Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Gremlin
Gremlin
Viktigt!
Spegling av Azure Cosmos DB i Microsoft Fabric är nu tillgängligt för NoSql API. Den här funktionen ger alla funktioner i Azure Synapse Link med bättre analytiska prestanda, möjlighet att förena din dataegendom med Fabric OneLake och öppna åtkomsten till dina data i Delta Parquet-format. Om du överväger Azure Synapse Link rekommenderar vi att du provar spegling för att utvärdera den övergripande anpassningen för din organisation. Kom igång med spegling i Microsoft Fabric.
Kom igång med Azure Synapse Link genom att gå till Komma igång med Azure Synapse Link
Azure Cosmos DB-analysarkivet är ett helt isolerat kolumnlager för att aktivera storskalig analys mot driftdata i Azure Cosmos DB, utan att påverka dina transaktionsarbetsbelastningar.
Azure Cosmos DB-transaktionsarkivet är schemaagnostiskt och gör att du kan iterera i dina transaktionsprogram utan att behöva hantera schema- eller indexhantering. Till skillnad från detta schemaiseras Azure Cosmos DB-analysarkivet för att optimera för analysfrågasprestanda. Den här artikeln beskriver i detalj om analytisk lagring.
Utmaningar med storskalig analys av driftdata
Driftdata för flera modeller i en Azure Cosmos DB-container lagras internt i ett indexerat radbaserat "transaktionslager". Radlagringsformatet är utformat för att tillåta snabba transaktionsläsningar och skrivningar i svarstiderna för millisekunder och driftsfrågor. Om din datamängd blir stor kan komplexa analysfrågor vara dyra när det gäller etablerat dataflöde på data som lagras i det här formatet. Hög förbrukning av etablerat dataflöde påverkar i sin tur prestandan för transaktionsarbetsbelastningar som används av dina realtidsprogram och -tjänster.
För att analysera stora mängder data extraheras driftdata traditionellt från Azure Cosmos DB:s transaktionslager och lagras i ett separat datalager. Data lagras till exempel i ett informationslager eller en datasjö i ett lämpligt format. Dessa data används senare för storskalig analys och analyseras med beräkningsmotorer som Apache Spark-kluster. Separationen av analys från driftdata leder till fördröjningar för analytiker som vill använda de senaste data.
ETL-pipelines blir också komplexa när du hanterar uppdateringar av driftdata jämfört med att endast hantera nyligen inmatade driftdata.
Kolumnorienterat analysarkiv
Azure Cosmos DB-analysarkivet hanterar de komplexitets- och svarstidsutmaningar som uppstår med de traditionella ETL-pipelines. Azure Cosmos DB-analysarkivet kan automatiskt synkronisera dina driftdata till ett separat kolumnlager. Kolumnlagringsformatet är lämpligt för storskaliga analysfrågor som ska utföras på ett optimerat sätt, vilket ger bättre svarstid för sådana frågor.
Med Azure Synapse Link kan du nu skapa HTAP-lösningar utan ETL genom att länka direkt till Azure Cosmos DB-analysarkivet från Azure Synapse Analytics. Det gör att du kan köra storskaliga analyser i nära realtid på dina driftdata.
Funktioner i analysarkivet
När du aktiverar analysarkiv i en Azure Cosmos DB-container skapas ett nytt kolumnlager internt baserat på driftdata i containern. Det här kolumnarkivet sparas separat från det radorienterade transaktionsarkivet för containern, i ett lagringskonto som hanteras helt av Azure Cosmos DB, i en intern prenumeration. Kunder behöver inte ägna tid åt lagringsadministration. Infogningar, uppdateringar och borttagningar till dina driftdata synkroniseras automatiskt till analysarkivet. Du behöver inte ändringsflöde eller ETL för att synkronisera data.
Kolumnlager för analytiska arbetsbelastningar på driftdata
Analytiska arbetsbelastningar omfattar vanligtvis aggregeringar och sekventiella genomsökningar av valda fält. Dataanalyslagret lagras i en kolumn-större ordning, vilket gör att värden för varje fält kan serialiseras tillsammans, om tillämpligt. Det här formatet minskar det IOPS som krävs för att skanna eller beräkna statistik över specifika fält. Det förbättrar frågesvarstiderna dramatiskt för genomsökningar över stora datamängder.
Om dina drifttabeller till exempel har följande format:
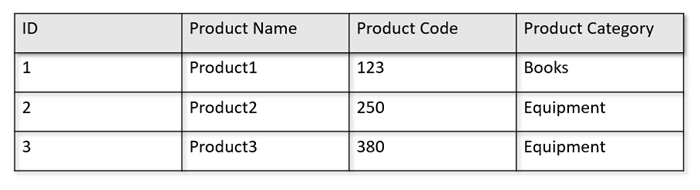
Radlagret bevarar ovanstående data i serialiserat format, per rad, på disken. Det här formatet möjliggör snabbare transaktionsläsningar, skrivningar och driftfrågor, till exempel "Returnera information om produkt 1". Men eftersom datamängden blir stor och om du vill köra komplexa analysfrågor på data kan det vara dyrt. Om du till exempel vill få "försäljningstrenderna för en produkt under kategorin "Utrustning" för olika affärsenheter och månader måste du köra en komplex fråga. Stora genomsökningar på den här datamängden kan bli dyra när det gäller etablerat dataflöde och kan också påverka prestandan för de transaktionsarbetsbelastningar som driver dina realtidsprogram och -tjänster.
Analysarkivet, som är ett kolumnlager, passar bättre för sådana frågor eftersom det serialiserar liknande datafält tillsammans och minskar diskens IOPS.
Följande bild visar transaktionsradslager jämfört med analyskolumnarkiv i Azure Cosmos DB:
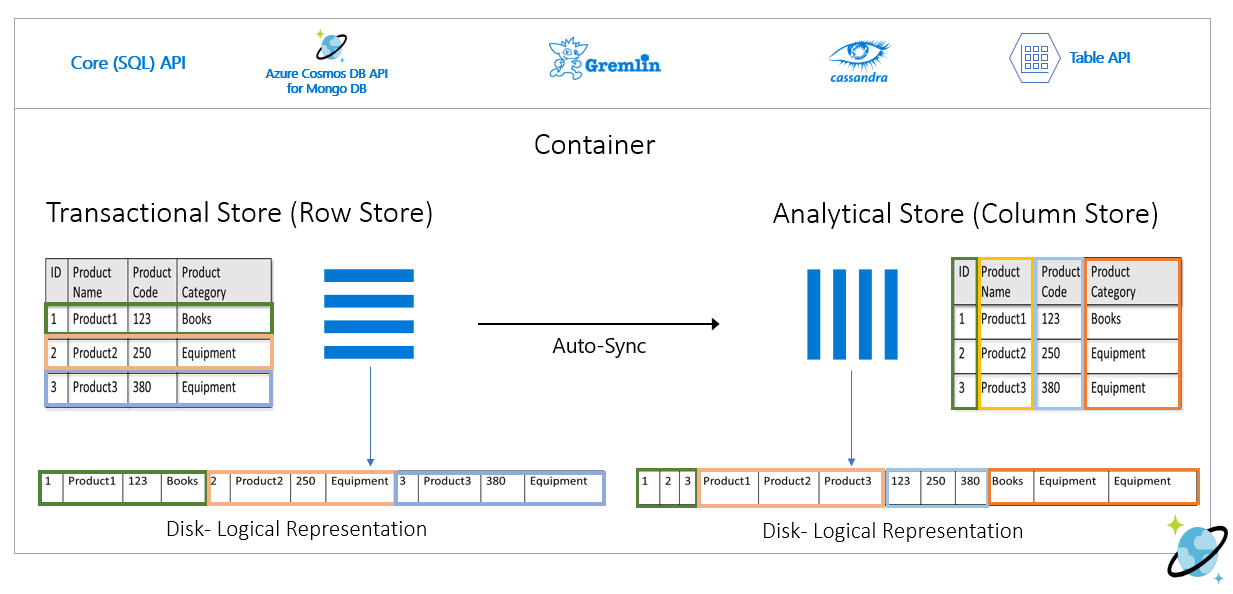
Frikopplade prestanda för analytiska arbetsbelastningar
Det påverkar inte prestandan för dina transaktionsarbetsbelastningar på grund av analysfrågor, eftersom analysarkivet är separat från transaktionslagret. Analysarkivet behöver inte separata enheter för begäranden (RU:er) som ska allokeras.
Automatisk synkronisering
Autosynkronisering refererar till den fullständigt hanterade funktionen i Azure Cosmos DB där infogningar, uppdateringar, borttagningar till driftdata automatiskt synkroniseras från transaktionslager till analysarkiv nästan i realtid. Svarstiden för automatisk synkronisering är vanligtvis inom 2 minuter. Vid databas med delat dataflöde med ett stort antal containrar kan svarstiden för automatisk synkronisering av enskilda containrar vara högre och ta upp till 5 minuter.
I slutet av varje körning av den automatiska synkroniseringsprocessen blir dina transaktionsdata omedelbart tillgängliga för Azure Synapse Analytics-körningar:
Azure Synapse Analytics Spark-pooler kan läsa alla data, inklusive de senaste uppdateringarna, via Spark-tabeller, som uppdateras automatiskt eller via
spark.readkommandot, som alltid läser det sista tillståndet för data.Azure Synapse Analytics SQL Serverless-pooler kan läsa alla data, inklusive de senaste uppdateringarna, via vyer, som uppdateras automatiskt eller via
SELECTtillsammans medOPENROWSETkommandona, som alltid läser den senaste statusen för data.
Kommentar
Dina transaktionsdata synkroniseras till analysarkivet även om TTL (transactional time-to-live) är mindre än 2 minuter.
Kommentar
Observera att om du tar bort containern tas även analysarkivet bort.
Skalbarhet och elasticitet
Azure Cosmos DB-transaktionsarkivet använder horisontell partitionering för att elastiskt skala lagringen och dataflödet utan avbrott. Horisontell partitionering i transaktionslagret ger skalbarhet och elasticitet i automatisk synkronisering för att säkerställa att data synkroniseras till analysarkivet nästan i realtid. Datasynkroniseringen sker oavsett transaktionstrafikens dataflöde, oavsett om det är 1 000 åtgärder per sekund eller 1 miljon åtgärder per sekund och det påverkar inte det etablerade dataflödet i transaktionslagret.
Hantera schemauppdateringar automatiskt
Azure Cosmos DB-transaktionsarkivet är schemaagnostiskt och gör att du kan iterera i dina transaktionsprogram utan att behöva hantera schema- eller indexhantering. Till skillnad från detta schemaiseras Azure Cosmos DB-analysarkivet för att optimera för analysfrågasprestanda. Med funktionen för automatisk synkronisering hanterar Azure Cosmos DB schemainferensen för de senaste uppdateringarna från transaktionsarkivet. Den hanterar även schemarepresentationen i analysarkivet, vilket innefattar hantering av kapslade datatyper.
När schemat utvecklas och nya egenskaper läggs till över tid, visar analysarkivet automatiskt ett unioniserat schema över alla historiska scheman i transaktionsarkivet.
Kommentar
I samband med analysarkivet betraktar vi följande strukturer som egenskap:
- JSON-element eller sträng/värde-par avgränsade med "
:. - JSON-objekt avgränsade av
{och}. - JSON-matriser avgränsade av
[och].
Schemabegränsningar
Följande begränsningar gäller för driftdata i Azure Cosmos DB när du aktiverar analysarkivet för att automatiskt härleda och representera schemat korrekt:
Du kan ha högst 1 000 egenskaper på alla kapslade nivåer i dokumentschemat och ett maximalt kapslingsdjup på 127.
- Endast de första 1 000 egenskaperna representeras i analysarkivet.
- Endast de första 127 kapslade nivåerna representeras i analysarkivet.
- Den första nivån i ett JSON-dokument är dess
/rotnivå. - Egenskaper på den första nivån i dokumentet representeras som kolumner.
Exempelscenarier:
- Om dokumentets första nivå har 2 000 egenskaper representerar synkroniseringsprocessen de första 1 000.
- Om dina dokument har fem nivåer med 200 egenskaper i var och en representerar synkroniseringsprocessen alla egenskaper.
- Om dina dokument har 10 nivåer med 400 egenskaper i var och en representerar synkroniseringsprocessen helt de två första nivåerna och endast hälften av den tredje nivån.
Det hypotetiska dokumentet nedan innehåller fyra egenskaper och tre nivåer.
- Nivåerna är
root,myArrayoch den kapslade strukturen imyArray. - Egenskaperna är
id,myArray,myArray.nested1ochmyArray.nested2. - Representationen av analysarkivet har två kolumner,
id, ochmyArray. Du kan använda Spark- eller T-SQL-funktioner för att även exponera de kapslade strukturerna som kolumner.
- Nivåerna är
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
JSON-dokument (och Azure Cosmos DB-samlingar/containrar) är skiftlägeskänsliga ur unikhetsperspektiv, men analysarkivet är inte det.
-
I samma dokument: Egenskapsnamn på samma nivå ska vara unika när skiftlägeskänsligt jämförs. Följande JSON-dokument har till exempel "Namn" och "namn" på samma nivå. Även om det är ett giltigt JSON-dokument uppfyller det inte unikhetsbegränsningen och visas därför inte helt i analysarkivet. I det här exemplet är "Namn" och "namn" samma när de jämförs på ett skiftlägesokänsligt sätt. Endast
"Name": "fred"representeras i analysarkivet eftersom det är den första förekomsten. Och"name": "john"kommer inte att representeras alls.
{"id": 1, "Name": "fred", "name": "john"}-
I olika dokument: Egenskaper på samma nivå och med samma namn, men i olika fall, representeras i samma kolumn med hjälp av namnformatet för den första förekomsten. Följande JSON-dokument har
"Name"till exempel och"name"på samma nivå. Eftersom det första dokumentformatet är"Name"används det här för att representera egenskapsnamnet i analysarkivet. Kolumnnamnet i analysarkivet blir"Name"med andra ord . Både"fred"och"john"kommer att representeras i"Name"kolumnen.
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}-
I samma dokument: Egenskapsnamn på samma nivå ska vara unika när skiftlägeskänsligt jämförs. Följande JSON-dokument har till exempel "Namn" och "namn" på samma nivå. Även om det är ett giltigt JSON-dokument uppfyller det inte unikhetsbegränsningen och visas därför inte helt i analysarkivet. I det här exemplet är "Namn" och "namn" samma när de jämförs på ett skiftlägesokänsligt sätt. Endast
Det första dokumentet i samlingen definierar det första analysarkivschemat.
- Dokument med fler egenskaper än det ursprungliga schemat genererar nya kolumner i analysarkivet.
- Det går inte att ta bort kolumner.
- Borttagningen av alla dokument i en samling återställer inte schemat för analysarkivet.
- Det finns ingen schemaversionering. Den senaste versionen som härleds från transaktionsarkivet är det du ser i analysarkivet.
För närvarande kan Azure Synapse Spark inte läsa egenskaper som innehåller vissa specialtecken i deras namn, som anges nedan. Azure Synapse SQL Serverless påverkas inte.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Kommentar
Blanksteg visas också i Spark-felmeddelandet som returneras när du når den här begränsningen. Men vi har lagt till en särskild behandling för vita utrymmen, kolla in mer information i objekten nedan.
- Om du har egenskapsnamn med hjälp av tecknen ovan är alternativen:
- Ändra datamodellen i förväg för att undvika dessa tecken.
- Eftersom vi för närvarande inte stöder schemaåterställning kan du ändra ditt program för att lägga till en redundant egenskap med ett liknande namn, vilket undviker dessa tecken.
- Använd Ändringsflöde för att skapa en materialiserad vy av containern utan dessa tecken i egenskapsnamn.
- Använd Spark-alternativet
dropColumnför att ignorera de berörda kolumnerna och läsa in alla andra kolumner i en DataFrame. Syntax:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark har nu stöd för egenskaper med blanksteg i sina namn. För det måste du använda
allowWhiteSpaceInFieldNamesalternativet Spark för att läsa in de berörda kolumnerna i en DataFrame och behålla det ursprungliga namnet. Syntax:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
Följande BSON-datatyper stöds inte och visas inte i analysarkivet:
- Decimal 128
- Reguljärt uttryck
- DB-pekare
- JavaScript
- Symbol
- MinKey/MaxKey
När du använder DateTime-strängar som följer ISO 8601 UTC-standarden kan du förvänta dig följande beteende:
- Spark-pooler i Azure Synapse representerar dessa kolumner som
string. - SQL-serverlösa pooler i Azure Synapse representerar dessa kolumner som
varchar(8000).
- Spark-pooler i Azure Synapse representerar dessa kolumner som
Egenskaper med
UNIQUEIDENTIFIER (guid)typer representeras somstringi analysarkivet och ska konverteras tillVARCHARi SQL eller tillstringi Spark för korrekt visualisering.SQL-serverlösa pooler i Azure Synapse stöder resultatuppsättningar med upp till 1 000 kolumner, och att exponera kapslade kolumner räknas också mot den gränsen. Det är en bra idé att tänka på den här informationen i din transaktionsdataarkitektur och modellering.
Om du byter namn på en egenskap i ett eller flera dokument betraktas den som en ny kolumn. Om du kör samma namnbyte i alla dokument i samlingen migreras alla data till den nya kolumnen och den gamla kolumnen representeras med
NULLvärden.
Schemarepresentation
Det finns två metoder för schemarepresentation i analysarkivet som är giltiga för alla containrar i databaskontot. De har kompromisser mellan enkelheten i frågeupplevelsen jämfört med bekvämligheten med en mer inkluderande kolumnrepresentation för polymorfa scheman.
- Väldefinierad schemarepresentation, standardalternativ för API för NoSQL- och Gremlin-konton.
- Fullständig återgivningsschemarepresentation, standardalternativ för API för MongoDB-konton.
Väldefinierad schemarepresentation
Den väldefinierade schemarepresentationen skapar en enkel tabellrepresentation av schemaagnostiska data i transaktionslagret. Den väldefinierade schemarepresentationen har följande överväganden:
- Det första dokumentet definierar basschemat och egenskaperna måste alltid ha samma typ i alla dokument. De enda undantagen är:
- För SQL-serverlösa pooler i Azure Synapse: Från
NULLtill någon annan datatyp. Den första icke-null-förekomsten definierar kolumndatatypen. Alla dokument som inte följer den första datatypen som inte är null representeras inte i analysarkivet. - För Sparkgrupper och ändringsdatafångst i Azure Data Factory i Azure Synapse: Från
NULLtillINT. Utveckling från null-egenskaper till andra datatyper än INT stöds inte för Spark-pooler och Azure Data Factory Change Data Capture i Azure Synapse. Det första värdet som inte är null måste vara ett heltal och alla dokument med en annan datatyp visas inte i analysarkivet. - Från
floattillinteger. Alla dokument representeras i analysarkivet. - Från
integertillfloat. Alla dokument representeras i analysarkivet. Om du vill läsa dessa data med Serverlösa Pooler i Azure Synapse SQL måste du dock använda en WITH-sats för att konvertera kolumnen tillvarchar. Och efter den här inledande konverteringen går det att konvertera den igen till ett tal. Kontrollera exemplet nedan, där num initialt värde var ett heltal och det andra var ett flyttal.
- För SQL-serverlösa pooler i Azure Synapse: Från
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
Egenskaper som inte följer basschemadatatypen visas inte i analysarkivet. Tänk till exempel på dokumenten nedan: den första definierade basschemat för analysarkivet. Det andra dokumentet, där
idär"2", har inget väldefinierat schema eftersom egenskapen"code"är en sträng och det första dokumentet har"code"som ett tal. I det här fallet registrerar analysarkivet datatypen"code"förintegercontainerns livslängd. Det andra dokumentet kommer fortfarande att ingå i analysarkivet, men dess"code"egenskap kommer inte att göra det.{"id": "1", "code":123}{"id": "2", "code": "123"}
Kommentar
Villkoret ovan gäller inte för NULL egenskaper. Till exempel {"a":123} and {"a":NULL} är fortfarande väldefinierat.
Kommentar
Villkoret ovan ändras inte om du uppdaterar "code" dokumentet "1" till en sträng i transaktionsarkivet. I analysarkivet "code" behålls som integer eftersom vi för närvarande inte stöder schemaåterställning.
- Matristyper måste innehålla en enda upprepad typ. Till exempel
{"a": ["str",12]}är inte ett väldefinierat schema eftersom matrisen innehåller en blandning av heltal och strängtyper.
Kommentar
Om Azure Cosmos DB-analysarkivet följer den väldefinierade schemarepresentationen och specifikationen ovan överträds av vissa objekt inkluderas inte dessa objekt i analysarkivet.
Förvänta dig olika beteende när det gäller olika typer i väldefinierat schema:
- Spark-pooler i Azure Synapse representerar dessa värden som
undefined. - SQL-serverlösa pooler i Azure Synapse representerar dessa värden som
NULL.
- Spark-pooler i Azure Synapse representerar dessa värden som
Förvänta dig ett annat beteende när det gäller explicita
NULLvärden:- Spark-pooler i Azure Synapse läser dessa värden som
0(noll) ochundefinedså snart kolumnen har ett värde som inte är null. - SQL-serverlösa pooler i Azure Synapse läser dessa värden som
NULL.
- Spark-pooler i Azure Synapse läser dessa värden som
Förvänta dig ett annat beteende när det gäller saknade kolumner:
- Spark-pooler i Azure Synapse representerar dessa kolumner som
undefined. - SQL-serverlösa pooler i Azure Synapse representerar dessa kolumner som
NULL.
- Spark-pooler i Azure Synapse representerar dessa kolumner som
Lösningar på representationsutmaningar
Det är möjligt att ett gammalt dokument, med ett felaktigt schema, användes för att skapa containerns basschema för analysarkivet. Baserat på alla regler som visas ovan kan du få NULL för vissa egenskaper när du frågar ditt analysarkiv med Hjälp av Azure Synapse Link. Att ta bort eller uppdatera de problematiska dokumenten hjälper inte eftersom grundläggande schemaåterställning inte stöds för närvarande. Möjliga lösningar är följande:
- Om du vill migrera data till en ny container kontrollerar du att alla dokument har rätt schema.
- Om du vill överge egenskapen med fel schema och lägga till ett nytt med ett annat namn som har rätt schema i alla dokument. Exempel: Du har miljarder dokument i containern Beställningar där statusegenskapen är en sträng. Men det första dokumentet i containern har status definierat med heltal. Så ett dokument har status korrekt representerad och alla andra dokument kommer att ha
NULL. Du kan lägga till egenskapen status2 i alla dokument och börja använda den i stället för den ursprungliga egenskapen.
Fullständig återgivning av schemarepresentation
Den fullständiga återgivningsschemarepresentationen är utformad för att hantera hela bredden av polymorfa scheman i schemaoberoende driftdata. I den här schemarepresentationen tas inga objekt bort från analysarkivet även om de väldefinierade schemabegränsningarna (som inte är några fält av blandad datatyp eller matriser med blandade datatyper) överträds.
Detta uppnås genom att översätta lövegenskaperna för driftdata till analysarkivet som JSON-par key-value , där datatypen är key och egenskapsinnehållet valueär . Den här JSON-objektrepresentationen tillåter frågor utan tvetydighet, och du kan analysera varje datatyp individuellt.
Med andra ord, i den fullständiga återgivningsschemarepresentationen genererar varje datatyp för varje egenskap i varje dokument ett key-valuepar i ett JSON-objekt för den egenskapen. Var och en av dem räknas som en av gränsen på 1 000 maximala egenskaper.
Vi tar till exempel följande exempeldokument i transaktionsarkivet:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
Det kapslade objektet address är en egenskap i dokumentets rotnivå och representeras som en kolumn. Varje lövegenskap i address objektet representeras som ett JSON-objekt: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
Till skillnad från den väldefinierade schemarepresentationen tillåter metoden fullständig återgivning variation i datatyper. Om nästa dokument i den här samlingen av exemplet ovan har streetNo som en sträng representeras det i analysarkivet som "streetNo":{"string":15850}. I en väldefinierad schemametod skulle den inte representeras.
Datatypes-karta för fullständigt återgivningsschema
Här är en karta över MongoDB-datatyper och deras representationer i analysarkivet i fullständig återgivningsschemarepresentation. Kartan nedan är inte giltig för NoSQL API-konton.
| Ursprunglig datatyp | ändelse | Exempel |
|---|---|---|
| Dubbel | ".float64" | 24,99 |
| Matris | .array | ["a", "b"] |
| Binära | ".binary" | 0 |
| Booleskt | ".bool" | Sant |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NOLL | ". NULL" | NOLL |
| Sträng | ".string" | "ABC" |
| Tidsstämpel | ".timestamp" | Tidsstämpel(0, 0) |
| Objekt-ID | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Dokument | .objekt | {"a": "a"} |
Förvänta dig ett annat beteende när det gäller explicita
NULLvärden:- Spark-pooler i Azure Synapse läser dessa värden som
0(noll). - SQL-serverlösa pooler i Azure Synapse läser dessa värden som
NULL.
- Spark-pooler i Azure Synapse läser dessa värden som
Förvänta dig ett annat beteende när det gäller saknade kolumner:
- Spark-pooler i Azure Synapse representerar dessa kolumner som
undefined. - SQL-serverlösa pooler i Azure Synapse representerar dessa kolumner som
NULL.
- Spark-pooler i Azure Synapse representerar dessa kolumner som
Förvänta dig olika beteende när det gäller
timestampvärden:- Spark-pooler i Azure Synapse läser dessa värden som
TimestampType,DateTypeellerFloat. Det beror på intervallet och hur tidsstämpeln genererades. - SQL Serverless-pooler i Azure Synapse läser dessa värden som
DATETIME2, allt från0001-01-01till9999-12-31. Värden utanför det här intervallet stöds inte och orsakar ett körningsfel för dina frågor. Om så är fallet kan du:- Ta bort kolumnen från frågan. Om du vill behålla representationen kan du skapa en ny egenskap som speglar kolumnen men inom det intervall som stöds. Och använd det i dina frågor.
- Använd Change Data Capture från analysarkivet, utan kostnad för RU:er, för att transformera och läsa in data i ett nytt format, inom en av de mottagare som stöds.
- Spark-pooler i Azure Synapse läser dessa värden som
Använda fullständigt återgivningsschema med Spark
Spark hanterar varje datatyp som en kolumn vid inläsning till en DataFrame. Låt oss anta en samling med dokumenten nedan.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Det första dokumentet har rating som tal och timestamp utc-format, men det andra dokumentet har rating och timestamp som strängar. Förutsatt att den här samlingen lästes in utan DataFrame någon datatransformering är utdata från df.printSchema() :
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
I en väldefinierad schemarepresentation skulle både rating och timestamp det andra dokumentet inte representeras. I fullständigt återgivningsschema kan du använda följande exempel för att individuellt komma åt varje värde för varje datatyp.
I exemplet nedan kan vi använda PySpark för att köra en aggregering:
df.groupBy(df.item.string).sum().show()
I exemplet nedan kan vi använda PySQL för att köra en annan aggregering:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Använda fullständigt återgivningsschema med SQL
Du kan använda följande syntaxexempel med samma dokument i Spark-exemplet ovan:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
Du kan implementera transformeringar med hjälp av cast, convert eller någon annan T-SQL-funktion för att ändra dina data. Du kan också dölja komplexa datatypsstrukturer med hjälp av vyer.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Arbeta med MongoDB-fältet _id
MongoDB-fältet _id är grundläggande för varje samling i MongoDB och har ursprungligen en hexadecimal representation. Som du ser i tabellen ovan bevarar schemat för fullständig återgivning dess egenskaper, vilket skapar en utmaning för dess visualisering i Azure Synapse Analytics. För korrekt visualisering måste du konvertera _id datatypen enligt nedan:
Arbeta med MongoDB-fältet _id i Spark
Exemplet nedan fungerar på Spark 2.x- och 3.x-versioner:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Arbeta med MongoDB-fältet _id i SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Arbeta med MongoDB-fältet id
Egenskapen id i MongoDB-containrar åsidosättas automatiskt med Base64-representationen av egenskapen "_id" både i analysarkivet. Fältet "id" är avsett för intern användning av MongoDB-program. För närvarande är den enda lösningen att byta namn på egenskapen "id" till något annat än "id".
Fullständigt återgivningsschema för API för NoSQL- eller Gremlin-konton
Du kan använda fullständigt återgivningsschema för API för NoSQL-konton i stället för standardalternativet genom att ange schematypen när du aktiverar Synapse Link på ett Azure Cosmos DB-konto för första gången. Här följer några saker att tänka på när du ändrar standardschemarepresentationstypen:
- Om du aktiverar Synapse Link i ditt NoSQL API-konto med hjälp av Azure Portal aktiveras det som ett väldefinierat schema.
- Om du för närvarande vill använda fullständigt återgivningsschema med NoSQL- eller Gremlin API-konton måste du ange det på kontonivå i samma CLI- eller PowerShell-kommando som aktiverar Synapse Link på kontonivå.
- För närvarande är Azure Cosmos DB for MongoDB inte kompatibelt med den här möjligheten att ändra schemarepresentationen. Alla MongoDB-konton har en fullständig återgivningsschemarepresentationstyp.
- Karta över fullständiga schemadatatyper för Fidelity som nämns ovan är inte giltig för NoSQL API-konton som använder JSON-datatyper. Till exempel
floatrepresenteras värdenintegersomnumi analysarkivet. - Det går inte att återställa schemarepresentationstypen, från väldefinierad till fullständig återgivning eller vice versa.
- För närvarande definieras containerscheman i analysarkivet när containern skapas, även om Synapse Link inte har aktiverats i databaskontot.
- Containrar eller grafer som skapades innan Synapse Link aktiverades med fullständigt återgivningsschema på kontonivå har ett väldefinierat schema.
- Containrar eller grafer som skapats efter att Synapse Link har aktiverats med fullständigt återgivningsschema på kontonivå har fullständigt återgivningsschema.
Beslutet om schemarepresentationstyp måste fattas samtidigt som Synapse Link är aktiverat för kontot med hjälp av Azure CLI eller PowerShell.
Med Azure CLI:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Kommentar
I kommandot ovan ersätter du create med update för befintliga konton.
Med PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Kommentar
I kommandot ovan ersätter du New-AzCosmosDBAccount med Update-AzCosmosDBAccount för befintliga konton.
TTL (Analytical Time-to-Live)
TTL för analys (ATTL) anger hur länge data ska behållas i analysarkivet för en container.
Analysarkiv aktiveras när ATTL anges med ett annat värde än NULL och 0. När det är aktiverat synkroniseras infogningar, uppdateringar, borttagningar till driftdata automatiskt från transaktionsarkivet till analysarkivet, oavsett TTTL-konfigurationen (transactional TTL). Kvarhållningen av dessa transaktionsdata i analysarkivet kan styras på containernivå av AnalyticalStoreTimeToLiveInSeconds egenskapen.
Möjliga ATTL-konfigurationer är:
Om värdet är inställt på
0: analysarkivet är inaktiverat och inga data replikeras från transaktionslagret till analysarkivet. Öppna ett supportärende för att inaktivera analysarkivet i containrarna.Om fältet utelämnas händer ingenting och det tidigare värdet behålls.
Om värdet är inställt på
-1: behåller analysarkivet alla historiska data, oavsett kvarhållning av data i transaktionslagret. Den här inställningen anger att analysarkivet har oändlig kvarhållning av dina driftdataOm värdet är inställt på ett positivt heltalsnummer
n: objekt upphör att gälla från analysarkivetnsekunder efter den senaste ändrade tiden i transaktionsarkivet. Den här inställningen kan användas om du vill behålla dina driftdata under en begränsad tidsperiod i analysarkivet, oavsett kvarhållning av data i transaktionslagret
Några saker att tänka på:
- När analysarkivet har aktiverats med ett ATTL-värde kan det uppdateras till ett annat giltigt värde senare.
- TTTL kan anges på container- eller objektnivå, men ATTL kan bara anges på containernivå för närvarande.
- Du kan uppnå längre kvarhållning av dina driftdata i analysarkivet genom att ange ATTL >= TTTL på containernivå.
- Analysarkivet kan göras för att spegla transaktionsarkivet genom att ange ATTL = TTTL.
- Om du har ATTL större än TTTL har du någon gång data som bara finns i analysarkivet. Dessa data är skrivskyddade.
- För närvarande tar vi inte bort några data från analysarkivet. Om du anger ditt ATTL till ett positivt heltal inkluderas inte data i dina frågor och du debiteras inte för det. Men om du ändrar ATTL tillbaka till
-1visas alla data igen, du börjar debiteras för all datavolym.
Så här aktiverar du analysarkiv på en container:
Från Azure Portal är ATTL-alternativet, när det är aktiverat, inställt på standardvärdet -1. Du kan ändra det här värdet till "n" sekunder genom att gå till containerinställningarna under Datautforskaren.
Från Azure Management SDK, Azure Cosmos DB SDK:er, PowerShell eller Azure CLI kan ATTL-alternativet aktiveras genom att ange det till -1 eller "n" sekunder.
Mer information finns i konfigurera TTL för analys på en container.
Kostnadseffektiv analys av historiska data
Datanivåindelning avser separation av data mellan lagringsinfrastrukturer som är optimerade för olika scenarier. Förbättra därmed den övergripande prestandan och kostnadseffektiviteten för datastacken från slutpunkt till slutpunkt. Med analysarkivet stöder Azure Cosmos DB nu automatisk nivåindelning av data från transaktionslagret till analysarkivet med olika datalayouter. Med analysarkivet optimerat i förhållande till lagringskostnaden jämfört med transaktionslagret kan du behålla mycket längre horisonter av driftdata för historisk analys.
När analysarkivet har aktiverats, baserat på datakvarhållningsbehoven för transaktionsarbetsbelastningarna, kan du konfigurera transactional TTL egenskapen så att poster tas bort automatiskt från transaktionslagret efter en viss tidsperiod.
analytical TTL På samma sätt kan du hantera livscykeln för data som behålls i analysarkivet, oberoende av transaktionslagret. Genom att aktivera analysarkiv och konfigurera transaktions- och analysegenskaper TTL kan du sömlöst nivåindela och definiera datakvarhållningsperioden för de två arkiven.
Kommentar
När analytical TTL är inställt på ett värde som är större än transactional TTL värdet har containern data som bara finns i analysarkivet. Dessa data är skrivskyddade och för närvarande stöder vi inte dokumentnivå TTL i analysarkivet. Om dina containerdata kan behöva uppdateras eller tas bort någon gång i framtiden ska du inte använda analytical TTL större än transactional TTL. Den här funktionen rekommenderas för data som inte behöver uppdateringar eller borttagningar i framtiden.
Kommentar
Om ditt scenario inte kräver fysiska borttagningar kan du använda en logisk metod för borttagning/uppdatering. Infoga i transaktionsarkivet en annan version av samma dokument som bara finns i analysarkivet men som behöver en logisk borttagning/uppdatering. Kanske med en flagga som anger att det är en borttagning eller en uppdatering av ett dokument som har upphört att gälla. Båda versionerna av samma dokument samexisterar i analysarkivet och ditt program bör bara ta hänsyn till den sista.
Elasticitet
Analysarkivet förlitar sig på Azure Storage och erbjuder följande skydd mot fysiska fel:
- Som standard allokerar Azure Cosmos DB-databaskonton analysarkiv i LRS-konton (Lokalt redundant lagring). LRS ger minst 99,99999999999% (11 nior) hållbarhet för objekt under ett visst år.
- Om någon geo-region för databaskontot har konfigurerats för zonredundans allokeras det i ZRS-konton (Zonredundant lagring). Du måste aktivera Tillgänglighetszoner i en region i deras Azure Cosmos DB-databaskonto för att ha analysdata för den regionen lagrade i zonredundant lagring. ZRS erbjuder hållbarhet för lagringsresurser på minst 99,999999999999 % (12 9) under ett visst år.
Mer information om hållbarhet i Azure Storage finns i den här länken.
