Metodtips för Azure Machine Learning för företagssäkerhet
I den här artikeln beskrivs metodtips för säkerhet för att planera eller hantera en säker Azure Machine Learning-distribution. Bästa praxis kommer från Microsoft och kundupplevelsen med Azure Machine Learning. Varje riktlinje förklarar praxis och dess motivering. Artikeln innehåller även länkar till instruktioner och referensdokumentation.
Rekommenderad nätverkssäkerhetsarkitektur (hanterat nätverk)
Den rekommenderade nätverkssäkerhetsarkitekturen för maskininlärning är ett hanterat virtuellt nätverk. Ett hanterat virtuellt Azure Machine Learning-nätverk skyddar arbetsytan, associerade Azure-resurser och alla hanterade beräkningsresurser. Det förenklar konfigurationen och hanteringen av nätverkssäkerhet genom att förkonfigurera nödvändiga utdata och automatiskt skapa hanterade resurser i nätverket. Du kan använda privata slutpunkter för att tillåta Att Azure-tjänster får åtkomst till nätverket och kan också definiera regler för utgående trafik så att nätverket kan komma åt Internet.
Det hanterade virtuella nätverket har två lägen som kan konfigureras för:
Tillåt utgående Internet – Det här läget tillåter utgående kommunikation med resurser som finns på Internet, till exempel de offentliga PyPi- eller Anaconda-paketlagringsplatserna.

Tillåt endast godkänd utgående trafik – Det här läget tillåter endast den minsta utgående kommunikation som krävs för att arbetsytan ska fungera. Det här läget rekommenderas för arbetsytor som måste isoleras från Internet. Eller där utgående åtkomst endast tillåts till specifika resurser via tjänstslutpunkter, tjänsttaggar eller fullständigt kvalificerade domännamn.

Mer information finns i Hanterad isolering av virtuella nätverk.
Rekommenderad nätverkssäkerhetsarkitektur (Azure Virtual Network)
Om du inte kan använda ett hanterat virtuellt nätverk på grund av dina affärskrav kan du använda ett virtuellt Azure-nätverk med följande undernät:
- Träningen innehåller beräkningsresurser som används för träning, till exempel beräkningsinstanser för maskininlärning eller beräkningskluster.
- Bedömning innehåller beräkningsresurser som används för bedömning, till exempel Azure Kubernetes Service (AKS).
- Brandväggen innehåller brandväggen som tillåter trafik till och från det offentliga Internet, till exempel Azure Firewall.
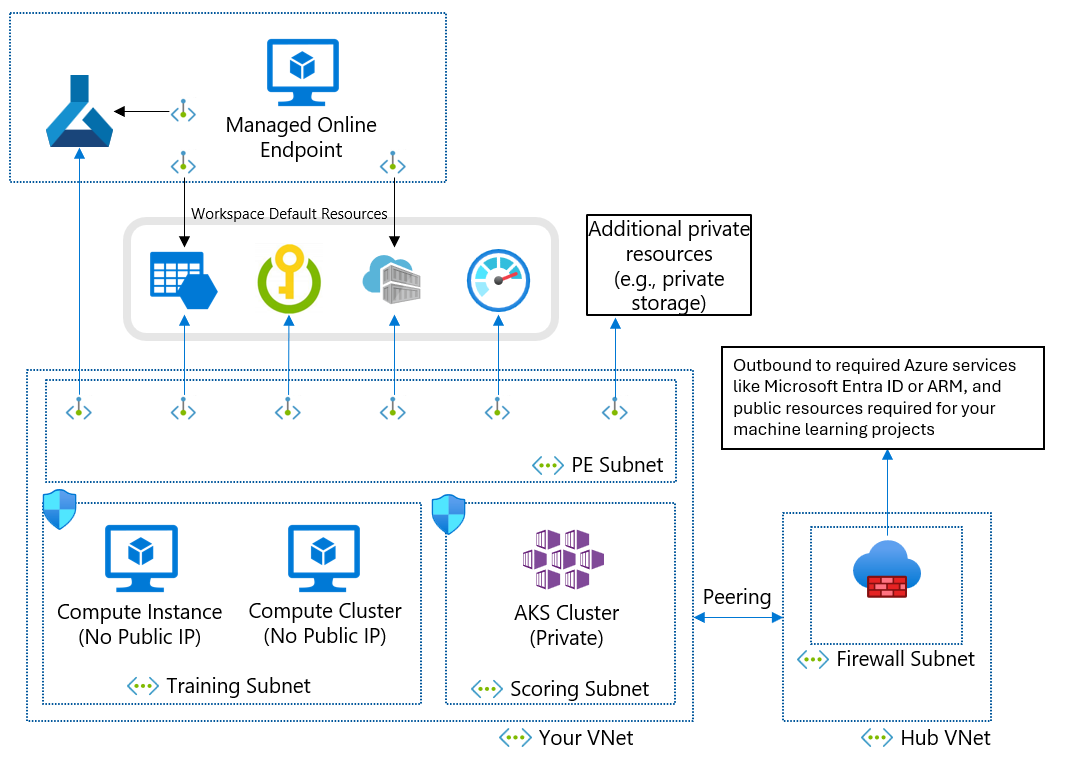
Det virtuella nätverket innehåller också en privat slutpunkt för din maskininlärningsarbetsyta och följande beroende tjänster:
- Azure-lagringskonto
- Azure Key Vault
- Azure Container Registry
Utgående kommunikation från det virtuella nätverket måste kunna nå följande Microsoft-tjänster:
- Maskininlärning
- Microsoft Entra ID
- Azure Container Registry och specifika register som Microsoft underhåller
- Azure Front Door
- Azure Resource Manager
- Azure Storage
Fjärrklienter ansluter till det virtuella nätverket med hjälp av Azure ExpressRoute eller en VPN-anslutning (virtual private network).
Design av virtuellt nätverk och privat slutpunkt
När du utformar ett virtuellt Azure-nätverk, undernät och privata slutpunkter bör du tänka på följande krav:
I allmänhet skapar du separata undernät för träning och bedömning och använder träningsundernätet för alla privata slutpunkter.
För IP-adressering behöver beräkningsinstanser en privat IP-adress vardera. Beräkningskluster behöver en privat IP-adress per nod. AKS-kluster behöver många privata IP-adresser, enligt beskrivningen i Planera IP-adressering för ditt AKS-kluster. Ett separat undernät för minst AKS hjälper till att förhindra överbelastning av IP-adresser.
Beräkningsresurserna i undernäten för träning och bedömning måste komma åt lagringskontot, nyckelvalvet och containerregistret. Skapa privata slutpunkter för lagringskontot, nyckelvalvet och containerregistret.
Standardlagring för maskininlärningsarbetsyta behöver två privata slutpunkter, en för Azure Blob Storage och en annan för Azure File Storage.
Om du använder Azure Machine Learning-studio ska de privata slutpunkterna för arbetsyta och lagring finnas i samma virtuella nätverk.
Om du har flera arbetsytor använder du ett virtuellt nätverk för varje arbetsyta för att skapa en explicit nätverksgräns mellan arbetsytor.
Använda privata IP-adresser
Privata IP-adresser minimerar dina Azure-resursers exponering mot Internet. Maskininlärning använder många Azure-resurser och den privata slutpunkten för maskininlärningsarbetsytan räcker inte för privat IP från slutpunkt till slutpunkt. I följande tabell visas de större resurser som maskininlärning använder och hur du aktiverar privat IP för resurserna. Beräkningsinstanser och beräkningskluster är de enda resurser som inte har den privata IP-funktionen.
| Resurser | Privat IP-lösning | Dokumentation |
|---|---|---|
| Arbetsyta | Privat slutpunkt | Konfigurera en privat slutpunkt för en Azure Machine Learning-arbetsyta |
| Register | Privat slutpunkt | Nätverksisolering med Azure Machine Learning-register |
| Associerade resurser | ||
| Lagring | Privat slutpunkt | Skydda Azure Storage-konton med tjänstslutpunkter |
| Key Vault | Privat slutpunkt | Skydda Azure Key Vault |
| Container Registry | Privat slutpunkt | Aktivera Azure Container Registry |
| Utbildningsresurser | ||
| Beräkningsinstans | Privat IP -adress (ingen offentlig IP-adress) | Säkra träningsmiljöer |
| Beräkningskluster | Privat IP -adress (ingen offentlig IP-adress) | Säkra träningsmiljöer |
| Värdresurser | ||
| Hanterad onlineslutpunkt | Privat slutpunkt | Nätverksisolering med hanterade onlineslutpunkter |
| Onlineslutpunkt (Kubernetes) | Privat slutpunkt | Skydda Azure Kubernetes Service-slutpunkter online |
| Batch-slutpunkter | Privat IP (ärvt från beräkningskluster) | Nätverksisolering i batchslutpunkter |
Kontrollera inkommande och utgående trafik för virtuella nätverk
Använd en brandvägg eller azure-nätverkssäkerhetsgrupp (NSG) för att styra inkommande och utgående trafik i virtuella nätverk. Mer information om krav för inkommande och utgående trafik finns i Konfigurera inkommande och utgående nätverkstrafik. Mer information om trafikflöden mellan komponenter finns i Nätverkstrafikflöde på en säker arbetsyta.
Se till att du har åtkomst till din arbetsyta
Utför följande steg för att säkerställa att din privata slutpunkt kan komma åt din maskininlärningsarbetsyta:
Kontrollera att du har åtkomst till ditt virtuella nätverk med hjälp av en VPN-anslutning, ExpressRoute eller en virtuell jump box-dator (VM) med Azure Bastion-åtkomst. Den offentliga användaren kan inte komma åt arbetsytan för maskininlärning med den privata slutpunkten eftersom den endast kan nås från ditt virtuella nätverk. Mer information finns i Skydda din arbetsyta med virtuella nätverk.
Kontrollera att du kan matcha arbetsytans fullständigt kvalificerade domännamn (FQDN) med din privata IP-adress. Om du använder en egen DNS-server (Domain Name System) eller en centraliserad DNS-infrastruktur måste du konfigurera en DNS-vidarebefordrare. Mer information finns i Så här använder du din arbetsyta med en anpassad DNS-server.
Åtkomsthantering för arbetsyta
När du definierar kontroller för maskininlärningsidentitet och åtkomsthantering kan du separera kontroller som definierar åtkomst till Azure-resurser från kontroller som hanterar åtkomst till datatillgångar. Beroende på ditt användningsfall bör du överväga om du vill använda självbetjäning, datacentrerad eller projektcentrerad identitets- och åtkomsthantering.
Självbetjäningsmönster
I ett självbetjäningsmönster kan dataexperter skapa och hantera arbetsytor. Det här mönstret passar bäst för proof-of-concept-situationer som kräver flexibilitet för att prova olika konfigurationer. Nackdelen är att dataexperter behöver expertis för att etablera Azure-resurser. Den här metoden är mindre lämplig när strikt kontroll, resursanvändning, granskningsspårningar och dataåtkomst krävs.
Definiera Azure-principer för att ange skydd för resursetablering och användning, till exempel tillåtna klusterstorlekar och VM-typer.
Skapa en resursgrupp för att hålla arbetsytorna och ge dataforskare en deltagarroll i resursgruppen.
Dataforskare kan nu skapa arbetsytor och associera resurser i resursgruppen på ett självbetjäningssätt.
För att få åtkomst till datalagring skapar du användartilldelade hanterade identiteter och beviljar identiteterna läsåtkomstroller i lagringen.
När dataexperter skapar beräkningsresurser kan de tilldela hanterade identiteter till beräkningsinstanserna för att få dataåtkomst.
Metodtips finns i Autentisering för analys i molnskala.
Datacentrerade mönster
I ett datacentrerat mönster tillhör arbetsytan en enskild dataexpert som kanske arbetar med flera projekt. Fördelen med den här metoden är att dataexperten kan återanvända kod- eller träningspipelines i olika projekt. Så länge arbetsytan är begränsad till en enskild användare kan dataåtkomst spåras tillbaka till den användaren vid granskning av lagringsloggar.
Nackdelen är att dataåtkomsten inte är uppdelad eller begränsad per projekt, och alla användare som läggs till på arbetsytan kan komma åt samma tillgångar.
Skapa arbetsytan.
Skapa beräkningsresurser med systemtilldelade hanterade identiteter aktiverade.
När en dataexpert behöver åtkomst till data för ett visst projekt ska du ge den beräkningshanterade identiteten läsbehörighet till data.
Ge den beräkningshanterade identiteten åtkomst till andra nödvändiga resurser, till exempel ett containerregister med anpassade Docker-avbildningar för träning.
Bevilja även arbetsytans hanterade identitet läsåtkomstroll för data för att aktivera dataförhandsgranskning.
Ge dataexperten åtkomst till arbetsytan.
Dataexperten kan nu skapa datalager för att komma åt data som krävs för projekt och skicka träningskörningar som använder data.
Du kan också skapa en Microsoft Entra-säkerhetsgrupp och ge den läsbehörighet till data och sedan lägga till hanterade identiteter i säkerhetsgruppen. Den här metoden minskar antalet direkta rolltilldelningar för resurser för att undvika att prenumerationsgränsen för rolltilldelningar nårs.
Projektcentrerade mönster
Ett projektcentrerat mönster skapar en maskininlärningsarbetsyta för ett visst projekt och många dataforskare samarbetar inom samma arbetsyta. Dataåtkomst är begränsad till det specifika projektet, vilket gör metoden lämplig för att arbeta med känsliga data. Det är också enkelt att lägga till eller ta bort dataexperter från projektet.
Nackdelen med den här metoden är att det kan vara svårt att dela tillgångar mellan projekt. Det är också svårt att spåra dataåtkomst till specifika användare under granskningar.
Skapa arbetsytan
Identifiera datalagringsinstanser som krävs för projektet, skapa en användartilldelad hanterad identitet och ge identiteten läsbehörighet till lagringen.
Du kan också ge arbetsytans hanterade identitet åtkomst till datalagring för att tillåta förhandsversion av data. Du kan utelämna den här åtkomsten för känsliga data som inte är lämpliga för förhandsversion.
Skapa datalager utan autentiseringsuppgifter för lagringsresurserna.
Skapa beräkningsresurser på arbetsytan och tilldela den hanterade identiteten till beräkningsresurserna.
Ge den beräkningshanterade identiteten åtkomst till andra nödvändiga resurser, till exempel ett containerregister med anpassade Docker-avbildningar för träning.
Ge dataforskare som arbetar med projektet en roll på arbetsytan.
Genom att använda rollbaserad åtkomstkontroll i Azure (RBAC) kan du hindra dataforskare från att skapa nya datalager eller nya beräkningsresurser med olika hanterade identiteter. Den här metoden förhindrar åtkomst till data som inte är specifika för projektet.
Om du vill förenkla hanteringen av projektmedlemskap kan du skapa en Microsoft Entra-säkerhetsgrupp för projektmedlemmar och ge gruppen åtkomst till arbetsytan.
Azure Data Lake Storage med genomströmning för autentiseringsuppgifter
Du kan använda Microsoft Entra-användaridentitet för interaktiv lagringsåtkomst från Machine Learning Studio. Data Lake Storage med hierarkiskt namnområde aktiverat möjliggör förbättrad organisation av datatillgångar för lagring och samarbete. Med hierarkiskt namnområde för Data Lake Storage kan du dela upp dataåtkomst genom att ge olika användare åtkomstkontrollista (ACL)-baserad åtkomst till olika mappar och filer. Du kan till exempel endast bevilja en delmängd användare åtkomst till konfidentiella data.
RBAC och anpassade roller
Azure RBAC hjälper dig att hantera vem som har åtkomst till maskininlärningsresurser och konfigurera vem som kan utföra åtgärder. Du kanske till exempel bara vill ge specifika användare rollen som arbetsyteadministratör för att hantera beräkningsresurser.
Åtkomstomfånget kan skilja sig åt mellan miljöer. I en produktionsmiljö kanske du vill begränsa användarnas möjlighet att uppdatera slutsatsdragningsslutpunkter. I stället kan du bevilja den behörigheten till ett auktoriserat huvudnamn för tjänsten.
Maskininlärning har flera standardroller: ägare, deltagare, läsare och dataexpert. Du kan också skapa egna anpassade roller, till exempel för att skapa behörigheter som återspeglar organisationens struktur. Mer information finns i Hantera åtkomst till Azure Machine Learning-arbetsyta.
Med tiden kan teamets sammansättning ändras. Om du skapar en Microsoft Entra-grupp för varje grupproll och arbetsyta kan du tilldela en Azure RBAC-roll till Microsoft Entra-gruppen och hantera resursåtkomst och användargrupper separat.
Användarens huvudnamn och tjänstens huvudnamn kan ingå i samma Microsoft Entra-grupp. När du till exempel skapar en användartilldelad hanterad identitet som Azure Data Factory använder för att utlösa en maskininlärningspipeline kan du inkludera den hanterade identiteten i en ML-pipelines-köre eller Microsoft Entra-grupp.
Central Docker-avbildningshantering
Azure Machine Learning tillhandahåller utvalda Docker-avbildningar som du kan använda för utbildning och distribution. Kraven på företagsefterlevnad kan dock kräva att du använder avbildningar från en privat lagringsplats som företaget hanterar. Maskininlärning har två sätt att använda en central lagringsplats:
Använd avbildningarna från en central lagringsplats som basavbildningar. Hantering av maskininlärningsmiljön installerar paket och skapar en Python-miljö där tränings- eller slutsatsdragningskoden körs. Med den här metoden kan du enkelt uppdatera paketberoenden utan att ändra basavbildningen.
Använd avbildningarna som de är, utan att använda maskininlärningsmiljöhantering. Den här metoden ger dig en högre grad av kontroll men kräver också att du noggrant konstruerar Python-miljön som en del av avbildningen. Du måste uppfylla alla nödvändiga beroenden för att köra koden, och eventuella nya beroenden kräver att avbildningen återskapas.
Mer information finns i Hantera miljöer.
Datakryptering
Vilande maskininlärningsdata har två datakällor:
Lagringen innehåller alla dina data, inklusive träningsdata och tränade modelldata, förutom metadata. Du ansvarar för lagringskryptering.
Azure Cosmos DB innehåller dina metadata, inklusive körningshistorikinformation som experimentnamn och experimentöverföringsdatum och -tid. På de flesta arbetsytor finns Azure Cosmos DB i Microsoft-prenumerationen och krypteras av en Microsoft-hanterad nyckel.
Om du vill kryptera dina metadata med din egen nyckel kan du använda en kundhanterad nyckelarbetsyta. Nackdelen är att du måste ha Azure Cosmos DB i din prenumeration och betala dess kostnad. Mer information finns i Datakryptering med Azure Machine Learning.
Information om hur Azure Machine Learning krypterar data under överföring finns i Kryptering under överföring.
Övervakning
När du distribuerar maskininlärningsresurser konfigurerar du loggnings- och granskningskontroller för observerbarhet. Motivationen för att observera data kan variera beroende på vem som tittar på data. Scenarier är:
Maskininlärningsutövare eller driftteam vill övervaka hälsotillståndet för pipelinen för maskininlärning. Dessa observatörer behöver förstå problem med schemalagd körning eller problem med datakvalitet eller förväntade träningsprestanda. Du kan skapa Azure-instrumentpaneler som övervakar Azure Machine Learning-data eller skapar händelsedrivna arbetsflöden.
Kapacitetshanterare, maskininlärningsansvariga eller driftsteam kanske vill skapa en instrumentpanel för att observera beräknings- och kvotanvändning. Om du vill hantera en distribution med flera Azure Machine Learning-arbetsytor kan du skapa en central instrumentpanel för att förstå kvotanvändningen. Kvoter hanteras på prenumerationsnivå, så den miljöomfattande vyn är viktig för att driva optimering.
IT- och driftteam kan konfigurera diagnostikloggning för att granska resursåtkomst och ändra händelser på arbetsytan.
Överväg att skapa instrumentpaneler som övervakar övergripande infrastrukturhälsa för maskininlärning och beroende resurser, till exempel lagring. Om du till exempel kombinerar Azure Storage-mått med pipelinekörningsdata kan du optimera infrastrukturen för bättre prestanda eller identifiera rotorsaken till problemet.
