Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Azure Data Explorer är en snabb, fullständigt hanterad dataanalystjänst. Den erbjuder realtidsanalys på stora mängder data som strömmas från många källor, till exempel program, webbplatser och IoT-enheter.
Om du vill kopiera data från en databas i Oracle Server, Netezza, Teradata eller SQL Server till Azure Data Explorer måste du läsa in enorma mängder data från flera tabeller. Vanligtvis måste data partitioneras i varje tabell så att du kan läsa in rader med flera trådar parallellt från en enda tabell. I den här artikeln beskrivs en mall som ska användas i dessa scenarier.
Azure Data Factory-mallar är fördefinierade Data Factory-pipelines. De här mallarna kan hjälpa dig att komma igång snabbt med Data Factory och minska utvecklingstiden för dataintegreringsprojekt.
Du skapar mallen Masskopiering från databas till Azure Data Explorer med hjälp av uppslags - och ForEach-aktiviteter . För snabbare datakopiering kan du använda mallen för att skapa många pipelines per databas eller per tabell.
Viktigt!
Se till att använda verktyget som är lämpligt för den mängd data som du vill kopiera.
- Använd mallen Masskopiering från databas till Azure Data Explorer för att kopiera stora mängder data från databaser som SQL Server och Google BigQuery till Azure Data Explorer.
- Använd verktyget Data Factory Copy Data för att kopiera några tabeller med små eller måttliga mängder data till Azure Data Explorer.
Förutsättningar
- Ett Azure-abonnemang. Skapa ett kostnadsfritt Azure-konto.
- Ett Azure Data Explorer-kluster och en databas. Skapa ett kluster och en databas.
- En datafabrik. Skapa en datafabrik.
- En datakälla.
Skapa ControlTableDataset
ControlTableDataset anger vilka data som ska kopieras från källan till målet i pipelinen. Antalet rader anger det totala antalet pipelines som behövs för att kopiera data. Du bör definiera ControlTableDataset som en del av källdatabasen.
Ett exempel på SQL Server-källtabellformatet visas i följande kod:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Kodelementen beskrivs i följande tabell:
| Fastighet | Beskrivning | Exempel |
|---|---|---|
| PartitionId | Kopieringsordningen | 1 |
| SourceQuery | Frågekriteriet som anger vilka data som ska kopieras under pipeline-processen | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''>
|
| ADXTableName | Destinations-tabellens namn | MyAdxTable |
Om din ControlTableDataset har ett annat format skapar du en jämförbar ControlTableDataset för ditt format.
Använda mallen Masskopiering från databas till Azure Data Explorer
I fönstret Låt oss komma igång väljer du Skapa pipeline från mall för att öppna fönstret Mallgalleri .
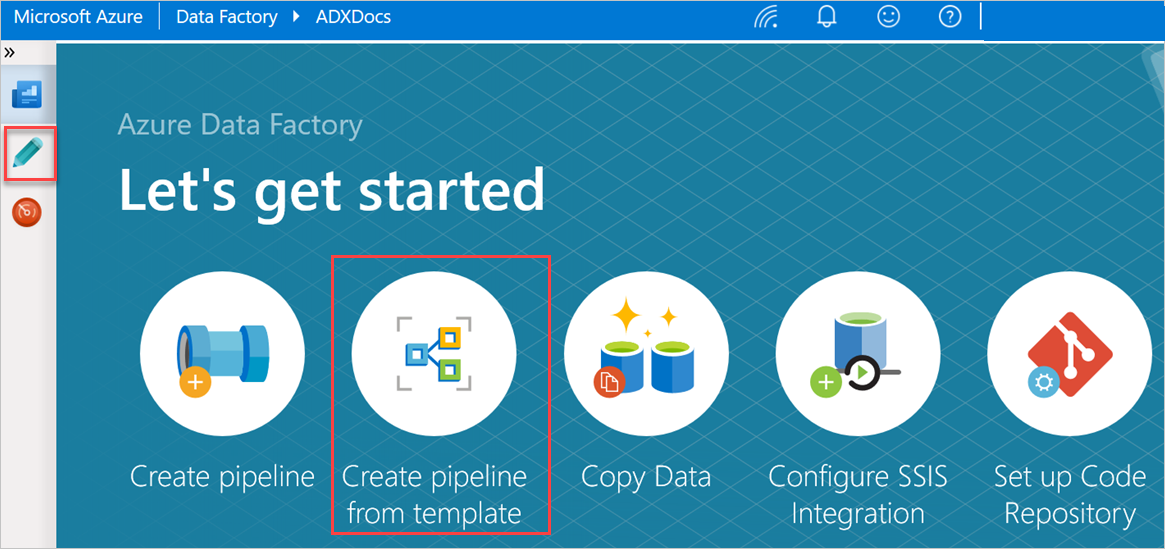
Välj mallen Masskopiering från databas till Azure Data Explorer .
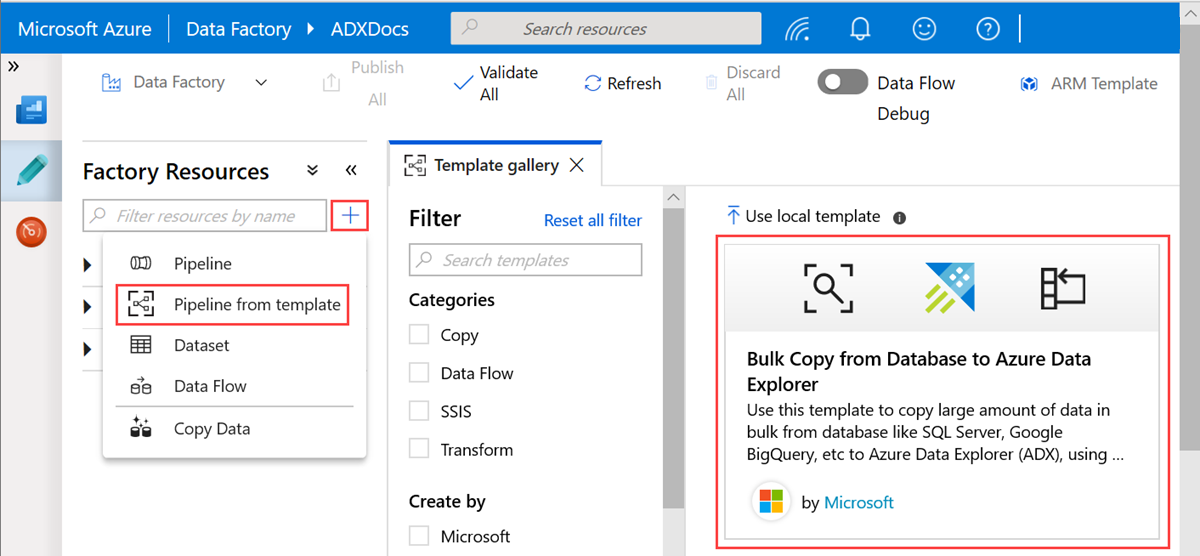
I fönstret Masskopiering från databas till Azure Data Explorer under Användarinmatning anger du dina datauppsättningar genom att utföra följande steg.
a. I listrutan ControlTableDataset väljer du den länkade tjänsten till kontrolltabellen som anger vilka data som kopieras från källan till målet och var de placeras i målet.
b) I listrutan SourceDataset väljer du den länkade tjänsten till källdatabasen.
Punkt c I listrutan AzureDataExplorerTable väljer du tabellen Azure Data Explorer. Om datauppsättningen inte finns skapar du den länkade Azure Data Explorer-tjänsten för att lägga till datauppsättningen.
d. Välj Använd denna mall.

Välj ett område på arbetsytan, utanför aktiviteterna, för att komma åt mallpipelinen. Välj fliken Parametrar för att ange parametrarna för tabellen, inklusive Namn (kontrolltabellnamn) och Standardvärde (kolumnnamn).