Säkerhetskopiering
Även om analysarkivet har inbyggt skydd mot fysiska fel kan säkerhetskopiering vara nödvändigt för oavsiktliga borttagningar eller uppdateringar i transaktionsarkivet. I sådana fall kan du återställa en container och använda den återställde containern för att fylla på data i den ursprungliga containern eller återskapa analysarkivet helt om det behövs.
Kommentar
För närvarande säkerhetskopieras inte analysarkivet, därför kan det inte återställas. Det går inte att planera säkerhetskopieringsprincipen.
Synapse Link och analysarkivet har därför olika kompatibilitetsnivåer med Azure Cosmos DB-säkerhetskopieringslägen:
- Läget för periodisk säkerhetskopiering är helt kompatibelt med Synapse Link och dessa två funktioner kan användas i samma databaskonto.
- Synapse Link för databaskonton som använder läget för kontinuerlig säkerhetskopiering är GA.
- Läget för kontinuerlig säkerhetskopiering för Synapse Link-aktiverade konton är i offentlig förhandsversion. För närvarande kan du inte migrera till kontinuerlig säkerhetskopiering om du inaktiverade Synapse Link på någon av dina samlingar i ett Cosmos DB-konto.
Principer för säkerhetskopiering
Det finns två möjliga säkerhetskopieringsprinciper och för att förstå hur du använder dem är följande information om Azure Cosmos DB-säkerhetskopior mycket viktig:
- Den ursprungliga containern återställs utan analysarkiv i båda säkerhetskopieringslägena.
- Azure Cosmos DB stöder inte containrar som skrivs över från en återställning.
Nu ska vi se hur du använder säkerhetskopiering och återställningar ur analysarkivets perspektiv.
Återställa en container med TTTL >= ATTL
När transactional TTL är lika med eller större än analytical TTLfinns fortfarande alla data i analysarkivet i transaktionsarkivet. Vid en återställning har du två möjliga situationer:
- Så här använder du den återställde containern som ersättning för den ursprungliga containern. Om du vill återskapa analysarkivet aktiverar du bara Synapse Link på kontonivå och containernivå.
- Så här använder du den återställde containern som datakälla för att fylla på eller uppdatera data i den ursprungliga containern. I det här fallet återspeglar analysarkivet automatiskt dataåtgärderna.
Återställa en container med TTTL < ATTL
När transactional TTL är mindre än analytical TTLfinns vissa data bara i analysarkivet och finns inte i den återställde containern. Återigen har du två möjliga situationer:
- Så här använder du den återställde containern som ersättning för den ursprungliga containern. I det här fallet, när du aktiverar Synapse Link på containernivå, inkluderas endast de data som fanns i transaktionslagret i det nya analysarkivet. Observera dock att analysarkivet för den ursprungliga containern fortfarande är tillgängligt för frågor så länge den ursprungliga containern finns. Du kanske vill ändra programmet så att det frågar båda.
- Så här använder du den återställde containern som datakälla för att fylla på eller uppdatera data i den ursprungliga containern:
- Analysarkivet återspeglar automatiskt dataåtgärderna för de data som finns i transaktionsarkivet.
- Om du åter infogar data som tidigare tagits bort från transaktionslagret på grund av
transactional TTLkommer dessa data att dupliceras i analysarkivet.
Exempel:
- Containern
OnlineOrdershar TTTL inställt på en månad och ATTL har angetts för ett år. - När du återställer det till
OnlineOrdersNewoch aktiverar analysarkivet för att återskapa det, kommer det bara att finnas en månads data i både transaktions- och analysarkivet. - Den ursprungliga containern
OnlineOrderstas inte bort och dess analysarkiv är fortfarande tillgängligt. - Nya data matas bara in i
OnlineOrdersNew. - Analytiska frågor kommer att göra en UNION ALL från analyslager medan de ursprungliga data fortfarande är relevanta.
Om du vill ta bort den ursprungliga containern men inte vill förlora sina analyslagringsdata kan du spara analysarkivet för den ursprungliga containern i en annan Azure-datatjänst. Synapse Analytics har möjlighet att utföra kopplingar mellan data som lagras på olika platser. Ett exempel: En Synapse Analytics-fråga kopplar analyslagringsdata till externa tabeller som finns i Azure Blob Storage, Azure Data Lake Store osv.
Det är viktigt att observera att data i analysarkivet har ett annat schema än det som finns i transaktionslagret. Även om du kan generera ögonblicksbilder av dina analyslagringsdata och exportera dem till valfri Azure Data-tjänst, utan kostnader för RU:er, kan vi inte garantera att den här ögonblicksbilden används för att mata tillbaka transaktionslagret. Den här processen stöds inte.
Global spridning
Om du har ett globalt distribuerat Azure Cosmos DB-konto blir det tillgängligt i alla regioner i det kontot när du har aktiverat analysarkiv för en container. Alla ändringar av driftdata replikeras globalt i alla regioner. Du kan köra analysfrågor effektivt mot närmaste regionala kopia av dina data i Azure Cosmos DB.
Partitionering
Partitioneringen av analysarkivet är helt oberoende av partitionering i transaktionsarkivet. Som standard partitioneras inte data i analysarkivet. Om dina analysfrågor har filter som används ofta kan du partitionera baserat på dessa fält för bättre frågeprestanda. Mer information finns i introduktionen till anpassad partitionering och hur du konfigurerar anpassad partitionering.
Säkerhet
Autentisering med analysarkivet – Autentiseringsmetoder som stöds varierar beroende på om nätverksfunktioner är aktiverade.
Nyckelbaserad autentisering: Det här scenariot stöds för alla konton i alla scenarier, inklusive sådana som saknar privata slutpunkter eller VNet aktiverat.
Tjänstens huvudnamn eller hanterad identitet: Användning av Entra-ID eller hanterad identitetsautentisering stöds endast för konton som inte använder privata slutpunkter eller aktiverar Vnet-åtkomst. Om du vill använda den här typen av autentisering måste användarna tillämpa RBAC för dataplanet och skapa en ny endast läsroll med följande dataåtgärder.
- Lägg till en anpassad MyAnalyticsReadOnlyRole med PowerShell och mappa "readMetadata" och "readAnalytics" RBAC-åtgärder till rollen.
