa handledningar för scenarier från början till slut: