Azure Cosmos DB: Användningsfall utan ETL-analys
GÄLLER FÖR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Azure Cosmos DB innehåller olika analysalternativ för no-ETL, nära realtidsanalys över driftdata. Du kan aktivera analys på dina Azure Cosmos DB-data med hjälp av följande alternativ:
- Spegling av Azure Cosmos DB i Microsoft Fabric
- Azure Synapse Link för Azure Cosmos DB
Mer information om de här alternativen finns i "Analys och BI på dina Azure Cosmos DB-data".
Viktigt!
Spegling av Azure Cosmos DB i Microsoft Fabric är nu tillgängligt som förhandsversion för NoSql API. Den här funktionen ger alla funktioner i Azure Synapse Link med bättre analysprestanda, möjlighet att förena din dataegendom med Fabric OneLake och öppna åtkomsten till dina data i OneLake med Delta Parquet-format. Om du överväger Azure Synapse Link rekommenderar vi att du provar spegling för att utvärdera den övergripande anpassningen för din organisation. Kom igång med spegling genom att klicka här.
No-ETL, nära realtidsanalys kan öppna upp olika möjligheter för dina företag. Här är tre exempelscenarier:
- Analys av leveranskedjan, prognostisering och rapportering
- Personanpassning i realtid
- Förebyggande underhåll, avvikelseidentifiering i IOT-scenarier
Analys av leveranskedjan, prognostisering och rapportering
Forskningsstudier visar att inbäddning av stordataanalyser i leveranskedjeoperationer leder till förbättringar i leveranstider och effektivitet i leveranskedjan.
Tillverkare registrerar sig för molnbaserade tekniker för att bryta sig ur begränsningar i äldre SYSTEM för företagsresursplanering (ERP) och Supply Chain Management (SCM). Med leveranskedjor som genererar ökande volymer av driftdata varje minut (order, leverans, transaktionsdata) behöver tillverkarna en driftdatabas. Den här driftdatabasen bör skalas för att hantera datavolymerna samt en analysplattform för att komma till en nivå av kontextuell intelligens i realtid för att ligga steget före kurvan.
Följande arkitektur visar kraften i att använda Azure Cosmos DB som den molnbaserade driftdatabasen i analys av leveranskedjan:
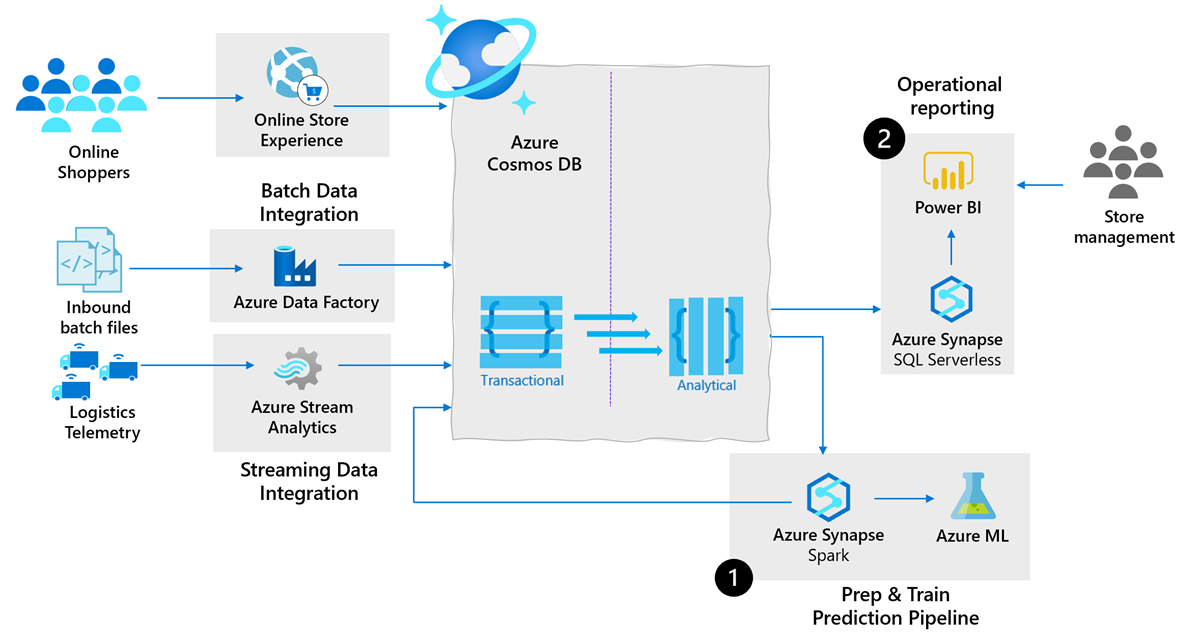
Baserat på tidigare arkitektur kan du uppnå följande användningsfall:
- Förbered och träna förutsägelsepipeline: Generera insikter över driftdata i leveranskedjan med hjälp av maskininlärningsöversättningar. På så sätt kan du sänka lager- och driftkostnaderna och minska leveranstiderna för kunderna.
Med spegling och Synapse Link kan du analysera ändrade driftdata i Azure Cosmos DB utan några manuella ETL-processer. De här erbjudandena sparar dig från ytterligare kostnader, svarstider och driftskomplexitet. De gör det möjligt för datatekniker och dataforskare att skapa robusta förutsägelsepipelines:
Fråga driftdata från Azure Cosmos DB med hjälp av intern integrering med Apache Spark-pooler i Microsoft Fabric eller Azure Synapse Analytics. Du kan köra frågor mot data i en interaktiv notebook-fil eller schemalagda fjärrjobb utan komplex datateknik.
Skapa Maskininlärningsmodeller (ML) med Spark ML-algoritmer och Azure Machine Learning-integrering (AML) i Microsoft Fabric eller Azure Synapse Analytics.
Skriv tillbaka resultaten efter modellslutsatsningen till Azure Cosmos DB för drift nästan realtidsbedömning.
Driftrapportering: Leveranskedjeteam behöver flexibla och anpassade rapporter över realtid, korrekta driftdata. Dessa rapporter krävs för att få en ögonblicksbild av leveranskedjans effektivitet, lönsamhet och produktivitet. Det gör det möjligt för dataanalytiker och andra viktiga intressenter att ständigt omvärdera verksamheten och identifiera områden för att justera för att minska driftskostnaderna.
Spegling och Synapse Link för Azure Cosmos DB möjliggör omfattande BUSINESS Intelligence (BI)/rapporteringsscenarier:
Fråga driftdata från Azure Cosmos DB med hjälp av intern integrering med fullständig uttrycksfullhet i T-SQL-språket.
Modellera och publicera automatiska uppdaterings-BI-instrumentpaneler via Azure Cosmos DB via Power BI som är integrerat i Microsoft Fabric eller Azure Synapse Analytics.
Följande är några riktlinjer för dataintegrering för batch- och strömmande data till Azure Cosmos DB:
Batch-dataintegrering och orkestrering: När leveranskedjorna blir mer komplexa måste dataplattformarna i leveranskedjan integreras med olika datakällor och format. Microsoft Fabric och Azure Synapse är inbyggda med samma dataintegreringsmotor och funktioner som Azure Data Factory. Med den här integreringen kan datatekniker skapa omfattande datapipelines utan en separat orkestreringsmotor:
Flytta data från över 85 datakällor som stöds till Azure Cosmos DB med Azure Data Factory.
Skriv kodfria ETL-pipelines till Azure Cosmos DB, inklusive relationella till hierarkiska och hierarkiska mappningar med mappning av dataflöden.