$resourceGroupName = "<myResourceGroup>" $accountName = "<myCosmosAccount>" New-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -Type CustomRole -RoleName 'MyAnalyticsReadOnlyRole' ` -DataAction @( ` 'Microsoft.DocumentDB/databaseAccounts/readMetadata', 'Microsoft.DocumentDB/databaseAccounts/readAnalytics' ) ` -AssignableScope "/"- Lista rolldefinitionerna för kontot för att hämta det nya rolldefinitions-ID:t.
$roleDefinitionId = Get-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName- Skapa rolltilldelningen genom att tilldela den nya rollen till Synapse MSI Principal.
$synapsePrincipalId = "<Synapse MSI Principal>" New-AzCosmosDBSqlRoleAssignment -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -RoleDefinitionId $readOnlyRoleDefinitionId ` -Scope "/" ` -PrincipalId $synapsePrincipalId
Nätverksisolering med privata slutpunkter – Du kan styra nätverksåtkomsten till data i transaktions- och analysarkiven oberoende av varandra. Nätverksisolering utförs med separata hanterade privata slutpunkter för varje butik i hanterade virtuella nätverk på Azure Synapse-arbetsytor. Mer information finns i artikeln Konfigurera privata slutpunkter för analysarkiv . Obs! Du måste använda nyckelbaserad autentisering när du aktiverar detta. Se föregående avsnitt.
Vilande datakryptering – Krypteringen för analysarkivet är aktiverad som standard.
Datakryptering med kundhanterade nycklar – Du kan sömlöst kryptera data i transaktions- och analyslager med samma kundhanterade nycklar på ett automatiskt och transparent sätt. Azure Synapse Link stöder endast konfiguration av kundhanterade nycklar med hjälp av ditt Azure Cosmos DB-kontos hanterade identitet. Du måste konfigurera kontots hanterade identitet i din Azure Key Vault-åtkomstprincip innan du aktiverar Azure Synapse Link för ditt konto. Mer information finns i artikeln Konfigurera kundhanterade nycklar med hjälp av Azure Cosmos DB-kontons hanterade identiteter .
Kommentar
Om du ändrar ditt databaskonto från Första part till System eller Användartilldelad Identy och aktiverar Azure Synapse Link i ditt databaskonto kan du inte återgå till identitet från första part eftersom du inte kan inaktivera Synapse Link från ditt databaskonto.
Stöd för flera Azure Synapse Analytics-körningar
Analysarkivet är optimerat för att ge skalbarhet, elasticitet och prestanda för analytiska arbetsbelastningar utan något beroende av beräkningskörningstiderna. Lagringstekniken är självhanterad för att optimera dina analysarbetsbelastningar utan manuella ansträngningar.
Data i Azure Cosmos DB-analysarkivet kan frågas samtidigt från de olika analyskörningar som stöds av Azure Synapse Analytics. Azure Synapse Analytics stöder Apache Spark och serverlös SQL-pool med Azure Cosmos DB-analysarkiv.
Kommentar
Du kan bara läsa från analysarkivet med hjälp av Azure Synapse Analytics-körningar. Och motsatsen är också sant, Azure Synapse Analytics-runtimes kan bara läsa från analysarkivet. Endast processen för automatisk synkronisering kan ändra data i analysarkivet. Du kan skriva tillbaka data till Azure Cosmos DB-transaktionsarkivet med hjälp av Azure Synapse Analytics Spark-poolen med hjälp av den inbyggda Azure Cosmos DB OLTP SDK.
Prissättning
Analysarkivet följer en förbrukningsbaserad prismodell där du debiteras för:
Lagring: mängden data som lagras i analysarkivet varje månad, inklusive historiska data enligt definitionen i TTL för analys.
Analytiska skrivåtgärder: den fullständigt hanterade synkroniseringen av driftdatauppdateringar till analysarkivet från transaktionslagret (automatisk synkronisering)
Läsåtgärder för analys: läsåtgärder som utförs mot analysarkivet från Azure Synapse Analytics Spark-poolen och serverlösa SQL-poolkörningstider.
Prissättningen för analysarkivet är separat från prismodellen för transaktionsarkivet. Det finns inget begrepp om etablerade RU:er i analysarkivet. Se prissättningssidan för Azure Cosmos DB för fullständig information om prismodellen för analysarkivet.
Data i analysarkivet kan bara nås via Azure Synapse Link, vilket görs i Azure Synapse Analytics-körningen: Azure Synapse Apache Spark-pooler och Azure Synapse-serverlösa SQL-pooler. Se prissättningssidan för Azure Synapse Analytics för fullständig information om prismodellen för åtkomst till data i analysarkivet.
För att få en kostnadsuppskattning på hög nivå för att aktivera analysarkiv i en Azure Cosmos DB-container kan du från analysarkivets perspektiv använda Kapacitetshanteraren för Azure Cosmos DB och få en uppskattning av dina kostnader för analyslagring och skrivåtgärder.
Uppskattningar av läsåtgärder för analysarkiv ingår inte i Kostnadskalkylatorn för Azure Cosmos DB eftersom de är en funktion i din analytiska arbetsbelastning. Men som en uppskattning på hög nivå resulterar genomsökning av 1 TB data i analysarkivet vanligtvis i 130 000 analytiska läsåtgärder och resulterar i en kostnad på 0,065 USD. Om du till exempel använder Serverlösa SQL-pooler i Azure Synapse för att utföra den här genomsökningen på 1 TB kostar det 5,00 USD enligt prissidan för Azure Synapse Analytics. Den slutliga totala kostnaden för den här 1 TB-genomsökningen skulle vara 5,065 USD.
Medan ovanstående uppskattning är för genomsökning av 1 TB data i analysarkivet, minskar användningen av filter mängden data som genomsöks och detta avgör det exakta antalet analytiska läsåtgärder med tanke på prismodellen för förbrukning. Ett konceptbevis kring den analytiska arbetsbelastningen skulle ge en finare uppskattning av analytiska läsåtgärder. Den här uppskattningen inkluderar inte kostnaden för Azure Synapse Analytics.
Nästa steg
Mer information finns i följande dokument:
Kolla in träningsmodulen om hur du utformar hybridtransaktions- och analysbearbetning med Hjälp av Azure Synapse Analytics