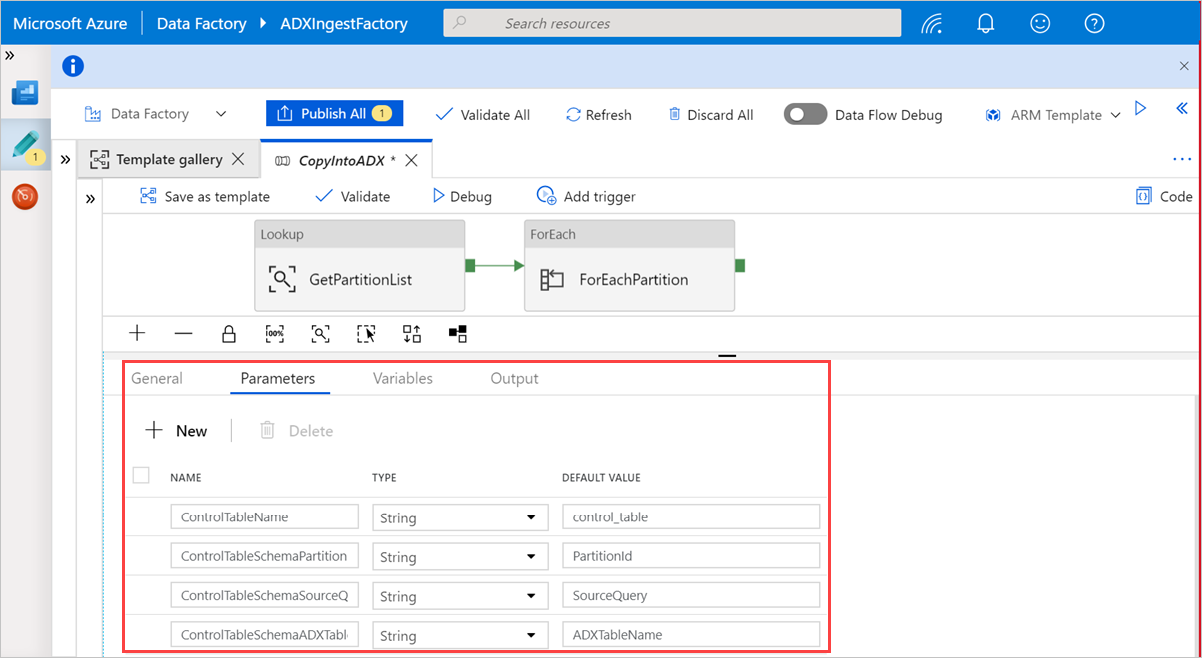
Under Sökning väljer du GetPartitionList för att visa standardinställningarna. Frågan skapas automatiskt.
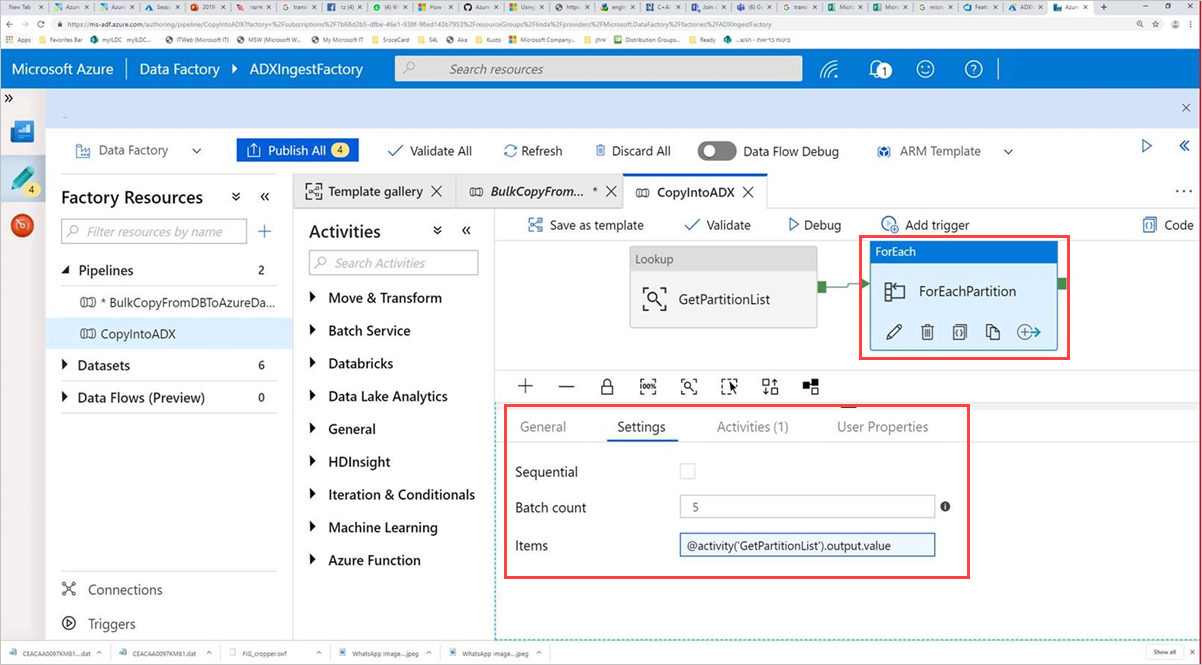
Välj kommandoaktiviteten ForEachPartition, välj fliken Inställningar och gör sedan följande:
a. I rutan Batch count anger du ett tal från 1 till 50. Den här markeringen avgör antalet pipelines som körs parallellt tills antalet ControlTableDataset-rader har nåtts .
b) Avmarkera kryssrutan Sekventiell för att säkerställa att pipelinebatcherna körs parallellt.
Tips/Råd
Det bästa sättet är att köra många pipelines parallellt så att dina data kan kopieras snabbare. För att öka effektiviteten partitionerar du data i källtabellen och allokerar en partition per pipeline enligt datum och tabell.
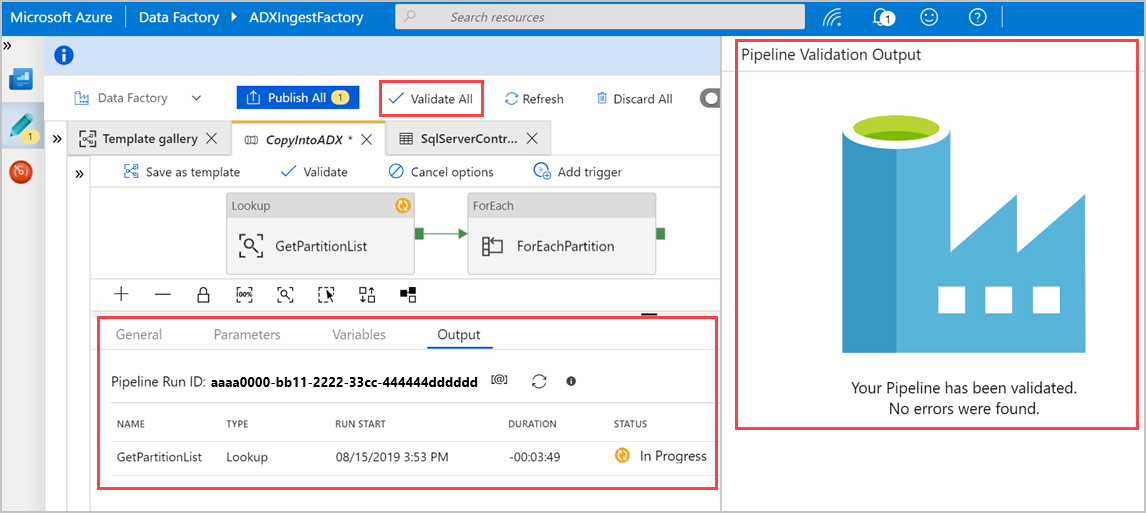
Välj Verifiera alla för att verifiera Azure Data Factory-pipelinen och visa sedan resultatet i fönstret Utdata för pipelineverifiering .
Om det behövs väljer du Felsök och sedan Lägg till utlösare för att köra pipelinen.
Nu kan du använda mallen för att effektivt kopiera stora mängder data från dina databaser och tabeller.
Relaterat innehåll
- Läs mer om Azure Data Explorer-anslutningsappen för Azure Data Factory.
- Redigera länkade tjänster, datauppsättningar och pipelines i Data Factory-användargränssnittet.
- Fråga efter data i Azure Data Explorer-webbgränssnittet.