Azure samlar in och lagrar plattformsmått och aktivitetsloggar automatiskt. Du kan dirigera data till andra platser med hjälp av en diagnostikinställning. Konfigurera diagnostikloggning till en centraliserad Log Analytics-arbetsyta för observerbarhet i flera arbetsyteinstanser. Använd Azure Policy för att automatiskt konfigurera loggning för nya maskininlärningsarbetsytor till den här centrala Log Analytics-arbetsytan.
Azure Policy
Du kan framtvinga och granska användningen av säkerhetsfunktioner på arbetsytor via Azure Policy. Här är några rekommendationer:
- Framtvinga anpassad hanterad nyckelkryptering.
- Framtvinga Azure Private Link och privata slutpunkter.
- Framtvinga privata DNS-zoner.
- Inaktivera icke-Azure AD-autentisering, till exempel Secure Shell (SSH).
Mer information finns i Inbyggda principdefinitioner för Azure Machine Learning.
Du kan också använda anpassade principdefinitioner för att styra säkerheten på arbetsytan på ett flexibelt sätt.
Beräkningskluster och instanser
Följande överväganden och rekommendationer gäller för beräkningskluster och instanser för maskininlärning.
Diskkryptering
Operativsystemdisken (OS) för en beräkningsinstans eller beräkningsklusternod lagras i Azure Storage och krypteras med Microsoft-hanterade nycklar. Varje nod har också en lokal tillfällig disk. Den tillfälliga disken krypteras också med Microsoft-hanterade nycklar om arbetsytan skapades med parametern hbi_workspace = True . Mer information finns i Datakryptering med Azure Machine Learning.
Hanterad identitet
Beräkningskluster stöder användning av hanterade identiteter för att autentisera till Azure-resurser. Med hjälp av en hanterad identitet för klustret kan autentisering till resurser utan att exponera autentiseringsuppgifter i koden. Mer information finns i Skapa ett Azure Machine Learning-beräkningskluster.
Installationsskript
Du kan använda ett installationsskript för att automatisera anpassningen och konfigurationen av beräkningsinstanser när de skapas. Som administratör kan du skriva ett anpassningsskript som ska användas när du skapar alla beräkningsinstanser på en arbetsyta. Du kan använda Azure Policy för att framtvinga användningen av installationsskriptet för att skapa varje beräkningsinstans. Mer information finns i Skapa och hantera en Azure Machine Learning-beräkningsinstans.
Skapa på uppdrag av
Om du inte vill att dataexperter ska etablera beräkningsresurser kan du skapa beräkningsinstanser för deras räkning och tilldela dem till dataexperterna. Mer information finns i Skapa och hantera en Azure Machine Learning-beräkningsinstans.
Privat slutpunktsaktiverad arbetsyta
Använd beräkningsinstanser med en privat slutpunktsaktiverad arbetsyta. Beräkningsinstansen avvisar all offentlig åtkomst utanför det virtuella nätverket. Den här konfigurationen förhindrar också paketfiltrering.
Stöd för Azure-princip
När du använder ett virtuellt Azure-nätverk kan du använda Azure Policy för att säkerställa att varje beräkningskluster eller instans skapas i ett virtuellt nätverk och anger det virtuella standardnätverket och undernätet. Principen behövs inte när du använder ett hanterat virtuellt nätverk eftersom beräkningsresurserna skapas automatiskt i det hanterade virtuella nätverket.
Du kan också använda en princip för att inaktivera icke-Azure AD-autentisering, till exempel SSH.
Nästa steg
Läs mer om säkerhetskonfigurationer för maskininlärning:
Kom igång med en mallbaserad distribution baserad på maskininlärning:
Läs fler artiklar om arkitekturöverväganden för att distribuera maskininlärning:
Lär dig hur teamstruktur, miljö eller regionala begränsningar påverkar konfigurationen av arbetsytor.
Se hur du hanterar beräkningskostnader och budgetar mellan team och användare.
Lär dig mer om Machine Learning DevOps (MLOps), som använder en kombination av människor, processer och teknik för att leverera robusta, tillförlitliga och automatiserade maskininlärningslösningar.