Integrering och bearbetning av strömmande data: Med tillväxten av industriell IoT (sensorer som spårar tillgångar från "golv till butik", anslutna logistikflottor osv.) genereras en explosion av realtidsdata som genereras på ett strömmande sätt som måste integreras med traditionella långsamma data för att generera insikter. Azure Stream Analytics är en rekommenderad tjänst för strömning av ETL och bearbetning i Azure med en mängd olika scenarier. Azure Stream Analytics stöder Azure Cosmos DB som en intern datamottagare.
Personanpassning i realtid
Återförsäljare måste idag bygga säkra och skalbara e-handelslösningar som uppfyller kraven från både kunder och företag. Dessa e-handelslösningar måste engagera kunder genom anpassade produkter och erbjudanden, bearbeta transaktioner snabbt och säkert och fokusera på uppfyllelse och kundservice. Med Azure Cosmos DB tillsammans med den senaste Synapse Link för Azure Cosmos DB kan återförsäljare generera anpassade rekommendationer för kunder i realtid. De använder inställningar för låg latens och justerbar konsekvens för omedelbara insikter som visas i följande arkitektur:
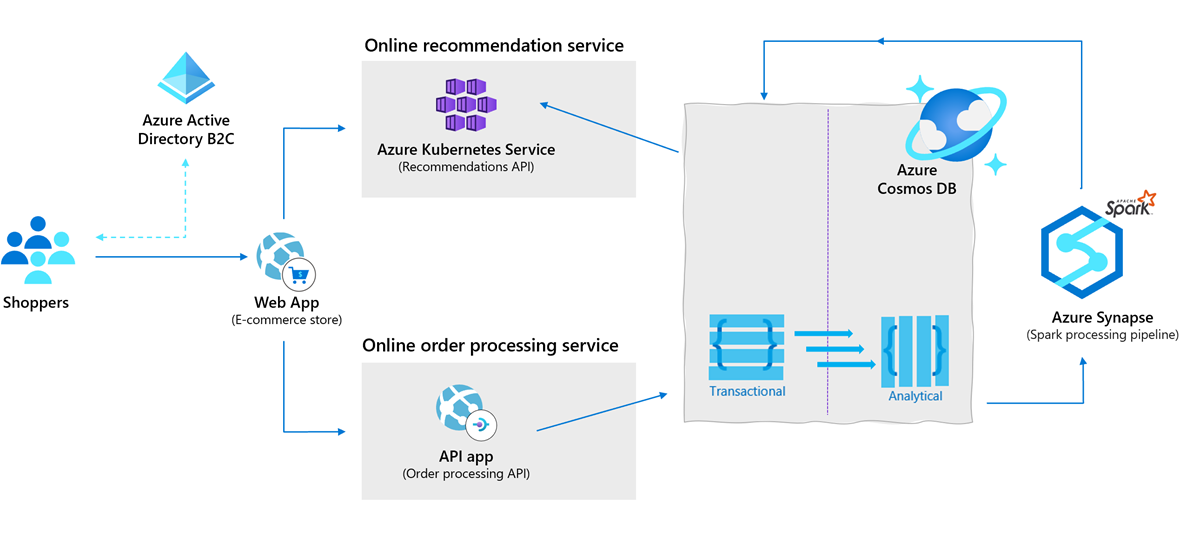
- Förbered och träna förutsägelsepipeline: Du kan generera insikter om driftdata i dina affärsenheter eller kundsegment med hjälp av Fabric- eller Synapse Spark- och maskininlärningsmodeller. Detta innebär anpassad leverans till målkundsegment, prediktiva slutanvändarupplevelser och riktad marknadsföring för att passa dina slutanvändares krav. )
Förutsägande underhåll av IOT
Industriella IOT-innovationer har drastiskt minskat stilleståndstiden för maskiner och ökat den totala effektiviteten inom alla branscher. En av dessa innovationer är analys av förutsägande underhåll för maskiner i molnets utkant.
Följande är en arkitektur som använder molnbaserade HTAP-funktioner i IoT-förutsägande underhåll:
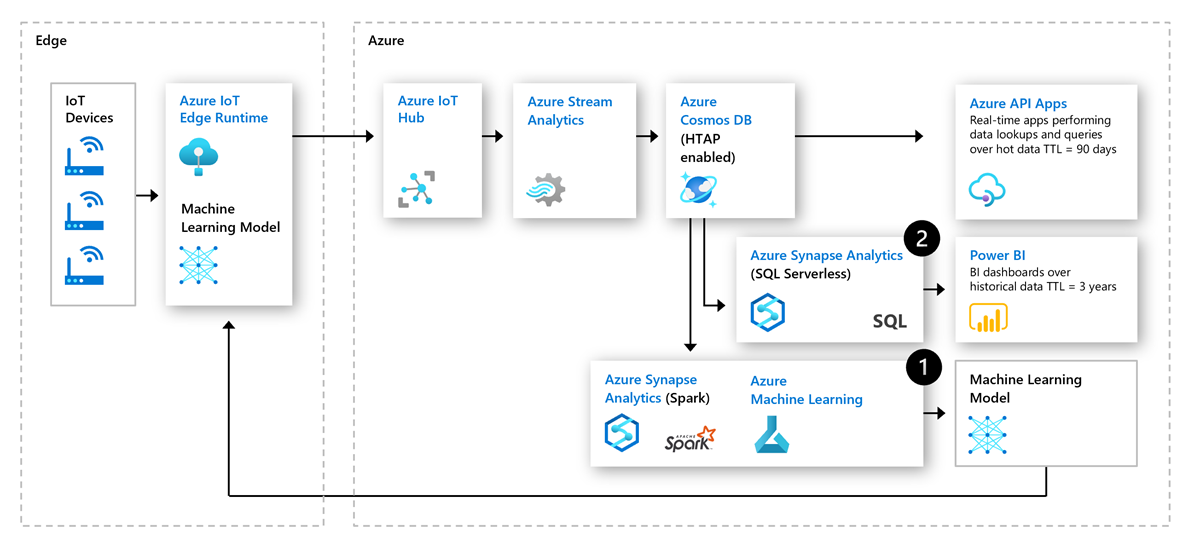
Förbered och träna förutsägelsepipeline: Historiska driftdata från IoT-enhetssensorer kan användas för att träna förutsägelsemodeller som avvikelsedetektorer. Dessa avvikelsedetektorer distribueras sedan tillbaka till gränsen för övervakning i realtid. En sådan god loop möjliggör kontinuerlig omträning av prediktiva modeller.
Verksamhetsrapportering: Med tillväxten av initiativ för digitala tvillingar samlar företag in stora mängder driftdata från ett stort antal sensorer för att skapa en digital kopia av varje dator. Dessa data driver BI måste förstå trender över historiska data utöver de senaste frekventa data.